
数据挖掘1——课后习题
部分习题
第一章:引论
1.3
定义以下数据挖掘功能:特征化、区分、关联和相关性分析、分类、回归、聚类、离群点分析。使用你熟悉的现实生活中的数据库,给出每种数据挖掘功能的例子。
- 特征化是目标类数据的一般特性或者特征的汇总。例如可以通过收集销量在前10%的物品的信息,再进行特征汇总。
- 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如将销量增加10%和销量减少30%的物品放在一起进行比较。
- 频繁模式:频繁模式(frequent pattern)是在数据中频繁出现的模式。挖掘频繁模式导致发现数据中有趣的关联和相关性。
- 关联是类与类之间的联接,使一个类知道另一个类的属性和方法。例如Apriori算法挖掘产生布尔关联规则所需频繁项集。
- 相关性分析是两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度。例如分析人的身高和体重之间的关系。
- 分类是找出描述和区分数据类或概念的模型,以便能够使用模型预测类标号位置的对象的类标号。例如找出描述销量增加30%和销量减少30%的物品,通过对其特征进行描述和建模,再对一个新的物品根据其特征将其分类。
- 回归建立连续值函数模型,用于预测缺失的难以确定的数据值。例如补全未采样的数据。
- 聚类根据最大化类内相似性、最小化类间相似性的原则分析数据对象,但不进行类标号。例如可以对客户数据进行分析,以簇形式表示每个购物目标群。
- 离群点分析指研究那些与数据的一般行为或模型不一致的数据离散点,可以从中挖掘某种模式。例如使用离群点分析发现信用卡诈骗使用活动。
1.4
给出一个例子,其中数据挖掘对于工商企业的成功是至关重要的。该工商企业需要什么数据挖掘功能?这种模式能够通过简单的查询处理或统计分析得到吗?
超市营销系统中采用Apriori算法发掘潜藏在商品中的某些关系,细化商品的布局和摆放。超市对销售数据进行分析,能够统计商品的销售情况,找出商品间存在的内在关联,预测新商品是否畅销。根据顾客购买记录,使用序列模式挖掘顾客的消费变化,分析顾客的忠诚程度。电商平台基于用户的基本属性(年龄、性别)、购买能力、行为特征、兴趣爱好,使用数据挖掘技术构建客户画像,实现精准营销。
1.5
解释区分和分类、特征化和聚类、分类和回归之间的区别和相似之处。
区分指的是将目标类数据的一般特性和一个或多个对比类对象的一般特性进行比较,即找出两者之间的特征区别;
分类指的是找出一种模型来描述和区分数据类型或概念,并预测类标号未知的对象的类标号。
相似性在于他们都要对目标类数据对象进行处理和分析,输出结果都是类别特征,这些类别是预先指定的。
区别:区分只是找出特征区别,分类是预测类标号。
特征化是对目标类数据的的一般特性或特征的汇总,即在进行数据特征化时很清楚特征化的这些数据的特点是什么;
聚类是分析数据对象,按照“最大化类内相似度、最小化类间相似度”的原则进行聚类或分组。即在不考虑明确标签分类的情况下进行分析。
相似处在于刻画目标的总体特征。
区别:特征化是对每一列特征维度,聚类是行与行之间元素维度。
分类用于找出一种模型来描述和区分数据类型或概念,并预测类标号未知的对象的类标号;
回归则是建立一个连续值函数模型,而不是离散、无序的标号。
相似点:用函数进行预测。
区别:分类是离散值,回归是连续值。
第二章:认识数据
2.5
简要概述如何计算被如下属性描述的对象的相异性。
(a)标称属性
两个对象i和j之间的相异性根据不匹配率来计算: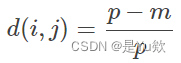
其中,p为刻画对象的属性总数,m是匹配的数目。
(b)非对称的二元属性
可以依据二元属性的列联表去计算,计算公式如下: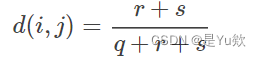
其中,r为在对象i中取1、在对象j中取0的属性数;s为在对象i中取0、对象j中取1的属性数;q为在对象i和j中都取1的属性数。
(c)数值属性
使用闵可夫斯基距离进行计算,即欧几里得距离和曼哈顿距离的推广,定义如下: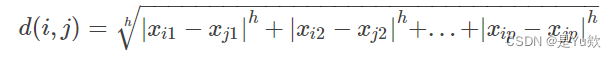
其中,h是实数,h≥1。且当h = 1时,它代表曼哈顿距离(即,L1范数);当h = 2时表示欧几里得距离(即,L2范数)。
(d)词频向量
使用余弦相似度进行计算,其计算公式如下: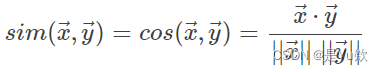
其中,余弦值0意味着两个向量呈90°夹角(正交),没有匹配。余弦值越接近于1,夹角越小,向量之间的匹配度越大。
2.6
给定两个被元组(22,1,42,10)和(20,0,36,8)表示的对象。
(a)计算这两个对象之间的欧几里得距离。
(b)计算这两个对象之间的曼哈顿距离。
(c)使用q=3,计算这两个对象之间的闵可夫斯基距离。
(d)计算这两个对象之间的上确界距离。
(a)计算两个对象之间的欧几里得距离: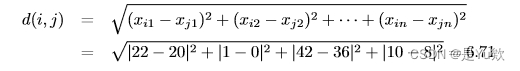
(b)计算两个对象之间的曼哈顿距离: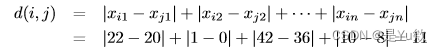
(c)使用q=3,计算这两个对象之间的闵可夫斯基距离: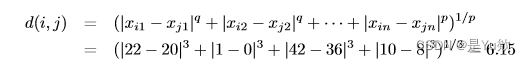
(d)计算这两个对象之间的上确界距离: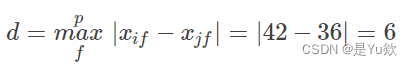
第三章:数据预处理
3.1
数据质量可以从多方面评估,包括准确性、完整性、一致性问题。 提出其他两个方面的数据质量。
准确性:由于技术的限制或人为的失误,有些需要准确投入营销,比如生日折扣等的商品,可能会失去作用。
完整性:由于技术的限制或人为的失误,有些需要准确投入营销比如生日折扣等的商品可能会失去作用。
如果要对某宝、某东或者某宁的买家信息进行一个数据挖掘,从而用来营销其他东西,比如要对地址进行挖掘,此时详细、完整的地址数据则是一个必备的特性。
一致性问题:由于某些不可抗因素而导致的数据不一致,例如多个数据源命名不一致时会影响数据集成等。比如技术问题,在并发量大的情况下,记录数据时出现问题;或者某些数据值是一样的,然而在不同的数据库中其命名却不一样;这些不一致性问题在数据挖掘时则会影响挖掘的结果。
数据质量的其他两个尺度:时效性和可信性。
时效性:数据必须在一定时间范围内可用,以便对决策有用。
可信性:数据值必须在可能结果的范围内,以便对决策有用。
3.2
在实际数据中,某些属性缺少值的元组是常见的情况。 描述解决此问题的各种方法。
处理数据元组中缺少值的问题的各种方法包括:
(a)忽略元组:通常在缺少类标签时执行此操作(假设挖掘任务涉及分类或描述)。除非元组包含缺少值的几个属性,否则此方法不太有效。当每个属性的缺失值的百分比相差很大时,这尤其差劲。
(b)手动填充缺失值:通常,此方法很耗时,对于缺失值很多的大型数据集,这可能不是一个合理的任务,尤其是当填充值不容易确定时。
(c)使用全局常量填充缺失值:用相同的常量替换所有缺失的属性值,例如“ Unknown”或-∞之类的标签。如果将缺失的值替换为“未知”,则挖掘程序可能会错误地认为它们构成了一个有趣的概念,因为它们都具有一个共同的值,即“未知”。因此,尽管此方法很简单,但不建议使用。
(d)将属性均值用于定量(数字)值或将属性模式用于分类(标称)值:例如,假设AllElectronics客户的平均收入为$ 28,000。 使用此值替换任何缺失的收入值。
(e)对于属于与给定元组相同类别的所有样本,使用定量(数值)值的属性均值或分类(名义)值的属性模式:例如,如果根据信用风险对客户进行分类,则替换缺失的与给定元组处于相同信用风险类别的客户的平均收入值。
(f)使用最可能的值来填补缺失值:这可以通过回归,使用贝叶斯形式主义的基于推理的工具或决策树归纳法来确定。 例如,使用数据集中的其他客户属性,我们可以构建决策树来预测收入的缺失值。
3.4
讨论数据集成需要考虑的问题。
数据集成涉及将来自多个源的数据组合到一个一致的数据存储中。 在这种集成过程中必须考虑的问题包括:
- 模式集成:必须集成来自不同数据源的元数据,以匹配等效的实际实体。 这称为实体识别问题。
- 处理冗余数据:派生的属性可能是冗余的,不一致的属性命名也可能导致结果数据集中的冗余。 在元组级别可能出现重复,因此需要检测和解决。
- 数据值冲突的检测和解决:表示,缩放或编码上的差异可能导致相同的现实世界实体属性值在要集成的数据源中有所不同。
3.7
使用习题3.3中给出的age数据,回答以下问题:
(a)使用最小最大规范化将age值35变换到[0.0,1.0]区间。
(b)使用z分数规范化,变换age,其中标准差为12.94。
(c)使用小数定标规范化变换35。
(d)指出给定数据,你愿意使用哪种方法。陈述你的理由。
(a)使用最小最大规范化将age值35变换到[0.0,1.0]区间
为了便于阅读,将A设为属性年龄。 使用公式: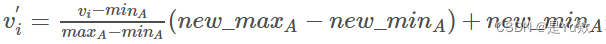
其中minA = 13,maxA = 70,new_minA = 0,new_maxA = 1.0,然后将v = 35转换为v` = 0.39。
(b)使用z分数规范化,变换age,其中标准差为12.94
使用公式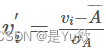 (其中
(其中 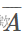 = 809/27 = 29.96,
= 809/27 = 29.96,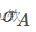 = 12.94),然后将v = 35转换为v` = 0.39。
= 12.94),然后将v = 35转换为v` = 0.39。
(c)使用小数定标规范化变换35
使用公式 (其中j = 2),将v = 35转换为v` = 0.35。
(其中j = 2),将v = 35转换为v` = 0.35。
(d)指出给定数据,你愿意使用哪种方法。陈述你的理由。
言之有理即可。一般情况下,使用最小最大规范化。
- 在给定数据的情况下,十进制缩放进行规范化,可以将保持数据的分布并直观地解释,同时仍允许在特定年龄段进行挖掘。
- 最小最大规范化具有不希望的结果,即不允许任何将来的值落在当前的最小值和最大值之外,而不会遇到“超出范围的误差”。 由于此类值可能会出现在将来的数据中,因此此方法不太合适。
- 最小最大规范化和z分数规范化都极大地改变了原始数据。z分数规范化将值转换为表示它们与标准差之间的距离的度量。但与十进制缩放相比,这种类型的转换对用户而言可能不那么直观。
第六章:挖掘频繁模式、关联和相关性
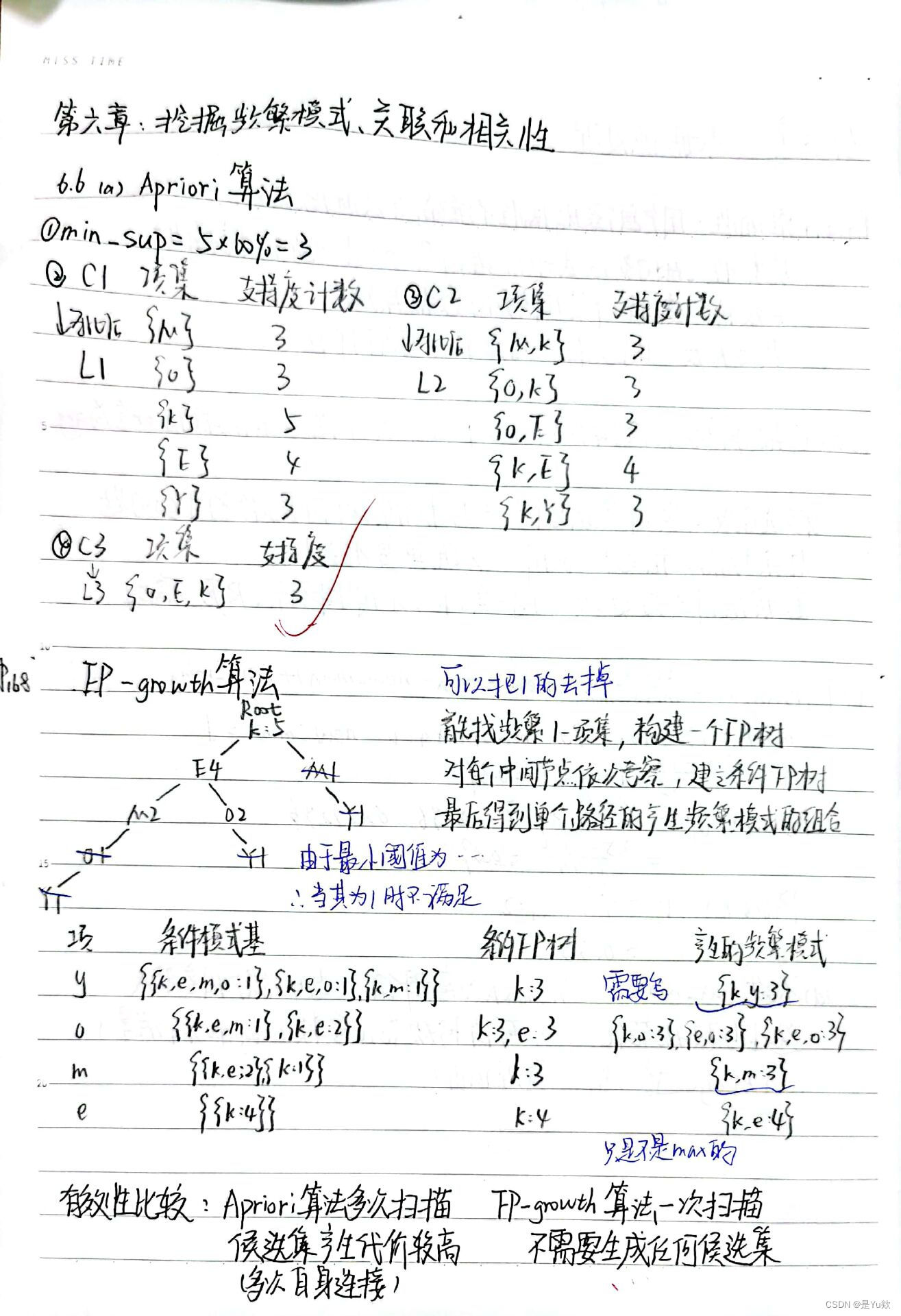
6.6
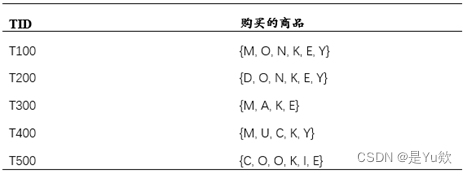
数据库有5个事务。设mini_sup=60%,min_conf=80%。
(a)分别使用Apriori算法和FP-growth算法找出频繁项集。比较两种挖掘过程的有效性。
(b)列举所有与下面的原规则匹配的强关联规则(给出支持度s和置信度c),其中X是代表顾客的变量,item是表示项的变量(如“A”,“B”等):
∀x∈transaction,buys(X,item_1 )∧buys(X,item_2 )⇒buys(X,item_3 ) [s,c]
使用Apriori算法
首先找出频繁的1-项集,然后进行组合再找出频繁的2-项集,以此类推,有如下图(其中L表示频繁项集):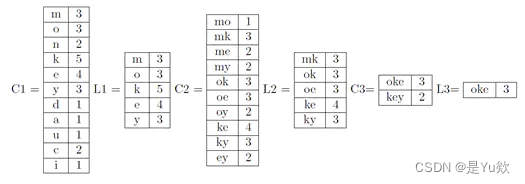
使用FP-growth算法
首先找出频繁的1-项集,然后构建一个FP树,再对每个中间节点依次进行考察,建立条件FP树,最后得到单个路径的产生频繁模式的所有组合。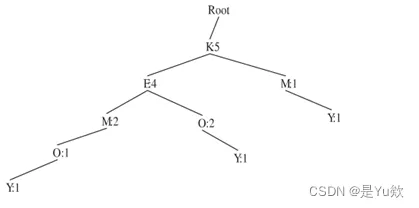

有效性比较:Apriori算法需要对数据库做多次扫描而FP-growth算法只需要一次扫描。Apriori的候选集产生代价较高(需要做多次自身连接),而FP-growth不需要生成任何候选集。
强关联规则:[s,c]支持度,置信度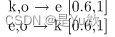
k,e —> o [0.6,0.75] (所以不满足要求)

6.14
下面的相依表汇总了超市的事务数据。其中,hot dogs表示包含热狗的事务,(hot dogs) ̅表示不包含热狗的事务。hamburgers表示包含汉堡包的事务,(hamburgers) ̅表示不包含汉堡包的事务。(题图中第二行第一列改成(hamburgers) ̅)
(a)假设挖掘出了关联规则hot dogs⇒humburgers,给定最小支持度阈值25%,最小置信度阈值50%,该关联规则是强规则吗?
(b)根据给定的数据,买hot dogs独立于买humburgers吗?如果不是,两者之间存在何种相关联系。
(c)在给定的数据上,将全置信度、最大置信度、Kulczynski和余弦的使用与提升度和相关度进行比较。
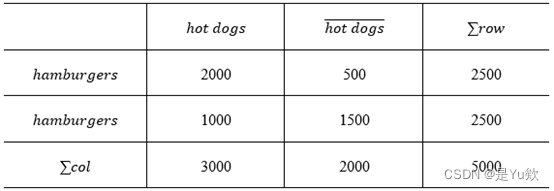
(a)假设挖掘出了关联规则hot dogs⇒humburgers,给定最小支持度阈值25%,最小置信度阈值50%,该关联规则是强规则吗?
由于支持度为2000/5000=40%,置信度为2000/3000=66.7%。因此,该关联规则是强关联规则。
(b)根据给定的数据,买hot dogs独立于买humburgers吗?如果不是,两者之间存在何种相关联系。
不是,corr(hotdog,hamburgers)=P(hot,hum)/(P(hot)×P(hum))=(2000/5000)/((2500/5000)×(3000/5000))=0.4/(0.5×0.6)=1.33>1,因此两者之间为正相关。
(c)在给定的数据上,将全置信度、最大置信度、Kulczynski和余弦的使用与提升度和相关度进行比较。
全置信度:〖all_conf〗(hotdog,hamburgers)=0.4/0.6=2/3
最大置信度:maxconf(hotdog,hamburgers)=0.4/0.5=0.8
Kulczynski:〖Kul〗(hotdog,hamburgers)=1/2 (0.8+2/3)=11/15
余弦度量:cos(hotdog,hamburgers)=√(0.8*2/3)=(2√30)/15
提升度:lift_(hotdog,hamburgers)=(2/3)/0.5=4/3
相关度:期望值计算参考P64,其计算公式为:
x2=∑〖(观测值-期望值)〗2/期望值,x2=833.3
第八章:分类基本概念
8.7
下表由雇员数据库的训练数据组成。数据已泛化。例如,age“31…35”表示年龄在31~35之间。对于给定的行,count表示department、status、age和salary在该行上具有给定值的元组数。
设status是类标号属性。
1) 如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count?
2) 使用修改过的算法,构造给定数据的决策树。
3) 给定一个数据元组,它的属性department、age和salary的值分别为“system”、“26…30”、“46…50K”。该元组status的朴素贝叶斯分类是什么?
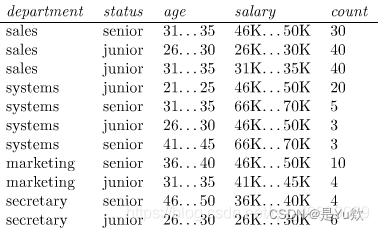
1) 如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count?
① 将每个元组的count作为计算属性选择方法中的一部分(例如信息增益)。
② 在决定元组多数表决的时候考虑元组的count。
2) 使用修改过的算法,构造给定数据的决策树。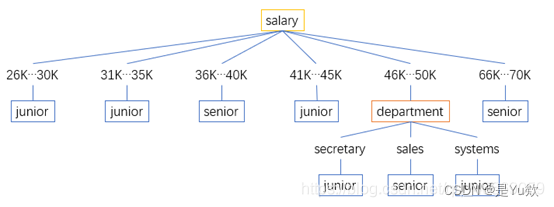
3) 给定一个数据元组,它的属性department、age和salary的值分别为“system”、“26…30”、“46…50K”。该元组status的朴素贝叶斯分类是什么?

8.12
如图中的数据元组已经按分类器返回概率值的递减序排序。对于每个元组,计算真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)的个数。计算真正例率(TPR)和假正例率(FPR)。为该数据绘制ROC曲线。
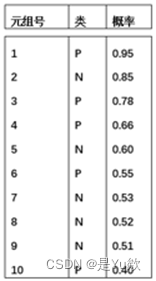
根据计算,可以得到如上图所示对应的TPR和FPR,绘制出来的表格如下:
(这个图不对,应该是纵坐标是TPR,这样才是凸包)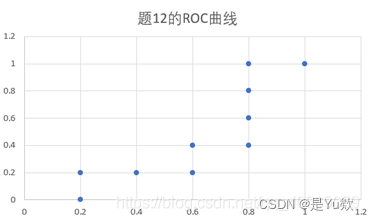
8.13
当一个数据对象可以同时属于多个类时,很难评估分类的准确率。评述在这种情况下,你将使用何种标准比较在相同数据上建立的不同分类器。
一个数据对象可以同时属于多个类。然而,一个数据对象可能比起其他类会更多属于一个特定类。因此,应该建立一个分类器去判断数据对象通常属于哪个类。第一个标准,一个类如果符合最可能或第二可能类即判断分类正确。
另一个标准是使用同一个数据集判断不同分类器的分类速度、鲁棒性、可扩展性以及解释性。
通常我们会选择一个计算代价更小(训练时间、分类时间)、能在给出噪声甚至不完整数据下做出准确预测、在大型数据上有效工作并提供能够更易理解的准确结果的分类器。
8.16
概述处理类不平衡问题的方法。解释基于大量非欺诈案例和很少的欺诈案例,如何构建高质量的分类器。
提升不平衡类分类准确率的方法有三大类:采样、阈值移动、调整代价或权重。
- 对较多的那个类别进行欠采样(under-sampling),舍弃一部分数据,使其与较少类别的数据相当。
- 对较少的类别进行过采样(over-sampling),重复使用一部分数据,使其与较多类别的数据相当。
- 阈值调整(threshold moving),将原本默认为0.5的阈值调整到 较少类别/(较少类别+较多类别)即可。
 前两种方法都会明显的改变数据分布,训练数据假设不再是真实数据的无偏表述。在第一种方法中,浪费了很多数据。而第二类方法中有无中生有或者重复使用了数据,会导致过拟合的发生。因此欠采样的逻辑中,往往会结合集成学习来有效的使用数据。
前两种方法都会明显的改变数据分布,训练数据假设不再是真实数据的无偏表述。在第一种方法中,浪费了很多数据。而第二类方法中有无中生有或者重复使用了数据,会导致过拟合的发生。因此欠采样的逻辑中,往往会结合集成学习来有效的使用数据。
方法评价: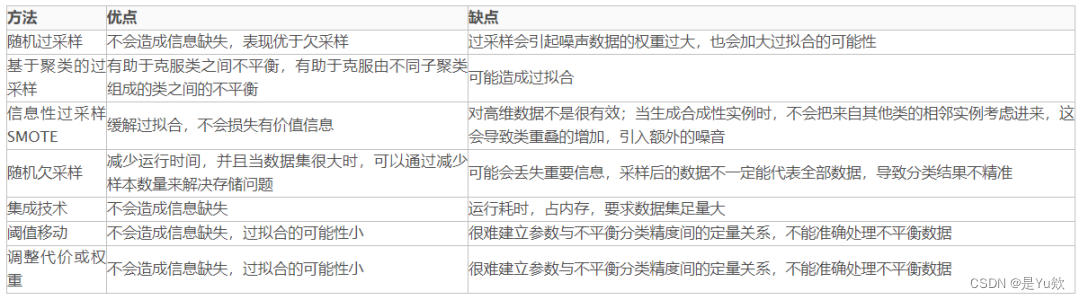
实例
假设正例数据n,而反例数据m个。可以通过欠采样,随机无重复的生成(k=n/m)个反例子集,并将每个子集都与相同正例数据合并生成k个新的训练样本。在k个训练样本上分别训练一个分类器,最终将k个分类器的结果结合起来,比如求平均值。
这就是一个简单的思路,也就是Easy Ensemble[1]。
[1] Liu, T.Y., 2009, August. Easyensemble and feature selection for
imbalance data sets. In Bioinformatics, Systems Biology and
Intelligent Computing, 2009. IJCBS’09. International Joint Conference
on (pp. 517-520). IEEE.
代码可参考:
https://cloud.tencent.com/developer/article/1689107
- 法一:SMOTE算法、LR模型以及阈值移动的方法
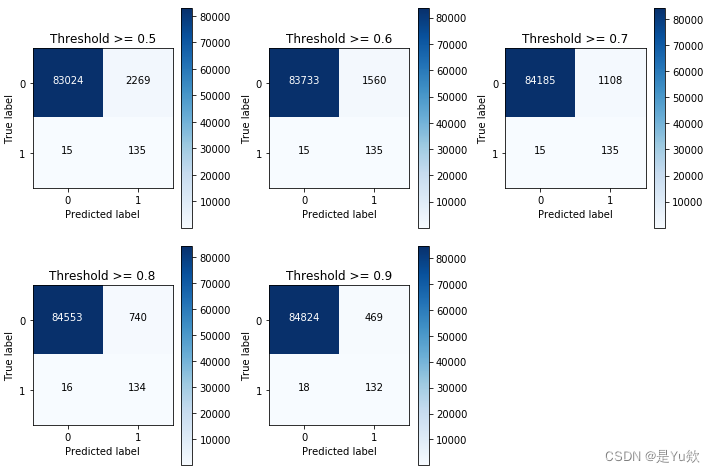
- 法二:算法集成技术XGBoost
第十章:聚类分析
10.2
假设数据挖掘的任务是将如下的8个点(用(x,y)代表位置)聚类为3个簇。
A_1(2,10) ,A_2 (2,5),A_3 (8,4),B_1 (5,8),B_2 (7,5),B_3 (6,4),C_1 (1,2),C_2 (9,4)
距离是欧氏距离。假设初始我们选择A_1,B_1和C_1分别为每个簇的中心,用k-均值算法给出:
(a)在第一轮执行后的3个簇中心。
(b)最后的3个簇。
(a)在第一轮执行后的3个簇中心。
在第一轮执行时,分别计算除中心点外的所有点和每个中心点的欧几里得距离,将其并入离自己最近的中心点的簇中。因此可得第一轮后,3个簇为:
{A_1},{B_1,A_3,B_2,B_3,C_2},{C_1,A_2},故簇中心为(2, 10),(6, 6),(1.5, 3.5)。
(b)最后的3个簇。
使用新的均值作为簇的中心点,再次按照以上流程进行计算;如此迭代后,直到分配稳定后,最后形成的三个簇为:{A_1,C_2 ,B_1},{A_3,B_2,B_3},{C_1,A_2}。
10.6
k-均值和k-中心点算法都可以进行有效的聚类。
(a)概述k-均值和k-中心点相比较的优缺点。
(b)概述这两种方法与层次聚类方法(如AGNES)相比有何优缺点。
(a)概述k-均值和k-中心点相比较的优缺点。
k-均值算法计算代价更小;k-中心点计算代价大,但是对于数据中的离群点和噪声鲁棒性更强,即更少受到离群点和噪声的影响。
(b)概述这两种方法与层次聚类方法(如AGNES)相比有何优缺点。
k-均值和k-中心点都是划分方法的一种,这种方法的好处在于每次迭代重定位的时候可以撤销之前的聚群操作,但是层次聚类方法一旦一个步骤(分裂或合并)完成将不能被撤回,因此层次聚类方法可能会影响聚类的结果的质量。划分方法在球形聚类上表现良好,且其聚类的结果在小型到中中型的数据库上质量较好。划分方法的缺点在于需要指定簇的数量。
层次聚类方法自动决定簇的数量。然而他们每一步做出合并或分裂步骤的时候需要进行大量计算来评估该步骤产生的簇的质量。然而,层次聚类方法能够和其他聚类方法集成一个扩展的聚类方法,提高层次聚类质量,如BIRCH、ROCK和Chameleon。
10.12
指出在何种情况下,基于密度的聚类方法比基于划分的聚类方法和层次聚类方法更合适。并给出一些应用实例来支持你的观点。
基于划分的聚类方法和层次聚类方法都是基于对象之间的距离。这样的方法更倾向于发现球形簇并在发现任意形状的簇上遇到困难。划分方法还在簇的密度和直径方面存在问题;而层次划分方法计算代价昂贵且不能撤回已经完成的分裂或合并步骤。
基于密度的聚类方法是建立在每个簇通常其簇内的点的密度比簇外的大的前提之上的,即簇时数据空间中被稀疏区域分开的稠密区域。基于密度的方法能够发现任意形状的簇,不同意传统的聚类方法,其可以处理数据中的噪声。下图中展示了不同形状的簇,使用DBSCAN方法将能轻松处理这些簇。
10.13
给出一个例子来说明如何集成特定的聚类方法,例如,一种聚类方法被用作另一种算法的预处理步骤。此外,请解释为什么两种聚类方法的集成有时候会改进聚类的质量和有效性。
一个例子是BIRCH,一种集成了层次性聚类方法(预处理步骤)和其他聚类方法的聚类算法。一开始使用树形结构作为层次划分的对象,然后使用其他聚类算法(例如迭代划分)来重新定义簇,BIRCH增量地构建一个聚类特征树(CF树),是一棵高度平衡树,用于为层次聚类存储聚类特征(总和特征)。BIRCH包括两个阶段,第一个阶段(微聚类)扫描一遍数据库,在内存中建立一棵CF树,可以看做数据的多层压缩,视图保留数据的内在结构;第二个阶段(宏聚类)采用其他的聚类算法(例如迭代重定位)来对CF树的叶节点进行聚类,把稀疏的点当做离群点移出并且将稠密的簇合并为更大的簇。
集成不同的聚类方法能够克服单个方法的局限性。例如,集成层次聚类方法和一种其他聚类方法,例如BIRCH克服了层次聚类分两大局限性——可扩展性和不能撤销已经完成的步骤。
参考
https://blog.csdn.net/qq_40669059/article/details/105697907
https://blog.csdn.net/qq_43060870/article/details/107099163
https://cloud.tencent.com/developer/article/1689107
版权归原作者 是Yu欸 所有, 如有侵权,请联系我们删除。