

本文的目的是介绍集成学习方法的各种概念。将解释一些必要的关键点,以便读者能够很好地理解相关方法的使用,并能够在需要时设计适合的解决方案。

我们知道,各种学习模型误差表现在以下几个方面:数据噪声、偏差(偏差过大的模型往往不具备较好的性能,通常不能反映重要的趋势性特征)、方差(方差过大的模型往往表现为过拟合,不能够较好应用于未知数据集,不具备较好的泛化能力)。
因此,首先让我们简单地解释一下集成学习,以了解它如何针对这些类型的误差:
集成学习是将不同的学习算法组合成一个预测模型的策略。它的核心方法在于“投票”,能够起到“群众智慧”或“团结就是力量”的目的。
其主要思想是基于“集合更多的预测方法能够建立一个更好的模型”。
它可以通过一些简单的技术来实现,比如最大投票(利用所有预测结果,主要用于分类问题)、平均或加权平均,或者更复杂的计算。

集成模型就如同一支管弦乐队
我们既可以通过集合同一类型的学习算法生成同质的集成学习算法,也可以通过不同类型的学习算法生成异质的集成学习算法。
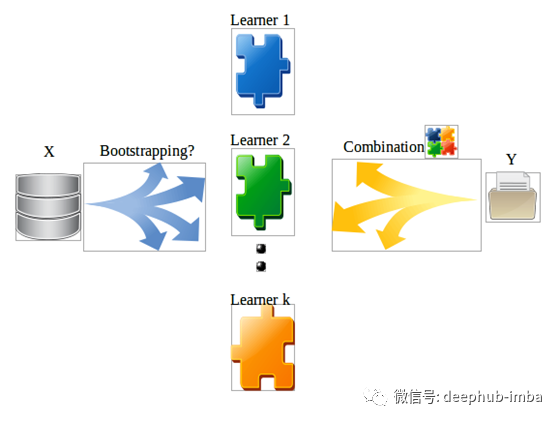
集成模型结合各个学习算法的结果综合判读最佳输出
目前集成模型大致可以分为以下四类:装袋(Bagging)、增压(Boosting)、堆叠(Stacking)、混合(Blending)。
Bagging
Bagging(Bootstrap AGGregatING) 集成方法,通过抽取训练数据的部分子样本形成子样本数据集并构建基模型,基模型在不同的子样本数据集上进行训练。在各个子样本数据集上单独建立基模型(base model),它们独立并行运行。最后的预测将通过综合所有模型的结果来确定。
通过为基模型提供不同的数据子集,能够降低这些模型给出相同结果的概率。

bagging 的典型例子:随机森林方法
随机森林方法遵循 bagging 技术,通过一个小的调整,解除树的相关性,并产生一个非常强大的模型。
Bagging 方法适用于高方差低偏差模型。如果单个模型得到的性能非常低(高偏差),那么 bagging 通常也不能很少地降低偏差。
Boosting
其主要思想是利用已有模型的信息对最终模型进行改进。Boosting 的目的是减少偏差,同时保持较小的方差。它通过非常缓慢的增长来追求方差,通过将许多基模型组合成一个“超级模型”来寻求更低的偏差。
Boosting 虽然可以应用于非树的模型,但最常用于树方法。
在Boosting中,第一个算法是在整个数据集上训练的。然后依次建立后续算法,并对前一算法的残差进行拟合。每个学习模型从先前的学习模型和每个阶段选择最佳的学习模型和权重。当前一模型预测效果不好时,它赋予其更高的权重。
损失函数和(伪)残差的计算方法取决于实际的boosting算法和学习参数 λ 的设置。
常见的 Boosting 集成模型有:
- AdaBoost(Adaptive Boosting):根据错误的预测结果确定权重。
- Gradient Boosting Machine(GBM):利用梯度下降来更新模型,以降低误差。
- Extreme Gradient Boosting Machine(XGBM):基于 Gradient Boosting 进行了一定优化。
- LightGBM:类似于 XGBM,但适用于大数据集,与 XGBM 的显著不同在于拆分树的方式。
- CatBoost(Category Boosting):使用类别变量和目标之间的统计关系处理类别变量。
Boosting不同于Bagging,Bagging适合并行的多个独立模型,每个树都将基于不同的数据子集创建。这两种方法都将不同模型的多个估计组合在一起,从而减小了单个估计的方差,因此得到的结果可能是一个具有更高稳定性的模型。值得注意的是,如果单个模型的问题在于过拟合,那么 Bagging 是更好的选择。
Stacking
它是一种元学习方法,在这种方法中,集成模型被用来“提取特征”,这些特征将被集成模型的另一层所使用。它也被称为叠加泛化(Stacked Generalization)。Stacking 结合了多个模型,在完整训练集的基础上训练基础层的基模型,然后根据基模型的输出作为特征对元模型进行训练。基础层通常由不同的学习算法组成,因此 Stacking 集成常常是异构的。
首先,将训练数据集划分为 K 份(类似于 K折交叉验证),然后对不同的基模型重复以下步骤:基模型通过 K-1 份数据集进行训练,预测余下数据的结果。在不同基模型的预测基础上,将预测结果作为输入数据传递至第二层的模型,通过第二次的模型预测测试集。

Stacking levels
Blending
类似于 Stacking 方法,但仅使用训练数据集中的指定子集进行预测。与 Stacking 相比,它更简单,信息泄漏的风险更小。
首先,将训练数据集划分为 训练子集和验证子集。然后基模型通过训练子集进行训练,并且对验证子集进行预测。预测结果将作为输入用于第二层模型的预测。
总结
本文主要介绍了集成学习方法,以及主要集成方法:Bagging, Boosting, Stacking, Blending。主要几点内容如下:
- 集成学习使用多个模型(基模型)来解决同一问题,然后将它们结合起来以获得更好的性能。
- 在 Bagging 中,对训练数据的不同子样本进行并行独立的相同基模型训练,然后在某种“平均”过程中进行聚合。它适用于高方差低偏差模型。
- 在 Boosting 中,第一个模型是在整个数据集上训练的。然后依次建立后续模型并拟合前一模型的残差。通过将许多基模型组合成一个“超级模型”来追求更低偏差。
- 在 Stacking 中,基于完整的训练集对底层模型进行训练,然后以底层模型的输出作为特征对元模型进行训练。
- 在 Blending 中,它类似于 Stacking,但仅使用训练数据集中的指定子集进行训练和预测。与 Stacking 相比,它更简单,信息泄漏的风险更小。
总之,集成学习方法可以综合不同的模型,以针对具体问题获得更好的预测结果。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********