
过去2年,整个行业仿佛陷入了一场参数竞赛,每一次模型发布的叙事如出一辙:“我们堆了更多 GPU,用了更多数据,现在的模型是 1750 亿参数,而不是之前的 1000 亿。”
这种惯性思维让人误以为智能只能在训练阶段“烘焙”定型,一旦模型封装发布,能力天花板就被焊死了。
但到了 2025 年,这个假设彻底被打破了。
先是 DeepSeek-R1 证明了只要给予思考时间,Open-weights 模型也能展现出惊人的推理能力。紧接着 OpenAI o3 登场,通过在单个问题上消耗分钟级而非毫秒级的时间,横扫了各大基准测试。
大家突然意识到我们一直优化错了变量。技术突破点不在于把模型做得更大,而在于让模型在输出结果前学会暂停、思考和验证。
这就是 Test-Time Compute(测试时计算),继 Transformer 之后,数据科学领域最重要的一次架构级范式转移。
推理侧 Scaling Law:比 GPT-4 更深远的影响
以前我们奉 Chinchilla Scaling Laws 为圭臬,认为性能严格受限于训练预算。但新的研究表明,Inference Scaling(训练后的计算投入)遵循着一套独立的、往往更为陡峭的幂律曲线。
几项关键研究数据揭示了这一趋势:
arXiv:2408.03314 指出,优化 LLM 的测试时计算往往比单纯扩展参数更有效。一个允许“思考” 10 秒的小模型,其实际表现完全可以碾压一个瞬间给出答案但规模大 14 倍的巨型模型。
实战数据也印证了这一点。2025 年 1 月发布的 DeepSeek-R1,其纯强化学习版本在 AIME 数学基准测试中,仅通过学习自我验证(Self-Verify),得分就从 15.6% 暴涨至 71.0%;引入 Majority Voting(多数投票)机制后,更是飙升至 86.7%。到了 4 月,OpenAI o3 在 AIME 上更是达到了惊人的 96.7%,在 Frontier Math 上拿到 25.2%,但代价是处理每个复杂任务的成本超过 $1.00。
结论很明显:在推理阶段投入算力的回报率,正在超越训练阶段。
新的“思考”格局
到了 2025 年底,OpenAI 不再是唯一的玩家,技术路径已经分化为三种。
这里需要泼一盆冷水:Google 的 Gemini 2.5 Flash Thinking 虽然展示了透明的推理过程,但当我让它数“strawberry”里有几个 R 时,它自信满满地列出逻辑,最后得出结论——两个。这说明展示过程不等于结果正确,透明度固然好,但没有验证闭环(Verification Loop)依然是徒劳。
在效率方面,DeepSeek-R1 的架构设计值得玩味。虽然它是一个拥有 6710 亿参数的庞然大物,但得益于 Mixture-of-Experts (MoE) 技术,每次推理仅激活约 370 亿参数。这好比一个存有 600 种工具的巨型车间,工匠干活时只取当下最顺手的 3 件。这种机制让它的成本比 o1 低了 95% 却保持了高密度的推理能力。正是这种 MoE 带来的经济性,才让超大模型跑复杂的多步 Test-Time Compute 循环在商业上变得可行。
现成的工程模式:Best-of-N with Verification
搞 Test-Time Compute 不需要千万美元的训练预算,甚至不需要 o3 的权重。其核心架构非常简单,普通开发者完全可以复刻。
核心就三步:
- Divergent Generation(发散生成): 提高 Temperature,让模型对同一问题生成 N 种不同的推理路径。
- Self-Verification(自我验证): 用模型自身(或更强的 Verifier)去批判每一个方案。
- Selection(择优): 选出置信度最高的答案。
学术界称之为 Best-of-N with Verification,这与论文 [s1: Simple test-time scaling (arXiv:2501.19393)] 的理论高度吻合。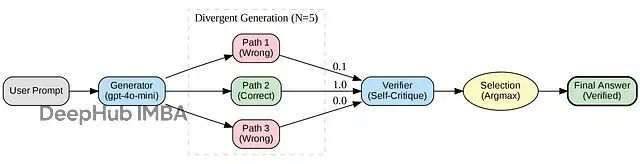
你只需要任何一个主流 LLM API(OpenAI, DeepSeek, Llama 3 均可)、几分钱的额度和一个简单的 Python 脚本。
代码实现如下:
import os
import numpy as np
from typing import List
from pydantic import BaseModel, Field
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define structure for "System 2" thinking
class StepValidation(BaseModel):
is_correct: bool = Field(description="Does the solution logically satisfy ALL constraints?")
confidence_score: float = Field(description="0.0 to 1.0 confidence score")
critique: str = Field(description="Brief analysis of potential logic gaps or missed constraints")
# 2. Divergent Thinking (Generate)
def generate_candidates(prompt: str, n: int = 5) -> List[str]:
"""Generates N distinct solution paths using high temperature."""
candidates = []
print(f"Generating {n} candidate solutions with gpt-4o-mini...")
for _ in range(n):
response = client.chat.completions.create(
model="gpt-4o-mini", # Small, fast generator
messages=[
{"role": "system", "content": "You are a thoughtful problem solver. Show your work step by step."},
{"role": "user", "content": prompt}
],
temperature=0.8 # High temp for diverse reasoning paths
)
candidates.append(response.choices[0].message.content)
return candidates
# 3. Convergent Thinking (Verify)
def verify_candidate(problem: str, candidate: str) -> float:
"""
Uses the SAME small model to critique its own work.
This proves that 'time to think' > 'model size'.
"""
verification_prompt = f"""
You are a strict logic reviewer.
Review the solution below for logical fallacies or missed constraints.
PROBLEM: {problem}
PROPOSED SOLUTION:
{candidate}
Check your work. Does the solution actually fit the constraints?
Rate the confidence from 0.0 (Wrong) to 1.0 (Correct).
"""
response = client.beta.chat.completions.parse(
model="gpt-4o-mini", # Using the small model as a Verifier
messages=[{"role": "user", "content": verification_prompt}],
response_format=StepValidation
)
return response.choices[0].message.parsed.confidence_score
# 4. Main loop
def system2_solve(prompt: str, effort_level: int = 5):
print(f"System 2 Activated: Effort Level {effort_level}")
candidates = generate_candidates(prompt, n=effort_level)
scores = []
for i, cand in enumerate(candidates):
score = verify_candidate(prompt, cand)
scores.append(score)
print(f" Path #{i+1} Confidence: {score:.2f}")
best_index = np.argmax(scores)
print(f"Selected Path #{best_index+1} with confidence {scores[best_index]}")
return candidates[best_index]
# 5. Execute
if __name__ == "__main__":
# The "Cognitive Reflection Test" (Cyberpunk Edition)
# System 1 instinct: 500 credits (WRONG)
# System 2 logic: 250 credits (CORRECT)
problem = """
A corporate server rack and a cooling unit cost 2500 credits in total.
The server rack costs 2000 credits more than the cooling unit.
How much does the cooling unit cost?
"""
answer = system2_solve(problem, effort_level=5) # Increased effort to catch more failures
print("\nFINAL ANSWER:\n", answer)
实测案例:“服务器机架”陷阱
我在认知反射测试(Cognitive Reflection Test)的一个变体上跑了这个脚本。这是一种专门设计用来诱导大脑(和 AI)做出快速错误判断的逻辑题。
题目是:“总价 2500,机架比冷却单元贵 2000,冷却单元多少钱?”System 1(直觉) 几乎总是脱口而出 500(因为 2500-2000=500)。System 2(逻辑) 才会算出 250(x + x + 2000 = 2500)。
运行结果非常典型:
System 2 Activated: Effort Level 5
Generating 5 candidate solutions...
Path [#1](#1) Confidence: 0.10 <-- Model fell for the trap (500 credits)
Path [#2](#2) Confidence: 1.00 <-- Model derived the math (250 credits)
Path [#3](#3) Confidence: 0.00 <-- Model fell for the trap
...
Selected Path [#2](#2) with confidence 1.0
注意
Path [#1](#1)
。在常规应用中,用户直接拿到的就是这个 500 credits(错误) 的答案。通过生成 5 条路径,我们发现 40% 的结果都掉进了陷阱。但关键在于,作为验证者的同一个小模型,成功识别了逻辑漏洞,并将包含正确推导的
Path [#2](#2)
捞了出来。
仅仅是“多想一会儿”,一个可靠性 60% 的模型就被强行拉到了 100%。
算力经济账
这肯定更贵。但值不值?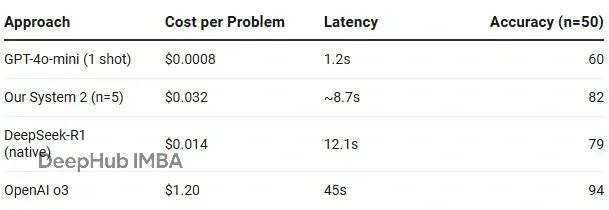
我的实验成本确实增加了 40 倍,但别忘了绝对值只有 3 美分。这 3 美分换来的是 22% 的准确率提升。如果你在做医疗推理或生产环境 Debug,这简直是白菜价;如果你只是做个闲聊机器人,那确实是贵了。
新的模型:Inference Budget
展望 2026 年,架构讨论的焦点将从“谁的模型更聪明”转移到“我们的推理预算(Inference Budget)是多少”。
未来的决策可能会变成这样:
- **System 1 (Standard API)**:延迟要求 < 2秒,或者搞搞创意写作。
- **System 2 (DeepSeek-R1 / o3)**:准确性至上(数学、代码、逻辑),且能容忍 10-30 秒的延迟。
- **System 3 (Custom Loops)**:需要形式化保证,必须依赖多 Agent 投票和验证的关键决策。
建议大家把上面的代码拷下来跑一跑,找一个你现在的 LLM 经常翻车的逻辑题或冷门 Bug 试一下,看着它实时自我修正。
你会发现,我们不该再把 LLM 当作“神谕(Oracle)”,而应将其视为预算可配置的“推理引擎”。懂 Inference-time compute 的数据科学家,才是 2026 年定义下一代 AI 产品的人。
相关阅读:
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (arXiv:2408.03314).
- s1: Simple test-time scaling (arXiv:2501.19393).
- DeepSeek AI (2025) — DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(arXiv:2501.12948).
作者:Cagatay Akcam