

在标准的卷积网络中,每层网络中神经元的感受野的大小都是相同的。在神经学中,视觉神经元感受野的大小是由刺激机制构建的,而在卷积网络中却很少考虑这个因素。本文提出的方法可以使神经元对于不同尺寸的输入信息进行自适应的调整其感受野的大小。building block为Selective Kernel单元。其存在多个分支,每个分支的卷积核的尺寸都不同。不同尺寸的卷积核最后通过softmax进行融合。分支中不同注意力产生不同的有效感受野。多个SK单元进行堆叠构成SKNet。
论文摘要
- 设计了一个称为选择性内核(SK)单元的构建块,其中使用softmax注意力融合了内核大小不同的多个分支,这些注意力由这些分支中的信息指导。
- 对这些分支的不同关注会导致融合层中神经元有效接受场的大小不同。
- 多个SK单元堆叠到称为选择性内核网络(SKNets)的深度网络中。
- 这是2019年CVPR中的论文,被引用200多次。
本文目录
- 选择性核卷积
- SKNet:网络体系结构
- 实验结果
- 消融研究
- 分析与解释
选择性内核卷积(Selective Kernel Convolution)

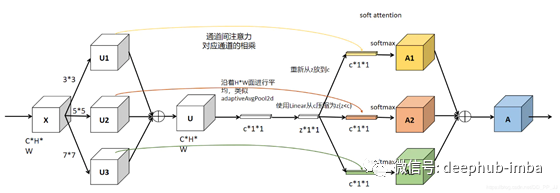
“选择性内核”(SK)卷积使神经元能够自适应地调整其RF大小。具体来说,我们通过三个运算符-Split,Fuse和Select来实现SK卷积。如上所示是两个分支的情况。
- Split:使用不同的卷积核对原图进行卷积。
- Fuse:组合并聚合来自多个路径的信息,以获得选择权重的全局和综合表示。
- Select:根据选择权重聚合不同大小的内核的特征图
Split
- 在输入特征图X上进行两次变换〜F和^ F,以分别输出内核大小为3和5的〜U和^ U。
- 〜F和^ F均由有效的分组/深度卷积,批归一化(BN)和ReLU依次组成。
- 为了进一步提高效率,将具有5×5内核的常规卷积替换为具有3×3内核且膨胀大小为2的膨胀卷积。
Fuse
首先,将多个(上图中的两个)分支的结果通过逐元素求和来融合:

应用全局平均池来获取全局信息。具体来说,通过将U缩小到空间尺寸H×W来计算s的第c个元素:
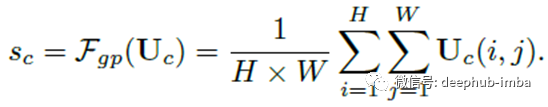
然后,将sc压缩为压缩特征z。这是通过简单的完全连接(fc)层来实现的,同时降低了尺寸,从而提高了效率:
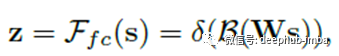
其中δ是ReLU,β是批归一化(BN)。为了研究d对模型效率的影响,我们使用缩减比r来控制其值:
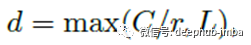
其中L表示d的最小值(L = 32是实验中的典型设置)。
Select
跨通道的软注意力用于自适应地选择信息的不同空间尺度,这由压缩特征z指导。具体来说,将softmax运算符应用于通道数字:
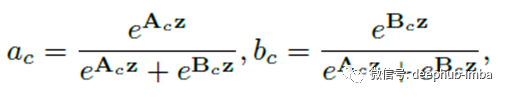
在两个分支的情况下,矩阵ac是冗余的,因为ac + bc = 1。最终特征图V是通过各种内核上的注意力权重获得的:
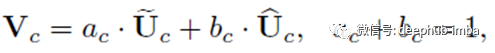
上面的公式适用于两分支情况,并且可以轻松推断出具有更多分支的情况。
三分支情况如下
上图和链接说明了三分支情况。
SKNet网络体系结构
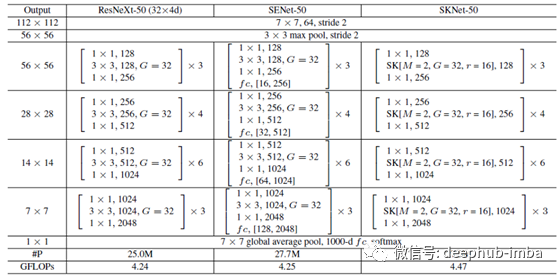
- 与ResNeXt相似,SKNet主要由一堆重复的瓶颈(bottleneck)块组成,称为“ SK单元”。
- 每个SK单元由1×1卷积,SK卷积和1×1卷积的序列组成。
- 通常,ResNeXt中原始瓶颈块中的所有大内核卷积都将由SK卷积代替。
- 与ResNeXt-50相比,SKNet-50仅会使参数数量增加10%,计算成本增加5%。
超参数和SKNet变体
在SKNet中确定了三个重要的超参数:路径数M确定要聚合的不同内核的选择数,分组数G控制每个路径的基数,减径比r控制着Fuse操作器中的参数数量。
SK [M,G,r]的一种典型设置是SK [2,32,16]。
50层SKNet-50具有四个阶段,分别带有{3,4,6,3}个SK单元。
SKNet-26具有{2,2,2,2} SK单位,而SKNet-101具有{3,4,23,3} SK单位。
SK卷积可以应用于其他轻量级网络,例如MobileNet,ShuffleNet,其中广泛使用3×3深度卷积。
实验结果
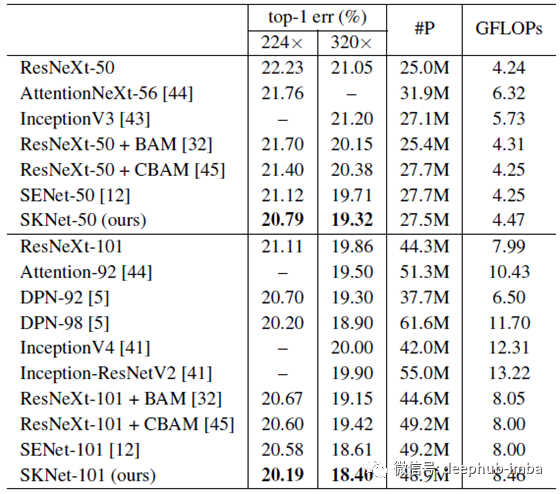
ImageNet
在类似的预算下,SKNet始终可以提高基于2019年的最新CNN的性能。值得注意的是,尽管ResNeXt-101在参数上大60%,在计算上大80%,但SKNet-50的性能比ResNeXt-101高出0.32%以上。与InceptionNets相比,其复杂性可比或更低,SKNets的绝对性能提高了1.5%以上,这证明了自适应聚合对于多个内核的优越性。使用较少的参数,SKNets可以在224×224和320×320的评估中获得类似网络SENet0.3- 0.4%的提高。
ImageNet上的选择性内核vs.深度/宽度/基数
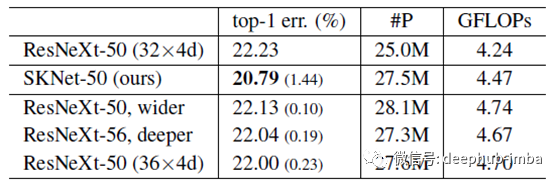
ResNeXt的复杂性也可通过更改其深度,宽度和基数来增加以匹配SKNets的复杂性。更深(从ResNeXt-50到ResNeXt-53的0.19%)或更宽(从ResNeXt-50到ResNeXt-50的0.1%)或基数稍大(从ResNeXt-50的0.23%( 32×4d)至ResNeXt-50(36×4d)) 相比之下,SKNet-50相对于基线ResNeXt-50绝对改善了1.44%,这表明SK卷积非常有效。
关于参数数量的性能
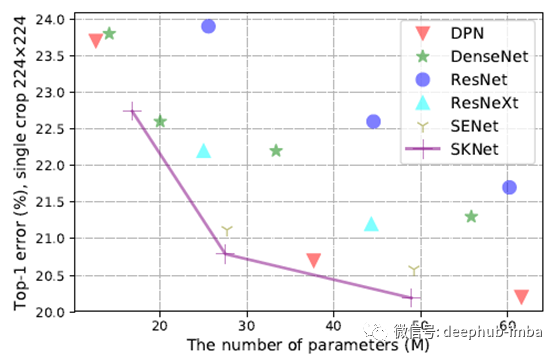
可以看出,与这些模型相比,SKNets更有效地利用了参数。例如,实现20.2 top-1错误,SKNet-101所需的参数比DPN-98少22%。
轻量模型
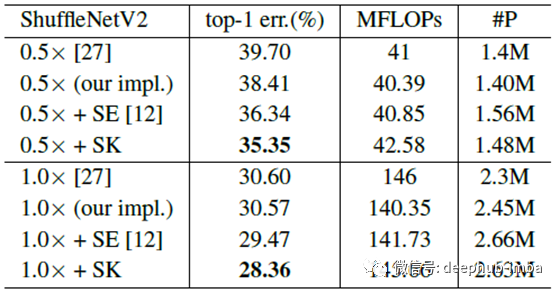
SK卷积不仅大大提高了基线的准确性,而且比SE表现更好。这表明SK卷积在低端设备应用中的巨大潜力。
CIFAR
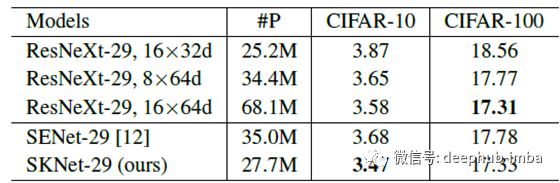
值得注意的是,SKNet-29的性能优于ResNeXt-29, 16×64d,且参数减少了60%,它在CIFAR-10和100上的性能始终优于SENet-29,且参数减少了22%。
消融研究
膨胀D和分组数G
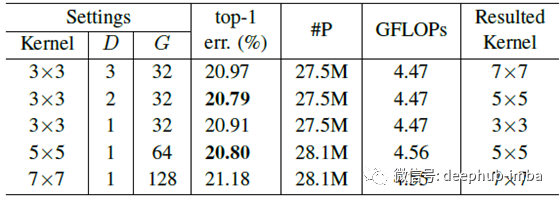
为了研究它们的效果,这里使用了两个分支的情况,其设置为:在SKNet-50的第一个内核分支中,具有D = 1且组G = 32的3×3滤波器。另一个分支的最佳设置是内核大小为5×5的那些。使用不同的内核大小被证明是有益的。
不同内核的组合

K5和K7是一堆3×3过滤器。当路径数M增加时,总体上识别误差减小。无论M = 2还是3,SK的聚合总是比简单的聚合方法获得更低的top-1错误。模型的性能增益从M = 2到M = 3是微不足道的(top-1误差从20.79%降低到20.76%)。为了在性能和效率之间取得更好的平衡,首选M = 2。
分析与解释
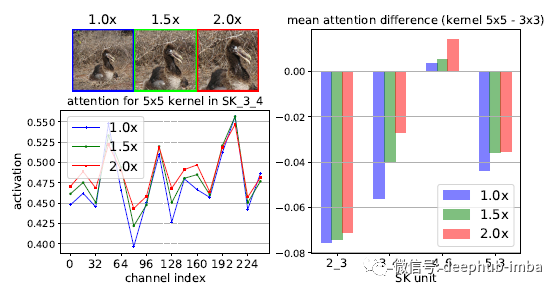
具有三个不同大小目标的两个随机采样图像的注意力结果

上图显示了SK 3_4中两个随机样本在所有通道中的注意力值。
可以看出,在大多数通道中,当目标对象扩大时,大核(5×5)的注意力权重就会增加,这表明神经元的RF大小会自适应地变大,这与预期相符。
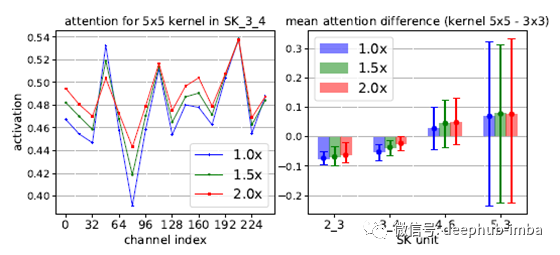
关于跨深度的自适应选择的作用,还有一个令人惊讶的特点;目标对象越大,通过低级和中级阶段(例如,SK 2_3,SK 3_4)的“选择性内核”机制,对更大内核的关注就越多。但是,在更高的层上(例如,SK 5_3),所有比例尺信息都丢失了,这种模式消失了。
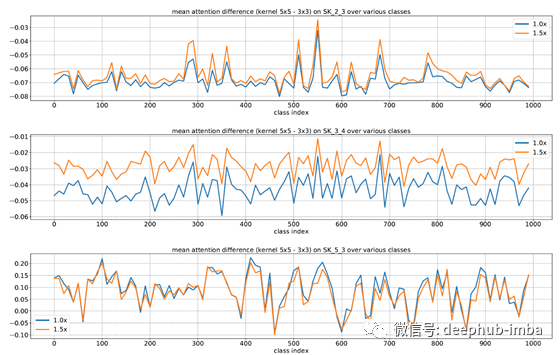
随着目标规模的增长,5×5内核的重要性不断提高。在网络的底层部份(前部),可以根据对象大小的语义意识来选择合适的内核大小,从而有效地调整这些神经元的RF大小。但是,这种模式在像SK 5_3这样的较高层中并不存在,因为对于高级表示,“比例”部分编码在特征向量中,并且与较低层的情况相比,内核大小的重要性较小。
论文原址:https://arxiv.org/pdf/1903.06586.pdf
作者:Sik-Ho Tsang
原文地址:https://sh-tsang.medium.com/review-sknet-selective-kernel-networks-image-classification-63ebbad7d78f
deephub翻译组