
多 Agent 流水线在每一次演示中都表现正常。但是到了生产环境,它可能在第四步之前就悄悄积累了三个错误决策,最终输出自信、流畅但是完全错误。并且最后没有人发现问题,因为根本没有信号可以捕捉链条末端只剩下一个看起来干干净净的结果。
这是 2026 年生产级 Agent 系统最典型的失败模式。正确构建验证层需要理解四种不同的架构模式、各自的失效边界,以及一个被多数团队忽视的规律。
为什么模型无法可靠地检查自己的工作
让 LLM 验证自身输出,它往往会同意自己。原因不在于它认真检查过,而在于结构上的倾向性,并且使用更好的提示词也改不了这一点。
同一个模型同时扮演生成器、评估器和批评者,倾向于在多次迭代中复现同样的推理结构,修正幅度极其有限。如果第一次推理就出了错,导致错误的那些表征偏差在重新评估时依旧存在。针对单 Agent Reflexion 的研究表明,自我反思大多只是重复先前的错误认知,很少引入新的推理路径。
多 Agent 验证之所以能在自我纠正失败的地方生效,机制就在于多样性:第二个 Agent 带着不同的角色设定、上下文甚至人设介入,对同一份输出给出截然不同的推理路径。
还有一层架构上的区别,传统评估只看最终输出但对于运行长序列动作的 Agent——研究工作流、编程助手、多步骤规划器——仅关注终点会遮蔽出错的位置。等到评估最终答案时,三步之前的根本原因早已不可见。正是这个缺口催生了过程验证的思路:逐步评估,而非只检查终态。
四种验证模式
以下逐一分析每种模式及其真实的权衡取舍。
模式 1:输出评分(LLM-as-Judge)
最简单的验证架构。一个独立 LLM 根据结构化评分标准对求解器的输出打分,超过阈值则放行,低于阈值则令求解器重试。
from langchain_anthropic import ChatAnthropic
from langchain_core.prompts import ChatPromptTemplate
judge_llm = ChatAnthropic(model="claude-haiku-4-5") # 小模型,成本更低
JUDGE_PROMPT = ChatPromptTemplate.from_messages([
("system", """You are a strict quality judge. Evaluate the response below on:
- Factual accuracy (0-10)
- Completeness (0-10)
- Logical consistency (0-10)
Respond ONLY with JSON: {"score": <average>, "reason": "<one sentence>"}"""),
("human", "Task: {task}\n\nResponse to evaluate:\n{response}")
])
def judge_output(task: str, response: str) -> dict:
chain = JUDGE_PROMPT | judge_llm
result = chain.invoke({"task": task, "response": response})
import json
return json.loads(result.content)
# 用法
verdict = judge_output(
task="Summarize the key risks in this contract",
response=solver_output
)
# {"score": 6.3, "reason": "Missing indemnification clause analysis"}
适用于需要低成本、快速门控的高吞吐量场景:客户支持分流、文档分类、大规模代码审查。
失效之处在于:单个 LLM 评判者自带见——偏好特定写作风格或内容类型——且只能代表一个视角。研究显示 GPT-4 的判断在总体统计上与人类偏好相关性很高,但在边缘案例上分歧明显。流畅而自信的幻觉往往也能拿到高分,因为评判者同样受流畅性偏差的影响。
模式 2:Reflexion(自我批评循环)
Reflexion在每轮尝试之间嵌入了结构化的自我批评步骤。求解器生成回答,批评者给出文字反馈,求解器再带着反馈重试。
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
task: str
attempts: Annotated[list, operator.add]
reflections: Annotated[list, operator.add]
current_output: str
iteration: int
passed: bool
def solver_node(state: AgentState) -> AgentState:
context = ""
if state["reflections"]:
context = f"\n\nPrevious attempt failed. Feedback:\n{state['reflections'][-1]}\nTry again."
response = solver_llm.invoke(state["task"] + context)
return {
"current_output": response.content,
"attempts": [response.content],
"iteration": state["iteration"] + 1
}
def reflexion_node(state: AgentState) -> AgentState:
critique_prompt = f"""
Task: {state['task']}
Response: {state['current_output']}
Identify specific errors. Be concise and actionable.
"""
critique = critic_llm.invoke(critique_prompt)
score = judge_output(state["task"], state["current_output"])
return {
"reflections": [critique.content],
"passed": score["score"] >= 7.5
}
def should_retry(state: AgentState) -> str:
if state["passed"] or state["iteration"] >= 3:
return END
return "solver"
graph = StateGraph(AgentState)
graph.add_node("solver", solver_node)
graph.add_node("reflexion", reflexion_node)
graph.add_edge("solver", "reflexion")
graph.add_conditional_edges("reflexion", should_retry, {"solver": "solver", END: END})
graph.set_entry_point("solver")
app = graph.compile()
适用于有明确正确性标准、模型能在反馈后改进的任务——编程题、事实性问答、结构化数据提取。
失效时的表现:在困难样本上循环会发散。经过两三轮相互矛盾的自我反馈,模型开始在几种错误之间来回振荡而非收敛。Multi-Agent Reflexion(MAR)针对这个问题,用多个基于人设引导的批评者和一个独立评判者替换了单一的自我反思模型,将 HumanEval pass@1 从 76.4 提升到 82.6——本质上是打破了单 Agent 的回音室。
模式 3:对抗性辩论
两个拥有不同人设的 Agent 各自独立给出答案,互相批评对方的推理,再由一个评判者综合双方意见得出最终结论。
Solver Agent A──┐
├──▶Debate Round ──▶Critique Exchange ──▶Judge ──▶Final Output
Solver Agent B──┘
def debate_round(task: str, answer_a: str, answer_b: str) -> dict:
critique_a = critic_a_llm.invoke(
f"Critique this answer to '{task}':\n{answer_b}\nFind specific flaws."
)
critique_b = critic_b_llm.invoke(
f"Critique this answer to '{task}':\n{answer_a}\nFind specific flaws."
)
synthesis = judge_llm.invoke(f"""
Task: {task}
Answer A: {answer_a}
Answer B: {answer_b}
Critique of A: {critique_b.content}
Critique of B: {critique_a.content}
Synthesize the best answer, incorporating valid critiques from both sides.
""")
return {"final": synthesis.content}
适用于没有唯一正确答案的高风险决策——战略建议、法律分析、复杂研究综合。结构化的对立意见在困难推理任务上确实能持续提升事实准确率。
但是这个方法的延迟和成本高。两路并行求解、两次批评、一次判定——推理开销至少是单 Agent 的 5 倍。亚秒级 SLA 的流水线根本用不了辩论架构。另一种失效场景是两个 Agent 拥有相同的训练盲点,最终在同一个错误答案上达成"共识"。
模式 4:过程验证(逐步验证)
对于复杂 Agent 最具架构意义的模式。验证器不评判最终输出,而是在执行轨迹的每一步向下游传播之前逐一检查。
最终答案未必是 bug 所在。一个在第 2 步错误查询数据库的研究 Agent,到第 6 步仍能产出流畅、格式规整却完全错误的答案。放在末端的输出评分抓到的是症状;过程验证抓到的是病因。
class ProcessVerifier:
def __init__(self, verifier_llm):
self.verifier = verifier_llm
self.step_history = []
def verify_step(self, step_number: int, step_description: str,
step_output: str, overall_goal: str) -> dict:
prompt = f"""
Overall goal: {overall_goal}
Steps completed so far: {self.step_history}Step {step_number}: {step_description}
Output: {step_output}
Does this step:
1. Correctly accomplish what it intended?
2. Remain consistent with previous steps?
3. Move toward the overall goal?
JSON only: {{"valid": true/false, "issue": "<if invalid, one sentence>", "confidence": 0-1}}
"""
result = self.verifier.invoke(prompt)
import json
verdict = json.loads(result.content)
if verdict["valid"]:
self.step_history.append(f"Step {step_number}: {step_description} → ✓")
return verdict
适用于长时域研究 Agent、多文件代码重构、分解为子任务的规划 Agent。在步骤级别拦截错误,能大幅压缩长工作流中的复合失败率。
成本随工作流深度线性增长。10 步流水线就意味着 10 次额外的验证调用。只有当一个错误的最终答案造成的损失高于验证开销时,这种模式在经济上才站得住脚——企业级工作流通常满足这一条件,轻量自动化场景则很少如此。
没人提到的成本问题
验证器根本不需要是最贵的模型,这可能跟很多人的认知不一样
验证在本质上比生成简单。生成一份正确的多步骤研究综合需要广博的知识储备、创造力和整合能力;核查某一步的输出是否与上一步在逻辑上一致,只需要聚焦且局部的推理。二者的能力门槛截然不同。
Agent 评估方向的研究一再表明,一个较小但配备了精细评分标准的专用验证模型,表现持续优于一个大模型临时充当自检角色。ICLR 2026 上有一个多 Agent 研究系统,刻意为执行和评估选用了不同的模型以降低自评偏差。
实际操作中:如果求解器用 Claude Sonnet,评判者换成 Claude Haiku 往往就够了,单 Token 成本低约 10 倍。每天 10,000 次调用的规模下,Sonnet 判 Sonnet 和 Haiku 判 Sonnet 之间的成本差距,足以决定验证方案的商业可行性。
Approximate cost comparison (1,000 solver calls, ~500 tokens output each):
Pattern | Pairing | Est. extra cost
---------------------------------|-------------------------|------------------
No verification | Sonnet only | $0
Output scoring (1 judge call) | Sonnet + Haiku judge | ~$0.40
Output scoring (1 judge call) | Sonnet + Sonnet judge | ~$4.50
Reflexion (avg 1.8 retries) | Sonnet + Haiku judge | ~$1.20
Process verification (5 steps) | Sonnet + Haiku verifier | ~$2.00
Adversarial debate | Sonnet×2 + Haiku judge | ~$9.50
LangGraph 中的参考架构
LangGraph 的条件边天然对应验证循环的核心决策——求解器 → 验证 → 重试或放行。
from langgraph.graph import StateGraph, END
from typing import TypedDict
class PipelineState(TypedDict):
task: str
output: str
verification_result: dict
retry_count: int
max_retries: int
def solver(state: PipelineState) -> PipelineState:
response = solver_llm.invoke(state["task"])
return {"output": response.content}
def verifier(state: PipelineState) -> PipelineState:
result = judge_output(state["task"], state["output"])
return {
"verification_result": result,
"retry_count": state["retry_count"] + 1
}
def route(state: PipelineState) -> str:
passed = state["verification_result"]["score"] >= 7.5
max_hit = state["retry_count"] >= state["max_retries"]
if passed or max_hit:
return "finalize"
return "solver"
def finalize(state: PipelineState) -> PipelineState:
# 如果在最大重试次数后仍然失败,则升级到人工审查
if state["verification_result"]["score"] < 7.5:
flag_for_human_review(state)
return state
graph = StateGraph(PipelineState)
graph.add_node("solver", solver)
graph.add_node("verifier", verifier)
graph.add_node("finalize", finalize)
graph.set_entry_point("solver")
graph.add_edge("solver", "verifier")
graph.add_conditional_edges("verifier", route, {
"solver": "solver",
"finalize": "finalize"
})
graph.add_edge("finalize", END)
app = graph.compile()
给
max_retries
设硬上限(3 是合理的默认值);记录每一次验证结果以供离线漂移分析;最大重试次数用尽后必须路由到人工审查,而非静默放行低分输出。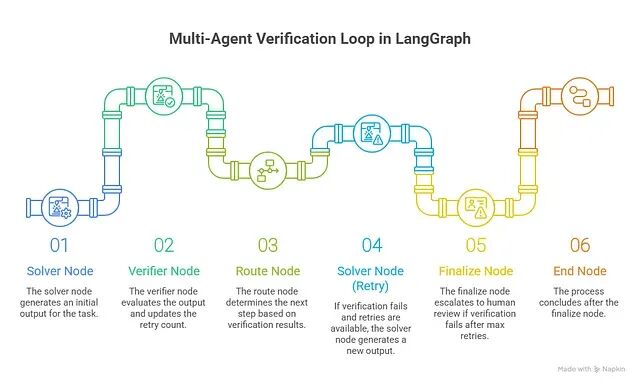
总结
2026 年的生产 Agent 系统里,验证不是可选项——它是演示与实际可部署产品之间的分界线。多步骤流水线中的错误累积是静默的、自信的、结构性的,再怎么提升求解器能力也无法根除,因为根源在架构而非模型质量。
模式已经成熟,LangGraph 让验证循环的搭建足够简洁。一旦认识到评判者的成本可以只是求解器的一个零头,经济上的问题就不是问题了。
真正的问题不在于是否加入验证层,而在于哪种模式匹配当前场景的错误容忍度、SLA 约束,以及一个错误输出可能造成的影响半径。过程验证能定位根因但开销更大;输出评分成本低廉但对复合错误视而不见;对抗性辩论能暴露最深层的分歧,代价是最高的基础设施投入。
所以按需选择。完全可以把验证的步骤加入到 Agent 流水线中。
by Yuval Mehta