
Kafka消息中间件
官网:https://kafka.apache.org/
docker安装kafka教程:https://bugstack.cn/md/road-map/kafka.html
Kafka的几个概念
生产者Producer
消费者Consumer
主题Topic
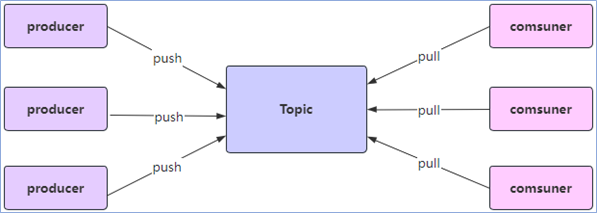
分区Partition
一个topic下可以有多个分区。当创建topic时,如果补置顶该topic的partition数量,那么默认就是1个partition。
偏移量Offset
标识每个分区中消息的唯一为止,从0开始。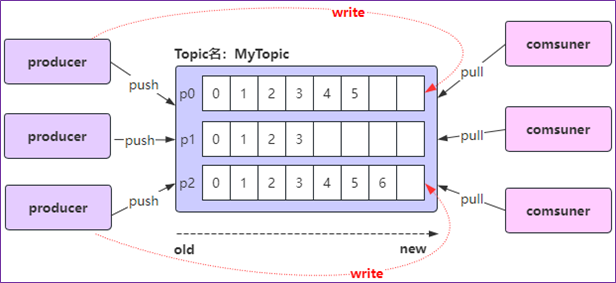
SpringBoot集成Kafka开发
依赖配置:
<!--kafka依赖,不是starter依赖--><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
配文件:
- 服务器连接
spring:application:# 应用名称 name: spring-boot-01-kafka-base
# kafka连接地址 (ip + port) kafka:bootstrap-servers: 10.15.15.201:9092
- 生产者 (KafkaProperties) 属性如下:
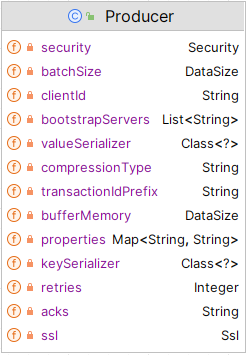
- 消费者 (KafkaProperties) 属性如下:

写代码:
- 生产者(写入事件):
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent(){
kafkaTemplate.send("hello-topic","hello kafka");}}
- 消费者(读取事件): 默认读的是最新的数据
@ComponentpublicclassEventConsumer{// 采用监听的方式接收事件 (消息、数据) @KafkaListener(topics ="hello-topic", groupId ="hello-group")publicvoidonEvent(String event){System.out.println("读取到的事件:"+ event);}}
去运行:
- 生产者发送事件Event(消息、数据)
@SpringBootTestclassSpringBoot01KafkaBaseApplicationTests{@ResourceprivateEventProducer eventProducer;@Testvoidtest01(){
eventProducer.sendEvent();}}
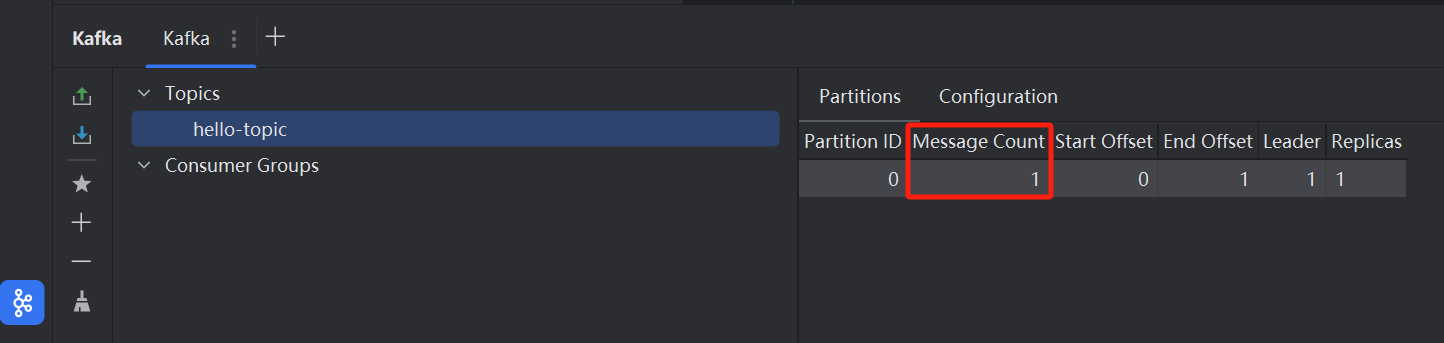
- 消费者接收事件Event(消息、数据)
读取最早的消息
默认情况下,当启动一个新的消费组时,它会从每个分区的最新偏移量(即该分区中最后一条消息的下一个位置)开始消费。如果希望从第一条消息开始消费,需要设置消费者的
auto.offset.reset
设置为
earliest
。
spring:kafka:consumer:auto-offset-reset: earliest
取值:
earliest
、
latest
、
none
、
exception
- earliest:自动将偏移量重置为最早的偏移量
- latest:自动将偏移量重置为最新的偏移量
- none:如果没有为消费者组找到以前的偏移量,则向消费者抛出异常
- exception:向消费者抛出异常。(spring-kafka不支持)

注意:
如果之前已经用相同的消费者组ID消费过该主题,并且kafka已经保存了该消费者组的偏移量,那么即使你设置了
auto.offset.reset=earliest
,该设置也不会生效,因为kafka只会在找不到偏移量时使用这个配置。在这种情况下,你需要手动重置偏移量或使用一个新的消费者组ID。
spring-kafka生产者发送消息
生产者客户端向kafka的主题topic中写入事件

- 发送Message对象
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent(){// 通过建造者模式创建Message对象 Message<String> message =MessageBuilder.withPayload("hello kafka").setHeader(KafkaHeaders.TOPIC,"test-topic")// 在header中放置topic的名字 .build();
kafkaTemplate.send(message);}}
- 发送ProduceRecord对象
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent(){// Headers里面是放一些信息(key-value键值对),到时候消费者接收到该消息后,可以拿到Headers里面放的信息 Headers headers =newRecordHeaders();
headers.add("phone","15349850538".getBytes(StandardCharsets.UTF_8));
headers.add("orderId","0D1234523452345".getBytes(StandardCharsets.UTF_8));ProducerRecord<String,String>record=newProducerRecord<>("test-topic",0,System.currentTimeMillis(),"k1","hello kafka", headers
);
kafkaTemplate.send(record);}}
- 发送指定分区的消息
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent4(){// String topic, Integer partition, Long timestamp, K key, V data
kafkaTemplate.send("test-topic",0,System.currentTimeMillis(),"k2","hello kafka");}}
- 发送默认topic消息
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent(){// Integer partition, Long timestamp, K key, V data
kafkaTemplate.sendDefault(0,System.currentTimeMillis(),"k3","hello kafka");}}
同时还需要在application.yml中配置默认topic
spring:kafka:# 配置模板默认的主题topic名称 template:default-topic: default-topic
获取生产者消息发送结果
.send()方法和.sendDefault()方法都返回CompletableFuture<SendResult<K, V>>;CompletableFuture是Java 8中引入的一个类,用于异步编程,它表示一个异步计算的结果,这个特性使得调用者不必等待操作完成就能继续执行其他任务,从而提高了应用程序的响应速度和吞吐量- 使用
CompletableFuture,.send()方法可以立即返回一个表示异步操作结果的未来对象,而不是等待操作完成,这样,调用线程可以继续执行其他任务,而不必等待消息发送完成。当消息发送完成时(无论是成功还是失败),CompletableFuture会相应地更新其状态,并允许我们通过回调、阻塞等方式来获取操作结果; - 方法一:调用
CompletableFuture的get()方法,同步阻塞等待发送结果
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsExecutionException,InterruptedException{// Integer partition, Long timestamp, K key, V data CompletableFuture<SendResult<String,String>> completableFuture
= kafkaTemplate.sendDefault(0,System.currentTimeMillis(),"k3","hello kafka");// 怎么拿到结果,通过CompletableFuture这个类拿结果,这个类里面有很多方法 // 1. 阻塞等待的方式拿结果 SendResult<String,String> sendResult = completableFuture.get();if(sendResult.getRecordMetadata()!=null){// 此时kafka这个服务器确认接收到了这个消息 System.out.println("消息发送成功:"+ sendResult.getRecordMetadata().toString());}System.out.println("producerRecord:"+ sendResult.getProducerRecord());}}
- 方法二:使用
thenAccept(), thenApply(), thenRun()等方法来注册回调函数,回调函数将在CompeletableFuture完成时被执行
@ComponentpublicclassEventProducer{// 加入spring-kafka依赖 + .yml配置信息,Springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent7(){// Integer partition, Long timestamp, K key, V data CompletableFuture<SendResult<String,String>> completableFuture
= kafkaTemplate.sendDefault(0,System.currentTimeMillis(),"k3","hello kafka");// 怎么拿到结果,通过CompletableFuture这个类拿结果,这个类里面有很多方法 // 2. 非阻塞的方式拿结果
completableFuture.thenAccept((sendResult)->{if(sendResult.getRecordMetadata()!=null){// 此时kafka这个服务器确认接收到了这个消息 System.out.println("消息发送成功:"+ sendResult.getRecordMetadata().toString());}System.out.println("producerRecord:"+ sendResult.getProducerRecord());}).exceptionally((exception)->{
exception.printStackTrace();// 做失败的处理 returnnull;});}}
生产者发送对象消息
- 注入kafkaTemplate,记得修改K V
@ResourceprivateKafkaTemplate<Object,Object> template;
- 发送消息代码
@Data@Builder@AllArgsConstructor@NoArgsConstructorpublicclassUser{privateint id;privateString phone;privateDate birthDay;}
publicvoidsendEvent(){User user =User.builder().id(1).phone("15349850538").birthDay(newDate()).build();// 分区为null,则让kafka自己去决定把消息发送哪个分区
template.sendDefault(null,System.currentTimeMillis(),"k3", user);}
- 配置application.yml,指定消息key和消息value的编码(序列化)方式
spring:kafka:bootstrap-servers: 192.168.237.105:9092# 配置生产者 (有24个配置) producer:# 默认是StringSerializer.class序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
kafka核心概念:Replica副本
- Replica:副本,为实现备份功能,保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且 Kafka仍然能够继续工作,Kafka提供了副本机制,一个topic的每个分区都有1个或多个副本;
- Replica副本分为Leader Replica和Follower Replica: - Leader:每个分区多个副本中的“主”副本,生产者发送数据以及消费者消费数据,都是来自leader副本;- Follower:每个分区多个副本中的“从”副本,实时从leader副本中同步数据,保持和leader副本数据的同步,leader副本发生故障时,某个follower副本会成为新的leader副本;
- 设置副本个数不能为0,也不能大于节点个数,否则将不能创建Topic;
指定topic的分区和副本
执行代码时指定分区和副本
kafkaTemplate.send("topic", message);- 直接使用send()方法发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有一个分区,分区有1个副本,也就是有它自己本身的副本,没有额外的副本备份;
- 我们可以在项目中新建一个配置类专门用来初始化topic;
@ConfigurationpublicclassKafkaConfig{@BeanpublicNewTopicnewTopic(){// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1 returnnewNewTopic("heTopic",5,(short)1);}// 对topic进行更新 @BeanpublicNewTopicupdateNewTopic(){// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1// 如果要修改分区数,只需修改配置值重启项目即可,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小returnnewNewTopic("heTopic",9,(short)1);}}
生产者发送对象消息的分区策略
消息发送到哪个分区?是什么策略?
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中;
- 默认分配策略:BuiltInPartitioner - 有key:Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;- 没有key:是使用随机数 % numPartitions
- 轮询分配策略:RoundRobinPartitioner (接口:Partitioner)
- 自定义分配策略:我们自己定义
指定生产者写入消息到topic时的分配策略:
- 轮询分配策略:RoundRobinPartitioner (接口:Partitioner)
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.producer.key-serializer}")privateString keySerializer;@Value("${spring.kafka.producer.value-serializer}")privateString valueSerializer;/**
* 生产者创建工厂
* @return
*/publicProducerFactory<String,?>producerFactory(){returnnewDefaultKafkaProducerFactory<>(producerConfigs());}/**
* 生产者相关配置
* @return
*/publicMap<String,Object>producerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,RoundRobinPartitioner.class);return props;}/**
* kafkaTemplate 覆盖默认配置类中的kafkaTemplate
* @return */@BeanpublicKafkaTemplate<String,?>kafkaTemplate(){returnnewKafkaTemplate<>(producerFactory());}}
- 自定义分配策略:XxxPartitioner (接口:Partitioner)
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.producer.key-serializer}")privateString keySerializer;@Value("${spring.kafka.producer.value-serializer}")privateString valueSerializer;/**
* 生产者创建工厂
* @return
*/publicProducerFactory<String,?>producerFactory(){returnnewDefaultKafkaProducerFactory<>(producerConfigs());}/**
* 生产者相关配置
* @return
*/publicMap<String,Object>producerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,CustomerPartitionerConfig.class);return props;}/**
* kafkaTemplate 覆盖默认配置类中的kafkaTemplate
* @return */@BeanpublicKafkaTemplate<String,?>kafkaTemplate(){returnnewKafkaTemplate<>(producerFactory());}}
publicclassCustomerPartitionerConfigimplementsPartitioner{privateAtomicInteger nextPartition =newAtomicInteger(0);@Overridepublicintpartition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,Cluster cluster){List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if(key ==null){// 使用轮询方式选择分区 int next = nextPartition.getAndIncrement();if(next >= numPartitions){
nextPartition.compareAndSet(next,0);}System.out.println("分区值:"+ next);return next;}else{// 如果key不为null,则使用默认的分区策略 returnUtils.toPositive(Utils.murmur2(keyBytes))% numPartitions;}}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> configs){}}
生产者发送消息流程
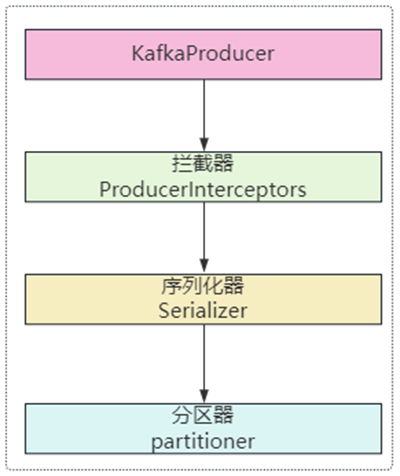
拦截生产者发送的消息
- 自定义拦截器拦截消息的发送;
- 实现
ProducerInterceptor<K, V>接口;
publicclassCustomerProducerInterceptorimplementsProducerInterceptor<String,Object>{/**
* 发送消息时,会先调用该方法,对消息进行拦截,可以在拦截中对消息进行处理,如记录日志等操作
* @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.
* @return */@OverridepublicProducerRecord<String,Object>onSend(ProducerRecordrecord){System.out.println("拦截消息:"+record.toString());returnrecord;}/**
* 服务器收到消息后的一个确认
* @param metadata The metadata for the record that was sent (i.e. the partition and offset).
* If an error occurred, metadata will contain only valid topic and maybe * partition. If partition is not given in ProducerRecord and an error occurs * before partition gets assigned, then partition will be set to RecordMetadata.NO_PARTITION. * The metadata may be null if the client passed null record to * {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)}.
* @param exception The exception thrown during processing of this record. Null if no error occurred.
*/@OverridepublicvoidonAcknowledgement(RecordMetadata metadata,Exception exception){if(null!= metadata){System.out.println("服务器收到了该消息:"+ metadata.offset());}else{System.out.println("消息发送失败了, exception = "+ exception.getMessage());}}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> configs){}}
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.producer.key-serializer}")privateString keySerializer;@Value("${spring.kafka.producer.value-serializer}")privateString valueSerializer;/**
* 生产者创建工厂
* @return
*/publicProducerFactory<String,?>producerFactory(){returnnewDefaultKafkaProducerFactory<>(producerConfigs());}/**
* 生产者相关配置
* @return
*/publicMap<String,Object>producerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,CustomerPartitionerConfig.class);// 添加一个拦截器
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,CustomerProducerInterceptor.class.getName());return props;}/**
* kafkaTemplate 覆盖默认配置类中的kafkaTemplate
* @return
*/@BeanpublicKafkaTemplate<String,?>kafkaTemplate(){returnnewKafkaTemplate<>(producerFactory());}}
获取生产者发送的消息
获取生产者发送的字符串消息
@ComponentpublicclassEventConsumer{// 采用监听的方式接收事件 (消息、数据) @KafkaListener(topics ="helloTopic", groupId ="helloGroup")publicvoidonEvent(@PayloadString event,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition){System.out.println("读取到的事件:"+ event +", topic : "+ topic +", partition: "+ partition);}}
注解:
@Payload:标记该参数是消息体的内容@Header:标记该参数是消息头的内容
@ComponentpublicclassEventConsumer{// 采用监听的方式接收事件 (消息、数据) @KafkaListener(topics ="helloTopic", groupId ="helloGroup")publicvoidonEvent(@PayloadString event,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition,ConsumerRecord<String,String>record){System.out.println("读取到的事件:"+ event +", topic : "+ topic +", partition: "+ partition);System.out.println("读取到的事件:"+record.toString());}}
获取生产者发送的对象消息
需要将对象转换成JSON数据,否则会报包不被信任的异常。
publicclassJSONUtils{// 创建对象映射工具类 privatestaticfinalObjectMapper OBJECT_MAPPER =newObjectMapper();/**
* 将对象转换成JSON
* @param object
* @return
* @throws JsonProcessingException
*/publicstaticStringtoJSON(Object object)throwsJsonProcessingException{// 把对象以字符串的形式写出去,就变成了json return OBJECT_MAPPER.writeValueAsString(object);}/**
* 将JSON转换成对象
* @param json
* @param clazz
* @return
* @param <T>
* @throws JsonProcessingException
*/publicstatic<T>TtoBean(String json,Class<T> clazz)throwsJsonProcessingException{return OBJECT_MAPPER.readValue(json, clazz);}}
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{User user =User.builder().id(1209).phone("1235324234").birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("helloTopic", userJSON);}}
@ComponentpublicclassEventConsumer{@KafkaListener(topics ="helloTopic", groupId ="helloGroup")publicvoidonEvent(String userJSON,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition,ConsumerRecord<String,String>record)throwsJsonProcessingException{User user =JSONUtils.toBean(userJSON,User.class);System.out.println("读取到的事件:"+ user +", topic : "+ topic +", partition: "+ partition);System.out.println("读取到的事件:"+record.toString());}}
通过占位符接收消息
@ComponentpublicclassEventConsumer{@KafkaListener(topics ="${kafka.topic.name}", groupId ="${kafka.consumer.group}")publicvoidonEvent(String userJSON,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition,ConsumerRecord<String,String>record)throwsJsonProcessingException{User user =JSONUtils.toBean(userJSON,User.class);System.out.println("读取到的事件:"+ user +", topic : "+ topic +", partition: "+ partition);System.out.println("读取到的事件:"+record.toString());}}
# 自定义配置,不是框架提供的 kafka:topic:name: helloTopic
consumer:group: helloGroup
手动消息确认
@ComponentpublicclassEventConsumer{// 采用监听的方式接收事件 (消息、数据) @KafkaListener(topics ="${kafka.topic.name}", groupId ="${kafka.consumer.group}")publicvoidonEvent(String userJSON,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition,ConsumerRecord<String,String>record,Acknowledgment ack)throwsJsonProcessingException{User user =JSONUtils.toBean(userJSON,User.class);System.out.println("读取到的事件:"+ user +", topic : "+ topic +", partition: "+ partition);System.out.println("读取到的事件:"+record.toString());
ack.acknowledge();// 手动确认消息,告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认 }}
spring:# kafka连接地址 (ip + port) kafka:bootstrap-servers: 192.168.237.105:9092# 配置消息监听器 listener:# 开启消息监听的手动确认模式 ack-mode: manual
默认情况下,Kafka消费者消费消息后会自动发送确认信息给Kafka服务器,表示消息已经被成功消费。但在某些场景下,我们希望在消息处理成功后再发送确认,或者在消息处理失败时选择不发送确认,以便Kafka能够重新发送该消息;
指定topic、partition、offset消费
@ComponentpublicclassEventConsumer{@KafkaListener(groupId ="${kafka.consumer.group}", topicPartitions ={@TopicPartition(
topic ="${kafka.topic.name}",
partitions ={"0","1","2"},
partitionOffsets ={@PartitionOffset(partition ="3", initialOffset ="3"),@PartitionOffset(partition ="4", initialOffset ="3")})})publicvoidonEvent(String userJSON,@Header(value =KafkaHeaders.RECEIVED_TOPIC)String topic,@Header(value =KafkaHeaders.RECEIVED_PARTITION)String partition,ConsumerRecord<String,String>record,Acknowledgment ack){try{// 收到消息后,处理业务 User user =JSONUtils.toBean(userJSON,User.class);System.out.println("读取到的事件:"+ user +", topic : "+ topic +", partition: "+ partition);System.out.println("读取到的事件:"+record.toString());// 业务处理完成,给kafka服务器确认
ack.acknowledge();// 手动确认消息,告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认 }catch(Exception e){
e.printStackTrace();}}}
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{for(int i =0; i <25; i++){User user =User.builder().id(i).phone("1235324234"+ i).birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("helloTopic","k"+ i, userJSON);}}}
@ConfigurationpublicclassKafkaConfig{@BeanpublicNewTopicnewTopic(){// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1 returnnewNewTopic("helloTopic",5,(short)1);}}
消费者批量消费消息
- 设置application.properties开启批量消费;
spring:application:# 应用名称 name: spring-boot-03-kafka-base
# kafka连接地址 (ip + port) kafka: bootstrap-servers: 192.168.237.105:9092# 配置消息监听器 listener:# 设置批量消费,默认是单个消息消费 type: batch
consumer:# 批量消费每次最多消费多少条消息 max-poll-records:20# 从第一条消息开始接收 auto-offset-reset: earliest
- 接收消息时用LIst来接收
@ComponentpublicclassEventConsumer{@KafkaListener(topics ={"batchTopic"}, groupId ="batchGroup2")publicvoidonEvent(List<ConsumerRecord<String,String>> records){System.out.println("批量消费,records.size() = "+ records.size()+",records = "+ records);}}
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{for(int i =0; i <125; i++){User user =User.builder().id(i).phone("1235324234"+ i).birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("batchTopic","k"+ i, userJSON);}}}
消费消息时的消息拦截
在消息消费之前,我们可以通过配置拦截器对消息进行拦截,在消息被实际处理之前对其进行一些操作,例如记录日志、修改消息内容或执行一些安全检查等;
- 实现kafka的ConsumerInterceptor拦截器接口
/**
* 自定义的消费者拦截器
*/publicclassCustomerConsumerInterceptorimplementsConsumerInterceptor<String,String>{/**
* 在消费消息之前执行
*
* @param records records to be consumed by the client or records returned by the previous interceptors in the list.
* @return
*/@OverridepublicConsumerRecords<String,String>onConsume(ConsumerRecords<String,String> records){System.out.println("onConsumer方法执行:"+ records);return records;}/**
* 消息拿到之后,提交offset之前执行该方法
*
* @param offsets A map of offsets by partition with associated metadata
*/@OverridepublicvoidonCommit(Map<TopicPartition,OffsetAndMetadata> offsets){System.out.println("onCommit方法执行:"+ offsets);}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> configs){}}
- 在kafka消费者的ConsumerFactory配置中注册这个拦截器
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.consumer.key-deserializer}")privateString keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")privateString valueDeserializer;/**
* 消费者相关配置
*
* @return
*/publicMap<String,Object>consumerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);// 添加一个消费者拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,CustomerConsumerInterceptor.class.getName());return props;}/**
* 消费者创建工厂
* @return
*/publicConsumerFactory<String,String>consumerFactory(){returnnewDefaultKafkaConsumerFactory<>(consumerConfigs());}}
- 监听消息时使用我们的监听器容器工厂Bean
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.consumer.key-deserializer}")privateString keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")privateString valueDeserializer;/**
* 消费者相关配置
*
* @return
*/publicMap<String,Object>consumerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);// 添加一个消费者拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,CustomerConsumerInterceptor.class.getName());return props;}/**
* 消费者创建工厂
* @return
*/@BeanpublicConsumerFactory<String,String>ourConsumerFactory(){returnnewDefaultKafkaConsumerFactory<>(consumerConfigs());}@BeanpublicKafkaListenerContainerFactory<?>ourKafkaListenerContainerFactory(ConsumerFactory<String,String> ourConsumerFactory){ConcurrentKafkaListenerContainerFactory<String,String> concurrentKafkaListenerContainerFactory =newConcurrentKafkaListenerContainerFactory<>();
concurrentKafkaListenerContainerFactory.setConsumerFactory(ourConsumerFactory);return concurrentKafkaListenerContainerFactory;}}
@ComponentpublicclassEventConsumer{@KafkaListener(topics ={"batchTopic"}, groupId ="batchGroup2", containerFactory ="ourKafkaListenerContainerFactory")publicvoidonEvent(ConsumerRecord<String,String>record){System.out.println("消息消费,records = "+record);}}
创建生产者
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{User user =User.builder().id(1028).phone("1235324234312").birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("interceptorTopic","k", userJSON);}}
消息转发
消息转发就是应用A从TopicA接收到消息,经过处理后转发到TopicB,再由应用B监听接收该消息,即一个应用处理完成后将该消息转发至其他应用处理,这在实际开发中,是可能存在这样的需求的;
@ComponentpublicclassEventConsumer{@KafkaListener(topics ={"topicA"}, groupId ="aGroup")@SendTo(value ="topicB")publicStringonEventA(ConsumerRecord<String,String>record){System.out.println("消息A消费,records = "+record);returnrecord.value()+"--forward message";}@KafkaListener(topics ={"topicB"}, groupId ="bGroup")publicvoidonEventB(ConsumerRecord<String,String>record){System.out.println("消息B消费,records = "+record);}}
消息消费的分区策略
Kafka消费消息时的分区策略:是指Kafka主题topic中哪些分区应该由哪些消费者来消费;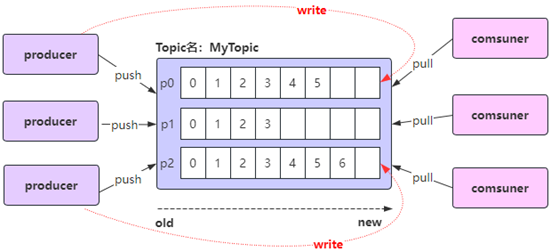
Kafka有多种分区分配策略,默认的分区分配策略是
RangeAssignor
,除了RangeAssignor策略外,Kafka还有其他分区分配策略:
RoundRobinAssignorStickyAssignorCooperativeStickyAssignor
这些策略各有特点,可以根据实际的应用场景和需求来选择适合的分区分配策略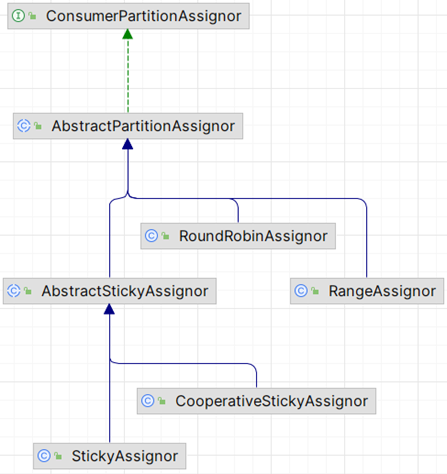
RangeAssignor分区策略
Kafka默认的消费分区分配策略:
RangeAssignor
;假设如下:
- 一个主题myTopic有10个分区;(p0 - p9)
- 一个消费者组内有3个消费者:consumer1、consumer2、consumer3;
RangeAssignor
消费分区策略:RangeAssignor策略是根据消费者组内的消费者数量和主题的分区数量,来均匀地为每个消费者分配分区。
- 计算每个消费者应得的分区数: 分区总数(10)/ 消费者数量(3)= 3 … 余1; - 每个消费者理论上应该得到3个分区,但由于有余数1,所以前1个消费者会多得到一个分区;- consumer1(作为第一个消费者)将得到 3 + 1 = 4 个分区;- consumer2 和 consumer3 将各得到 3 个分区;
- 具体分配: 分区编号从0到9,按照编号顺序为消费者分配分区: - consumer1 将分配得到分区 0、1、2、3;- consumer2 将分配得到分区 4、5、6;- consumer3 将分配得到分区 7、8、9;
@ComponentpublicclassEventConsumer{@KafkaListener(topics ={"myTopic"}, groupId ="myGroup", concurrency ="3")publicvoidonEventA(ConsumerRecord<String,String>record){System.out.println(Thread.currentThread().getName()+" -->消息消费,records = "+record);}}
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{for(int i =0; i <100; i++){User user =User.builder().id(1028+i).phone("1370909090"+i).birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("myTopic","k"+ i, userJSON);}}}
@ConfigurationpublicclassKafkaConfig{@BeanpublicNewTopicnewTopic(){// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1 returnnewNewTopic("myTopic",10,(short)1);}}
RoundRobinAssignor分区策略
继续以前面的例子数据,采用
RoundRobinAssignor
策略进行测试,得到的结果如下:
- consumer1:0、3、6、9
- consumer2:1、4、7
- consumer3:2、5、8
@ConfigurationpublicclassKafkaConfig{@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;@Value("${spring.kafka.consumer.value-deserializer}")privateString valueDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")privateString keyDeserializer;@Value("${spring.kafka.consumer.auto-offset-reset}")privateString autoOffsetReset;@BeanpublicNewTopicnewTopic(){// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1 returnnewNewTopic("myTopic",10,(short)1);}/**
* 消费者相关配置
*
* @return
*/publicMap<String,Object>consumerConfigs(){Map<String,Object> props =newHashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);// 指定使用轮询的消息消费区分策略
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,RoundRobinAssignor.class.getName());return props;}/**
* 消费者创建工厂
* @return
*/@BeanpublicConsumerFactory<String,String>ourConsumerFactory(){returnnewDefaultKafkaConsumerFactory<>(consumerConfigs());}/**
* 创建监听器容器工厂
*
* @param ourConsumerFactory
* @return
*/@BeanpublicKafkaListenerContainerFactory<?>ourKafkaListenerContainerFactory(ConsumerFactory<String,String> ourConsumerFactory){ConcurrentKafkaListenerContainerFactory<String,String> concurrentKafkaListenerContainerFactory =newConcurrentKafkaListenerContainerFactory<>();
concurrentKafkaListenerContainerFactory.setConsumerFactory(ourConsumerFactory);return concurrentKafkaListenerContainerFactory;}}
@ComponentpublicclassEventConsumer{@KafkaListener(topics ={"myTopic"}, groupId ="myGroup2", concurrency ="3", containerFactory ="ourKafkaListenerContainerFactory")publicvoidonEventA(ConsumerRecord<String,String>record){System.out.println(Thread.currentThread().getId()+" -->消息消费,records = "+record);}}
@ComponentpublicclassEventProducer{//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @ResourceprivateKafkaTemplate<String,String> kafkaTemplate;publicvoidsendEvent()throwsJsonProcessingException{for(int i =0; i <100; i++){User user =User.builder().id(1028+i).phone("1370909090"+i).birthDay(newDate()).build();String userJSON =JSONUtils.toJSON(user);
kafkaTemplate.send("myTopic","k"+ i, userJSON);}}}
StickyAssignor消费分区策略
- 尽可能保持消费者与分区之间的分配关系不变,即使消费组的消费者成员发生变化,减少不必要的分区重分配;
- 尽量保持现有的分区分配不变,仅对新加入的消费者或离开的消费者进行分区调整。这样,大多数消费者可以继续消费它们之前消费的分区,只有少数消费者需要处理额外的分区;所以叫“粘性”分配;
CooperativeStickyAssignor消费分区策略
- 与 StickyAssignor 类似,但增加了对协作式重新平衡的支持,即消费者可以在它离开消费者组之前通知协调器,以便协调器可以预先计划分区迁移,而不是在消费者突然离开时立即进行分区重分配;
Kafka事件(消息、数据)的存储
- kafka的所有事件(消息、数据)都存储在
/tmp/kafka-logs目录中,可通过log.dirs=/tmp/kafka-logs配置; - Kafka的所有事件(消息、数据)都是以日志文件的方式来保存;
- Kafka一般都是海量的消息数据,为了避免日志文件过大,日志文件被存放在多个日志目录下,日志目录的命名规则为:
<topic_name>-<partition_id>; - 比如创建一个名为 firstTopic 的 topic,其中有 3 个 partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,
firstTopic-0、firstTopic-1、firstTopic-2; - 00000000000000000000.index 消息索引文件- 00000000000000000000.log 消息数据文件- 00000000000000000000.timeindex 消息的时间戳索引文件- 00000000000000000006.snapshot 快照文件,生产者发生故障或重启时能够恢复并继续之前的操作- leader-epoch-checkpoint 记录每个分区当前领导者的epoch以及领导者开始写入消息时的起始偏移量- partition.metadata 存储关于特定分区的元数据(metadata)信息 - 每次消费一个消息并且提交以后,会保存当前消费到的最近的一个offset;
- 在kafka中,有一个__consumer_offsets的topic, 消费者消费提交的offset信息会写入到 该topic中,__consumer_offsets保存了每个consumer group某一时刻提交的offset信息,__consumer_offsets默认有50个分区;
- consumer_group 保存在哪个分区中的计算公式:Math.abs(“groupid”.hashCode())%groupMetadataTopicPartitionCount ;
Offset详解
- 生产者Offset - 生产者发送一条消息到Kafka的broker的某个topic下某个partition中;- Kafka内部会为每条消息分配一个唯一的offset,该offset就是该消息在partition中的位置;
- 消费者Offset - 消费者offset是消费者需要知道自己已经读取到哪个位置了,接下来需要从哪个位置开始继续读取消息;- 每个消费者组(Consumer Group)中的消费者都会独立地维护自己的offset,当消费者从某个partition读取消息时,它会记录当前读取到的offset,这样,即使消费者崩溃或重启,它也可以从上次读取的位置继续读取,而不会重复读取或遗漏消息;(注意:消费者offset需要消费消息并提交后才记录offset)
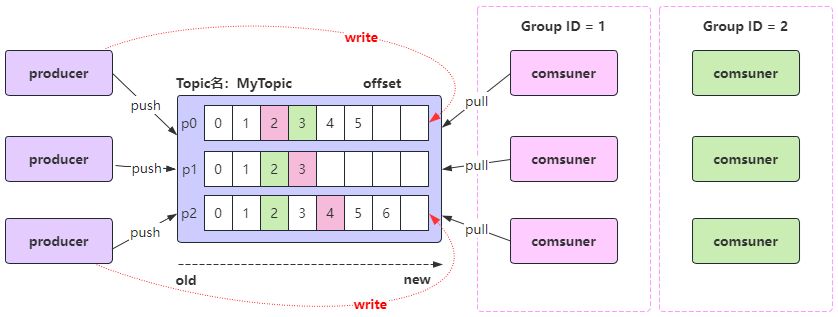
每个消费者组启动开始监听消息,默认从消息的最新的位置开始监听消息,即把最新的位置作为消费者offset;
- 分区中还没有发送过消息,则最新的位置就是0;
- 分区中已经发送过消息,则最新的位置就是生产者offset的下一个位置; 消费者消费消息后,如果不提交确认(ack),则offset不更新,提交了才更新; 命令行命令:
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group osGroup --describe结论: 消费者从什么位置开始消费,就看消费者的offset是多少,消费者offset是多少,它启动后,可以通过上面的命令查看;
版权归原作者 程序员劝退师_ 所有, 如有侵权,请联系我们删除。