
ChatGPT 发布之后,AI 智能体的概念就一直牵动着整个行业的想象力。它描绘的场景很诱人:给 AI 系统一个目标,让它自行拆解问题、调用工具、收集信息,最终综合出结果。
围绕这个概念的框架生态已经相当拥挤了:LangChain、CrewAI、AutoGen、Semantic Kernel、Agent Framework……新框架层出不穷,个个声称能简化智能应用的构建。但大多数还停留在 hello world 级别:一个智能体回答问题,顶多再调一两个工具。
构建一个多智能体系统,核心挑战不在于让智能体跑起来,因为任何框架都能做到,而在于如何让系统可维护、可测试、可扩展。本文围绕一个实际项目(多智能体协作从 YouTube 视频中提取、摘要和整理信息),探讨智能体系统的架构设计。涉及的关键问题包括:为什么智能体系统跟其他复杂应用一样需要分层架构,工具(LLM 接口)和服务(业务逻辑)的分离为何是智能体设计的核心洞见,领域驱动设计的概念如何自然映射到智能体架构,以及编排器模式下四个专业化智能体如何协调工作。
这个项目基于 Microsoft Agent Framework 构建,这是 Semantic Kernel 和 AutoGen 的继任者,融合了两者的优势。不过具体框架不是重点,后面讨论的原则无论用哪个框架都适用。
架构挑战
框架们都擅长帮你快速搭出 demo,但没有一个在引导你走向可维护、可扩展的架构。比如说各种示例代码中LLM 调用、工具集成、业务逻辑和编排之间的边界模糊得一塌糊涂。关注点分离这个概念在软件工程里存在几十年了,但在智能体领域,框架们集体选择了"快速上手"而非架构指导。教程优化的是"看多简单!"而不是"看多可维护!"
下面是一个典型的单体写法的简化版本,把所有东西混在一起:
# orchestrator.py - 智能体、工具、提示词和业务逻辑全部在一起
def run_research(query: str) -> str:
# 搜索智能体,工具定义在行内
def search_youtube(q: str) -> str:
response = requests.get(f"https://youtube.com/results?q={q}")
return parse_html_for_videos(response.text)
search_agent = ChatAgent(
name="SearchAgent",
instructions="""You search YouTube. Use search_youtube to find videos.
Return video IDs and titles as JSON.""",
tools=[search_youtube]
)
# 字幕智能体,有自己的行内工具
def get_transcript(video_id: str) -> str:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return " ".join([t["text"] for t in transcript])
transcript_agent = ChatAgent(
name="TranscriptAgent",
instructions="Fetch transcripts using get_transcript tool.",
tools=[get_transcript]
)
# 摘要智能体,提示工程嵌入其中
summarize_agent = ChatAgent(
name="SummarizeAgent",
instructions=f"""Summarize cooking content. Focus on:
- Temperatures and timing
- Key techniques
- Pro tips
Format as markdown."""
)
# 编排逻辑与智能体调用交织在一起
client = AzureOpenAI(api_key=os.environ["KEY"], ...)
videos = search_agent.run(query, client=client)
transcripts = []
for vid in parse_json(videos)[:3]:
text = transcript_agent.run(f"Get transcript for {vid['id']}", client=client)
transcripts.append(text)
summary = summarize_agent.run(f"Summarize:\n{transcripts}", client=client)
Path(f"./outputs/{query}.md").write_text(summary)
return summary
上面代码拿来做 demo 没问题,快速验证想法也完全合适。但问题是如果你要继续修改呢?
为什么这是一个架构问题
LLM 调用工具其实是两件事:用简单参数(字符串、数字)调用一个函数,然后解释返回的字符串结果。
但实际干活的部分:搜索 YouTube、解析 HTML、处理错误要复杂得多。涉及配置、错误处理、重试,返回的是带多个字段的结构化对象。
这两件事是不同的关注点,LLM 要的是简单字符串,应用要的是合理的抽象。把它们搅在一起就像把 SQL 查询直接写在视图层:能跑,但架构上是错的。
分离这两个职责,可测试性、可复用性、代码清晰度全都跟着出来了。
如何分离?
工具 = LLM 接口
工具是 LLM 和应用之间的薄适配层。接受简单参数(字符串、数字、布尔值),调用对应的服务,把结果格式化成 LLM 能理解的字符串。无状态。
# tools/youtube.py
async def fetch_video_transcript(
video_id: Annotated[str, Field(description="YouTube video ID")]
) -> str:
"""Fetch the transcript for a YouTube video.
Returns the full transcript text with video metadata.
"""
result = await fetch_transcript(video_id) # calls service
## Format for LLM
return f"Transcript for '{result.metadata.title}':\n\n{result.transcript.full_text}"
工具没有做的事:没有配置管理,没有复杂返回类型,没有业务逻辑。它只干一件事:调用服务、格式化结果。纯粹的适配。
服务 = 业务逻辑
服务才是真正实现所在。它们是带配置的可复用类,返回丰富的领域对象(模型),可以从 CLI、测试、其他服务任何地方调用,可能维护状态或连接。
# services/youtube.py
class YouTubeTranscriptFetcher:
"""Fetches transcripts from YouTube videos."""
def __init__(self, proxy_url: str | None = None):
self.proxy_url = proxy_url
async def fetch(
self,
video_id: str,
languages: list[str] | None = None
) -> TranscriptResult:
"""Fetch transcript with full metadata.
Returns a TranscriptResult containing the transcript text,
video metadata, and language information.
"""
# Real implementation with error handling, retries, etc.
raw_transcript = await self._fetch_from_api(video_id, languages)
metadata = await self._fetch_metadata(video_id)
return TranscriptResult(
metadata=metadata,
transcript=Transcript(
full_text=self._format_transcript(raw_transcript),
segments=raw_transcript,
language=self._detect_language(raw_transcript),
),
)
复杂性就该待在这里。配置、缓存、错误处理、重试、类型化返回,这些全归服务管。脱离 LLM,服务照样能用。
流程
LLM 决定获取字幕时的调用链:
LLM decides to call "fetch_video_transcript"
↓
tools/youtube.py::fetch_video_transcript(video_id)
↓
services/youtube.py::YouTubeTranscriptFetcher.fetch(video_id)
↓
Returns TranscriptResult object
↓
Tool formats as string for LLM
为什么这很重要
先说可复用性。服务可以直接从 CLI、测试脚本、批处理任何入口调用,完全绕过 LLM:
# 从 CLI 使用,完全绕过智能体
@click.command()
def download_transcript(video_id: str, output: str):
fetcher = YouTubeTranscriptFetcher()
result = fetcher.fetch(video_id)
Path(output).write_text(result.transcript.full_text)
# 在测试中使用,无需模拟 LLM
def test_fetcher_handles_unavailable_videos():
fetcher = YouTubeTranscriptFetcher()
with pytest.raises(TranscriptDisabledError):
fetcher.fetch("video_with_disabled_transcript")
# 在批处理中使用
async def process_videos(video_ids: list[str]):
fetcher = YouTubeTranscriptFetcher()
results = await asyncio.gather(*[fetcher.fetch(id) for id in video_ids])
return results
再说可测试性。服务返回类型化对象,断言写起来干脆利落。工具返回格式化字符串,验证起来就费劲多了:
# 测试服务 - 清晰的断言
def test_fetcher_returns_transcript():
result = fetcher.fetch("abc123")
assert result.transcript.full_text
assert result.metadata.video_id == "abc123"
assert result.transcript.language in ["en", "en-US"]
# 测试工具 - 需要字符串解析
def test_tool_formats_correctly():
output = fetch_video_transcript("abc123")
assert "## " in output # Has title?
assert "Transcript" in output # Has section header?
# Much harder to validate structure
然后是关注点分离。工具代码管"怎么呈现给 LLM",服务代码管"怎么真正干活"。YouTube API 改了?只动
services/youtube.py
。想换输出格式?只改工具就可以了。
分层架构
工具和服务的分离只是一条边界。完整的智能体系统需要更多结构。经过反复实验,最终落地了一个六层架构,每层一个明确的职责。熟悉领域驱动设计的话,应该会觉得眼熟:
实际代码中是这样的:
# presentation/cli.py - 表示层
@click.command()
def search(query: str):
"""Search for videos on YouTube."""
agent = create_search_agent()
result = agent.run(query)
click.echo(result)
# agents/search.py - 智能体层(仅配置)
def create_search_agent() -> ChatAgent:
"""Factory function that creates a Search Agent."""
return ChatAgent(
chat_client=get_chat_client(),
name="SearchAgent",
instructions=SEARCH_AGENT_INSTRUCTIONS,
tools=[search_youtube_formatted],
)
# tools/youtube.py - 工具层(薄 LLM 适配器)
async def search_youtube_formatted(query: str) -> str:
"""Search YouTube for videos matching the query."""
results = await search_youtube(query) # calls service
return format_for_llm(results) # formats for LLM
# services/youtube.py - 服务层(业务逻辑)
async def search_youtube(query: str) -> list[VideoResult]:
"""Search YouTube - returns rich domain objects."""
url = build_search_url(query)
html = await fetch_html(url) # calls infra
return parse_video_results(html)
# models/youtube.py - 模型层(领域对象)
@dataclass
class VideoResult:
video_id: str
title: str
channel: str
# infra/http_client.py - 基础设施层(HTTP 传输)
async def fetch_html(url: str, timeout: float = 10.0) -> str:
"""Fetch HTML content with browser-like headers."""
async with httpx.AsyncClient() as client:
response = await client.get(url, headers=DEFAULT_HEADERS, timeout=timeout)
response.raise_for_status()
return response.text
每层各司其职:智能体配置行为,工具做 LLM 适配,服务实现逻辑,模型定义结构。测试也更直接了:在层边界 mock,不深入内部。
DDD 的映射不是硬凑的,它自然浮现,因为智能体系统跟其他复杂应用面对的是同样一组关注点: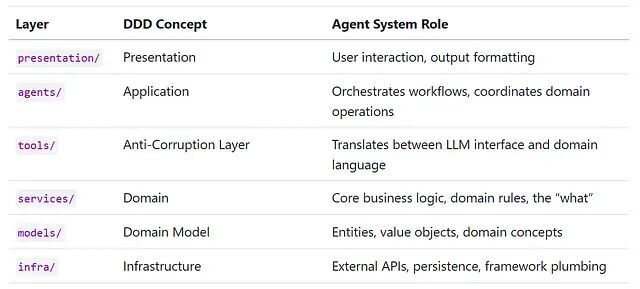
tools/
层作为防腐层这个对应关系特别精准。在 DDD 里,防腐层保护领域模型不被外部系统的概念入侵。这里也一样——它隔离了 LLM 的接口需求,在"LLM 能推理的字符串"和"代码使用的丰富领域对象"之间做翻译。
调用流程严格向下。智能体用工具,工具调服务,服务操作模型。这个约束逼着你想清楚每段代码该放在哪。
何时需要这种架构
对简单项目来说是不是过度设计?算是,但有几种情况下值得从一开始就这么做:要上生产、在用 AI 编码助手(GitHub Copilot、Claude Code 这类工具在结构清晰的代码上表现好得多)、多人协作、需要正经测试、领域本身复杂(多个外部 API、复杂业务逻辑、丰富数据模型),或者预期会持续扩展。
智能体系统里的"混乱"都是渐进发生的。一开始图快用内联工具,后来要复用一个,再后来要测试某个东西,再后来要加错误处理。每改一次,代码就纠缠一分。
AI 编码助手时代的架构
还有一个越来越重要的维度:结构清晰的代码跟 AI 编码助手配合得更好。
GitHub Copilot、Cursor、Claude Code 这些工具已经成了开发工作流的标配。一个很明显的规律是,面对结构良好的代码,它们的表现远胜于面对全新项目或纠缠的代码库。配上文档提供上下文的话效果更好。
比如让 Claude Code "实现按最短时长过滤搜索结果的功能",它会精准地找到
services/youtube.py
。服务层边界清晰、接口有类型、模式一致。AI 不需要理解整个系统就能推理出该怎么改。
如果工具定义散在编排代码里,AI 就得先搞清楚工具在哪定义、跟智能体怎么耦合、改了会不会影响其他地方、依赖关系怎么走。
让代码对人类可维护的那些架构原则,同时也让代码对 AI 助手可导航。清晰的边界让 AI 能聚焦单一层而不用理解全栈。一致的模式让 AI 学会之后可以一致地应用。类型提示不只是文档,它们是 AI 生成正确代码的约束。单一职责让 AI 改一个服务时不用推理多个关注点。
这不是为了"对 AI 友好"而牺牲设计,而是真正让代码对 AI 系统可理解的东西。
AI 编码助手越普及,架构纪律就越有价值。从 AI 辅助中获益最多的永远是本来就结构良好的代码库。混乱的代码库只会继续混乱,因为 AI 会放大已有的模式——不管好坏。
测试
分层架构带来的一个自然好处是可测试性。层间边界清晰,测试策略就跟着直截了当。
遵循的原则:在系统边界 mock,不在内部 mock。
┌─────────────────────────────────────────────┐
│ agents/ → tools/ → services/ │ ← Test with REAL code
└─────────────────────────────────────────────┘
↓
┌─────────────────┐
│ External APIs │ ← MOCK here
│ - YouTube API │
│ - Azure OpenAI │
└─────────────────┘
不要 mock 自己的服务。测试
TranscriptSummarizer
时,注入 mock 的 OpenAI 客户端,但让服务本身的逻辑真实执行。测试存储时,用临时目录,但跑真正的文件 I/O。
这样拿到的是更高的信心(走的是真实代码路径),更少脆弱的测试(少维护 mock),还能捕获纯单元测试漏掉的集成 bug。
领域驱动的组织方式
有了分层结构,下一个问题是:每个层内部怎么组织代码?拿
services/
包举例,同样的思路适用于所有层,不过不同层可能会得出不同结论。
这个地方 DDD 的限界上下文概念直接适用。
两个选项:
选项 A 按功能拆分:
services/
├── search.py # YouTube search
├── transcript.py # Transcript fetching
├── summarizer.py # AI summarization
└── storage.py # Persistence
选项 B 按限界上下文:
services/
├── youtube.py # Search + transcripts (same context)
├── summarizer.py # AI summarization
└── storage.py # Persistence
选了 B。
限界上下文
在领域驱动设计中,限界上下文是一个术语具有一致含义的边界。"YouTube"就是一个限界上下文——"video_id"指 YouTube 视频 ID,"channel"指 YouTube 频道,"transcript"指 YouTube 字幕。
搜索和字幕获取共享同一个 API 面、同一组领域概念(视频、频道)、同一类错误条件(速率限制、视频不可用)。放在一起可以获得内聚性(调试字幕问题不用翻多个文件)、可替换性(加 Vimeo 支持?建一个
services/vimeo.py
实现同样接口,其余系统不用动)、可发现性("YouTube 逻辑在哪?"答案是
services/youtube.py
,就这么简单),以及 AI 可理解性——一致的领域语言让 AI 助手能共享你的词汇表,不用猜。
判定准则
决定代码放哪的时候,可以问自己一个问题:"如果把这个外部系统换掉,什么要跟着变?"
每个领域边界就是一个潜在的替换点。如果换掉一个外部系统需要改多个文件,边界很可能划错了。
这个限界上下文原则贯穿了领域层和防腐层——
services/
、
tools/
、
models/
里各有一个
youtube.py
,组织 YouTube 相关的功能。导航变得可预测:"YouTube 逻辑在哪?"在任何一层找
youtube.py
就行。
对 AI 辅助开发还有个附带好处:LLM 需要理解或修改 YouTube 相关代码时,一致的命名让它不用猜就能找到正确的文件。而且大一点的内聚模块不是坏事——模型读一个文件就有完整上下文,比从一堆小文件里拼信息好得多。
智能体设计:单一职责
层结构和领域组织都定了,来看智能体本身。
每个智能体恰好做一件事:
看起来也许太死板了——TranscriptAgent 手头已经有字幕文本了,为什么不顺便做个摘要?
原因在于可预测性和可调试性。出了问题的时候:摘要质量差,查 SummarizeAgent;字幕拉不下来,查 TranscriptAgent;搜索结果不相关,查 SearchAgent。一个问题一个入口。
为什么不用一个 YouTubeAgent?
你可能注意到了一个矛盾。刚才主张
services/
、
tools/
、
models/
都按限界上下文组织,每个层都有
youtube.py
。那为什么不搞一个同时处理搜索和字幕的 YouTubeAgent?
因为不同层的组织逻辑不同。领域层(服务、模型)和防腐层(工具)按外部系统划分,这些层包含"video_id"、"channel"这类领域概念,按限界上下文分组让系统更容易理解和替换。但智能体是编排层:定义的是任务和角色,不是系统边界。SearchAgent 的任务是"找视频",TranscriptAgent 的任务是"拉字幕",它们碰巧用了同一个外部系统。
没人会把 SummarizeAgent 叫"AzureOpenAIAgent",虽然它确实用了 Azure OpenAI。智能体的身份取决于它做什么,而非它用了什么。一个任务,一个智能体,出问题时一个要看的地方。
编排器模式
四个职责单一的智能体需要协调,这就是 OrchestratorAgent 的工作:
用户请求
↓
编排器(决定做什么)
↓
├── "需要搜索" → SearchAgent
├── "需要字幕" → TranscriptAgent
├── "需要摘要" → SummarizeAgent
└── "需要保存" → WriterAgent
编排器维护对话记忆,清楚哪些内容已经缓存(通过上下文注入),把具体工作委托给专家,自己从不直接调 YouTube 或 OpenAI。
这种分离意味着每个专业智能体都可以独立测试,输入输出清清楚楚。
智能体
定义一个智能体出乎意料地简单:
[#agents](#agents)/search_agent.py
SEARCH_AGENT_INSTRUCTIONS = """You are a YouTube Search Agent. Your job is to find relevant YouTube videos based on user queries.
When asked to search:
1. Use the search_youtube tool to find videos
2. Return the results clearly formatted
3. Highlight which videos seem most relevant to the query
You only search - you do not fetch transcripts or summarize. Other agents handle those tasks."""
def create_search_agent() -> ChatAgent:
"""Factory function that creates a Search Agent."""
return ChatAgent(
chat_client=get_chat_client(),
name="SearchAgent",
instructions=SEARCH_AGENT_INSTRUCTIONS,
tools=[search_youtube_formatted],
)
指令提取成了模块级常量(也可以从外部文件加载,比如
prompts/search_agent.txt
,迭代提示词时不用碰 Python 代码)。工具来自
tools/
层的函数(它们再去调服务)。智能体完全不知道 YouTube API 的存在——它只调工具。
编排器的样子
编排器遵循同样的模式,只不过它的"工具"是委托给其他智能体:
class OrchestratorAgent:
"""Coordinates sub-agents for YouTube research tasks."""
def __init__(self) -> None:
self._agents: dict[str, ChatAgent] = {}
# Agent factory registry for lazy initialization
self._agent_factories = {
"search": create_search_agent,
"transcript": create_transcript_agent,
"summarize": create_summarize_agent,
"writer": create_writer_agent,
}
def _get_agent(self, name: str) -> ChatAgent:
"""Get or create an agent by name (lazy initialization)."""
if name not in self._agents:
self._agents[name] = self._agent_factories[name]()
return self._agents[name]
async def _delegate(self, agent_name: str, request: str) -> str:
"""Delegate a request to a sub-agent."""
agent = self._get_agent(agent_name)
result = await agent.run(request)
return result.text
async def ask_search_agent(self, request: str) -> str:
"""Delegate a search request to the Search Agent."""
return await self._delegate("search", request)
# ... similar for transcript, summarize, writer
def get_orchestrator(self) -> ChatAgent:
return ChatAgent(
chat_client=get_chat_client(),
name="Orchestrator",
instructions=ORCHESTRATOR_INSTRUCTIONS,
tools=[
self.ask_search_agent,
self.ask_transcript_agent,
self.ask_summarize_agent,
self.ask_writer_agent,
],
)
这里用类而不是简单的工厂函数是刻意的:编排器要维护状态,具体来说是一个延迟初始化的子智能体缓存。避免每次委托都重建智能体,初始化成本推迟到首次使用。
编排器的"工具"本质上是委托函数。LLM 决定搜索时调
ask_search_agent
,后者运行 SearchAgent 并返回结果。编排器拿到结果,决定下一步。
这就是中心辐射(hub-and-spoke)模式:
┌─────────────┐
│ Orchestrator│
│ (LLM) │
└──────┬──────┘
│
┌────────────┬─────┴─────┬───────────┐
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌──────────┐ ┌─────────┐ ┌─────────┐
│ Search │ │Transcript│ │Summarize│ │ Writer │
│ Agent │ │ Agent │ │ Agent │ │ Agent │
└─────────┘ └──────────┘ └─────────┘ └─────────┘
所有交互流经中心。编排器逐步积累上下文,维护完整的对话历史。
上下文注入
一个容易忽略但很关键的模式:编排器需要知道哪些字幕已经缓存了,才能做出聪明的决策。Microsoft Agent Framework 提供了
ContextProvider
基类,通过实现
invoking()
方法在每次 LLM 调用之前注入上下文:
from agent_framework._memory import Context, ContextProvider
class TranscriptContextProvider(ContextProvider):
"""Provides context about stored transcripts to the orchestrator."""
async def invoking(self, messages, **kwargs) -> Context:
"""Called before each LLM invocation."""
video_ids = self._storage.list_videos()
if not video_ids:
return Context(instructions="No transcripts currently stored.")
lines = ["You have these transcripts available:"]
for vid in video_ids:
stored = self._storage.load(vid)
if stored:
status = "summarized" if stored.summary else "not summarized"
lines.append(f"- {stored.metadata.title} ({vid}): {status}")
return Context(instructions="\n".join(lines))
框架在每次 LLM 请求前调
invoking()
,返回的
Context
合并到智能体指令里。
这跟对话记忆是两回事,因为对话记忆是用户和智能体之间的来回对话历史,框架自动管理,通常走线程或会话机制。传给
invoking()
的
messages
参数已经包含了这个历史。
ContextProvider
解决的是另一个问题:注入对话之外的领域状态。存储层把字幕持久化到磁盘了,但 LLM 不知道那边有啥除非主动告诉它。查询存储、格式化成指令,弥合的是应用状态和 LLM 上下文窗口之间的鸿沟。
对话记忆回答"聊了什么",领域上下文回答"有什么资源可用"。框架管前者,后者得自己负责。
于是编排器就能做这样的推理:"用户要摘要,字幕已经缓存了,跳过获取直接找 SummarizeAgent。"
输出
最终的 markdown 文件:
# Pork Loin Roast on a Kamado (YouTube-Technique Guide)
**Date:** 2025-01-11
**Source:** YouTube technique summaries (videos linked below)
## Key targets (temps & doneness)
- **Pit / dome temp (indirect smoking):****250–275°F** (121–135°C)
- **Internal temp targets (pork loin):**
- **Pull at 140–145°F** (60–63°C) for juicy slices
- If you prefer more done: **150°F** (66°C)
- **Rest:****10–20 minutes** (loosely tented)
## Recommended kamado setups
### Setup A — Indirect "smoke-then-finish" (most consistent)
1. **Charcoal:** quality lump; add 1–3 chunks of mild fruit wood
2. **Heat deflectors:** installed for indirect cooking
3. **Target pit temp:** stabilize at **250–275°F**
...
## Video references
- **Fork & Embers** — Pork loin roast method
- **Chuds BBQ** — Temp-control + finishing approach
多个 YouTube 视频的信息被综合成了一份连贯、可直接操作的参考文档。SearchAgent 找到对的视频,TranscriptAgent 拿到内容,SummarizeAgent 提炼关键信息,WriterAgent 保存结果。各司其职。
迭代优化
编排器维护着对话历史,所以可以接着聊来细化结果:
User: Can you add a section comparing direct vs indirect cooking methods?
User: The temperatures seem low - can you check if Chuds mentions a hotter approach?
User: Save a version without the glaze instructions for my friend who doesn't like sweet.
后续请求直接复用缓存的字幕,不需要重新从 YouTube 拉取。编排器记得自己有什么,推理还缺什么,按需委托。这个对话循环才是智能体模式真正出彩的地方——系统根据反馈调整,不用每次都从头来。
灵活性的代价
编排器模式有个重要的权衡,跑多几次才看得出来:方差。
上面展示的整齐的顺序流程只是一种可能的执行路径。同样的请求再跑一次,可能走一个完全不同的路线。
对同一请求做多次基准测试,LLM 调用次数从 17 到 34 不等。同样的输入。编排器 LLM 每次做出的战术决策不一样: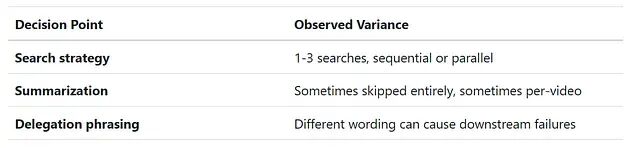
开详细日志就能看到差异:
# Run A (17 calls) - Minimal approach
SearchAgent called with: Kamado pork loin Fork and Embers
SearchAgent called with: Chuds BBQ pork loin kamado
TranscriptAgent called with: Fetch transcript for video FsbwQI-EI-k...
TranscriptAgent called with: Fetch transcript for video 2AF1ysZ8eEA...
TranscriptAgent called with: Fetch transcript for video fI86yXKlnQA...
WriterAgent called with: Write a markdown file... # Skipped summarization!
# Run B (25 calls) - Thorough approach
SearchAgent called with: Find YouTube videos where Fork and Embers...
SearchAgent called with: Find YouTube videos where Chuds BBQ...
SearchAgent called with: Find top YouTube videos about cooking pork loin...
TranscriptAgent called with: ...
SummarizeAgent called with: From the provided transcripts, extract...
WriterAgent called with: ...
Run A 认为 WriterAgent 可以直接从原始字幕综合出结果。Run B 多走了一步摘要。两个都给出了有效输出,但成本和质量可能不同。
"把 temperature 设成零不就行了?"
面对方差的第一反应自然是把 LLM temperature 调低,追求确定性行为。测了:
所有运行都设了固定 seed(42)。
即使 temperature=0 加固定 seed,调用次数仍有 10 次的波动(25 到 35 次)。不可预测性的根源不是采样随机性,而是 LLM 在每次运行中做出了不同的、但都合理的策略选择:发几个并行搜索(1、2 还是 3)、按视频分别摘要还是合并摘要、要不要跳过摘要让 writer 直接综合。
这种方差是架构层面的。要削减它要么把每个智能体的范围卡得极其严格让决策空间收窄,要么干脆提前规划好执行路径,消除运行时决策。后续文章会探讨这些替代方案。
这不是 bug,这是让 LLM 在运行时决策工作流的固有代价。编排器获得了随机应变的灵活性,代价是不可预测性。对于对话式交互场景,这个权衡通常划得来。对于需要高可预测性的批处理,可能得换别的方法。
总结
本文的出发点是想验证一件事:智能体系统到底能不能像其他严肃软件一样做架构。编排器模式的探索证明:能。
方法本身谈不上新颖。分层架构、关注点分离、领域驱动设计,全是老话题。不过可以看到它们映射到智能体系统时几乎是天然契合的。
工具和服务承担的是根本不同的职责。工具在 LLM 的世界(简单参数、字符串输出)和领域的世界(丰富对象、业务逻辑)之间做翻译,把它们分清楚,系统就自然变得清晰可测。
我们可以理解智能体是带了自然语言接口和 LLM 组件的软件系统。工程纪律那套东西几十年了,依然适用,只是得想清楚边界画在哪。
本文代码:
https://github.com/Chris-hughes10/multi-agent-patterns
作者:Chris Hughe