
文章目录
1. 第一章行为决策在自动驾驶系统架构中的位置
Claudine Badue[1]等人以圣西班牙联邦大学(UFES)开发的自动驾驶汽车(Intelligent Autonomous Robotics Automobile,IARA)为例,提出了自动驾驶汽车的自动驾驶系统的典型架构。如图所示,自动驾驶系统主要由感知系统(Perception System)和规划决策系统(Decision Making System)组成。感知系统主要由交通信号检测模块(Traffic Signalization Detector,TSD)、移动目标跟踪模块(Moving Objects Tracker,MOT)、定位与建图模块(Localizer and Mapper)等组成。规划决策系统主要由全局路径规划模块(Route Planner)、局部路径规划模块(Path Planner)、行为决策模块(Behavior Selector)、运动规划模块(Motion Planner)、自主避障模块(Obstacle Avoider)以及控制模块(Controller)组成。
图1-1 自动驾驶系统架构图
行为决策在此架构中主要是由行为决策模块完成的。行为决策模块负责选择当前的驾驶行为,如车道保持、十字路口处理、红绿灯处理等。该模块选取一组路径
P
P
P中的一条路径
p
j
p_j
pj,以及
p
j
p_j
pj中的一个位姿点
p
g
p_g
pg,该位姿点大致位于汽车决策前的5s左右(这被称为决策视野),并设立目标速度与目标位姿
G
o
a
l
g
=
(
p
g
,
v
g
)
Goal_g=(p_g,v_g)
Goalg=(pg,vg)。行为决策模块选择一个考虑当前驾驶行为的目标路径,并在决策视野内避免与环境中静态和移动障碍物的碰撞。
2. 行为决策算法的种类
行为决策模块负责选择当前的驾驶行为,如车道保持、十字路口处理、红绿灯处理等。该模块选取一组路径
P
P
P中的一条路径
p
j
p_j
pj,以及
p
j
p_j
pj中的一个位姿点
p
g
p_g
pg,该位姿点大致位于汽车决策前的5s左右(这被称为决策视野),并设立目标速度与目标位姿
G
o
a
l
g
=
(
p
g
,
v
g
)
Goal_g=(p_g,v_g)
Goalg=(pg,vg)。行为决策模块选择一个考虑当前驾驶行为的目标路径,并在决策视野内避免与环境中静态和移动障碍物的碰撞。
自动驾驶行为决策不得不考虑一些有关伦理道德的问题,例如,当自动驾驶汽车发生交通事故时,应该优先保护其他交通参与者——行人的安全还是优先保护自己车上乘客的安全?
图2-1 应该优先保护乘客还是行人?
E. Awad团队
[2]通过从年龄、教育、性别、收入、政治和宗教等多个方面对调查人员进行标记,并统计他们的选择(选择左边代表优先保护乘客,选择右边代表优先保护行人)。据他们的统计发现,更多的人们倾向于保护行人,尤其是婴幼儿、男孩、女孩等未成年人。 图2-2 优先保护对象的统计图
图2-2 优先保护对象的统计图
自动驾驶汽车必须处理各种道路和城市交通情况。许多文献将行为选择问题根据不同的交通场景进行划分,以便解决问题,这类方法成为集中式决策。集中式决策中主要有基于规则的决策算法和基于统计的决策算法。还有一些文献采用的是端到端的方法,例如使用CNN
[3]来处理自动驾驶的相关问题。 图2-3 CNN架构图,该网络大约有2700万个连接和25万个参数
图2-3 CNN架构图,该网络大约有2700万个连接和25万个参数
在DARPA城市挑战赛,用于不同驾驶场景的主要方法有启发式组合法
[4]、决策树
[5,6]、有限状态机(FSM)
[7]和贝叶斯网络
[5]。上述的这些方法在一些简单的、限定的场景里可以实现,表现良好,但对复杂场景,例如中高密度的城市路网交通流,算法的稳定性与适应性就稍欠理想。
此外,近年来,基于状态机的方法得到改进并与其他方法融合,以应对更多的真实城市交通场景,例如X. Han[8]等人在现有研究的基础上,提出了一种通过层次框架具有组织行为的综合多车道平台算法。该算法在战略任务层面上,开发了一种基于确定性有限状态机(FSM)的平台化行为协议来指导成员的操作。此外,他们以FSM为基线训练遗传模糊系统,以扩展算法在入口匝道合并场景下的能力。基于本体论[9](Ontologies-based)的方法同样也可以作为一个场景建模的工具。该方法主要基于知识库进行行为决策。
除此之外,一些方法考虑了决策过程中的其他交通参与者的决策意图以及运动轨迹的不确定性,例如马尔可夫决策过程[10](MDP)和部分可观察马尔可夫决策过程11。
2.1 基于规则的决策算法
2.1.1 决策树
决策树是依据决策建立起来的、用来分类和决策的树结构。概括地说,决策树算法的逻辑可以描述为if-then, 根据样本的特征属性按照“某种顺序”排列成树形结构,将样本的属性取值按照if-then逻辑逐个自顶向下分类,最后归结到某一个确定的类中[5]。“某种顺序”是指决策树的属性选择方法。以二叉决策树为例,树形结构由结点和边组成,决策树的结点代表分类问题中样本的某个属性,边的含义为是与否两种情况,即样本属性取值是否符合当前分类依据。
决策树学习的关键在于选择划分属性。属性的选择流程可简略表述为:首先,计算训练样本中每个属性的“贡献度”,选择贡献最高的属性作为根结点。根结点下扩展的分支将依据根结点所代表属性的取值决定。然后,将已经被选择为结点的属性从候选属性集中剔除,接着不断重复进行候选属性集合中剩余属性的“贡献度”的计算和选择,直至达到预设的模型训练阈值(例如达到决策树最大深度)。最后,得到一棵能较好地拟合训练样本分布的决策树模型。
常见的决策树算法有以下三种:
- ID3(iterative dichotomiser 3)算法:
信息增益大的属性优先。首先,计算所有候选属性的信息增益,选择其中信息增益最大的属性作为根结点。然后,按照根结点所代表属性的取值决定分支情况。其次,将已选择属性从候选集中删除,并计算剩余属性的信息增益。最后,选择信息增益最大的结点作为子结点,直至所有属性都已选择。信息熵是用来衡量样本纯度指标的,是计算信息增益的前提,定义为:
E
n
t
(
D
)
=
−
∑
K
=
1
∣
K
∣
p
k
log
2
p
k
Ent(D) = - \sum\limits_{K = 1}^{\left| K \right|} {{p_k}{{\log }_2}{p_k}}
Ent(D)=−K=1∑∣K∣pklog2pk式中
D
D
D——样本集合;
p
k
——
D
p_k——D
pk——D中第
k
k
k类样本所占的比例,其计算方式为:
p
k
=
∣
C
k
∣
∣
D
∣
{p_k} = \frac{{\left| {{C_k}} \right|}}{{\left| D \right|}}
pk=∣D∣∣Ck∣式中
C
k
C_k
Ck——集合D中属于第k类样本的样本子集。
假设
D
D
D中某个具有
V
V
V个取值的属性为
A
A
A,取值分别为
a
1
,
a
2
,
…
,
a
V
{a_1,a_2,…,a_V}
a1,a2,…,aV。根据不同的取值将
D
D
D中的样本划分为
V
V
V个子集。其中,取值为
a
v
a_v
av的样本属于第
v
v
v个子集,记作
D
v
D_v
Dv。
根据式(2-1)可以计算出样本
D
v
D_v
Dv的信息熵。通过增加各分支权重
∣
D
v
∣
/
∣
D
∣
|D_v|/|D|
∣Dv∣/∣D∣使样本数量多的结点具有更大的“影响”。首先,计算属性
A
A
A对于数据集
D
D
D的条件熵
E
n
t
(
D
∣
A
)
Ent(D|A)
Ent(D∣A):
E
n
t
(
D
∣
A
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
(
∑
k
=
1
K
∣
D
v
k
∣
∣
D
v
∣
log
2
∣
D
v
k
∣
∣
D
v
∣
)
\begin{array}{c}Ent(D|A) = \sum\limits_{v = 1}^V {\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}} Ent({D^v})\\ = - \sum\limits_{v = 1}^V {\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}} \left( {\sum\limits_{k = 1}^K {\frac{{\left| {{D^{vk}}} \right|}}{{\left| {{D^v}} \right|}}{{\log }_2}\frac{{\left| {{D^{vk}}} \right|}}{{\left| {{D^v}} \right|}}} } \right)\end{array}
Ent(D∣A)=v=1∑V∣D∣∣Dv∣Ent(Dv)=−v=1∑V∣D∣∣Dv∣(k=1∑K∣Dv∣∣Dvk∣log2∣Dv∣∣Dvk∣) 再计算用属性
a
a
a对样本集合
D
D
D进行划分所得的信息增益=信息熵-条件熵:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
E
n
t
(
D
∣
A
)
Gain(D,a) = Ent(D) - Ent(D|A)
Gain(D,a)=Ent(D)−Ent(D∣A) 通过对所有属性的信息增益进行计算,选择信息增益最大的属性作为结点添加入树,重复进行属性的信息增益计算和选择过程,最终构建出一棵分类决策树。
- C4.5算法:
信息增益率大于平均值的属性优先。信息增益率即为各属性信息增益所占比例。因此,属性取值的个数越少,信息增益率反而越高,这就导致信息增益率准则更偏向于取值个数少的属性。因此,在ID3算法中各属性信息增益计算的基础上,C4.5算法运用了一个启发式原则:首先,计算每个属性的信息增益率,进而计算所有属性的平均信息增益率。然后,按照信息增益率与平均信息增益率的大小关系,将属性分为两类。最后,选择信息增益率大于平均值,且数值最大的属性。信息增益率的计算方式为:
G
a
i
n
r
a
t
i
o
(
D
,
A
)
=
G
a
i
n
(
D
,
A
)
H
A
(
D
)
Gai{n_{ratio}}(D,A) = \frac{{Gain(D,A)}}{{{H_A}(D)}}
Gainratio(D,A)=HA(D)Gain(D,A) 式中
H
A
(
D
)
H_A(D)
HA(D)——与属性
A
A
A有关的定值。通常,取值为样本集合
D
D
D的信息熵:
H
A
D
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
log
2
∣
D
v
∣
∣
D
∣
{H_A}D = - \sum\limits_{v = 1}^V {\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}} {\log _2}\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}
HAD=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣ 施发园[6]基于C4.5算法,以目标车道后方车辆与换道车辆横向距离
X
1
X_1
X1、目标车道后方车辆与换道车辆纵向距离
Y
1
Y_1
Y1、目标车道前方车辆与换道车辆纵向距离
Y
2
Y_2
Y2、目标车道后方车辆与换道车辆速度差
v
1
v_1
v1、目标车道前方车辆与换道车辆速度差
v
2
v_2
v2、目标车道后方车辆与换道车辆加速度差
a
1
a_1
a1、目标车道前方车辆与换道车辆加速度差
a
2
a_2
a2等作为影响因素进行分类。得到的“if-then”分类规则如表2-1所示。
表2-1决策树分类规则
- 分类与决策树(classification and regression tree, CART)算法:
该算法以基尼指数小的属性优先。CART不再以信息增益为基础进行属性的选择,而是采用一种代表样本不纯度的指标对属性进行度量,这种不纯度指标叫做基尼指数。基尼指数越小代表样本的纯度越高。基尼指数的定义为:
G
i
n
i
(
D
)
=
1
−
∑
k
=
1
K
∣
D
v
∣
∣
D
∣
(
∣
C
2
∣
∣
D
∣
)
G
i
n
i
(
D
∣
A
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
\begin{array}{l}Gini(D) = 1 - \sum\limits_{k = 1}^K {\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}} \left( {\frac{{\left| {{C_2}} \right|}}{{\left| D \right|}}} \right)\\Gini(D|A) = \sum\limits_{v = 1}^V {\frac{{\left| {{D^v}} \right|}}{{\left| D \right|}}} Gini({D^v})\end{array}
Gini(D)=1−k=1∑K∣D∣∣Dv∣(∣D∣∣C2∣)Gini(D∣A)=v=1∑V∣D∣∣Dv∣Gini(Dv)
2.1.2 有限状态机(FSM)
在FSM方法中,采用基于规则的决策过程来选择不同交通场景流下的决策行为。将各个驾驶行为用状态表示,状态转移条件则是来自于由感知信息得到的离散规则,当前状态则定义了汽车的当前行为。该方法的主要缺点是难以模拟实际交通中的不确定性和复杂的城市交通情景。
斯坦福大学的Junior 将车辆行为细分,建立了一个拥有13个状态的有限状态机组成决策系统[7],如图2-4所示。其状态分别为:初始状态、前向驾驶、车道跟随、避障、停止标志前等待、路口处理、等待路口空闲、掉头、车辆在掉头线前停止、越过黄线行驶、在停车区域内行驶、通过交通阻塞路段、在不匹配RNDF 路网文件的情况下在路上行驶、任务结束。
图2-4 FSM状态转移图(图中只显示了11个)。初始状态(LOCATE_VEHICLE)、前向驾驶(FORWARD_DRIVE)、车辆在掉头线前停止(UTURN_STOP)、通过交通阻塞路段(CROSS_DIVIDER)、停止标志前等待(STOP_SIGN_WAIT)、掉头(UTURN_DRIVE)、路口处理(CROSS_INTERSECTION)、任务结束(MISSION_COMPLETE)、 等待路口空闲(STOP_FOR_CHEATERS)、在停车区域内行驶(PARKING_NAVIGATE)、在不匹配RNDF路网文件的情况下在路上行驶(BAD_RNDF)
为了解决更为复杂的问题,Ziegler[12]采用了分层并行状态机(HSM)的方法。在该方法中,行为选择模块生成一系列约束,这些约束来自这些分层并行状态机,并用作轨迹优化问题的输入。这些约束是由行为选择模块制定的,它考虑了诸如驾驶走廊的特征、静态和移动障碍物以及生成或合并规则等信息。他们的状态图如图2-5所示。
图2-5 分层并行状态机(HSM)的状态图
Okumura等人将FSM与支持向量机(SVM)结合起来,构建了一个针对环形路情况下的高级行为选择器过程的分类器[13]。首先,SVM分类器将当前的机器人状态和感知数据映射到一个动作,然后由FSM处理该动作,以输出控制指令。
2.1.3 基于本体论(Ontologies-based)
本体是知识表示的框架,可以用于建模概念及其关系。Zhao等人[9]使用基于本体的知识库对交通法规和传感器数据进行建模,以帮助自动驾驶汽车了解世界。为了构建决策系统,他们手动构建了基于本体的知识库,主要关注发生在十字路口和狭窄的道路上的交通情况。该系统会考虑车辆的通行权,并将“停车”、“左转”或“让路”等决策发送给路径规划系统,以改变路线或停车以避免碰撞。这种方法的缺点是需要设计一个精确的世界模型,由每个位置的映射车道和交通规则组成,而这通常是由人类手动完成的,工作量大且复杂。他们主要设计两个本体——地图和控制模块,针对不同的驾驶场景进行分类,如图2-6所示。
图2-6 地图和控制本体(Ontology)的设置以及地图本体的相关例子
2.2 基于统计的决策算法
2.2.1 贝叶斯网络(BN)
BN是一种以贝叶斯公式为基础的概率图模型,BN的结构是一个有向无环图(directed acyclic graph, DAG),图中结点被称为BN结点,若结点之间存在依赖关系,则由一条有向边连接,方向为被依赖结点指向依赖结点[5]。BN的参数由结点的概率值和结点间的条件概率表(conditional probability table, CPT)组成,用来描述属性的联合概率分布。基于BN的行为决策模型主要包括BN学习阶段与BN的驾驶行为决策阶段。
BN通过有向边将网络中各个结点连接起来,当其中的 某个结点状态发生变化时,与其直接或间接相连的结点也会随之更新,这个过程称为贝叶斯推理。推理的前提是构建出符合问题需求的 BN模型,为了充分利用BN概率推理 的能力,学习得到一个好的DAG和CPT十分重要。
BN的学习阶段分为结构学习和参数学习。
结构学习是指构建出符合问题需求的DAG结构,常用方法为基于采样的马尔可夫链蒙特卡洛(Markov chain Monte Carlo, MCMC)方法。参数学习是指在已知贝叶斯网络结构的情况下,构建当前结构各结点代表的属性之间的CPT,目前最常用的参数学习方法为最大似然估计(maximum likelihood estimation, MLE)。
BN训练好(即结构和条件概率表确定)后,便可以用来进行“查询”即概率 推理,通过一些属性变量的观测值来推测其他属性变量的取值,这个过程被称为贝叶斯推断,属性变量观测值称为“证据”。
在自动驾驶行为决策中,根据驾驶场景信息进行BN学习,结合先验知识进行最优结构筛选。然后,将学习到的BN模型导出。最后,将传感器实时数据和人工驾驶行为预测结果输入到模型中,进行BN概率推理,获得最优驾驶动作。其决策框架如图2-7所示。
图2-7 BN决策模型框图
2.2.2 马尔可夫决策过程(MDP)
马尔可夫决策过程数学框架广泛应用于随机控制理论的离散事件系统,该数学框架适用于系统输出结果部分随机并且决策部分可控的情况[14]。在马尔可夫链中引入动作和报酬便可以构造出 MDP,所以MDP和马尔可夫链同样具有马尔可夫性,即系统的下一个状态只与当前状态和当前执行的动作有关。马尔可夫决策过程的理论基础完善且研究成果众多,其模型可以用一个四元组表示:
{
S
,
A
(
i
)
,
p
(
j
∣
i
,
a
)
r
(
i
,
a
)
}
{\rm{\{ }}S, A(i),p(j|i,a)r(i, a){\rm{\} }}
{S,A(i),p(j∣i,a)r(i,a)} 式中
S
S
S——系统的有限状态空间;
A
(
i
)
A(i)
A(i)——系统所有可能选取动作的集合,状态
i
∈
S
i \in S
i∈S ;
p(j|i,a)——系统的状态转移概率,其中状态
i
,
j
∈
S
i, j \in S
i,j∈S,动作
a
∈
A
(
i
)
a \in A(i)
a∈A(i);
r
(
i
,
a
)
r(i,a)
r(i,a)——系统在状态i时执行动作
a
a
a后获得的期望总报酬。
其中系统被假定为由基础马尔可夫链驱动,具体的马尔可夫链(状态-动作序列)运行过程如图2-8所示。在离散的时间步长,系统从当前状态随机跳转到下一个状态的转移概率与其之前的状态无关,仅是取决于系统当前的状态。
图2-8 马尔可夫链运行过程示意图
Brechtel提出了一种交通环境中的高层决策制定方法[10],采用了马尔可夫决策过程(MDP),通过评估行动的结果来规划最优策略。该方法从编码为动态贝叶斯网络(DBN)的复杂连续时间模型中推导出抽象的符号状态,并将离散的MDP状态用随机变量来解释,将连续世界用DBN描述,离散世界用MDP描述,并将两者相结合。该方法不依赖于精确的场景描述与识别,具有良好的鲁棒性。
2.2.3 部分可观察马尔可夫决策过程(POMDP)
部分可观察马尔可夫决策过程(POMDP)框架不仅解决了状态间转移中的不确定性,而且还解决了感知中的不确定性。该算法还将值迭代算法推广到估计最优控制策略[15]。
Brechtel使用了一种连续的POMDP方法来推理潜在的隐藏对象和观察的不确定性,并考虑到交通参与者之间的相互作用[11]。他们的方法分为以下两步,在第一步中,回报函数旨在通过返回加速和减速的成本以达到目标区域来优化舒适度和效率。此步骤仅依赖于车辆的状态和先前定义的目标。在第二步中,通过与其他交通参与者增加更高的碰撞成本来考虑其他交通参与者。通过将两步的代价值合并为一个回报函数,进行优化。为了将驾驶的任务表述为一个连续的POMDP,就必须定义空间和模型。图2-9概述了空间和模型之间的关系。

图2-9 动态贝叶斯网络的POMDP模型。
S为状态,O为输出,A为动作,R为回报函数。
2.3 基于端到端的决策算法
基于规则的决策模型实时性好,搭建简单,但是已有的规则都是研究人员针对特定场景手工设定的,不能达到经验驾驶员决策效果,而基于统计的决策模型由于从驾驶员数据出发,能够处理一些具有不确定因素存在的场景,并可以减小不确定性因素影响,但计算量大、实时性差[16]。
基于规则的决策方法通过构建规则库的方法进行自动驾驶决策。通过对自动驾驶车可能遇到的情况进行统计,然后建立车辆行驶状态与对应策略之间的规则,进而采用这些规则进行自动驾驶车的控制[17]。但是现实的驾驶环境是复杂多变的,想要完整构建规则库是不现实的,而且当自动驾驶车遇到规则库里所没有出现的情况时,会增加事故发生的概率。因此,基于规则的自动驾驶系统无法满足人们的需求。
基于统计的决策方法可以减少不确定性带来的影响,但这种方法需要大量数据,而且方法的有效性与数据质量有很大关联,通常来说数据量越大、覆盖范围越广、分布越均匀方法的有效性越好,然而在现实情况中,采集大量数据并对数据进行预处理;有很大困难,采集的数据通常具有一定特殊性,因此基于统计的决策方法前期需有大量工作,不能快速实现功能,而且模型一旦形成不能及时更改。
与基于基于规则的决策方法相比,深度学习则无需人为构建规则库,通过神经网络来实现端到端的控制无人驾驶车辆。但深度学习算法需要庞大的数据集支撑,且无法适应复杂多变的道路交通场景,训练出来的无人驾驶车辆鲁棒性和自我探索性有所不足。
相比于深度学习,强化学习则无需训练数据,无人驾驶车辆的探索性也较强,但前期训练时需要耗费大量试错成本。在强化学习基础之上,一些学者将深度学习和强化学习结合,提出深度强化学习算法。
J.Hu等人[18]提出了一个端到端自动驾驶网络(BGNet),它可以从专家演示(数据集)中学习类似于专家的驾驶动作。所提出的BGNet通过增强对环境的场景理解,进一步推动了基于视觉的自动驾驶任务的可解释性。具体来说,视觉引导路径(VGP)提出学习的空间语义占领识别对象的原始视觉输入描述视觉场景的直观状态,和驾驶费用路径(DAP)提出利用几个环境的影响指标来表示环境的约束当前驾驶行为。视觉导向路径和驾驶启示路径相互互补,以获得更高的性能。通过这两条路径,BGNet可以实现从视觉输入到驾驶导航的完整映射。该方法的架构图如图2-10所示。
图2-10 端到端自动驾驶架构图
M.Park等人[19]创建了一个基于真实驾驶数据的端到端自动驾驶算法,并分析了我们提出的算法的性能。基于从实际的城市驾驶环境中获得的数据,通过基于卷积神经网络预测车辆控制值,可以在一些非正式环境中实现端到端自动驾驶。
图2-11 基于真实驾驶数据的端到端自动驾驶架构
Q-learning算法是一种基于值函数的强化学习算法。Matzliach[20]提出了Deep-Q-learning算法,解决了在不确定环境下,自主移动智能体对多个静态和移动目标的检测问题,以最大限度地增加关于目标位置的累积信息增益,并以预定义的检测概率最小化地图上的轨迹长度。图2-12描述了基于Deep-Q-learning的算法架构。

(a)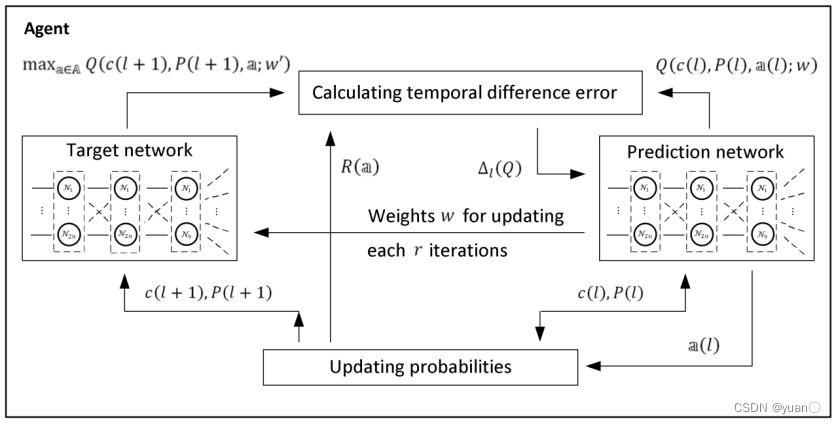 (b)
(b)
图2-12 基于Deep-Q-learning算法的算法架构
(a)基于在线地图实现;(b)基于离线地图实现
参考文献
[1] C. Badue, et al. Self-driving cars: A survey[J]. Expert Systems with Applications, 2021, 165.
[2] E. Awad, et al. The Moral Machine experiment[J]. Nature, 2018, 563(7729): 59-64.
[3] Karol Zieba, et al. End to End Learning for Self-Driving Cars[J]. NVIDIA Corporation Holmdel, NJ 07735, arXiv:1604.07316v1 [cs.CV] 25 Apr 2016.
[4] Urmson, C., Anhalt, J., Bagnell, D., Baker, C., Bittner, R., Clark, M., Dolan, J.,Duggins, D., Galatali, T., & Geyer, C. Autonomous driving in urban environments: Boss and the urban challenge[J]. Journal of Field Robotics, 2008, 25(8), 425–466.
[5] 刘延钊,黄志球,沈国华,王金永,徐恒.基于决策树和BN的自动驾驶车辆行为决策方法[J].系统工程与电子技术,2022,44(10):3143-3154.
[6] 施发园,陈凌珊.基于决策树对车辆换道的研究分析[J].农业装备与车辆工程,2020,58(05):85-88.
[7] Montemerlo, et al. , & Huhnke, B.Junior: The stanford entry in the urban challenge[J]. Journal of Field Robotics, 2008,25(9), 569–597.
[8] X. Han, et al. Strategic and tactical decision-making for cooperative vehicle platooning with organized behavior on multi-lane highways[J]. Transportation Research Part C: Emerging Technologies, 2022, 145.
[9] Zhao, L.,et al. & Sasaki, Y. Ontology-based decision making on uncontrolled intersections and narrow roads[J]. IEEE intelligent vehicles symposium (IV),2015, 83–88.
[10]Brechtel, S., Gindele, T., & Dillmann, R. Probabilistic mdp-behavior planning for cars[C]. In 2011 IEEE 14th International Conference on Intelligent Transportation Systems (ITSC) ,1537–1542.
[11]Brechtel, S., Gindele, T., & Dillmann, R.Probabilistic decision-making under uncertainty for autonomous driving using continuous pomdps[C]. In 17th international IEEE conference on intelligent transportation systems (ITSC), 392–399.
[12]J. Ziegler, et al. Making Bertha Drive—An Autonomous Journey on a Historic Route[J]. IEEE Intelligent Transportation Systems Magazine, 2014, 6(2): 8-20.
[13]B. Okumura, et al. Challenges in Perception and Decision Making for Intelligent Automotive Vehicles: A Case Study[J]. IEEE Transactions on Intelligent Vehicles, 2016, 1(1): 20-32.
[14]杨家源. 半Markov决策过程强化学习算法研究[D].哈尔滨工业大学,2018.
[15]Thrun, S., Burgard, W., & Fox, D. Probabilistic robotics[M]. MIT press,2005.
[16]袁盛玥. 自动驾驶车辆城区道路环境换道行为决策方法研究[D].北京理工大学,2016.
[17]王丙琛. 基于深度强化学习的自动驾驶决策控制研究[D].大连理工大学,2020.DOI:10.26991/d.cnki.gdllu.2020.002159.
[18]J. Hu, et al. Enhancing scene understanding based on deep learning for end-to-end autonomous driving[J]. Engineering Applications of Artificial Intelligence, 2022, 116.
[19]M. Park, H. Kim,S. Park. A Convolutional Neural Network-Based End-to-End Self-Driving Using LiDAR and Camera Fusion: Analysis Perspectives in a Real-World Environment[J]. Electronics, 2021, 10(21).
[20]Matzliach, B.; Ben-Gal, I.; Kagan, E. Detection of Static and Mobile Targets by an Autonomous Agent with Deep Q-Learning Abilities[J]. Entropy 2022, 24, 1168. https://doi.org/10.3390/e24081168
版权归原作者 yuan〇 所有, 如有侵权,请联系我们删除。