
本文原本打算直接简单介绍一下harris和sift,之后进行特征匹配,来一波图像拼接。
想来想去还是先介绍下原理吧,虽然没人看QAQ。可以直接点击右侧目录跳转到代码区。
本文可以完成:
角点检测 和 图像特征提取(就几行代码)

以及进行图像拼接代码,来完成如下操作:
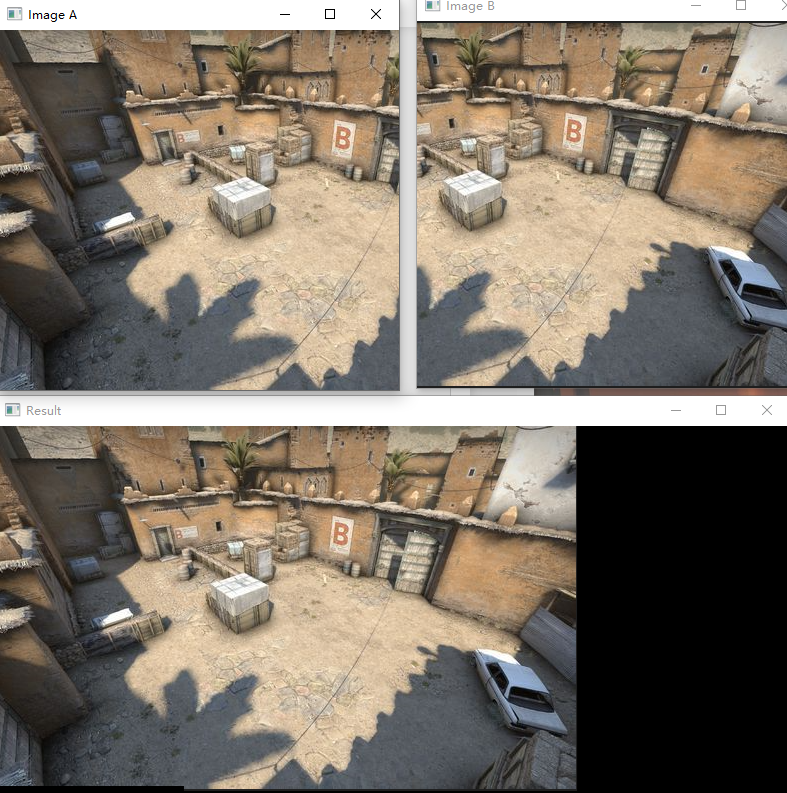
一、图像特征-harris
1.1 harris角点检测
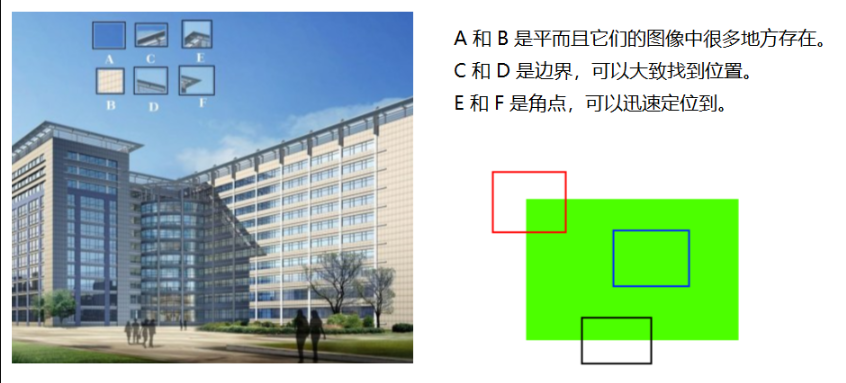
上图我们可以清楚地看到楼房地形状,这是由于它的边边角角在画面上将其勾勒了出来,就像我们小时候玩拼图一样,边边角角有线条或者拐弯的地方最容易选择,对于上图,E和F很好查找,C和D次之,而想找出A和B所在的位置,则要难上很多。
1.2 基本原理
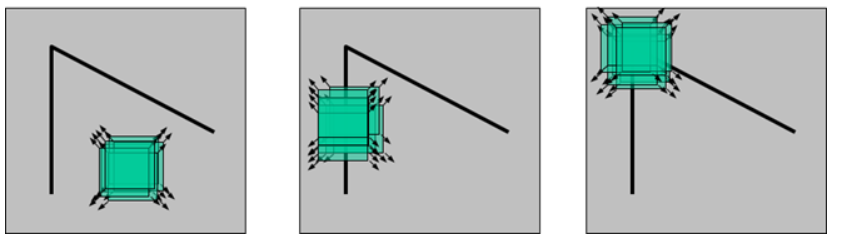
上图绿色矩阵的部分看作我们要识别的部分,当其在上面移动时:
- 左图矩阵x与y变化不大
- 中间图篇y方向发生“剧烈变化”,x变化不大。
- 右图x与y都发生“剧烈变化”
我们把那个矩阵看作 ,当在点(u,v)处平移
后变化幅度为:
其中W(x,y)是以点(x,y)为中心的窗口,就是权重,这个矩阵W是常数也可以是高斯加权函数(中间权重大,离得远的权重低):
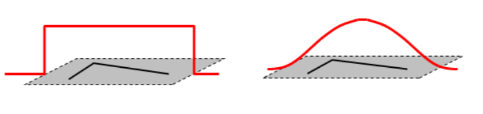
注:上面平方是为了使其在任何方向上平移进行做差时,结果都为正数,用以描述变化的幅度。
然后对其进行泰勒展开,取一阶近似,得到以下公式:
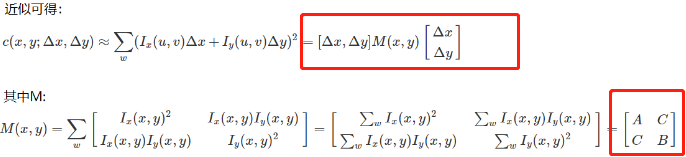
即化简后为:
上方二次项函数本质上是一个椭圆函数。
可能有的兄弟不太明白,怎么能是个椭圆呢 ?实际上它和我们想象中长轴短轴在x或y轴上的标准椭圆不太一样,或许是稍微倾斜一些的,但依旧是个椭圆。就像图片中的边角一样,无论怎么旋转,它依旧是那个角。
所以,我们也可以把椭圆变成我们所熟知的长轴、短轴在x、y轴上的形式:
椭圆方程为:
即公式: 当C=0或者C消失的时候不就是标准的椭圆方程了吗?
其中 矩阵 M 为2阶实对称矩阵,对角化可以得到两个特征值
上面公式看不懂?没关系,不需要懂,我来捋一下
我们通过证明,得到一个歪着的椭圆公式,我们把其中的矩阵M对角化得到两个特征值 ,就把椭圆正过来了。
即
该椭圆 半长轴、半短轴即a和b为 就这么简单。 (在椭圆中,长的叫长轴,短的叫短轴,分母开根号得到的结果叫半长/短轴,最长的不一定在x轴上,这里只是这样介绍。)
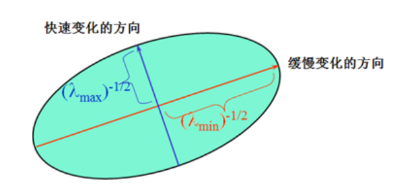
椭圆越大,说明变化越大,越剧烈,两个特征越大,反之则反之。
- ***角点:两个特征值都大,且近似相等,自相关函数在所有方向都增大。 **
- *边界:一个特征值大,另一个特征值小,自相关函数在某一方向上大,其它都小。
- ***平面:两个特征值都小,且近似相等,自相关函数在所有方向都大。 **
角点影响R值:
即:
其中k一般取[0,04,0.06]。
自己随便带入符合上面特点的两个数,有以下结论:
平坦
边界
角点
注:可能会出现以下现象
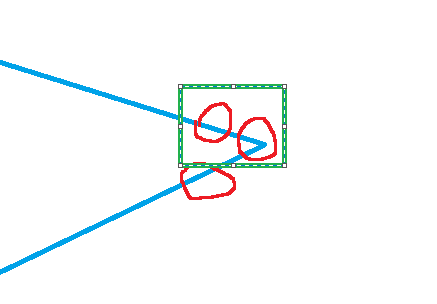
把角点周围的部分也当作角点了,该框也框中了角点,变化也挺大的。
我们要对其进行非极大值抑制,NMS。
1.3 相关代码
cv2.cornerHarris(img, blockSize, ksize, k)
- img: 要求数据类型为 float32 的入图像
- blockSize: 角点检测中指定区域(窗口)的大小
- ksize: Sobel求导中使用的窗口大小,
- k: 取值参数为 [0,04,0.06]
返回值:每个点的变化幅度C:
import cv2
import numpy as np
img = cv2.imread('d2.jpeg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)

注:返回的dst不是原图像,而是该图像每个点各种平移做差后的变化幅度,所以shape大小是一样的,不过里面的数值一般都很小。
我们得到变化幅度矩阵dst,选择里面的部分值在原图像上标记出来:

二、图像特征-sift
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点。
我们要做的就是让计算机看清楚、模糊或者远、近的同一张图片,都能识别出这是个什么东西来。
2.1 图像尺度空间
高斯模糊
尺度空间的获取通常使用高斯模糊来实现
其中 越大,即标准差越大,变化幅度越大,越模糊。

多分辨率金字塔
除了要分辨不同模糊程度的还要会分辨远近的。所以还要做一个图像金字塔。
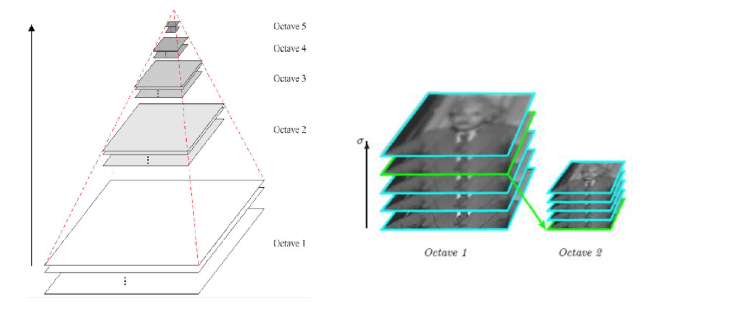
即比如该400400的图片做n次高斯滤波,200200也做n次,100*100...也是。
高斯差分金字塔(DOG)
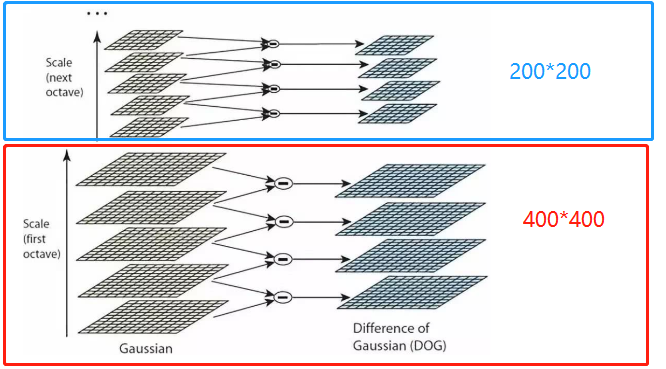
对 金字塔每层 的 不同标准差高斯滤波 的图片临近间做差,如上图每层做了5次高斯滤波,得到4个结果。
做差的目的是为了找出特征。
DOG公式定义:
****
其实就是不同标准差之间高斯做差乘以I。
DoG空间极值检测
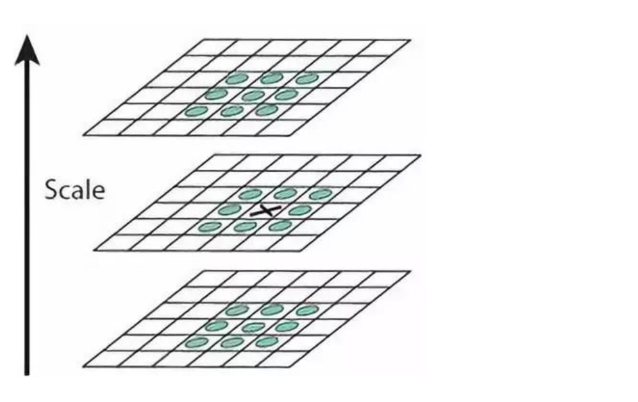
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。
如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。
注:
- 最上和最下的板子无法进行比较。想要得到1个比较结果需要3层板子,2个比较结果需要4层板子...
- 高斯模糊层数要大于DOG板子个数,它们的关系是 G = DOG+1
这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点。
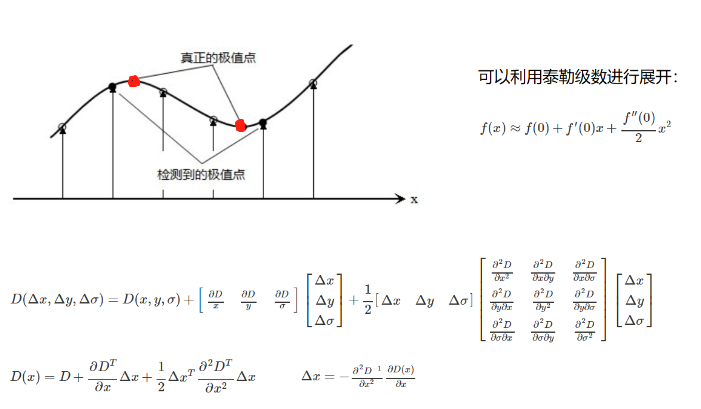
关键点的精确定位
上面说到,这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间DOG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
消除边界响应

特征点的主方向
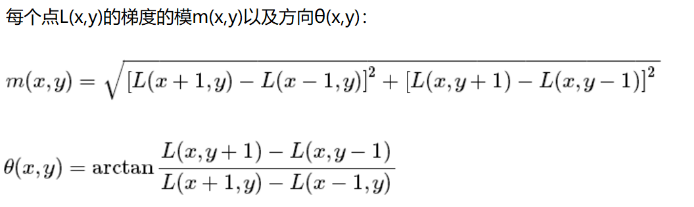
每个特征点可以得到三个信息(x,y,σ,θ),即位置、尺度和方向。
具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
生成特征描述
在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。
全部的话太多了,选8个:上下左右,还有45°的。
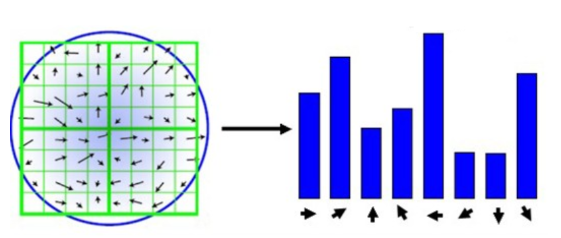
为了保证特征矢量的旋转不变性,要以特征点为中心,在附近邻域内将坐标轴旋转θ角度,即将坐标轴旋转为特征点的主方向。
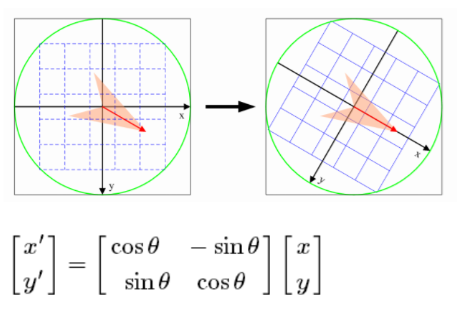
旋转之后的主方向为中心取8x8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4x4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征的由4个种子点组成,每个种子点有8个方向的向量信息。
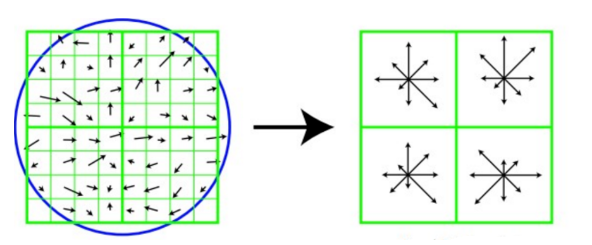
论文中建议对每个关键点使用4x4共16个种子点来描述,这样一个关键点就会产生128维的SIFT特征向量。
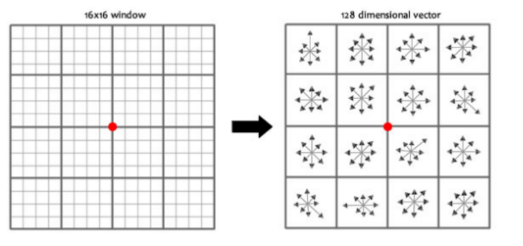
想必过程大家看都没看,没关系,我再来捋一下。
我们 1. 为了找出图片中的特征点,2. 做了个差分金字塔,3. 引入了一个函数DOG(其实就是两层图片间做差),得到的结果是离散的,4. 我们把它们进行拟合修正找到真正的极值点(特征点),有了特征点以后,就知道了它的位置、尺度、方向。
然后取个88窗口,化成22的大窗口,这22每个大窗口都是之前44大小的,里面各是8个方向大小不同的种子点。
差不多就这个意思,只不过我们代码是按照论文来的,也就是一个关键点就会产生128维的SIFT特征向量。
2.2 相关代码
首先要降低openCV的版本,因为高版一些方法申请专利了,差不多3.4几以下就行了。
# 卸载
pip uninstall opencv-python # 记得先关闭anaconda
pip uninstall opencv-contrib-python # 没下载过就没有 不用删
# 安装 老版本 如果3.4.18.65没了那就找有的
pip install opencv-python==3.4.18.65 -i https://pypi.doubanio.com/simple
pip install opencv-contrib-python==3.4.18.65 -i https://pypi.doubanio.com/simple
import cv2
import numpy as np
# 我现在的cv2.__version__ 是'3.4.18'
img = cv2.imread('d2.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
**建立SIFT生成器、返回特征点、用提供好的接口绘制特征点 **
# 建立SIFT生成器
sift = cv2.xfeatures2d.SIFT_create()
# 返回特征点
kp = sift.detect(gray, None)
# 用提供好的接口绘制
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
**注:kp返回的是特征点列表,里面是一些对象,如kp[0].pt才能得到点的坐标。 **
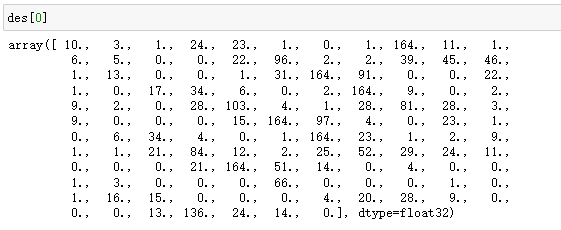
计算每个特征的128维的SIFT特征向量****:
kp, des = sift.compute(gray, kp) # 返回关键点 和每个关键点对应的特征或者叫描述子
注:
- print (np.array(kp).shape) # (1242,) 对象列表 kp[n].pt 才是点坐标 如(4.65476, 136.66870)
- print(des.shape) # (1242, 128) 每个关键点对应的特征128个维度向量
更好的写法:
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
kps, features = descriptor.detectAndCompute(image, None)
# 相当于下面这两行
kp = sift.detect(gray, None)
kp, des = sift.compute(gray, kp)
三、特征匹配
3.1 Brute-Force蛮力匹配
两个图片特征点一个个去比,找相似的,欧氏距离比较(默认)。
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def cv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
cv_show('img1',img1)
cv_show('img2',img2)


sift = cv2.xfeatures2d.SIFT_create() # 实例化
kp1, des1 = sift.detectAndCompute(img1, None) # 特征点和 及其特征向量
kp2, des2 = sift.detectAndCompute(img2, None) # 特征点和 及其特征向量
1对1匹配
两个特征矩阵计算距离,默认欧几里德,越小越接近,匹配效果越好。
matches返回的是两图特征点匹配的结果对象列表。
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
# 默认NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance) # 根据距离排序
# 画出匹配效果最好的前10个
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
cv_show('img3',img3)
注:
np.array(matches).shape # (260,) 大小与两张图片匹配特征点的多少有关

k对最佳匹配
在一堆匹配好了的里面筛选一下,因为有的匹配的一般,就不要了。
k=2就有2个匹配,3个特征点( 匹配1(A1,B1)、匹配2(A2,B1) )其中A12B1是特征点对象,我们用这两个匹配的距离做比。
如果比值比0.75小说明第一个匹配中两个特征点的最近距离小,第二个匹配中两个特征点距离大,最近距离越好,就接纳第一个特征点。
引入第二个特征点的作用是过滤掉一些不好的。
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
good = []
# 在一堆里面筛选一下 k=2就有两个,这两个做比,
# 如果比0.75小说明最近距离小第二距离大,最近距离越好,就接纳它。
for m, n in matches:
if m.distance < 0.75 * n.distance: # 过滤操作
good.append([m])
img4 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show('img4',img3)
注:
np.array(matches).shape # (604, 2) 显然比之前k=1时多了

如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher,树层面上的优化。
ps:对于matches:返回cv2.DMatch对象列表。
- 大小与两张图片特征相似度有关,与原图大小无太大关系。
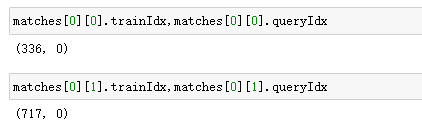
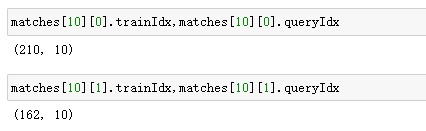
- k = 1时,里面一个单元就是一个匹配的对象结果,“一维”。 - matches[0].distance 这个匹配的距离- matches[0].trainIdx 该匹配对象在特征点矩阵或描述子矩阵A中的索引/位置- matches[0].queryIdx 该匹配对象在特征点矩阵或描述子矩阵B中的索引/位置
- k = 2时, 里面一个单元是一个元组,元组里是两个匹配的对象结果,“二维”。
表示两种匹配。A336点与B0点 和 A717点与B0点 最匹配,其中第一个匹配最好。下图同。
而之前学到的kp是特征点cv2.KeyPoint列表,里面是一些对象,kp[0].pt才能得到点的坐标。
随机抽样一致算法(Random sample consensus,RANSAC)
由于我们上面匹配有一些匹配错了 如

我们后面对其进行一些操作如计算变换矩阵H时, 特征点都匹配错了,计算肯定会出问题,所以我们要过滤掉一些点,采用RANSAC方法:
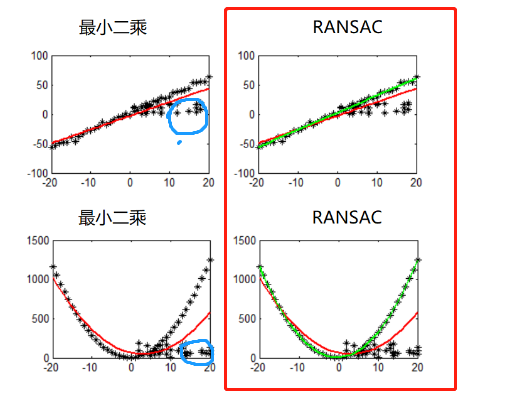
左侧被蓝色部分的点影响从而走偏,离群点。
选择初始样本点进行拟合(如n=2 随机选2个点),给定一个容忍范围,不断进行迭代(有一点点像SVM学到的最大间隔分类器):
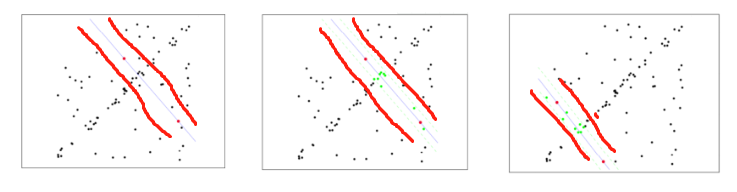
每一次拟合后,容差范围内都有对应的数据点数,找出包含数据点个数最多的情况,就是最终的拟合结果。
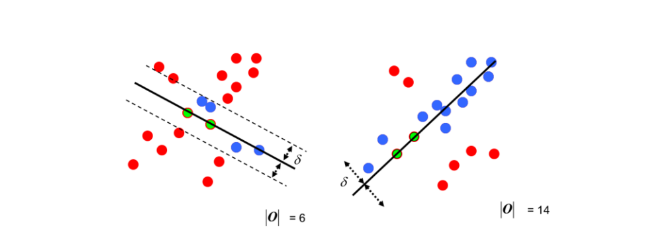
单应性矩阵(简单了解)
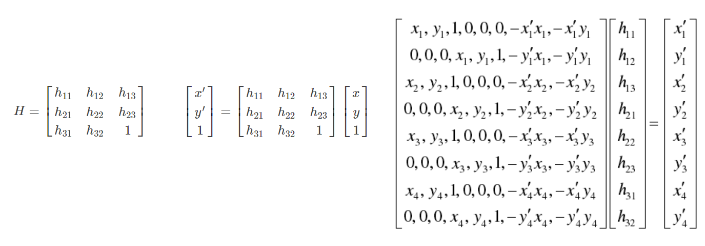
我们把两张图片融合到一起,就像是全景相机那样,需要先将一张图片进行"弯折变换",这一步就需要用到矩阵H。
H矩阵一般是3*3的,8个方程(8个未知数)4对点,所以特征点最少得有四对。
RANSAC一次次迭代找到最合适的一对点,就把离群的过滤掉了,之后,计算H矩阵才会从何时的/正确的特征点中被计算出(H要最好的四对点,可以定义个损失函数,计算经过变换后与预期原本的差距。)



其实这部分内容还挺多的,也是一些不同的方法算法及原理,但我打算日后再精细整理。
3.2 代码如下
考虑没有看上面的介绍的一些初学者,这里再说一下:
首先要降低openCV的版本,因为高版一些方法申请专利了,差不多3.4几以下就行了。
# 卸载
pip uninstall opencv-python # 记得先关闭anaconda
pip uninstall opencv-contrib-python # 没下载过就没有 不用删
# 安装 老版本 如果3.4.18.65没了那就找有的
pip install opencv-python==3.4.18.65 -i https://pypi.doubanio.com/simple
pip install opencv-contrib-python==3.4.18.65 -i https://pypi.doubanio.com/simple
代码如下:道理都写在注释里了真的很详细了
import cv2
import numpy as np
class Stitcher:
def __init__(self, ratio=0.75, reprojThresh=4.0, showMatches=False):
self.ratio = ratio
self.reprojThresh = reprojThresh
self.showMatches = showMatches
def cv_show(self, name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 用来返回图片的特征点点集NumPy数组(而不是默认的对象集列表),及对应的描述特征,128向量。
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
kps, features = descriptor.detectAndCompute(image, None)
# 通过kp.pt 将结果转换成NumPy数组,里面每个单元是特征点的坐标(x,y)
kps = np.float32([kp.pt for kp in kps])
return kps, features
# 特征匹配,并且得到变换矩阵H
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
# 得到原生匹配对象的结果 我们还没进行比较筛选
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
# 筛选过滤,得到的列表matches是A与B匹配的特征点的索引
matches = []
for obj1, obj2 in rawMatches:
# 当最近距离obj1.distance跟次近距离的比值小于ratio值时,保留此匹配对。
if obj1.distance < obj2.distance * self.ratio:
# 记录obj1这个匹配结果在featuresA, featuresB中的索引值
# 即这个匹配是A图哪个位置的点与B图哪个位置的点,把这两个位置记录下来
matches.append((obj1.trainIdx, obj1.queryIdx))
# 当筛选后的匹配对数大于4时,计算视角变换矩阵 如果太少不就没必要匹配了吗(说明可能是不相关的图)
# 最重要的是 变换矩阵H是3*3 矩阵 8个方程 所以至少4对点
if len(matches) > 4:
# 从matches中拿到位置,在kps中取出对应的点(x,y)
# ksp是所有特征点点集 pts是通过匹配后的特征点点集
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵。 cv2.RANSAC 找到最合适的那一对点,来过略掉一些离群点 用来算H矩阵
# H:3*3矩阵 status:[[1][1][1][1][0][0]] 这样的列表,表示是否匹配成功,或者说是经变换后是否相似/可以接受。
H, status = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, self.reprojThresh)
# 返回 匹配(位置) 变换矩阵 0/1结果(表示是否匹配成功)
return matches, H, status
# 匹配对小于4,返回None
return None
# 这是一个用来画线 匹配特征点之间的线的函数
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
hA, wA = imageA.shape[:2]
hB, wB = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1) # 画线
# 返回可视化结果
return vis
# 主拼接函数
def stitch(self, Images):
# 获取输入图片
imageB, imageA = Images
# A、B图片的SIFT关键特征点(真正的点集kps),特征描述子features
kpsA, featuresA = self.detectAndDescribe(imageA)
kpsB, featuresB = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
matches, H, status = M
# 将图片A进行视角变换,A_changed是变换后图片。
# 宽度相加是因为一会要横向拼接,给B留位置 imageA.shape[0]就是A本身的高度,因为要变换的就是A。
A_changed = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('A_changed', A_changed)
# 将图片B传入result图片最左端
A_changed[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('B-->A_changed = result', A_changed)
# 检测是否需要显示图片匹配,就是画着匹配横线的图片。
if self.showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回匹配后的图片 和 画着线的图片
return result, vis
# 返回匹配后的图片
return result
# 出图顺序:
'''
1. 原始图片A、B;
2. A经过变化后的图片; 在类代码中 可以注释掉
3. B与A变化融合后的图片(结果); 在类代码中 可以注释掉
4. B与A变化融合后的图片(结果)、画线匹配图(showMatches=True的话)
'''
# 读取拼接图片并显示
imageA = cv2.imread("left_01.png")
imageB = cv2.imread("right_01.png")
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 把图片拼接成全景图
stitcher = Stitcher(showMatches=True)
result, vis = stitcher.stitch([imageA, imageB])
# 显示图片
cv2.imshow("Result", result)
cv2.imshow("Keypoint Matches", vis)
cv2.waitKey(0)
cv2.destroyAllWindows()
一个简单的问题:
图片A经矩阵H变换后是弯的:
而自己截的图经过变换后确是平的

实际上是由于自己截图分开的两张图片过于匹配,几乎没有远近、大小、角度的区别,所以看不出来(从连线图的密集程度就能看出来):
下图还是有着角度大小等的差异的
所以感兴趣的可以自己动手再给图片加一些变换就好了。或者自己拍几张照片,或者进游戏截几张图片:

版权归原作者 老师我作业忘带了 所有, 如有侵权,请联系我们删除。