
Yann LeCun 反复强调过一个观点:当前LLM基于概率、逐 Token 预测的设计路线,很可能走不到人类水平的AI。他的团队更看好另一条路,基于能量的模型(EBM)。
上图来自他十多年前的一篇论文,LLM对候选答案返回"概率",EBM返回的则是"能量",能量最低的选项胜出。举个例子:输入 X = "汽车有4个轮子吗?",LLM可能给出 p("是") = 0.9、p("否") = 0.1;EBM则可能给出 E("是", X) = -3.1、E("否", X) = 0.4。谁的能量低谁就是答案。
两类模型的差异大吗?对EBM的输出做某种"归一化"就应该得到LLM输出的概率,但是差异恰恰就在归一化这一步。LLM用 Softmax 保证概率之和为1,EBM则松开了这条约束。训练时不需要归一化、不需要计算概率,在高维连续空间中反而获得了更多的灵活性和可训练性。对连续数据(比如图像)的全部可能输出做归一化本身就极其困难,能绕开就绕开。
构建EBM模型
给每个(可能的)数据点分配一个能量值,这个值是某个函数 E(x) 对输入数据点返回的标量。数据点出现的概率与该标量成反比——能量低则概率高,反过来也成立。回忆高中物理里各种"能量"(势能、动能等),势能越低的系统通常越稳定,道理一样。
假设已经拿到了 E(x),能否把它转换成概率?有时候确实需要,因为两个分别训练的系统各自输出的能量没有共同的校准基准,不能直接比较与合并;做密度估计时也需要概率。
密度估计是整个概率AI的核心主题,假定存在一个随机过程持续产生可观测的数据点,密度估计的任务是根据已观测的数据"猜"出该过程的概率密度函数(PDF)。一旦掌握了PDF数据的分布规律就清楚了:不仅能做预测,还能做生成。
理解数据生成过程的PDF,远超常规AI中"给定 X 预测 Y"的范畴。后者只是在估计某个过程的结果,不尝试理解或建模整个过程,生成完全是另一码事。
寻找能量函数 E(x)
训练EBM的核心目标:找到一个能量函数,能够为给定的 X 识别出最佳的 Y。换言之,在一系列可能的 Y 值中,哪一个和当前 X 最兼容?
合理的做法是训练一个深度神经网络,接收数据点(X 和 Y 的组合)作为输入,输出一个标量。X 和 Y 兼容性低时输出高值,兼容性好时输出低值。为了符号简洁,将能量函数的输入统一记作 x,即 E(x),x 代表 X 和 Y 的组合。
训练方式是常规套路:取大量数据样本,学习能量函数 E(x) 的参数 θ,让已观测到的、合理的数据点能量低,不太可能出现的数据点能量高。损失函数需要同时做两件事:(1) 压低正确答案的能量;(2) 抬高错误答案的能量。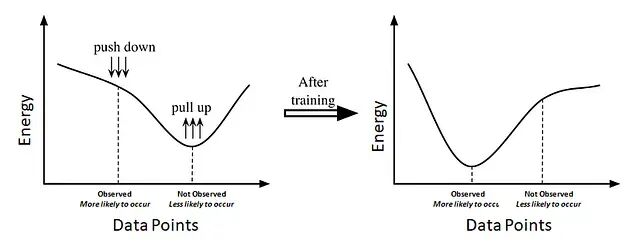
一般性理论到这里就够了,但是接下来才进入更棘手的部分:寻找密度函数。
寻找概率密度函数(PDF)
目标是找到由 θ 参数化的概率密度函数 q(x):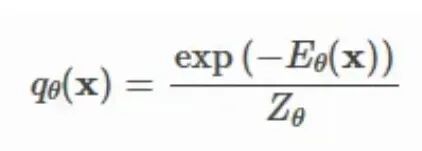
能量函数 E(x) 的值域是 -∞ 到 +∞,取指数后输出自动变为正值,概率必须为正。至于为什么不直接约束 E(x) 本身为正?因为放开限制能让设计更自由,只要用 exp(E(x)) 保证输出为正即可。接下来做归一化:所有状态的概率之和(或积分)应该等于1,分母中的 Z 干的就是这件事。这样PDF就搞定了。
Z 大概是学概率模型的人最怕遇到的东西。名字有好几个——配分函数、归一化常数——出了名地难算。
指数前面那个负号呢?坦白讲没有功能性意义,纯粹是惯例所以去掉也不影响。
能量函数和密度函数的概念到此为止。
来自物理学的一点启发
上面的内容大量借鉴自物理学。把墨水滴入水中,它怎样扩散?过程本身是随机的,但宏观上系统总是从高能量状态向低能量状态演化。如果一个随机过程有10种可能的状态,每种状态各有其能量值,系统最终大概率停留在能量最低的那个状态。能量是一种粗粒度度量,它把一个状态内部所有微观过程的贡献浓缩成一个数。
远在AI出现之前,Boltzmann就发明了一种概率分布来描述热平衡中气体的统计力学行为。Gibbs后来做了进一步改进,这个分布被称为 Boltzmann分布(也叫Gibbs分布)。它给出系统处于某个状态的概率,是该状态能量和系统温度的函数。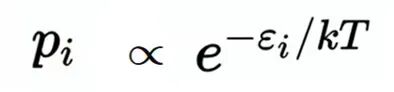
p_i 是系统处于状态 i 的概率,ε_i 是该状态的能量,常数 k*T 不重要。Boltzmann分布说的一件事很简单:能量低的状态被占据的概率更高。要得到精确的概率值,除以归一化常数 Z 即可。而这个方程和EBM的密度估计 q(x) 几乎一模一样——物理学的直觉和EBM的数学走到了同一条路上。
训练EBM
LeCun讨论了多种损失函数。这类任务天然适合对比训练方法:拿一对样本喂给模型,训练目标是让其中一个的能量高于另一个。这种对比性质适合自监督训练。要绕开 Z可以构造只关心能量相对差异、不需要计算绝对概率的训练场景——比如取两个能量的比值,让 Z 在分子分母间自行消掉。
最终目标是学到一个能量景观:高概率的数据点能量低,低概率的能量高,全程不碰 Z。可选的算法有 Score Matching 族以及其他几类方法,但如果要建模密度函数 q(x) 呢?
这意味着要计算精确概率而非相对概率。分母里的 Z 注定让事情变困难。精确计算需要遍历所有可能的数据配置,计算量是"不可解的"。绕过精确 Z 的办法是用 MCMC 等采样过程产生大量样本,对训练所需的对数似然梯度做近似估计。对数似然展开后有两个关键项: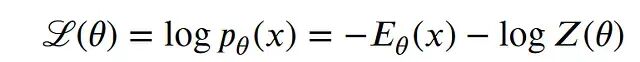
第一项的梯度把已观测数据点的能量往下压让它们更可能出现。第二项对数配分函数 Z 的梯度,则把其余所有位置的能量往上抬,防止模型给什么数据都打低能量。这一项实际上就是能量在模型当前分布上的平均梯度。
操作上可以这么理解:从模型中"生成"样本,和已观测的数据点混在一起训练,目的是让已观测数据点获得低能量、模型生成的样本获得高能量。用LeCun讲课时的比喻来说,损失函数应该在能量景观中"雕刻"出地形——训练样本附近挖坑(能量低),其他地方填高。模型要学会在观测数据所在位置"挖洞",在其余位置"堆土"。详细推导见附录。
回头再看LeCun论文中训练EBM的原始图示: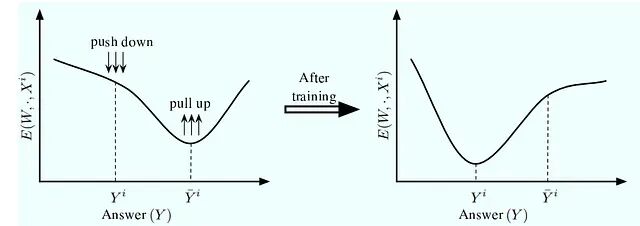
Y_i 是正确答案,Y_i 上方带hash标记的则是"最具迷惑性的错误答案",所有错误答案中能量最低的那个。在连续情况下定义正误很直观:Y_i 一定距离内的答案算正确,超出该距离的算错误。设计良好的损失函数在学习过程中会压低 E(Y_i, X_i),同时抬高错误答案的能量,尤其是 E(Y¯_i, X_i)。
不过生成样本非常慢,因为马尔可夫链必须跑到平衡态才能采样步数往往很大。为此 Hinton 提出了对比散度(CD)方法:只运行极短的马尔可夫链,采样速度大幅提升。设 p_0 为数据分布、p_∞ 为模型分布,梯度按以下公式计算: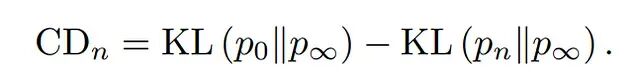
右侧第一项是数据分布与模型分布之间的"散度",即 p_0 和 p∞ 之差(至于它们为什么不直接叫 P_data 和 P_model,LeCun也没解释)。第二项是短程MCMC链——从 p_0 出发跑 n 步得到 p_n——与模型分布 p∞ 之间的散度。直觉解释见附录。
上面这个差分关注的是"模型经过 n 步后偏离数据的程度",由此产生的梯度引导模型让训练数据更可能出现,同时让 n 步重建的结果更不可能出现。令人意外的是即使 n = 1,训练出来的EBM质量也相当好。
配合一些工程技巧——比如训练过程中维护并复用样本缓冲区——速度还能进一步提升。
使用训练好的EBM做推理
假设手上已有一个训练好的EBM,推理过程是什么样的?
和常规模型不同EBM的推理不是直接"给定 X 输出 Y"。这里需要遍历 Y 的所有可能取值,找出哪个 X 与 Y 的组合能量最低,那就是最终预测。本质上这是一个优化问题,模型预测的是输入 X 和输出 Y 之间的兼容程度。由此可以衍生出几类任务:分类——"哪个 Y 与 X 最兼容?"取能量最低的组合,应用场景如机器人导航;排序——"Y1 和 Y2 哪个与 X 更兼容?"按能量排序即可,应用场景如数据挖掘;检测——"这个 Y 与 X 兼容吗?"看能量升降趋势,如人脸检测中图像越不像人脸能量越高。
推理可以概括为:固定已观测变量的值,搜索剩余变量的配置使能量最小化。这个过程代价可能很高,需要选择合适的优化算法。参考LeCun的论文,按照 Y 的形式不同,推理策略也不同:
如果 Y 是连续变量且能量曲面 E(X,Y) 光滑,直接套用基于梯度的优化算法找最优 Y 就行。与训练阶段更新网络权重不同,这里是对 Y 本身做优化——从某个初始 Y 出发,沿 E(X,Y) 对 Y 的梯度方向迭代,直到落入极小值。思路和训练神经网络并无本质区别。如果 Y 是一组离散变量,能量函数可以表达为因子图——即若干依赖于不同变量子集的能量函数(因子)之和——那么可以用 min-sum 等算法。图、团和EBM的关系后面会进一步讨论。如果输出 Y 的每个元素可以表示为加权有向无环图(DAG)中的一条路径,特定 Y 的能量就是沿路径的边和节点值之和;因为图无环且能量是简单求和,最优路径可以用动态规划(如Viterbi算法)高效求解,在生物序列分析(如基因查找)中很实用。还有一些情况下,能量函数依赖于一组隐变量 Z——比如训练人脸检测系统时尺度和姿态信息未知。很多时候精确优化不切实际,必须诉诸近似方法,包括替代能量函数。
EBM的优势
EBM属于指数族,在AI领域有大量成熟的技术和工具可供复用。做最大似然估计取对数似然时"对数"和"指数"相互抵消,让数学处理变得简洁得多。统计物理中配分函数、自由能、变分近似等概念同样可以直接搬过来用。
在架构设计和训练准则方面,EBM比概率方法有更大的回旋余地。关键优势在于:概率方法不可解的场景下,EBM是可解的。概率模型必须做归一化,往往需要在所有可能的变量配置空间上计算积分,而很多时候这个积分根本算不出来。EBM不要求归一化,这个问题被天然绕过了。
EBM还有一个有意思的性质:总能量可以是多个能量函数之和——即专家乘积(Product of Experts)。图模型其实是EBM的一个特例,能量函数分解为各个能量项的和。为每个团(clique)分别设计能量函数然后简单相加就得到总能量,已有成熟的推理算法可以对这些项之和关于目标变量求最小值。听起来有些抽象,值得展开解释。
EBM作为因子图
从专家乘积(PoE)说起。PoE模型将多个专家各自输出的概率密度相乘得到总概率,每个"专家"对应一个未归一化能量函数。什么是未归一化能量函数?之前定义过归一化版本的能量函数: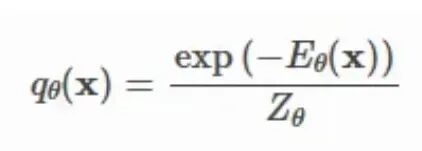
未归一化能量函数就是分子部分,即 Exp(-E(x))。
假设整体能量函数复杂到无法直接处理——高维、变量众多。如果能把这个复杂系统拆分成若干子系统,每个子系统只依赖一小部分变量,每个子系统就是一个"专家"。这些专家的乘积给出总概率。因为子系统规模小得多,可以更透彻地分析和设计各自的能量函数。
做乘积时,把各专家的指数函数相乘即可。根据 Exp(a) * Exp(b) = Exp(a+b),乘法变成了各能量的简单加法,整体(未归一化)能量就是各子能量之和。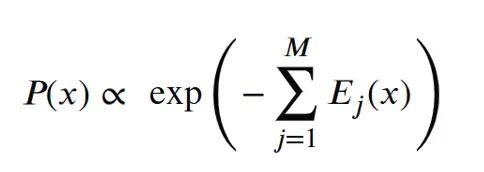
和试图为整个复杂系统找一个巨大的能量函数相比,把多个小而专的能量函数直接相加明显更可行——一个专家负责某方面,另一个负责另一方面。EBM的能量函数就这样被"因式分解"为各个函数(因子)之和,等价于因子图表示的图模型。
任何传统图模型都可以表示为因子图,EBM在这类场景下有天然的适配性。为每个团分别定义能量函数,求和即得总能量。团就是变量的一个子集。循环置信传播等高效算法可以用来计算最低能量配置。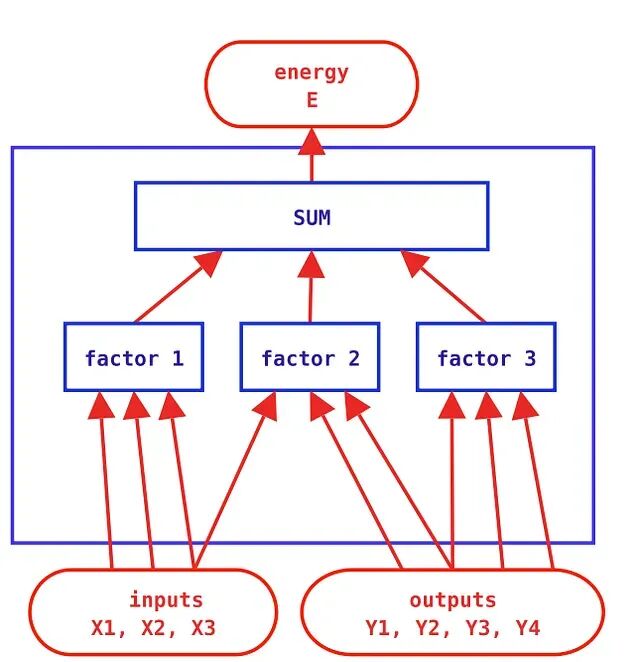
从Hopfield网络到Transformer注意力机制
能量模型并非新事物1982年 John Hopfield 就提出了一种循环人工神经网络,功能类似"联想记忆系统"。
就像一丝微弱的气味能唤起完整的记忆一样,Hopfield网络接收不完整的数据,尝试还原完整的原始模式。它的机制正是EBM:将"模式"存储为能量景观中稳定的局部最小值。面对损坏或缺失的输入,网络迭代更新神经元状态,沿能量景观不断下降,直至落入最近的稳定"记忆",输出完整的重建结果。具体过程如下:
- 将损坏或不完整的图像输入网络。
- 网络中的神经元彼此相连,迭代更新自身状态,持续降低系统总能量。
- 网络达到稳定的最低能量状态时停止更新——得到对原始未损坏模式的最佳重建。
去噪只是一个方面。这类网络也能用于求解优化问题(如旅行商问题),收敛到低能量状态就对应着优化问题的解。
Hopfield网络的能量函数由 Lyapunov函数 控制返回一个将神经元状态映射到实数值的标量,Hopfield网络是确定性的总会收敛到最近的局部能量最小值。另一种架构——玻尔兹曼机——则引入了随机性(概率性),使网络有能力跳出局部最小值去寻找全局最优。
玻尔兹曼机通常包含隐含单元,因而能建模更复杂的数据结构、学习内部表示。从物理意义上说,隐含节点在可见节点之间引入了有效的高阶交互,产生了针对可见节点的新能量函数。当隐含节点与可见节点之间的交互设为零时,玻尔兹曼机退化为Hopfield网络。
模拟和训练玻尔兹曼机不容易。一种简化方案是移除所有层内连接、只保留层间连接——所有可见节点都连到所有隐含节点,同层内无连接。由此得到的受限玻尔兹曼机参数更少、表达能力有所下降,但训练更方便且泛化性能更好。训练依然适用前面讨论过的那些技术。
2024年诺贝尔物理学奖颁给了Geoffrey Hinton和John Hopfield。Hopfield网络启发了现代机器学习方法。AI领域没有独立的诺贝尔奖类别,不过Hinton和LeCun拿到了地位相当的图灵奖——话题又回到了LeCun和他的团队。
LeCun的世界模型
LeCun离开Meta后创立了AMI Labs。他的核心论点是:当前LLM一次生成一个 Token 的固有设计,决定了它无法达到人类水平的智能,EBM可能是另一条出路。
EBM能同时预测整个输出序列的能量,而LLM每次只输出单个 Token 的概率。给整个句子算一个能量,再和其他候选句子比较,这在LLM框架下做不到。推而广之,规划在中途就能评估进展时效果最好——如果只在最后才拿到反馈,那和猜没什么区别。一个可以施加到中间状态的评分,能告诉你当前是否正确、哪里需要修复。EBM正好提供了这种能力:能量可以在部分轨迹上计算,而非仅限于最终答案。
从认知科学角度看,EBM可以(大致)对应Daniel Kahneman《思考,快与慢》中那种缓慢而审慎的类型2思维:在推理时运行优化过程以最小化能量,模仿深思熟虑的过程。LLM则按顺序逐 Token 生成、从不回头检查,本质上是"快"而直觉式的类型1思考。EBM可以在输出之前对完整答案反复斟酌,正如人类在面对复杂问题时所做的那样。LeCun的原话是:"真正的推理应该被表述为一个优化问题。"
Softmax 在这方面有结构性缺陷。它本质上是"赢者通吃"——两个输出值只要稍有差距,Softmax就会把这个差距放大为概率上的巨大悬殊。生成模型在理想状态下应当能考虑多种可能的下一步,而不是每次都锁定得分最高的那个选项。基于 Softmax 的模型天生具有单峰偏差:擅长表示分布中单一的宽峰,难以处理落在输入空间不相邻区域的数据。EBM不存在这个问题,它可以同时给多个不相交的数据区域赋予低能量(多峰分布中多个不同的峰)。Softmax还带来过度自信的问题——膨胀大的输出、压制小的输出,程度远超合理范围。虽然有各种变通方案,但这是一个结构层面的硬伤。
LLM还有一个根本局限:它困在文本的离散世界里,缺乏人类意义上的"世界模型",无法预判行动的后果。试图构建一个预测未来每个细节的生成模型注定行不通。在世界建模的框架下,做法是在输入空间中预测未来状态,再通过EBM衡量这些预测状态与当前上下文之间的"兼容性"。
人脑对世界的感知方式也不是直接的。大脑通过感官观察世界,从中构建出外部世界的表征,这个过程发生在一个独立的潜空间中。潜空间的结构与真实世界有关联,但针对实用性而非精确性做了优化。世界模型也应当具备类似特性。
JEPA(联合嵌入预测架构)是世界模型方向上的一次尝试。它学习世界的抽象表征(团队用视频做了实验),在抽象空间中做预测。I-JEPA 面向图像,V-JEPA 面向视频,都跳过了像素级重建,直接在潜空间中预测更高层次的特征。JEPA及类似模型在不同程度上借鉴了EBM的思想。严格说它们不是完整的EBM——推理时不做能量优化,仍然走常规前向传播——但确实把能量或相关替代指标用作了模型架构的关键组件。Logical Intelligence 发布的Kona是一个更激进的例子。
Kona是面向关键系统的"基于能量"的AI模型,核心机制是物理驱动的优化而非逐 Token 预测。它能同时生成完整的推理轨迹,并直接对问题和约束做条件化。推理在连续潜空间中进行,输出密集向量 Token 而非离散 Token,因而可以利用学到的能量对推理轨迹做受控的局部编辑,通过近似梯度信息改善连贯性和约束满足度。在困难数独上Kona的解题率达到96.2%,超出当时所有前沿LLM。
附录
每当在概率AI方面有疑问,翻开Goodfellow等人的《深度学习》总能找到答案。这本书封底有三位在AI领域可能无人能及的学者的推荐语,不是没有原因的。直接跳到第18章,标题恰如其分——"面对配分函数"。先从之前讨论过的对数似然入手。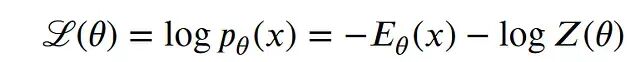
它来源于一个简单的关系: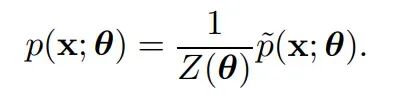
PDF p 等于未归一化的 PDF(p 上方带hash标记)除以归一化常数 Z。θ 是要通过梯度下降求解的参数集。上式对数似然的梯度展开后变成: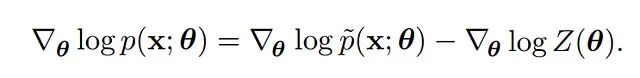
到这里并没有做什么复杂的操作。倒三角是梯度符号。幸运的是,这在机器学习中是常见的模式——学习的正阶段(第一项)和负阶段(第二项)。第一项从数据集中采样就能轻松求出,真正麻烦的是第二项。注意 Z 本身只是 p(带hash标记)的求和或积分,因而是 θ 的函数,求梯度就必须对它做计算。
第二项可以通过几步简单变换改写为期望值的形式。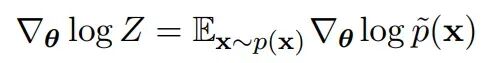
有了期望值的形式,就可以用采样来近似:从模型 p(x) 中抽取若干 x 的样本,做蒙特卡罗估计得到训练所需的梯度。最终的对数似然梯度变为: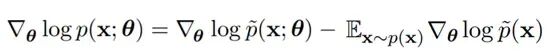
方程中两项各有分工。第一项对应从数据集中均匀抽样计算梯度;第二项对应从正在训练的模型 p(x) 中用MCMC抽样、取平均后计算梯度。这就是机器学习文献中的正阶段与负阶段。正阶段中,对从数据集抽取的 x 增大 log p˜(x);负阶段中,对从模型分布抽取的 x 减小 log p˜(x),以此降低配分函数。全程只需要处理未归一化的 p˜,不涉及 Z 的精确计算,操作上完全可行。
能量函数去哪了?Goodfellow给出了连接:深度学习文献中通常用能量函数来参数化 log p˜。正阶段于是对应压低数据集中训练样本的能量,负阶段对应抬高从模型中抽取的样本的能量。
再看Goodfellow版本的能量升降图示,和LeCun的版本略有不同: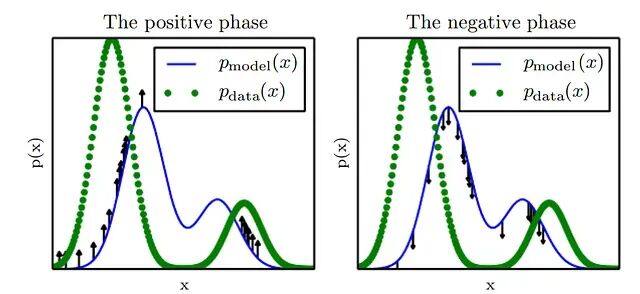
绿色的点表示数据集的PDF。从数据集中均匀采样时,取到的 x 更多地集中在绿色峰值附近。正阶段是对数似然梯度的第一项,它让模型的 PDF p(x) 在这些数据点周围有更高的密度(对应的能量应被压低,但这里暂不引入能量概念以保持简洁),从而让模型逐渐逼近数据分布。
但正阶段有一个副作用:它盲目地在所有位置增加未归一化概率——绿色峰值处加得多一些,其他地方也加了。只做这一步是不够的。要加速收敛,必须同步降低其他位置的未归一化概率。这正是负阶段做的事情。(虽然叫"阶段",两者实际上同步发生。)
负阶段从模型分布中采样点,压低它们的未归一化概率。通过MCMC从 p(x) 中采到的点可能来自任何位置——好的数据点也好,坏的数据点也好,一律压低。把好数据点的概率推回去是正阶段的职责。
两项协同工作。第二项抵消了正阶段到处加常数的倾向,训练过程中模型与数据集的分布逐渐趋同。当二者完全相等时,正阶段在任何一点推高的力与负阶段推低的力大小相等,梯度的期望降为零,训练收敛。
负阶段降低了从模型中采样的点的概率,因此这些点通常被解读为模型对世界的"错误信念"。一个引人遐想的推论:负阶段被提议用于解释人类的做梦——大脑维护着一个关于世界的概率模型,清醒时经历真实事件并沿 log p˜ 的梯度更新模型,睡眠时经历从当前模型中采样出的事件并沿 log p˜ 的负梯度走,以最小化 log Z。
如何简化MCMC采样
MCMC的主要成本在于每步都要从随机初始化开始"预热"马尔可夫链(详见前面分享的MCMC链接)。自然的优化思路是从一个接近模型分布的分布出发来初始化链。用什么初始化?可以直接用数据集。
对比散度(CD)算法在每步用数据分布的样本初始化马尔可夫链。训练初期,数据分布和模型分布差距较大,负阶段精度不高;与此同时正阶段默默发挥作用。等正阶段把模型分布拉近了数据分布,负阶段的精度也跟着上来。
CD算法的梯度计算方式前面已经展示过: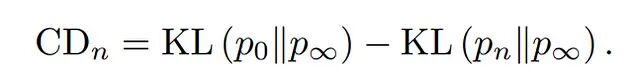
可以这样理解:当输入来自数据时,如果模型的马尔可夫链对输入做了剧烈改动,就予以惩罚。这个估计有偏差——MCMC中 n 步之后的项被忽略了——但偏差很小。研究表明,CD丢掉的恰恰是正确MCMC更新梯度中最小的那些项。
作者:Allohvk