
JudgeLM: Fine-tuned Large Language Models are Scalable Judges
https://arxiv.org/pdf/2310.17631.pdf
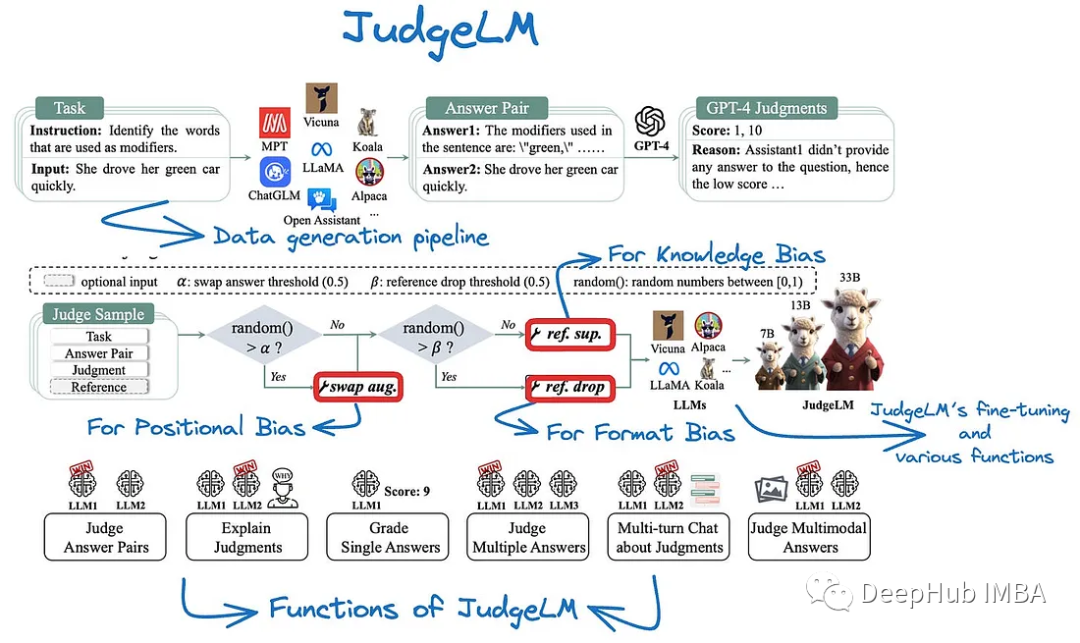
由于现有基准和指标的限制,在开放式环境中评估大型语言模型(llm)是一项具有挑战性的任务。为了克服这一挑战,本文引入了微调llm作为可扩展“法官”的概念,称为JudgeLM,这样可以在开放式基准场景中有效地评估llm。该方法结合了大量高质量的法官模型数据集,包括不同的种子任务、LLM生成的响应和GPT-4的详细判断,从而为LLM评估的未来研究奠定了基础。JudgeLM作为一种可扩展的语言模型法官,其一致性水平超过90%,超过了人与人之间的一致性。该模型在处理各种任务时也表现出适应性。该分析解决了LLM判断微调固有的偏差,并介绍了增强不同情况下模型一致性的方法,从而增强了JudgeLM的可靠性和灵活性。
Matryoshka Diffusion Models
https://arxiv.org/pdf/2310.15111.pdf
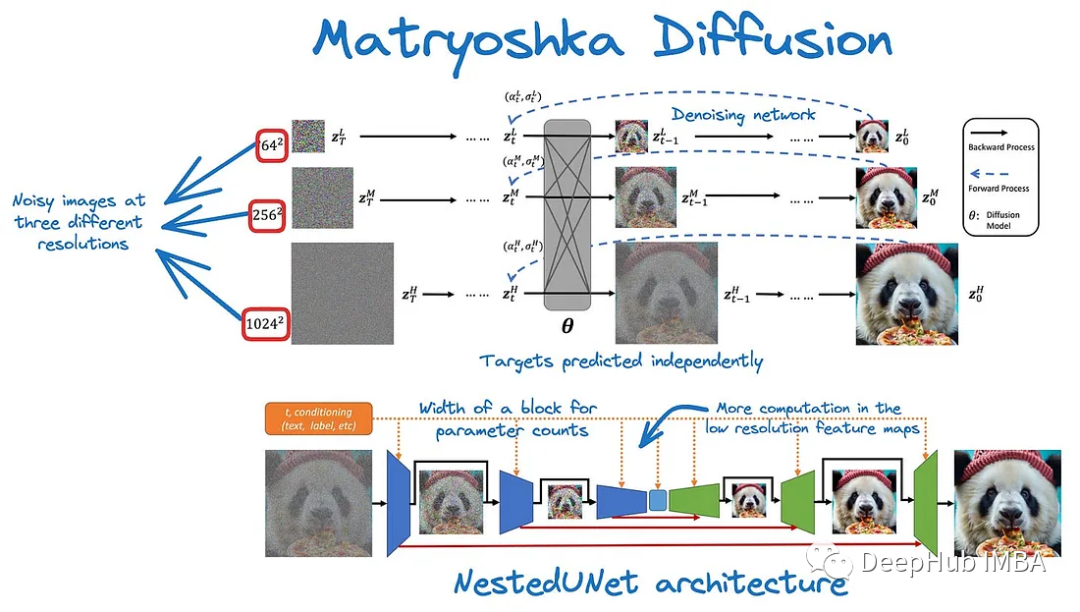
扩散模型被广泛用于生成高质量的图像和视频,但由于计算和优化问题,训练这样的高维模型是具有挑战性的。目前的方法通常在像素空间中使用级联模型,或者依赖于单独训练的自编码器的下采样潜在空间。而这篇论文介绍了MDM (Matryoshka Diffusion),一个用于高分辨率图像和视频合成的端到端框架。MDM提出了一种扩散过程,它同时对多个分辨率的输入去噪,采用NestedUNet架构,较小规模输入的特征和参数嵌套在较大规模中。此外,MDM支持从低分辨率到高分辨率的渐进式训练计划,从而显著改善了高分辨率生成的优化。该方法在各种基准测试中都很有效,包括类条件图像生成、高分辨率文本到图像和文本到视频应用程序。值得注意的是,它能够以高达1024 × 1024像素的分辨率训练单个像素空间模型,仅使用CC12M数据集的1200万张图像就展示了强大的零样本泛化。这种训练策略从一开始就避免了昂贵的高分辨率训练,加速了整体收敛,并且还支持单个批次内的混合分辨率训练。
ConvNets Match Vision Transformers at Scale
https://arxiv.org/pdf/2310.16764.pdf
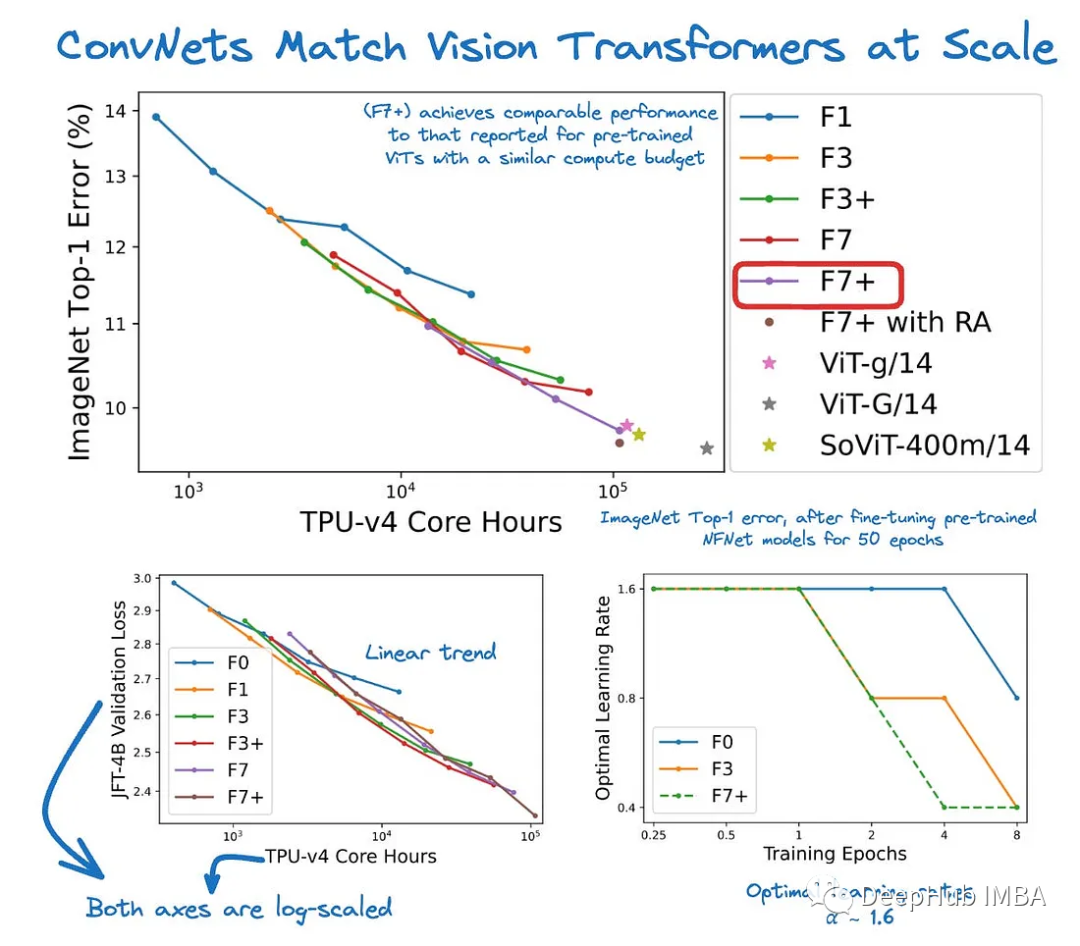
与普遍认为Vision transformer主要在网络规模的数据集上优于ConvNets的观点相反,论文通过评估在JFT-4B(一个用于训练基础模型的大量标记图像数据集)上预训练的高性能ConvNet架构来挑战这一观点。评估跨越了预训练计算预算的范围,从0.4k到110k TPU-v4核心计算小时,并涉及NFNet模型中不断增加深度和宽度的训练网络。值得注意的是,损失和计算预算之间存在对数-对数缩放关系。在ImageNet上进行微调后,NFNets在计算预算相似的情况下实现了与Vision transformer相当的性能,而最强大的微调模型实现了90.4%的Top-1精度。作者发现,一个可靠的经验法则是以相同的速率缩放模型大小和训练轮次的数量,正如Hoffmann等人(2022)先前在语言建模中观察到的那样。
ALCUNA: Large Language Models Meet New Knowledge
https://arxiv.org/pdf/2310.14820.pdf
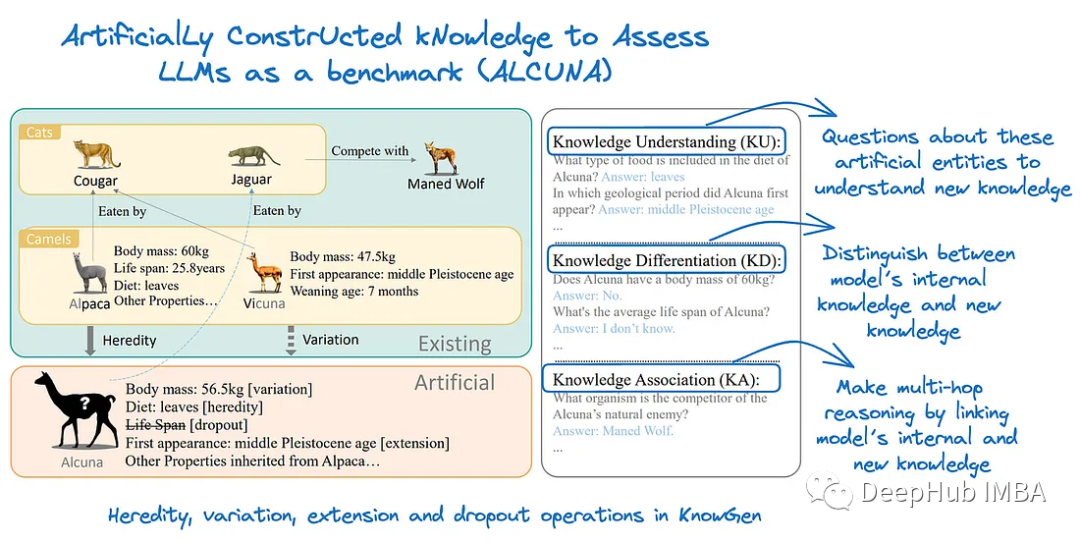
虽然像RAG这样的方法在丰富LLM工作流程方面被证明是有效的,但一个常见的问题是知识不匹配。LLM通常是静态的(有训练的截止时间),因此注入新知识可能会产生性能和真实性问题。作者提出了一种名为KnowGen的方法,通过改变现有实体的属性和关系来产生新知识,从而产生与现实世界实体不同的人工实体。论文还提出了一个基准ALCUNA来评估LLM在知识理解、区分和关联方面的能力。基准测试结果也显示,当引入新知识时,LLM的性能并不令人满意。所以LLM与外部信息的结合越来越受欢迎,相信以后还有更多这样的工作,为这个常见问题提供了更多的见解,以及如何正确地衡量它。
Woodpecker: Hallucination Correction for Multimodal Large Language Models
https://arxiv.org/pdf/2310.16045.pdf
在多模态大型语言模型(Multimodal Large Language Models, mllm)中,生成的文本与图像内容不一致的问题是一个重大的挑战。现有的方法通常需要用特定的数据重新训练模型来减少幻觉。这篇论文引入了一种新的不需要训练的框架——Woodpecker 来解决这个问题。值得注意的是,它是第一个提出使用这种方法下对视幻觉采用矫正的论文。这个框架每个步骤的都清晰和透明,增强了可解释性。综合评价表明,该方法非常有效,在纠正mllm幻觉方面具有很大的潜力。在POPE基准测试中,该方法的精度比基线MiniGPT-4/mPLUG-Owl提高了30.66%/24.33%。”

作者:Zain ul Abideen