
机器学习模型处理不了原始文本。无论是线性回归、XGBoost还是神经网络,遇到
"red"
、
"medium"
、
"CA"
这类分类变量都没法直接处理。所以必须把它们转成数字这个过程就是分类编码。
大家入门时肯定都学过独热编码或序数编码,但编码方法其实非常多。目标编码、CatBoost编码、James-Stein编码这些高级技术,用对了能给模型带来质的飞跃,尤其面对高基数特征的时候。
编码到底有多重要
拿
"Toyota"
举例,它本身没有数值含义,但模型只认数字:
{"Toyota": 0, "Ford": 1, "Honda": 2}
或者写成向量形式:
[0, 1, 0]
更高级的做法是直接编码成目标相关的数值:
Toyota → +0.12 mean adjusted uplift in target
编码方式选得好不好,直接影响模型准确率、可解释性、过拟合程度、训练速度、内存占用,还有对稀有类别的处理能力。
示例代码准备
后面所有例子都基于这个简单数据集:
import pandas as pd
from sklearn.model_selection import train_test_split
import category_encoders as ce
from sklearn.linear_model import LogisticRegression
df = pd.DataFrame({
"color": ["red", "blue", "green", "green", "blue", "red"],
"city": ["NY", "LA", "NY", "SF", "LA", "NY"],
"target": [1, 0, 1, 0, 0, 1]
})
X = df.drop("target", axis=1)
y = df["target"]
1、序数编码 Ordinal Encoding
最简单粗暴的方法,给每个类别分配一个整数。red是0,blue是1,green是2。
XGBoost、LightGBM这类树模型用这个就够了。另外当类别本身有顺序含义(比如small/medium/large)时也很合适。
encoder=ce.OrdinalEncoder(cols=["color"])
X_trans=encoder.fit_transform(X, y)
2、独热编码 One-Hot Encoding
每个类别单独开一列,是就标1,不是就标0。
线性回归、逻辑回归、神经网络经常用这个。不过类别太多的话列数会爆炸,低基数特征才适合。
encoder=ce.OneHotEncoder(cols=["color"], use_cat_names=True)
X_trans=encoder.fit_transform(X)
3、 二进制编码 Binary Encoding
把类别索引转成二进制。比如索引5变成101,拆成三列。
这个方法在类别数量中等偏多(50-500个)的时候很好使,既保持了稀疏性又比独热编码省内存。
encoder=ce.BinaryEncoder(cols=["city"])
X_trans=encoder.fit_transform(X)
4、Base-N编码
二进制编码的泛化版本,可以用任意进制。base=3时,索引5就变成
"12"
。想精细控制输出维度的话可以试试。
encoder=ce.BaseNEncoder(cols=["city"], base=3)
X_trans=encoder.fit_transform(X)
5、哈希编码 Hashing Encoding
用哈希函数把类别映射到固定数量的列上。速度极快,输出宽度固定,也不用存储类别映射表。
缺点就是:会有哈希冲突而且结果不可解释。
encoder=ce.HashingEncoder(cols=["city"], n_components=8)
X_trans=encoder.fit_transform(X)
6、Helmert编码
正交对比编码的一种,每个类别跟它后面所有类别的均值做比较。统计建模和分类对比回归分析会用到。
encoder=ce.HelmertEncoder(cols=["color"])
X_trans=encoder.fit_transform(X, y)
7、求和编码 Sum Encoding
也叫偏差编码。每个类别跟总体均值比较,而不是跟某个基准类别比。
encoder=ce.SumEncoder(cols=["color"])
X_trans=encoder.fit_transform(X, y)
8、多项式编码 Polynomial Encoding
给有序类别生成线性、二次、三次对比项。如果怀疑类别对目标有非线性影响,可以考虑这个。
encoder=ce.PolynomialEncoder(cols=["color"])
X_trans=encoder.fit_transform(X, y)
9、向后差分编码 Backward Difference Encoding
每个类别跟前面所有类别的均值比较,跟Helmert正好相反。
encoder=ce.BackwardDifferenceEncoder(cols=["color"])
X_trans=encoder.fit_transform(X, y)
10、计数编码 Count Encoding
直接用类别出现的次数替换类别值。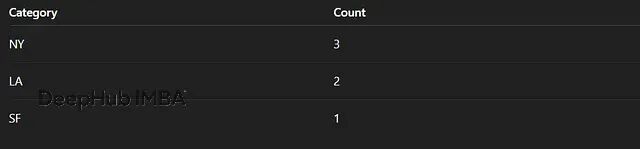
高基数特征用这个效果不错,计算快、结果稳定。只要在训练集上fit就不会有数据泄露问题。
encoder=ce.CountEncoder(cols=["city"])
X_trans=encoder.fit_transform(X)
11. 目标编码 Target Encoding
把每个类别替换成该类别下目标变量的均值。
威力很大但有个坑,就是容易造成目标泄露。必须配合平滑处理或者用交叉验证的方式来做。
encoder = ce.TargetEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
12、CatBoost编码
CatBoost编码是目标编码的改良版。编码每一行时只用它前面的行来计算,这样就大大降低了泄露风险。
这是目前最安全的目标编码方案,高基数特征、时序数据都能用,效果很稳。
encoder = ce.CatBoostEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
13、留一法编码 Leave-One-Out Encoding
计算类别的目标均值时把当前行排除掉。既保留了目标编码的效果,又减轻了泄露。
encoder = ce.LeaveOneOutEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
14、M估计编码 M-Estimate Encoding
用贝叶斯思想对目标编码做平滑。
高基数和噪声目标场景下表现不错。
encoder = ce.MEstimateEncoder(cols=["city"], m=5)
X_trans = encoder.fit_transform(X, y)
15、WOE证据权重编码
这是信用评分领域的老朋友了。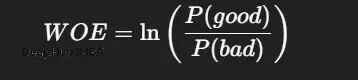
逻辑回归配WOE是经典组合,可解释性很强。
encoder = ce.WOEEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
16、James-Stein编码
基于James-Stein估计的收缩编码器。能有效降低方差,做分类变量回归时效果很好。
encoder = ce.JamesSteinEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
17、GLMM编码
用广义线性混合模型来编码。处理层次结构数据或者类别组很大的时候可以一试。
encoder = ce.GLMMEncoder(cols=["city"])
X_trans = encoder.fit_transform(X, y)
18、分位数编码 Quantile Encoding
不用均值,用目标分布的分位数来编码。
encoder = ce.QuantileEncoder(cols=["city"], quantile=0.5)
X_trans = encoder.fit_transform(X, y)
19、RankHot编码
独热编码的变体,列按类别频率排序。对树模型友好。
encoder = ce.RankHotEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
20、格雷编码 Gray Encoding
用格雷码表示类别,相邻编码只差一位。
encoder = ce.GrayEncoder(cols=["city"])
X_trans = encoder.fit_transform(X)
怎么选编码器
低基数(<10个类别):独热、二进制、序数都行。统计模型的话可以试试求和、Helmert、多项式编码。
中等基数(10-100):二进制、BaseN、CatBoost、带平滑的目标编码。
高基数(100-50000):计数编码、CatBoost编码(首选)、留一法、M估计、带交叉验证的目标编码,内存紧张就用哈希编码。
常见的坑
目标编码泄露:用CatBoost编码、交叉验证或留一法来规避。
树模型误读序数整数:树模型可能会把序数编码的数字当连续变量处理,换成独热或目标编码更稳妥。
独热编码维度爆炸:类别太多就别用独热了,换二进制、BaseN或哈希。
稀有类别噪声:M估计、James-Stein或目标平滑能缓解这个问题。
总结
分类编码是特征工程里最容易被忽视却又最能出效果的环节。scikit-learn自带的编码器只是冰山一角,
category_encoders
这个库才是真正的百宝箱:统计编码、贝叶斯编码、哈希编码、对比编码应有尽有,用好了模型效果能上一个台阶。
作者:Abish Pius