
数据增强是现代机器学习中一个绕不开的环节。在计算机视觉里,不做增强就很难训练出一个好的的模型;在时间序列分类领域,虽然也已经沉淀出一套相对成熟的技术——jittering、scaling、window slicing、time warping、permutation、rotation,还有若干基于模式的变体,但时间序列预测是另一回事。
预测任务的目标不是一个离散的类别标签,而是紧接在输入之后的那一段连续信号。这一点改变了整个问题的性质。对分类任务来说安全的变换——比如对输入的一部分做 warping,或者往一个窗口里注入噪声——放到预测里就很容易破坏 look-back 窗口和预测 horizon 之间的关系。但是关系一旦断裂,模型训练时看到的 input-target 对就不再彼此自洽,预测性能随之滑落。
大部分在分类中表现良好的经典增强方法都在预测任务上被评估过,结果基本都没能跑赢不做增强的基线。这个结果本身就很说明问题:它把预测增强中一个内在问题暴露了出来:方法必须引入足够的多样性,让模型见到训练数据之外的变化,而且还要保持时间一致性,让增强后的信号仍然是一个合法的连续序列。把这两点同时搞定才是预测增强难以处理的地方。
所以一个有效的预测增强,应当对序列做足够的修改以产生价值,但不能修改到让输入与其未来失去一致性。
为什么面向分类的增强在预测中表现不佳
jittering、scaling、window warping、permutation 这些经典技术,最初都是为分类任务设计的。在标签不变的前提下,它们工作得不错。可预测里的“标签”就是序列后面那一段,只扰动输入、对信号局部做 warping 或者把局部时序扭得过猛,都会产出一段未来已不再合理的输入。这类方法通常压不过不做增强训练出来的模型。
WaveMask/WaveMix 和 TPS 这两条工作线都强调同一点:预测任务对 input-target 一致性的要求,比分类或异常检测严苛得多。随机性可以加,但必须是正确那种随机性——不破坏信号时间结构的那种。
数据-标签一致性:一个必要条件
记 look-back 窗口为 x,预测目标为 y。训练作用的对象是连续序列 (s = x ∥ y),而不是孤立的 x。所以增强应该作用在拼接后的序列上,再切分成输入和目标:
s = x ∥ y, s̃ = 𝒜(s), (x̃, ỹ) = Split(s̃)
听起来几乎是一句废话但是是预测增强里最关键的思路之一。只对 (x) 动手、让 (y) 原封不动,输入与目标之间天然的连续性就被人为切断了,因为去掉数据-标签一致性带来的性能下降最大。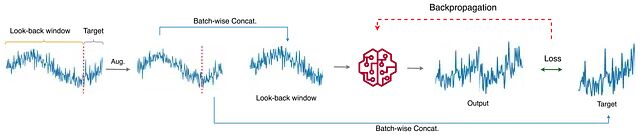
图 1. 预测增强流水线:look-back 窗口与预测 horizon 在增强之前拼起来,增强之后再拆开,以此保持 input-target 对齐。
预测增强方法的分类体系
近几年真正有效的预测增强方法,主要来自三条路线——频域、信号分解,以及受控的信号级操纵。可以简要归类如下:
- 基于频率:RobustTAD 、FreqMask、FreqMix 、WaveMask、WaveMix 、Dominant Shuffle 。
- 基于分解:STAug 。
- 其他方法:wDBA 、MBB 、Upsample 。
- 基于 Patch:TPS 。
下面按类依次梳理,先从频域方法讲起——直到最近,这一直是主流范式。
RobustTAD
频域增强里一个奠基性的工作是 RobustTAD。做法是先对拼接后的输入与目标做离散 Fourier 变换,在选定的频率片段上做扰动,然后反变换回时域。实际操作时,把频谱视作实部和虚部的组合,再从中导出幅度和相位。
扰动的粒度由一个相对于完整频谱的比例决定,只改动选中的那些区域。幅度变体里,原始幅度被替换为从一个受扰动强度控制的 Gaussian 分布中采样的值;相位变体里,选中的相位值被一个小的受控扰动偏移。RobustTAD 原文主要面向异常检测,但一些预测研究会把幅度扰动变体用到了多变量时间序列预测上,所以本文的实验也把相位扰动纳入了比较。
FreqMask 和 FreqMix
FreqMask 和 FreqMix是预测任务中使用最广的频域增强。两者都从拼接输入与目标、然后做实 FFT 开始:
s = x ∥ y, S = rFFT(s)
FreqMask 用一个二值 mask (M) 把选定的频率分量清零:
FreqMask: S̃ = M ⊙ S, s̃ = irFFT(S̃)
直觉在于:抑制掉若干周期分量,可以迫使模型对这些分量的缺失保持鲁棒。FreqMix 把思路推了一步,去混合两个不同序列的频谱:
FreqMix: S̃ = M ⊙ S₁ + (1 − M) ⊙ S₂, s̃ = irFFT(S̃)
这让一个序列能部分地“继承”另一个序列的结构特征。两种方法概念清爽,实现也简单。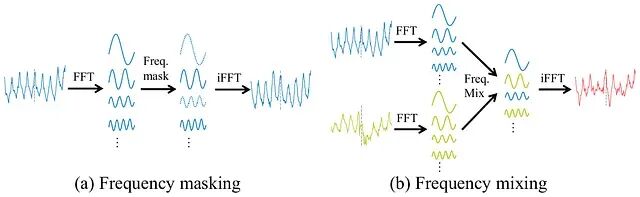
图 2. FreqMask 移除选定的频率分量;FreqMix 在两个序列之间混合频率。
两种方法都纯粹在 Fourier 域内操作,能捕捉哪些频率存在,却无法告诉你这些频率出现在时间轴的哪里。这个差别,后来被证明比看起来重要得多。
时频定位:WaveMask 和 WaveMix
Fourier 变换给出的是漂亮的全局频率信息,但把时间定位丢掉了。Short-Time Fourier Transform (STFT) 用局部窗口做了弥补可窗口大小是固定的。Wavelets 要灵活许多:它在多分辨率下同时工作,对高频事件给出高时间分辨率,对低频趋势给出高频率分辨率。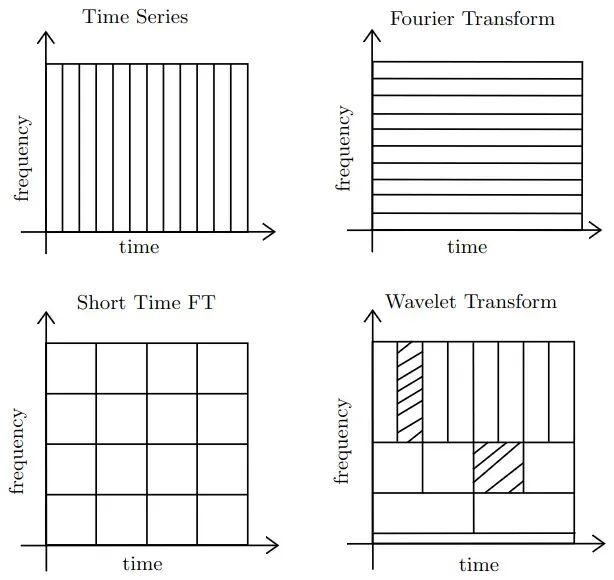
图 3. 时频分辨率比较。Fourier Transform 无时间定位;STFT 使用固定大小的窗口;Wavelet Transform 在不同尺度上自适应调整分辨率。
一句话概括:FFT 回答“哪些频率存在”,wavelets 回答“哪些频率存在、大概出现在哪里”。时间序列里局部变化往往携带关键信息,多出来的这一层时间定位因此格外有用。
WaveMask/WaveMix [8] 的做法是,先用离散 wavelet 变换 (DWT) 把信号分解为跨多个层级的近似系数和细节系数,再直接在这些系数上做增强:
s = x ∥ y
W = WaveDec(s) = {W⁽¹⁾, W⁽²⁾, …, W⁽ᴸ⁺¹⁾}
WaveMask:
W̃⁽ˡ⁾ = M⁽ˡ⁾ ⊙ W⁽ˡ⁾
s̃ = WaveRec(W̃)
WaveMix:
W̃⁽ˡ⁾ = M⁽ˡ⁾ ⊙ W₁⁽ˡ⁾ + (1 − M⁽ˡ⁾) ⊙ W₂⁽ˡ⁾
s̃ = WaveRec(W̃)
masking 和 mixing 可以在每一层独立施加,细粒度的细节和粗粒度的趋势不必被同等对待。论文中的结果显示,WaveMask 和 WaveMix 在 16 种预测 horizon 设置中的 12 种上压过了所有基线,其余四种排第二。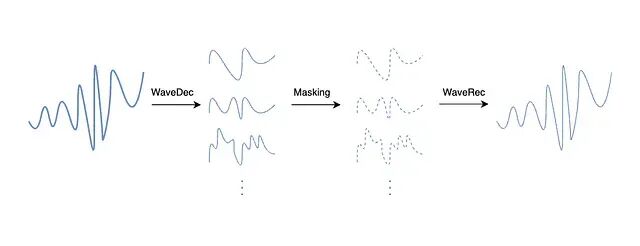
图 4. WaveMask 流水线:信号先经 DWT 分解,wavelet 系数在每一层被选择性 mask,再经逆 DWT 重建。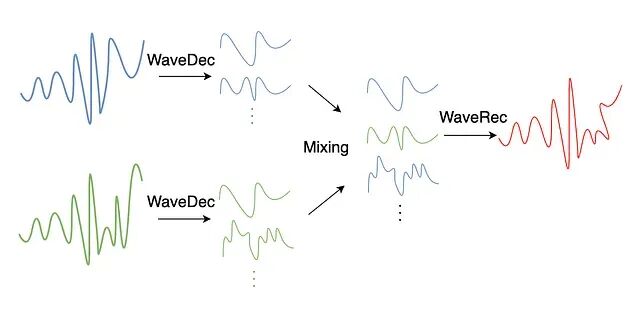
图 5. WaveMix 流水线:两个信号分别分解,它们的 wavelet 系数通过互补 mask 交换,混合后的系数再被重建。
Dominant Shuffle
Dominant Shuffle 则是一条更克制的路。它不对任意频谱分量做 mask 或 mix,而是先挑出最具主导性的那些频率,再在重建之前对它们做 shuffle:
S = FFT(s)
Ωₖ = indices of top-k dominant frequencies
S̃_{Ωₖ} = Shuffle(S_{Ωₖ})
s̃ = IFFT(S̃)
避免过于激进地扰动整个频谱——那样做有把增强样本推出分布的风险,原论文对此有比较详细的讨论。不过在 TPS 论文 的统一比较里,Dominant Shuffle 并不是整体最强的一个。
图 6. Dominant Shuffle:挑出 top- 主导频率分量做 shuffle,频谱的其余部分保持不动。
STAug
STAug 属于基于分解的一类。它对两个序列施加 Empirical Mode Decomposition (EMD),得到 intrinsic mode functions (IMFs),再用从均匀分布采样的 mixup 式插值权重把两组 IMF 重新组合。产出的是一段混合了两个输入时间特征的新序列。
STAug 给出了一种兼顾多样性与一致性的样本生成机制,颇有美感。它真正的问题在工程层面——EMD 内存开销很大,数据集一大就顶不住。TPS 实验 中,STAug 在 ECL 和 Traffic 数据集上因 GPU 内存不够而无法评估,这一限制在 STAug 原论文里也有承认。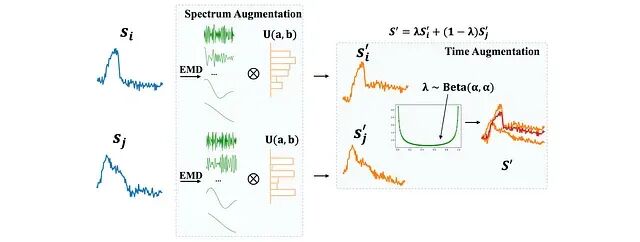
图 7. STAug 通过 EMD 把两个序列分解为 intrinsic mode functions (IMFs),再借由插值权重重新组合。
wDBA、MBB 和 Upsample
这三种方法代表了频域之外的几个方向。
wDBA在基于 DTW 的对齐下对时间序列取平均,借此构造新样本;产出的合成数据质量不错,代价是计算开销很大。MBB先用 STL 把序列拆成趋势、季节性和残差,再从残差里 bootstrap 块生成新序列。Upsample的思路更简单——选一段连续片段,用线性插值把它拉伸回原始长度,相当于对局部结构加了一面放大镜。
Upsample 值得单独点一笔:它稳居较强的非频率基线行列,常常能给出一个不容忽视的 benchmark。但在 TPS 论文更广泛的评估中,TPS 在整体上仍然胜出。
从图像 patch 到时间 patch
Patch-based 增强在计算机视觉里已经是成熟工具。PatchShuffle 、PatchMix 之类的做法,把图像切成 patch,做 shuffle 或 mix,再拼回来。能这么干的前提是图像本身有空间冗余——patch 内部的局部像素重排通常不会把场景搞乱。
时间序列的性质完全不同。它是序列化的,每一个尺度上,值的顺序都在讲话。简单地把序列切成非重叠块再打乱,会制造出硬边界、肉眼可见的断裂,以及 input-target 错位。把 patch 的思路搬到时间域,每一步都得重新想一遍。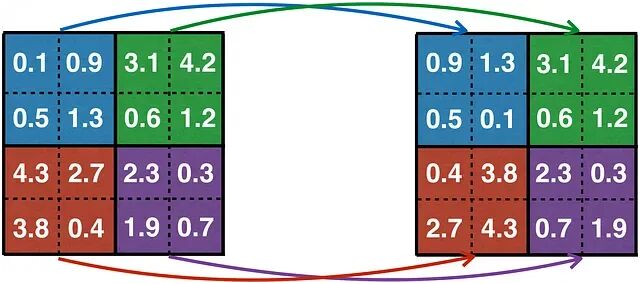
图 8. 计算机视觉中的 PatchShuffle:一张 4×4 图像被划分为非重叠的 2×2 patch,每个 patch 内部的像素被独立 shuffle。
Temporal Patch Shuffle (TPS)
TPS核心流程不复杂:给定完整序列(look-back 窗口与预测 horizon 的拼接),先提取重叠的时间 patch,为每个 patch 算一个基于 variance 的分数,按这个分数选择性地 shuffle 一个 patch 子集——低 variance 的优先——最后在重叠区域取平均来重建整条序列。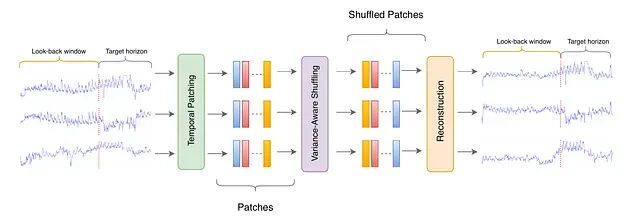
图 9. TPS 流水线。输入序列被切成重叠 patch(Temporal Patching);一个子集按 variance 分数被重排(Variance-Aware Shuffling);随后通过在重叠区域取平均重建序列(Reconstruction)。
流程
按论文 的表述,完整流程是这样的:
- 拼接。把 look-back 窗口和预测 horizon 合成一条连续序列,从源头强制数据-标签一致性。
- Temporal Patching。用 patch 长度 (p) 和 stride (s) 提取重叠 patch。重叠不是装饰,它让相邻 patch 共享时间步,重建时过渡才会平滑。
- Variance 评分。在归一化输入空间内,跨所有通道计算每个 patch 的 variance。低 variance 的 patch 结构特征较少,被视作更安全的扰动对象——一个相当保守的启发式。
- 选择性 shuffle。选出 variance 最低的 (\alpha) 比例的 patch,随机置换它们的位置;其余 patch 原地不动。
- 重建。把每个 patch 放回它(也许是新的)时间位置,在重叠区域取平均。取平均是一种自然的平滑手段,能把 shuffle 引入的任何不连续性柔化掉。
- 拆分。把重建后的序列拆回增强后的输入与增强后的目标。
形式化地,算法如下:
Algorithm 1: Temporal Patch Shuffle (TPS)
控制该方法的超参数有三个:patch 长度 (p)、stride (s) 和 shuffle 比例 (α)。实际选择时并不跑完整的 Cartesian 网格,而是在一组预先定义的候选组合上(大约 20 种配置)做基于验证集的搜索。
消融实验
TPS 论文的消融实验把每个设计选择的贡献分离开来。大致按重要性排序,结论如下。
数据-标签一致性是决定性的。只对输入做增强、让目标保持不变,带来的性能下降是所有单一消融中最大的——从经验层面把核心论点钉死:预测里输入和目标必须被联合变换。
重叠的影响同样实在。把重叠 patch 换成非重叠 patch,结果会明显退化。重叠正是在 shuffle 之下仍能保留局部时间结构的那道闸门。
基于 variance 的排序提供的是一份适度红利。它的效果比重叠小,但在只 shuffle 一个 patch 子集时仍然是个有用的细节。当 (α = 1.0)、所有 patch 都被 shuffle 时,variance 排序在构造上就失去意义。
时域优于频域。一个把同样的 patch 操作搬到 FFT 变换之后的变体,结果也会退化,说明 TPS 最好的工作状态是直接作用在原始时域信号上。
较高的 shuffle 比例通常更有利。在敏感性研究里,0.7 到 1.0 之间的取值在各数据集上稳定给出最强结果。
消融实验真正想说的是一件事:预测增强不是随便注入随机性的问题,而是注入受控随机性——一种尊重信号结构的随机性。
长期预测
TPS 在九个长期预测数据集上进行评估,用到五个近期的骨干:TSMixer、DLinear、PatchTST、TiDE、LightTS。在所有骨干上,TPS 都拿到了所比较增强方法中最好的平均 MSE。下图给出了整体比较。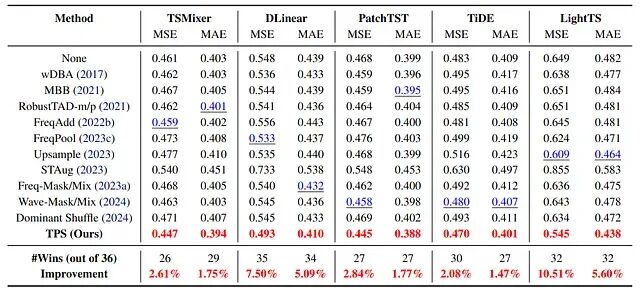
图 10. 九个数据集、五个骨干上的长期预测结果。TPS 在每个骨干上都拿到了最好的平均 MSE 和最多的胜出次数。五个骨干上,相对最好竞争增强方法的 MSE 相对改善区间为 2.08% 到 10.51%。
LightTS 上那 10.51% 的改善是最醒目的一个数字,但故事的主线是一致性:TPS 并不依赖某个恰好合拍的骨干或数据集。从线性模型(DLinear、LightTS)到基于 MLP 的设计(TSMixer、TiDE),再到 transformer 风格的 PatchTST,它都能拿到收益。
短期交通预测
TPS 随后在四个短期交通数据集(PeMS-03、04、07、08)上用 PatchTST 再做一轮评估,仍然拿到了整体最强的增强表现 。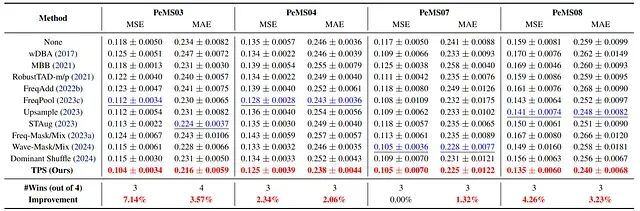
图 11. 用 PatchTST 在 PeMS-{03, 04, 07, 08} 上的短期交通预测结果。TPS 相对最好竞争增强方法的 MSE 改善分别为 7.14%、2.34%、0.00%、4.26%。即便在收益最小的 PeMS07,TPS 也没有让性能倒退。
稳定性和峰值表现一样要紧:一个好的增强方法不该像买彩票——某些数据集大赚,另一些数据集反倒亏出去。
扩展到时间序列分类
TPS 还有一个讨喜的地方,就是迁到分类任务上的顺滑程度。分类任务没有预测 horizon,只需要两处改动:直接作用在输入序列 (X) 上(不再做拼接),并把 shuffle 从批次级别移到样本级别。就这点改动,TPS 在单变量(UCR)和多变量(UEA)基准上都拿到了所比较增强方法里最好的平均准确率 。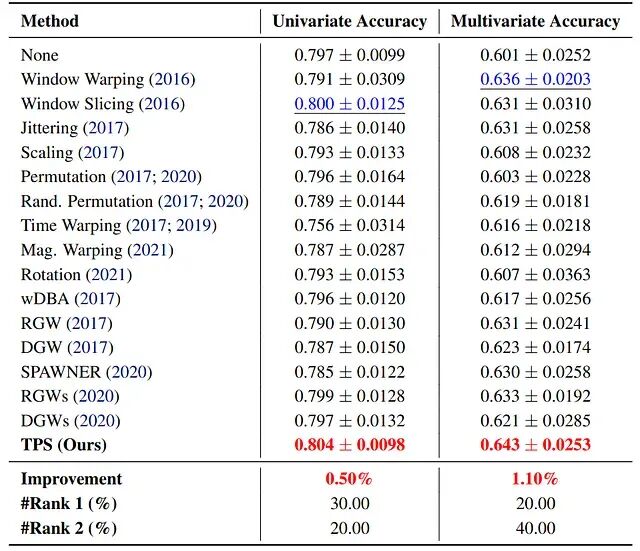
图 12. 分类结果。在 30 个 UCR 单变量数据集上(MiniRocket),TPS 相对最好竞争方法把准确率提升了 0.50%,在 50% 的数据集上进入 top-2。在 10 个 UEA 多变量数据集上(MultiRocket),准确率提升 1.10%,60% 的数据集上进入 top-2。
基于 patch 的核心思路能不能走出预测本身,这是一份比较正面的早期证据。
总结
把上面这些放到一起看,TPS 的独特之处来自几个叠加的原因。它绕开了费力的分解步骤;不去无差别地改动整个频谱;也不去破坏 input-target 关系。做法是以受控的方式修改序列——重叠和平均守住局部时间结构;数据-标签一致性守住输入与目标的对齐。
在各项评估中,TPS 在长期预测(九个数据集,五个骨干)、短期预测(四个 PeMS 交通数据集)和时间序列分类(UCR、UEA 基准)上都取得了 SOTA 级别的增强效果。这种跨任务、跨架构的覆盖面,是它最有意思的地方。
by Sai Nitesh Palamakula