
这篇文章从基本原理出发完整拆解变分自编码器(VAE)的构建过程。重点不在数学推导而在于把概念落到足够具体的层面:完成实现、训练、调试和部署。每个组件做了什么、为什么需要它、代码里怎么写文章都会逐一交代,后半部分会逐行走读一个最小化的 PyTorch 实现,并介绍训练完成后的几种推理模式。
VAE 为什么存在
当需要理解数据中潜藏的模式时,变分自编码器(VAE)是一个值得考虑的选项。它不只是做数据压缩而是以连续、可插值的方式去捕捉数据背后的生成结构:覆盖可能性的完整范围。训练结束后模型既能重建已有样本,也能生成新的逼真样本,还能对新数据做异常检测。
标准自编码器的做法是把数据压缩到低维表示再还原。问题出在它学到的潜在空间往往缺乏结构:相邻的点未必对应相似的数据,随机采样产出的结果也大多没有意义。
VAE 对潜在空间施加了正则化约束。输入不再被映射到单一的潜在向量,而是映射到一个分布:通常是高斯分布。训练期间,模型让这些分布贴近一个已知的先验(一般取标准正态分布),最终得到的潜在空间平滑且有组织,可以安全地从中采样和推断。
这正是 VAE 在异常检测和表示学习中发挥作用的原因。重建偏差可以在原始特征空间中得到直观解读;潜在偏差如果实现了解耦也具有可解释性,但缺少专门的训练目标(如 β-VAE、FactorVAE 等)时,解耦并无保证。
VAE 在学习重建数据的同时,也在学习一个形态接近简单概率分布的潜在空间。
三个核心组件
VAE 由三个概念层面的部件组成——编码器、潜在空间(通过采样/重参数化技巧实现)、解码器。
编码器接收输入,输出两个向量:均值 μ 和方差 σ²,二者共同定义潜在空间上的概率分布。采样步骤利用一种保持可微性的技巧从该分布中抽取潜在向量,解码器再拿到这个向量去重建原始输入。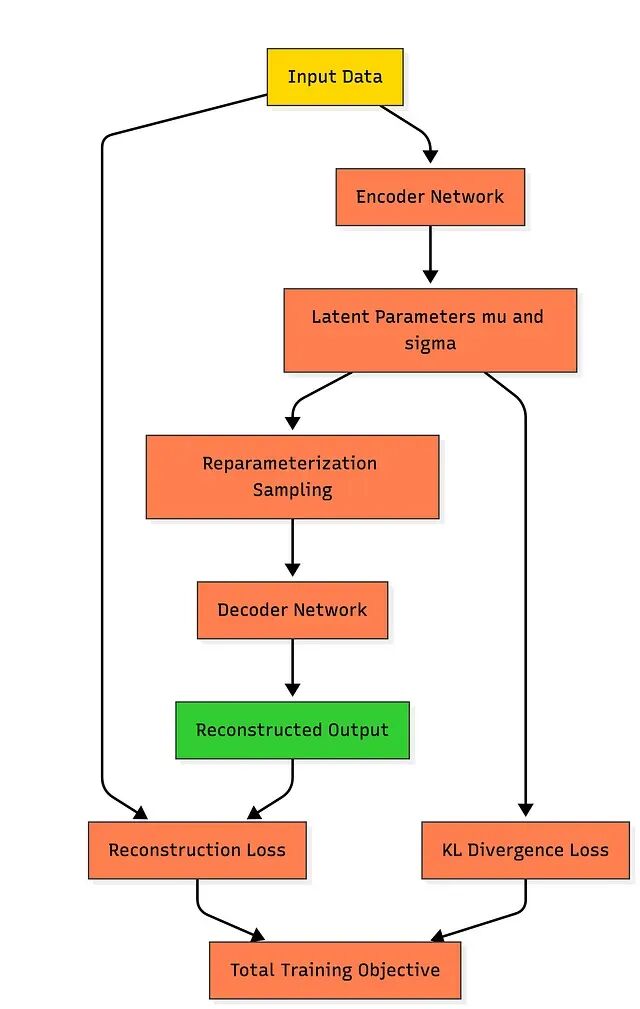
训练过程同时平衡两个目标:重建要准确,潜在分布要贴近先验。VAE 的结构特性正来源于这种平衡。
损失函数
VAE 的损失函数同时追求两件事:把输入数据重建得尽可能准,并约束潜在空间服从标准正态分布。重建损失(比如均方误差)度量输出与输入的偏差;KL 散度度量学习到的潜在分布与标准正态分布之间的距离。
换个角度看——重建损失在奖励保真度,KL 损失则在防止模型死记硬背,迫使潜在空间维持良好的分布形态。
VAE 的损失函数同时追求两件事:把输入数据重建得尽可能准,并约束潜在空间服从标准正态分布。
从理论到代码
下面逐步走读一个最小化的 PyTorch 实现。示例假定输入为表格或展平后的数据,但同样的思路适用于图像和序列。
定义编码器
编码器将输入向量映射为两个输出:潜在分布的均值和对数方差。
import torch # PyTorch核心库
import torch.nn as nn # 神经网络构建模块
import torch.nn.functional as F # 常用激活函数和工具函数
class Encoder(nn.Module): # 将编码器定义为神经网络模块
def __init__(self, input_dim, latent_dim):
super().__init__() # 初始化父类nn.Module
# 第一个全连接层:
# 接收输入数据并将其映射到隐藏表示
self.fc1 = nn.Linear(input_dim, 128)
# 输出潜在分布均值(mu)的线性层
self.fc_mu = nn.Linear(128, latent_dim)
# 输出潜在分布对数方差(log σ²)的线性层
# 使用对数方差是为了数值稳定性
self.fc_logvar = nn.Linear(128, latent_dim)
def forward(self, x):
# 将输入通过第一层并应用ReLU激活函数
# 从原始输入中提取有用特征
h = F.relu(self.fc1(x))
# 计算潜在分布的均值
mu = self.fc_mu(h)
# 计算潜在分布的对数方差
logvar = self.fc_logvar(h)
# 返回两个参数,以便后续从分布中采样
return mu, logvar
到这一步为止,还没有涉及任何概率运算。代码只是在预测分布的参数。
编码器将输入数据压缩为紧凑的潜在表示(μ 和 σ),捕捉其关键特征。
重参数化技巧
直接从分布中采样会切断梯度的传播路径。重参数化技巧的做法是把采样拆解为一个确定性函数加上随机噪声。
def reparameterize(mu, logvar):
# 将对数方差转换为标准差
# std = sqrt(variance)
# 使用logvar保持训练的数值稳定性
std = torch.exp(0.5 * logvar)
# 从标准正态分布中采样随机噪声
# 这个噪声是使VAE具有随机性的关键
eps = torch.randn_like(std)
# 创建潜在向量z
# z = 均值 + (随机噪声 * 标准差)
# 这使得梯度在训练过程中能够通过mu和std流动
return mu + eps * std
梯度照常经由 μ 和 σ 回传,随机性又被保留下来。
重参数化技巧让 VAE 能在潜在空间中采一个随机点,同时不破坏反向传播。本质上,它把随机性改写成了网络可以求导的形式。
定义解码器
解码器负责把潜在向量映射回原始输入空间。
class Decoder(nn.Module):
def __init__(self, latent_dim, output_dim):
# 初始化PyTorch父模块
super().__init__()
# 第一个全连接层
# 接收潜在向量z并将其扩展为隐藏表示
self.fc1 = nn.Linear(latent_dim, 128)
# 输出层
# 将隐藏表示映射回原始输入大小
# 产生重建结果
self.fc_out = nn.Linear(128, output_dim)
def forward(self, z):
# 将潜在向量z通过第一个线性层
# 并应用ReLU引入非线性
h = F.relu(self.fc1(z))
# 将隐藏表示通过输出层
# 产生重建的输入
return self.fc_out(h)
解码器不需要知道任何关于概率分布的事情,它只做重建。
解码器从采样得到的潜在向量出发,尝试恢复出与原始输入匹配的数据。
组合在一起:VAE
class VAE(nn.Module):
def __init__(self, input_dim, latent_dim):
super().__init__()
# 编码器将输入数据映射到潜在分布(mu, logvar)
self.encoder = Encoder(input_dim, latent_dim)
# 解码器将潜在向量z映射到重建的输入
self.decoder = Decoder(latent_dim, input_dim)
def forward(self, x):
# 将输入通过编码器获取潜在分布参数
mu, logvar = self.encoder(x)
# 使用重参数化技巧采样潜在向量z
z = reparameterize(mu, logvar)
# 将潜在向量解码回输入空间
recon_x = self.decoder(z)
# 返回重建结果和潜在统计量(用于计算损失)
return recon_x, mu, logvar
前向传播的流程与概念上的流程完全一致。
损失函数的代码实现
def vae_loss(recon_x, x, mu, logvar, beta=1.0):
# 重建损失:
# 衡量输出与原始输入的接近程度
recon_loss = F.mse_loss(recon_x, x, reduction='mean')
# KL散度损失:
# 惩罚潜在分布偏离标准正态分布过远的情况
kl_loss = -0.5 * torch.mean(
1 + logvar - mu.pow(2) - logvar.exp()
)
# 总损失平衡重建质量
# 和潜在空间正则化
return recon_loss + beta * kl_loss
beta 参数控制重建质量与潜在正则化之间的权衡。当 beta > 1 时即为 β-VAE——以牺牲重建精度为代价换取更解耦的潜在因子。
训练循环
训练阶段模型只接触数据样本,优化上述组合损失。有一点需要特别留意:用于异常检测时,VAE 通常仅在正常数据上训练,模型由此学会"正常"的分布形态,异常样本则在推理时暴露为高重建误差或偏离常规的潜在分布。
# 创建优化器来更新VAE的参数
# Adam是训练神经网络的常用且稳定的选择
optimizer = torch.optim.Adam(vae.parameters(), lr=1e-3)
# 多次遍历数据集
for epoch in range(num_epochs):
# 遍历数据的批次
for batch in dataloader:
# 获取当前批次的输入数据
x = batch
# 前向传播:
# 编码 -> 采样潜在z -> 解码
recon_x, mu, logvar = vae(x)
# 计算VAE损失(重建损失 + KL散度)
loss = vae_loss(recon_x, x, mu, logvar)
# 清除上一步的旧梯度
optimizer.zero_grad()
# 反向传播:
# 计算损失相对于模型参数的梯度
loss.backward()
# 使用优化器更新模型参数
optimizer.step()
用于异常检测时,VAE 通常仅在正常数据上训练。模型学到"正常"的分布形态后,异常样本会以高重建误差或偏离常规的潜在分布暴露出来。
训练完成后得到了什么
训练结束后,手里拿到的远不止一个重建模型。潜在空间中的距离和偏差都携带语义:可以检视哪些潜在维度在异常出现时发生了漂移,可以对比重建结果,也可以跟踪 KL 散度随时间的变化趋势。
可解释性在异常检测中就是这样进行。如果潜在空间已解耦,某个因子的异常即可定位到具体原因;即使未能解耦,仍然可以在原始特征空间中分析重建偏差,回溯根因。
实际应用——训练好的 VAE 的推理模式
VAE 的用途不止一种。训练完成后根据目标不同可以被复用在多个场景中,编码器-解码器架构加上结构化的潜在空间给了它足够的适应余地。
异常检测
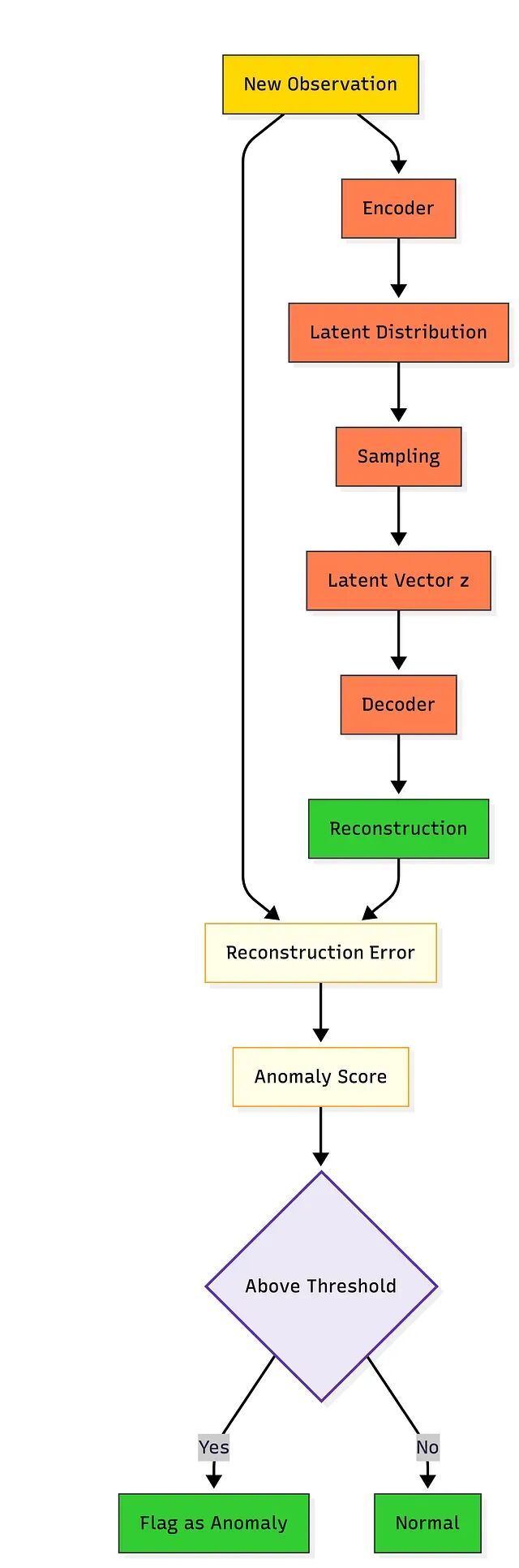
训练结束后 VAE 已经建立了对"正常"数据的内部表征。新输入经过编码器→潜在空间→解码器后,将输出与原始输入做比较即可判断异常——重建误差越大,样本越可能偏离正常模式。以信用卡交易为例,消费模式异常的交易在重建时会产生明显偏差,对应较高的异常得分。类似场景还包括设备监控和医疗异常检测。关键推理信号是重建误差,或样本在已学分布下的似然度。
合成数据生成
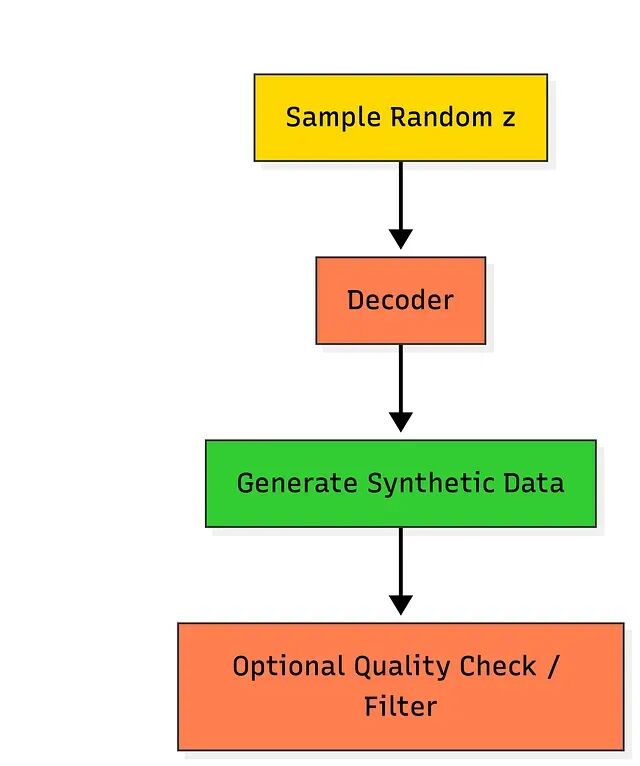
无需任何特定输入,直接在潜在空间中采样再经解码器输出,即可生成新的逼真样本。潜在空间在训练期间已被约束为近似标准正态分布,从中采样的点解码后会产生与训练数据风格相近的新数据。典型场景包括数据增强、系统仿真和压力测试。在医学领域,可以产出罕见病的逼真影像,或合成客户交易历史用于测试。
关键推理信号是从潜在先验分布采样(z ~ N(0,1)),经解码输出新样本。
条件生成
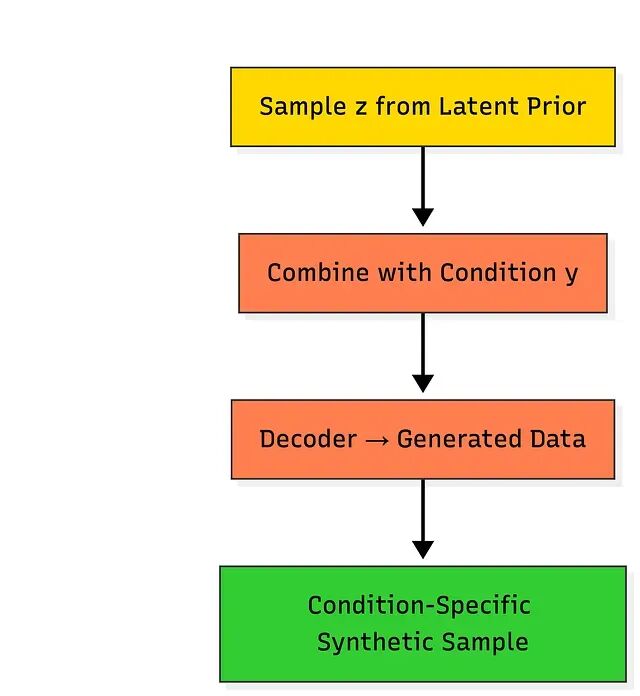
在标准 VAE 基础上引入额外的条件信息,就得到了条件 VAE(CVAE)。例如基于标签生成图像,或基于客户群体生成合成交易、生成某类肿瘤的影像,或某商户类别的交易记录。应用方向包括定向数据增强、场景模拟、受控合成实验。
潜在空间操作与可解释性
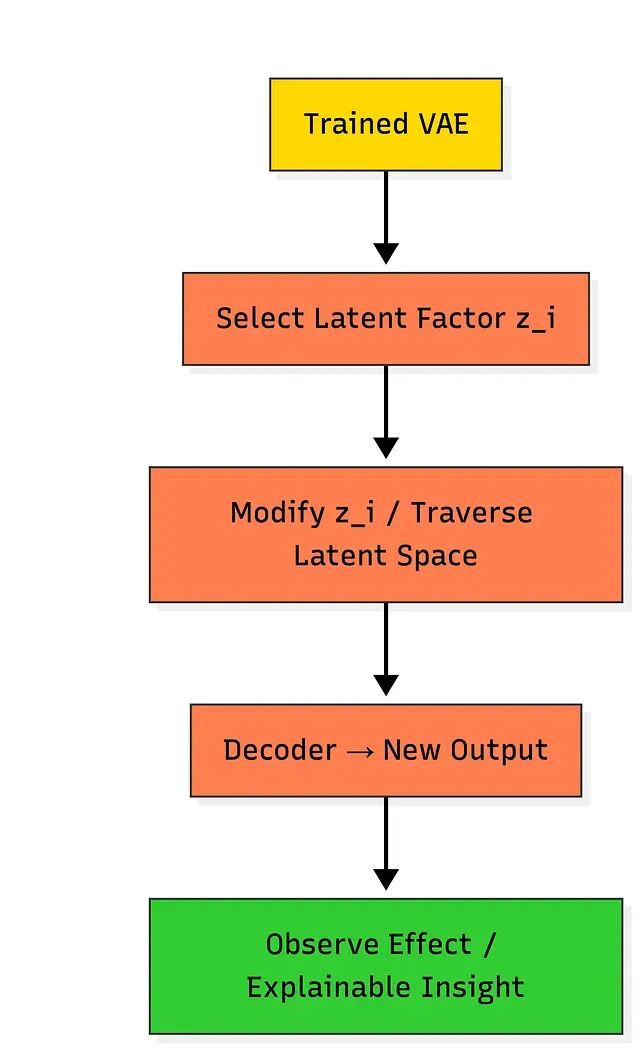
对潜在空间做分析和修改,可以观察输出如何随之变化。潜在遍历——固定其余维度、单独改变一个维度——能揭示各因子的语义含义;潜在空间本身也可用于聚类。一个具体的例子:在机械传感器数据中,某个潜在因子可能对应振动频率,调整它就能模拟机器提速后的状态。这类操作在可解释性分析、根因定位和场景规划中都有用处。
数据填补与重建
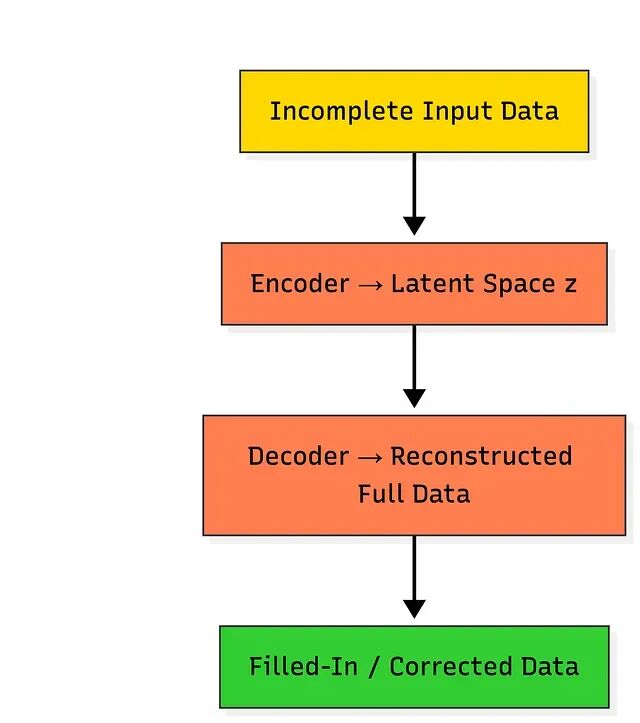
训练好的 VAE 可以处理不完整输入——编码后在潜在空间中采样,再解码出完整的重建,从而填补缺失数据。典型场景有数据清洗、预处理和错误修正,比如补全图像中的缺失像素、物联网数据中丢失的传感器读数,或者残缺不全的交易记录。
总结
VAE模型要做的核心决策是:哪些信息值得保留,哪些可以丢弃。理清这一点之后数学只是执行层面的工具,不再是障碍。
一个经过良好训练的 VAE 产出的不只是重建结果,它提供了一个观察数据行为的视角——数据在哪里偏离,复杂系统如何被压缩进一个紧凑且可解读的表示里。本系列的下一篇将聚焦 VAE 在异常检测中的实际应用。
by Ayo Akinkugbe