
😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法、深度学习等内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。💛💛💛本文摘要💛💛💛
计算机视觉项目-背景建模文章目录


这里我准备用自己的一个投篮来做试一下这个小项目!后期会做出结果。本来是要做视频的结果没有办法,总显示数据不存在,大家简单的看一下就好。
⭐️项目前言
熟悉OpenCV的小伙伴们都知道一点就是视频是由一帧一帧的图像组合而成,那么当我们传进来一个摄像头录制的图像的时候(因为摄像头录制的较为稳定),我们是不是也可以做这样的一件事:检测到那些物体或者说那些人在运动,那些物体没有在运动。也就是我们所谓的哪些是前景,那些是背景。那么我们就来具体看看背景建模都有那些方法。
⭐️背景建模-帧差法
首先我们来讲一下什么是帧差法:由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续两帧或者三帧图像进行像素值差分运算,不同帧对应的像素值进行相减,判断灰度值的绝对值。当绝对值超过了一定的阈值之后,既可以判断成运动目标,从而实现运动的目标检测功能。

侦差法非常简单,但是会引入噪音,和一些空洞问题。很明显两帧图像背景的部分,不可能像素值一点不变,变一点计算机都是可以识别的,所以他一定会出现一些噪音点,比如上方的图像就是出现了人的周围也出现了很多的噪音点。还有一个就是空洞问题,那么什么是一个空洞问题呢,就是上方图像中整个人都是在运动的,但是由于两帧图像中人移动的很小,把自己身体部分一部分一直处于一个黑色的状态,导致人体内部都是黑色的。没有识别出来。
⭐️背景建模-混合高斯模型
流程总览:在进行前景检测前,先对背景进行训练,对图像的每一个背景都进行一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应。对于新来的像素值进行GMM匹配,如果该像素数值能够匹配其中一个高斯模型,那么就可以认为是背景,否则认为是前景,由于整个过程GMM都在不断更新学习的过程,所以对于动态背景该算法也具有一定的鲁棒性,最后通过一个有树枝摇摆的动态背景进行前景检测,会取得较好的结果。
首先我们先来看一下什么是高斯模型: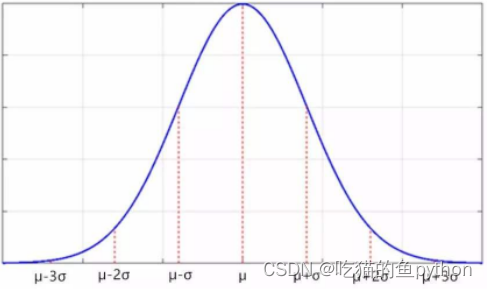
对于像素值中的一个点的展示是这样:
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
这里我们来具体说一下为什么说是混合高斯模型,为什么要混合呢?因为当你拿到一帧图像的时候,不可能在这个图像当中就一个背景的,可能有天空,可能有绿地,可能有具体的事物。那么这些背景的对应的高斯模型都是不相同的,那么就需要混合高斯模型来做这一件事。天空这个背景对应第一个高斯模型,草地这个背景对应第三个高斯模型。都被匹配上了,那么我们就认为他是一个背景,如果都没有被高斯模型匹配上,那么我们就认为他是一个运动的。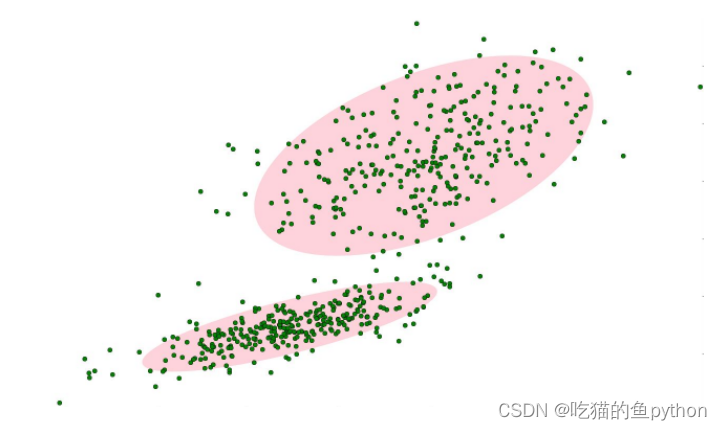
这里面就描述了两个高斯模型。
混合高斯模型学习方法:
- 首先初始化每个高斯模型矩阵参数。 这里我们初始化每一个高斯模型矩阵。比如我们拿到了第一个像素点的数值是100,然后对应的均值差默认值是5。
- 取视频中T帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布。 我们取得不是一帧图像,而是多帧,一般我们取值在200帧左右,第一帧的第一个像素点取完之后呢,然后我们取第二帧的第一个像素点,得到像素值是105,然后计算一下105-100=5<3*均值差=15。然后我们就把105归为这个高斯模型。
- 当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新。
- 如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。 当第三帧图像来的时候,像素值假如是180,那么180-105=75>3*5,那么我们这个时候就要创建一个分布。
一般来说,我们创建的分布设定在3-5个就OK!
对于混合高斯模型来说,他有一个学习更新的过程。所以他要比帧差法要强很多。
在测试阶段,对于新来的像素点的数值,混合高斯模型中的每一个均值比较,如果差值在二倍的方差之间的话就可以认为他是一个背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。
⭐️混合高斯模型背景建模实战
首先我们来看了一下官方标准案例。他是做了一个摄像头下的人物走动的视频,然后使用混合高斯模型进行背景建模。我们来看一下代码。
这里导入第三方库。
import numpy as np
import cv2
然后将视频导入,建立一个卷积核,并且创建混合高斯模型用于背景建模。
cap = cv2.VideoCapture('test.avi')#形态学操作需要使用
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))#创建混合高斯模型用于背景建模
fgbg = cv2.createBackgroundSubtractorMOG2()
cv2.getStructuringElement
这个函数的第一个参数表示内核的形状。共有三种。
- 矩形:MORPH_RECT;
- 交叉形:MORPH_CROSS;
- 椭圆形:MORPH_ELLIPSE;
mog = cv2.createBackgroundSubtractorMOG2(history,varThreshold,false);
这个函数来说。
- history:用于训练背景的帧数,默认帧数为500帧,如果不动手设置learingRate,history就被用于计算当前的learningRate, 此时history越大,learningRate越小,背景更新越慢;
- varThreshold:方差阈值,用于判断当前像素是前景还是背景。一般默认为16,如果光照变化明显,如阳光下的水面,建议设为25,值越大灵敏度越低。
- detectShadows:是否检测影子,设为true为检测,false为不检测,检测影子会增加程序时间复杂度,一般设置为false;
然后
mog->apply(src_YCrCb, foreGround, 0.005);
- image 源图
- fmask 前景(二值图像)
- learningRate 学习速率,值为0-1,为0时背景不更新,为1时逐帧更新,默认为-1,即算法自动更新;
然后进入循环
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)#形态学开运算去噪点
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)#寻找视频中的轮廓
contours, hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
首先我们先来
ret, frame = cap.read()
用于摄像头或视频文件中,捕获帧信息。返回的两个值分别是:
- ret 是返回的捕获到的帧,如果没有帧被捕获到,则该值为空。
- frame表示帧捕获是否成功,如果成功,retval为True,失败为False。
然后利用
cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel
开运算。
在进行膨胀操作的时候我们介绍到了这个:
1.图像被腐蚀后,去除了噪声,但是会压缩图像。
2.对腐蚀过的图像,进行膨胀处理,可以去除噪声,并保持原有形状。
开运算(image)=膨胀(腐蚀(image))
开运算就是先把图像进行腐蚀操作,然后进行膨胀操作的一个过程!
如果我们对于有噪声的图像单独的进行腐蚀操作,就会对图像进行压缩,如果我们想要恢复到原始图像就要进行相同程度上的膨胀,这个操作我们就成为开运算。
🌔开运算操作函数介绍
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img:原始图像
cv2.MORPH_OPEN:表示进行开运算,相同的我们所知道的还有闭运算。
kernel:卷积核,同样我们对开运算的卷积核要进行设定。
然后
contours, hierarchy = cv2.findContours
这里是寻找轮廓,这里注意的是新的版本返回的是两个数值,旧的版本是3个数值。
for c in contours:#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)if perimeter >188:#找到一个直矩形(不会旋转)
x,y,w,h = cv2.boundingRect(c)#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
遍历每一个轮廓,然后计算轮廓的周长,进行筛选如果周长的数值大于188,那么我们把这个矩阵给画出来。
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(150)&0xffif k ==27:break
cap.release()
cv2.destroyAllWindows()
然后这里就结束了。我们来看一下视频。
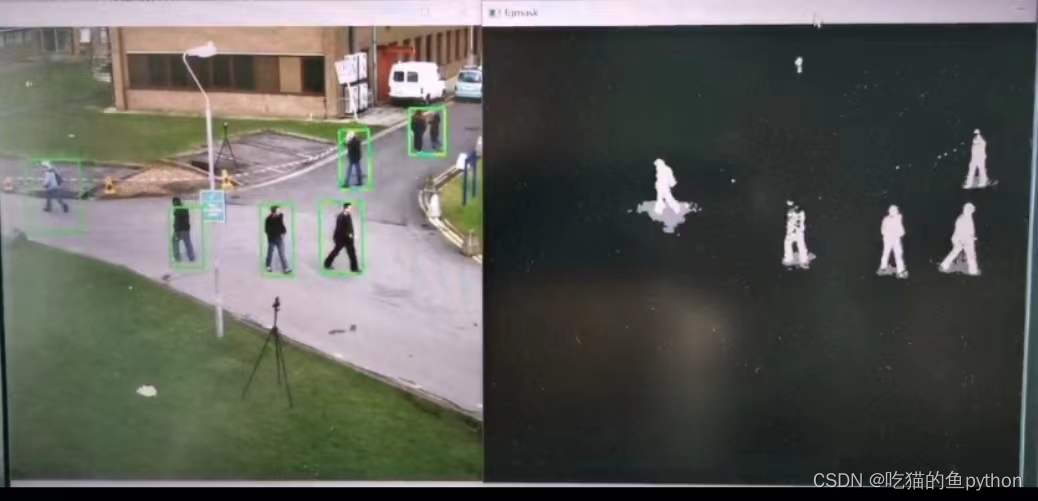
这个是项目中的视频的结果。然后我们继续做一下开头投篮的一个背景建模视频。

这里和官方视频有很大的差距,分析了一下主要原因是由于我们手工录制的视频他一直在发抖,摄像头一直在抖动,稳定性不高导致的背景中的噪音点较多,但是我们去掉这个缺陷之后呢,可以看到运动中的篮球和人物展示的效果都是非常不错的。篮球在空中飞的过程中刻画的也是非常的清晰。
⭐️光流估计
光流是空间运动的物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如说目标追踪。
这里我们假设车在移动的过程中,第一帧和第二帧图像,他们像素点的移动过程是分速度的大小的,右图所示。这个过程中有很多个小概念需要知道:
1.亮度恒定:同一点随着时间的变化,我们认为他的亮度是不发生改变的。也就是说第一帧和第二帧我们忽略了亮度对于光流的影响。
2. 小运动:随着时间的变化不会引起位置的剧烈变化,只有在小运动的情况下才能用前后帧之间的单位位置变化的偏导数。
3. 空间一致:一个场景上临近的点投影到图像上也是临近点,且临近点速度一致。因为光流法基本方程约束只有一个,要求x,y方向的速度,有两个位置变量,所以需要联立n个方程求解。
🔎Lucas-Kanade算法
根据上述的条件,我们可以进行一下约束方程的书写: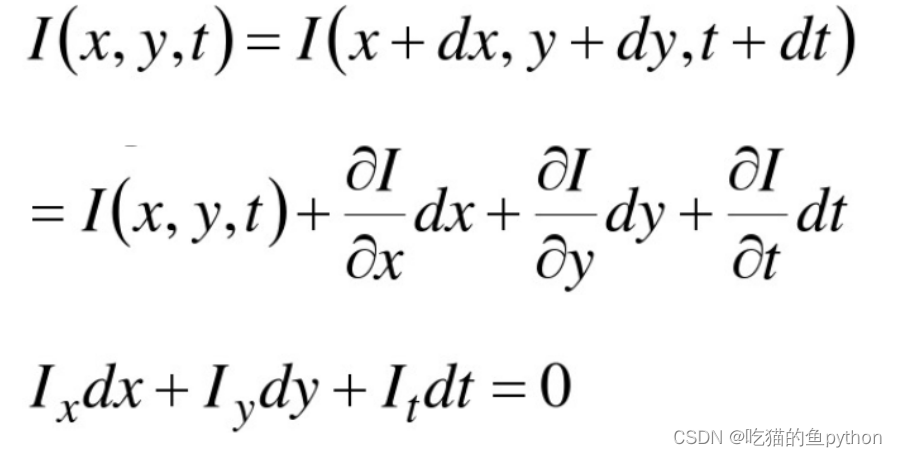
这里很简单,就是说前后帧的图像进行了位置的一个等式,我们认为他是一个小运动。且符合亮度恒定,然后进行了一阶泰勒公式展开。得到的结果进行左右约掉了一部分,然后我们可以得到: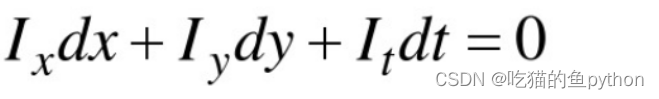
继续推导: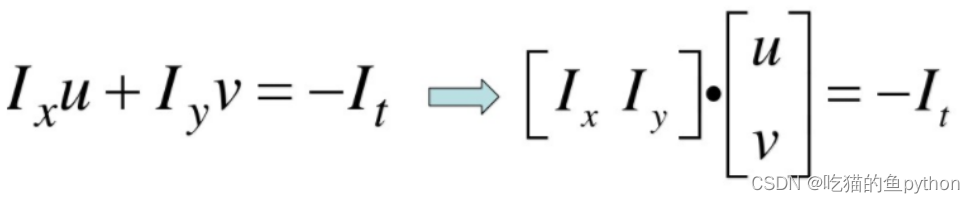
这里面有两个未知数,u和v。那么我们至少要需要两个方程才能解决这个问题。所以我们构造方程使用了多个点进行构造,这就符合了我们第三个条件,就是空间一致。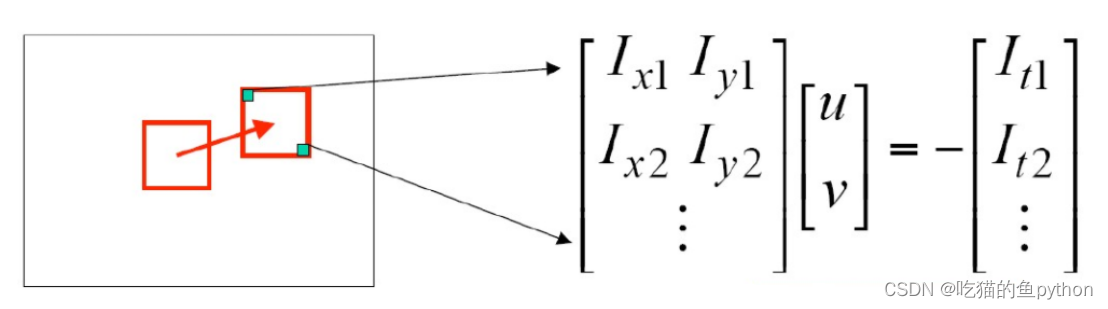
这里面我们用了25个方程来构造这个函数,那么2个未知数,用了25个方程他有一个什么好处呢?就是说和我们在机器学习中的一元线性回归任务当中基于很多点选择一条完美的直线很类似,就是要把这个解弄得完美一点。 差不多这个意思。
差不多这个意思。
然后我们最后通过最小二乘法进行了求解,但是这里有一个问题就是出现了一个逆矩阵,那么我们知道逆矩阵是要符合条件的,那么就需要λ1和λ2,当是角点的时候。才可逆。所以我们在检测的过程中拿到的点都要是角点才可以。
⭐️光流估计实战演示
cv2.calcOpticalFlowPyrLK():
这个函数简单介绍一下
参数:
prevImage: 前一帧图像
nextImage: 当前帧图像
prevPts: 待跟踪的特征点向量
winSize: 搜索窗口的大小
maxLevel: 最大的金字塔层数
返回:
nextPts 输出跟踪特征点向量
status 特征点是否找到,找到的状态为1,未找到的状态为0
读入库和视频
import numpy as np
import cv2
cap = cv2.VideoCapture('aaa.mp4')
首先我们要进行一下角点检测,先定义出来角点检测的函数。以及lucas kanade算法的参数。定义追踪颜色条,然后对每一帧图像做预处理操作。
feature_params =dict( maxCorners =100,
qualityLevel =0.3,
minDistance =7)# lucas kanade参数
lk_params =dict( winSize =(10,10),
maxLevel =2)# 随机颜色条
color = np.random.randint(0,255,(100,3))# 拿到第一帧图像
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask =None,**feature_params)# 创建一个mask
mask = np.zeros_like(old_frame)
然后绘制主体,把相应的参数传入进去。
while(True):
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)#p0 = cv2.goodFeaturesToTrack(old_gray, mask = None, **feature_params)# 需要传入前一帧和当前图像以及前一帧检测到的角点
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0,None,**lk_params)# st=1表示
good_new = p1[st==1]
good_old = p0[st==1]# 绘制轨迹for i,(new,old)inenumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask,(int(a),int(b)),(int(c),int(d)), color[i].tolist(),2)
frame = cv2.circle(frame,(int(a),int(b)),5,color[i].tolist(),-1)
img = cv2.add(frame,mask)
cv2.imshow('frame',img)
k = cv2.waitKey(150)&0xffif k ==27:break# 更新
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
cv2.destroyAllWindows()
cap.release()
结果展示:



🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
版权归原作者 吃猫的鱼python 所有, 如有侵权,请联系我们删除。