

Sprite生产的几个阶段。即草图,线条图,底纹,区域上色和索引。

上面的图片来自Trajes Fatais:Feats of Fate游戏,我作为首席开发者从事该游戏的制作。长话短说,每个精灵要绘制大约一小时,每个角色平均要绘制五百个精灵。在“游戏的机器学习辅助资料生成:像素绘画Sprite表格研究”中,我们探索了Pix2Pix架构来自动生产Sprite的流程,将每个Sprite花费的平均时间减少了15分钟(〜25%)。这是我们首次发表的有关精灵生成的工作,我们希望在将来进一步改进它。
该论文获得了2019年巴西游戏与数字娱乐研讨会(SBGames 2019)的最佳论文奖。
像素绘画是视频游戏中最受欢迎的美学之一。它致力于重现任天堂和Arcade旧游戏的外观。在90年代,像素绘画是大多数游戏机的唯一选择。屏幕分辨率有限,并且大多数设备无法实时执行高级技术。如今,像素绘画已成为一种选择-一种昂贵的选择。
为了实现街机游戏的外观和感觉,绘画者必须受颜色数量限制。最初的Game Boy只有四种绿色。它的继任者Game Boy Color可同时显示多达56种不同的颜色。后来的设备称为16位生成器,每个像素点最多允许256种颜色,这是美学上的重大突破。在我们的游戏中,我们限制为每个角色256个颜色。

每个像素点都有自己的256种颜色
通常,像素点是“索引精灵”与“调色板”的混合体。绘画时,绘画者使用与调色板的256种颜色之一相关的“索引”对每个像素进行着色。在游戏中,每个索引精灵都用其关联的颜色替换,从而构成最终图像。此过程使设计人员可以为每个角色创建不同的“皮肤”,从而允许用户自定义其体验并为角色创建“邪恶”版本。下图描绘了索引精灵,调色板和渲染的混合。

索引精灵,调色板和渲染
将绘画者的颜色选择限制为256种是不科学的。这使得选择阴影很难。为了简化此任务,在语义上对工作进行了划分。在我们的通道中,生成了两个中间的精灵:“阴影”精灵和“区域”精灵。前者最多使用6个选择来表示“灯光”,而后者最多使用42个选择来表示精灵的“区域”,例如手臂,头发,腿等。将两个精灵像素相乘 -之后我们获得了索引精灵,它最多可以支持252种颜色(6 * 42)。下图显示了阴影,区域和索引精灵的示例。此过程将256色问题转换为两个简单的子问题,每个子问题分别具有6和42色。

从左到右,阴影,区域和索引精灵。
最终,每个角色都是由一个人设计的,他将为其所有动画进行绘制。它们以“草图”子图形显示,后来又被精炼为“艺术线条”子图形。前者用于在游戏中快速制作新动画的原型,后者用于与其他绘画者交流最终精灵的外观。这样,设计人员可以在几天内概念化整个角色,并将其余工作外包给绘图团队。以下是草图和艺术线条精灵的示例:

草图和艺术线条
设计师将所有动画放在一起,通过绘制每个动画的草图,然后制作各自的艺术线条来创建角色。这些线型精灵将按顺序传递给绘图团队,后者将绘制它们的着色和区域。最后,使用脚本将两者结合起来以生成可用于游戏的索引精灵。
总共大约需要一个小时。草图,线条图和区域精灵的制作平均需要10分钟,而阴影则需要花费其余时间才能完成。跟踪每个图纸花费的确切时间几乎是不可能的。为了计算它们,我们检查了生产日志,采访了团队,并以可控的方式测量了12个精灵的绘制步骤。
假设使用机器学习模型可以生成阴影和彩色图片,那么生成的精灵必须足够好,以至于人类绘画者可以用比从头开始绘制更少的时间来完善它。
生成对抗网络入门
在这项工作中,我们解决了两个图像映射问题:线条到阴影和线条到区域。形式上,我们必须创建一个生成器G(x),该生成器从线条艺术中接收输入,并在阴影/区域中生成输出。此问题也称为图像翻译。
为了保证G(x)是有用的映射,我们将创建一个鉴别器D(x,y),该鉴别器查看x和y并说明y是否是一个优质子画面。换句话说,G是我们的“虚拟艺术家”,D是我们的“虚拟鉴赏家”。如果我们能让G使D开心,那么我们就有一个有用的映射。
更详细地说,考虑一下我们有几个线条艺术精灵(x)以及已经绘制的人类绘画者的阴影和区域精灵(y)。我们知道这些通过了质量控制,因此D(x,y)将很高兴。现在我们的任务是训练G给定x产生ŷ(对真实y的模仿)。如果复制良好,D将批准ŷ;否则,它将予以谴责。最后,我们会修正D的对与错,并要求D提供有建设性的反馈。
我刚刚描述的过程称为对抗训练。从某种意义上说,两种模式“竞争”,一种正在试图击败另一种。在我们的案例中,G试图击败D使其认为ŷ是y,而D则拼命试图说出什么是真实的,什么是假的。随着时间的流逝,G将成为成功的艺术家,而D可能会被解雇。
通过使用神经网络实现G和D,我们得到了所谓的生成对抗网络。将标题分解为“条件”是因为G接受x而不是随机噪声作为输入,“对抗”是因为它训练对手成为输入器,而“网络”则是(神奇!)神经网络 。
从算法上来说,对于每个线条艺术x和阴影/区域精灵y:
- 使用G从x生成ŷ
- 使用D评估ŷ是否看起来逼真
- 使用y和D的反馈来训练G
- 训练D认识到ŷ是假的而y是真的。
多次对整个数据集重复执行此过程,最终将融合为一个G网络(创建逼真的绘画)和一个D网络(无法分辨出图像是真实的或伪造的)。
Pix2Pix架构
Pix2Pix体系结构为基于U-Net生成器和基于补丁(Patch)的鉴别器。下图显示了组合的体系结构。鉴别器经过训练,可将每个32x32图片分类为真实或伪造,并经过交叉熵损失训练。反过来,训练生成器以使y和ŷ之间的L1损失最小,并使鉴别器损失最大。
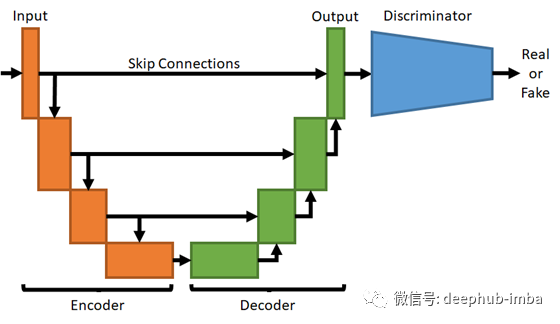
高级Pix2Pix架构。
U-Net模型是基于编码器-解码器思想的全卷积神经网络。对于每个编码器层,将跳过全连接添加到解码器层。这允许网络利用来自编码层的“原始”信息和通过解码器层的“已处理”信息。这里给出了该体系结构及其相应出版物的全面概述。
鉴别器是一个截断的网络,输出对多个补丁图像的判断,而不是对整个图像的判断。因此,鉴别器向生成器提供详细的反馈,指出哪些区域看起来是真实的,哪些区域看起来是伪造的。可以在此处找到该体系结构内部细节的完整概述。
与原始网络相比,我们进行了以下更改:
- 我们使用了Y型网络。一个编码器,两个解码器和两个鉴别器。这样一来,即可解决阴影和区域问题。
- 使用分叉架构,每个分支都有两个损失。同样,我们使用L2范数代替L1范数,因为它显示出更好的结果。
- 原始论文使用LeakyReLU单位。我们使用了ELU单位。
- 在编码器中,我们对每次下采样使用了两次卷积运算,而不是一次卷积。
数据集

在Trajes Fatais游戏中,我们选择了Sarah和Lucy角色作为数据集,以评估Pix2Pix体系结构。莎拉(Sarah)角色只有87个完成的精灵,还有207个需要绘制。它也是一个中等复杂的图片,具有多个平滑复杂的区域。另一方面,露西(Lucy)角色已完成,因此它具有530个完全绘制的精灵,并且非常容易绘制,具有大部分平滑的特征。
从某种意义上说,露西是我们的上限。它具有我们希望得到的所有数据,并且很容易绘制。如果该算法无法处理露西,那么其他任何数据都可能会失败。相比之下,莎拉是我们常见的情况:一个中等复杂的人物,只有几十个精灵可以训练。如果算法对莎拉有用,那么它可能对我们有价值。
结果

可以看出,该算法对于阴影问题和区域精灵的问题具有很好的结果。因为颜色变化了,并且精灵周围有一些噪声。对于着色精灵,只检测到了较小的问题,例如第二行中的肩膀和腿部。

在第二批中,可以找到更多问题。在生成的阴影列中,可以在阴影区域看到许多伪图像,例如在女孩(第一个行),鸭嘴兽的背部(第2行)和鸭嘴兽的喙(第3行)上。对于彩色画面,会存在大量噪声,使这些子画面无法使用,因为人类很难去除噪声。

第三批的作品来自207个精灵,仅提供艺术线条。因此,这些需要主观分析来评价效果。这些行分别由类似于训练中使用的子图形,以前不曾看到的精灵的子图形和其他精灵的子图形组成。
尽管第一行最有用,但是第二和第三行上的彩色图像会迅速恶化。着色精灵的质量基本保持一致。但是,着色精灵的第三列不一致。第二行中的正面小精灵的脸应更亮,并且右下角的小精灵的亮度不连续。
现在,我们可以确定的假设着色精灵可以使用,但是区域精灵却不能使用,因为它们噪声太大并且存在色移问题。让我们将注意力转移到露西。
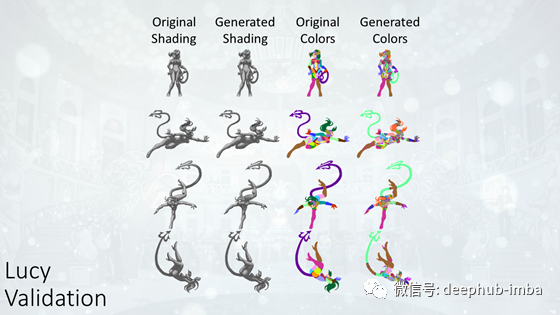
露西精灵的数据多了五倍,与莎拉相比改善更加明显。阴影精灵几乎完美,阴影区域的毛发很小,头发的差异可忍受。但是,区域精灵仍然远非最佳。色移问题和噪点仍然存在。这表明增加数据集大小并不能使这些问题得到明显改善。
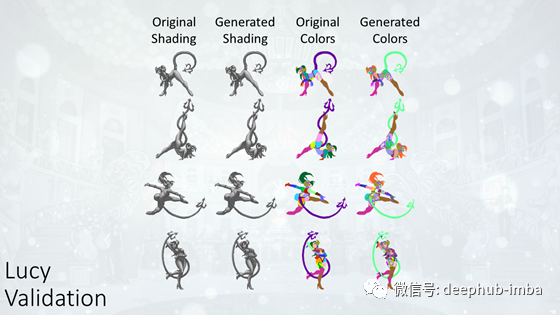
第二批包含我们手动选择的精灵,因为它们与大多数其他精灵有很大的不同。尽管如此,阴影精灵仍然与人类绘制的精灵几乎相同。彩色图像的质量也并没有像莎拉一样严重下降。但是,它仍然远远达不到理想的结果。
考虑到这些结果,可以说增加数据集的大小可以显着改善阴影,但不能改善区域。由于露西是我们的最佳情况,因此可以假设我们需要另一个问题表述/体系结构来解决区域精灵问题。
为了更客观地量化所生成内容的质量,我们计算了两个数据集的MSE,MAE和SSIM分数。
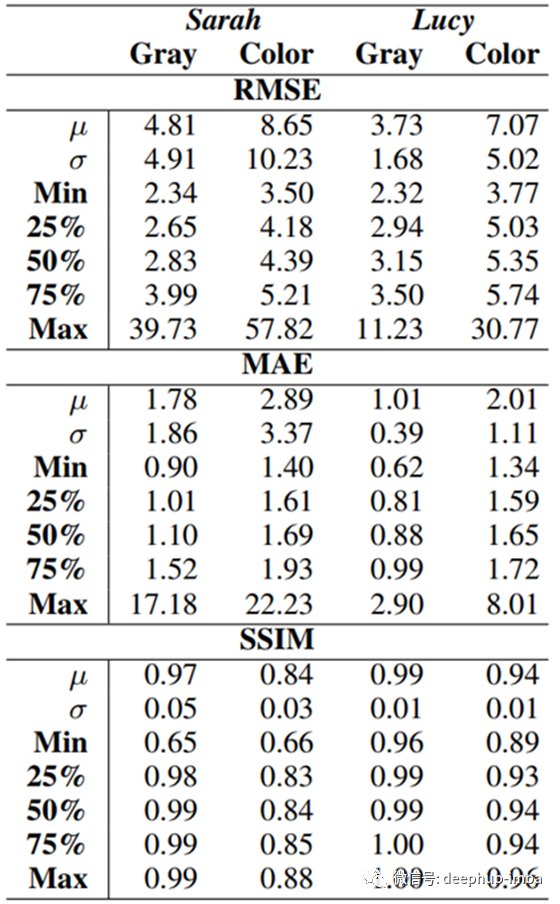
从表中可以看出,在所有这三个指标上,阴影精灵的均值(μ)和方差(σ²)比彩色图像更好。同样,75%的四分位数与最大可见值之间的差异很大,这表明分布偏斜。
此外,露西(Lucy)的结果始终好于莎拉(Sarah)的结果,其方差低得多,而且歪斜度也大大降低。
SSIM评分的范围从0(完全不相似)到1(完全相同),并衡量两个图像的感知相似度。虽然MSE和MAE纯粹是数学概念,但SSIM分数与人类感知更加相关。在表中,阴影精灵的得分接近1,表明它们与平均观察者几乎相同,而彩色图像则并非如此。
作为第三次也是最后一次评估,我们要求设计团队对207个为莎拉生成的精灵进行评论。他们的反馈意见大多是积极的,称赞了着色精灵的质量并丢弃了彩色精灵。总之,他们发表了四点评论:
- 几乎一半的着色精灵有用,可以在20到30分钟内完善。彩色精灵不可用。
- 该算法在单个动画中效果不稳定,这可能会使子画面失效。某些姿势下即使是着色精灵也会产生可怕的结果。将色彩数量固定为使用6和42种颜色时,会引入一些不必要的噪音。
下图说明了观点2、3和4。

八帧动画中的身体明亮度不一致
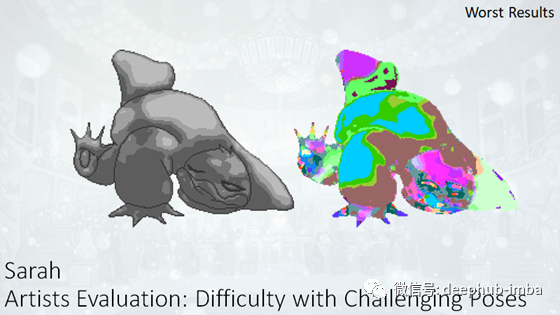
使用与训练中使用的姿势相差太大的姿势会产生较差的结果。

在量化为6和42种颜色数量时,会引入一些噪音。在轮廓中可以很容易看到。
结论
在这项工作中,我们评估了使用现代生成模型来解决像素艺术生成问题的效果。即,我们采用了改进的Pix2Pix架构,取得了一定程度的效果。更详细地讲,着色精灵被艺术团队认为是有用的,而彩色小精灵则被认为是无用的。
对于着色精灵,团队提出平均需要20到30分钟来完善每一个精灵,比从头开始绘制一个要少10到30分钟。保守的估计是,每个有用的精灵都会节省10分钟的劳动时间,这意味着生产力提高了约15%。
尽管具有更多的颜色,但对于设计团队而言,区域精灵所花费的时间并不多于着色精灵。正如首席美术师所解释的那样,动画中的区域更容易预测,并且可以轻松地从一个精灵复制到另一个精灵。因此,不生成它们不是大问题。
从技术角度来看,这项工作证明了当前模型可以有效地用作创造性任务的助手。其他动漫领域也发现了类似的结论,动漫领域主要是由平坦而丰富的颜色组成,并且比像素艺术具有更少的限制。此外,Pix2Pix模型适用于现实世界的图片,也适用于像素艺术和动漫数据,这证明了其普适性。
未来的工作
我们当前的系统基于Pix2Pix模型,基于像素。但是,我们的问题可以根据图像分割名词来表述为按像素分类。这样的思路可能会大大改善我们的结果。
有时,简化问题可能使其更易于处理。区域精灵共有42种颜色,但每个精灵仅出现大约十二种颜色,并且这些颜色占据所有精灵中很大一部分。将问题缩小为更具选择性的阴影可能会减轻生成器的工作压力。
Pix2Pix创始于2017年。自那时以来,GAN取得了一些进步,包括更好的损失函数,注意力机制和改进的方法。使用更先进的技术可能会大大改善结果。
U-Net和Pix2Pix的参考资料
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation” 2016
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks” 2017
作者:Ygor Rebouças Serpa
deephub翻译组:孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********