
DALL-E是OpenAI基于GPT-3开发的一种新型神经网络。它是GPT-3的一个小版本,使用了120亿个参数,而不是1750亿个参数。但它已经经过专门训练,可以从文本描述生成图像,使用的是文本-图像对的数据集,而不是像GPT-3这样非常广泛的数据集。它可以使用自然语言从文字说明中创建图像,就像GPT-3创建网站和故事一样。
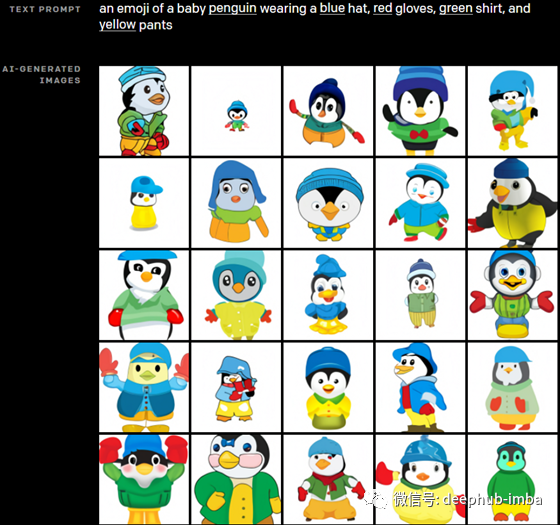
DALL-E与GPT-3非常相似,它也是一个transformer语言模型,接收文本和图像作为输入,以多种形式输出最终转换后的图像。它可以编辑图像中特定对象的属性,正如你在这里看到的。甚至可以同时控制多个对象及其属性。这是一项非常复杂的任务,因为网络必须了解对象之间的关系,并在其理解的基础上创建图像。以这个为例,向网络发送“一个戴着蓝帽子、红手套、绿衬衫、黄裤子的小企鹅的表情符号”。所有这些组件都需要理解,包括对象、颜色,甚至对象的位置。这意味着企鹅的手套必须是红色的,而且必须戴在手上,其他的企鹅也是一样。考虑到任务的复杂性,结果是非常令人印象深刻的。
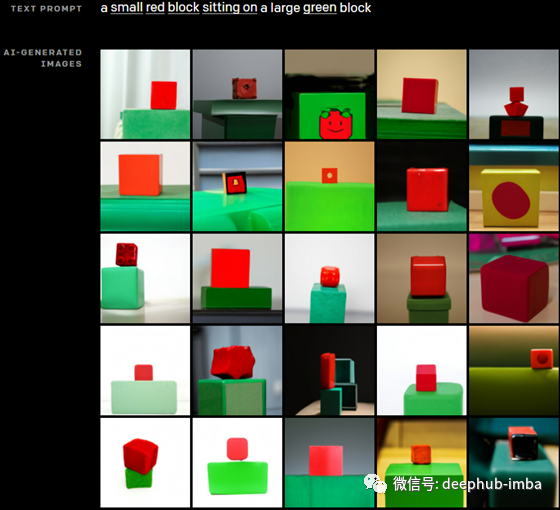
我们可以看到另一个更简单的例子,我们将“一个小的红色方块放在一个大的绿色方块上”输入到网络中。现在它只需要知道有两个方块,它们的颜色,一个小一些,另一个大一些。这对我们来说似乎很简单,但它需要真正高水平的理解才能实现。正如你所看到的,它仍然不是完美的,但我们已经很接近了!
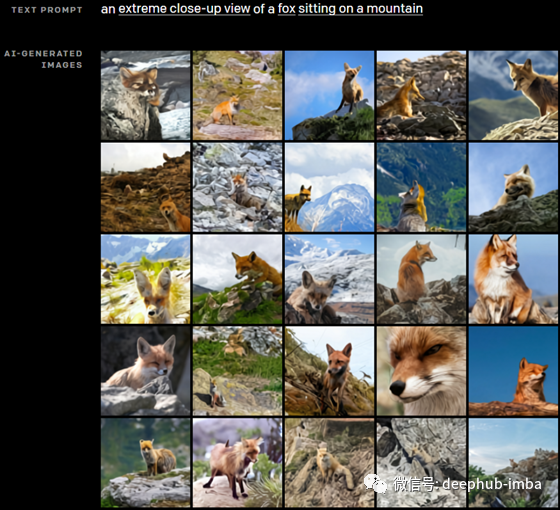
DALL-E还可以改变场景的视角。例如,这里我们发送了“山上一只鹰的特写”,这就是结果。

这里,我们把老鹰换成了狐狸,这就是生成的结果。
当然,一个简单的标题就能产生无数似是而非的图像,如果你想到一幅“日出时坐在田野里的狐狸的彩画”,没人知道你脑子里想的是什么。有很多可变因素,比如狐狸本身,它的颜色,它在看什么地方,它在什么位置,我们甚至不讨论这幅画的背景和风格。幸运的是,由于它非常类似于GPT-3,所以我们可以向输入文本添加细节,并生成更接近于我们预期的结果,就像您在这里看到的不同风格的绘画一样。

它还可以使用彼此不相关的物体生成图像,比如制作一个逼真的牛油果椅子,或者生成原始的、看不见的插图,比如一个新的表情符号。
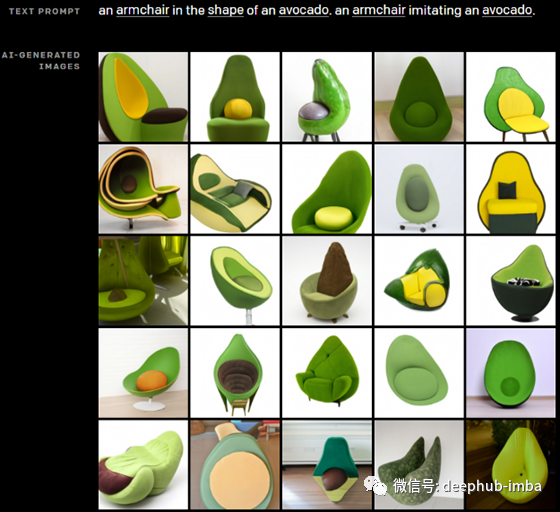
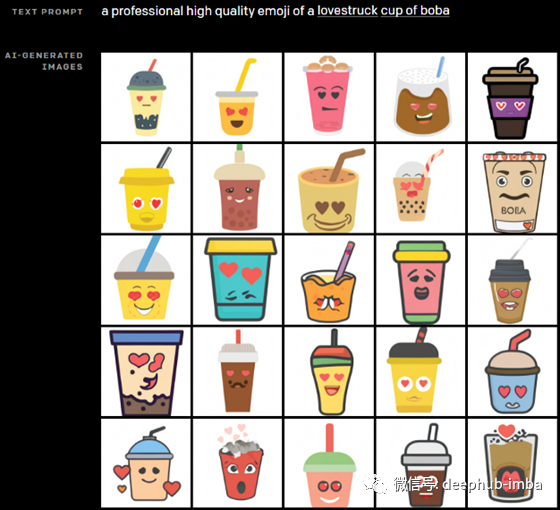
简而言之,他们将DALL-E描述为一个简单的解码器转换器。
如前所述,它接收文本和图像作为标记形式的输入,就像GPT-3一样,以生成转换后的图像。就像我在之前的视频中描述的那样,它使用自我注意力来理解文本的上下文,以及对图像的稀疏注意力。关于它是如何工作的,或者它究竟是如何训练的,并没有很多细节,但他们将发表一篇论文来解释他们的方法。简而言之,这个DALL-E网络表明,通过语言操纵视觉概念现在是可以实现的,我很兴奋地阅读他们即将发表的论文!
open AI地址:https://openai.com/blog/dall-e/
deephub翻译组