
小罗碎碎念
这期推文来盘一盘如何从零开始复现一个深度学习的项目,我选择的项目是与AI病理相关的。
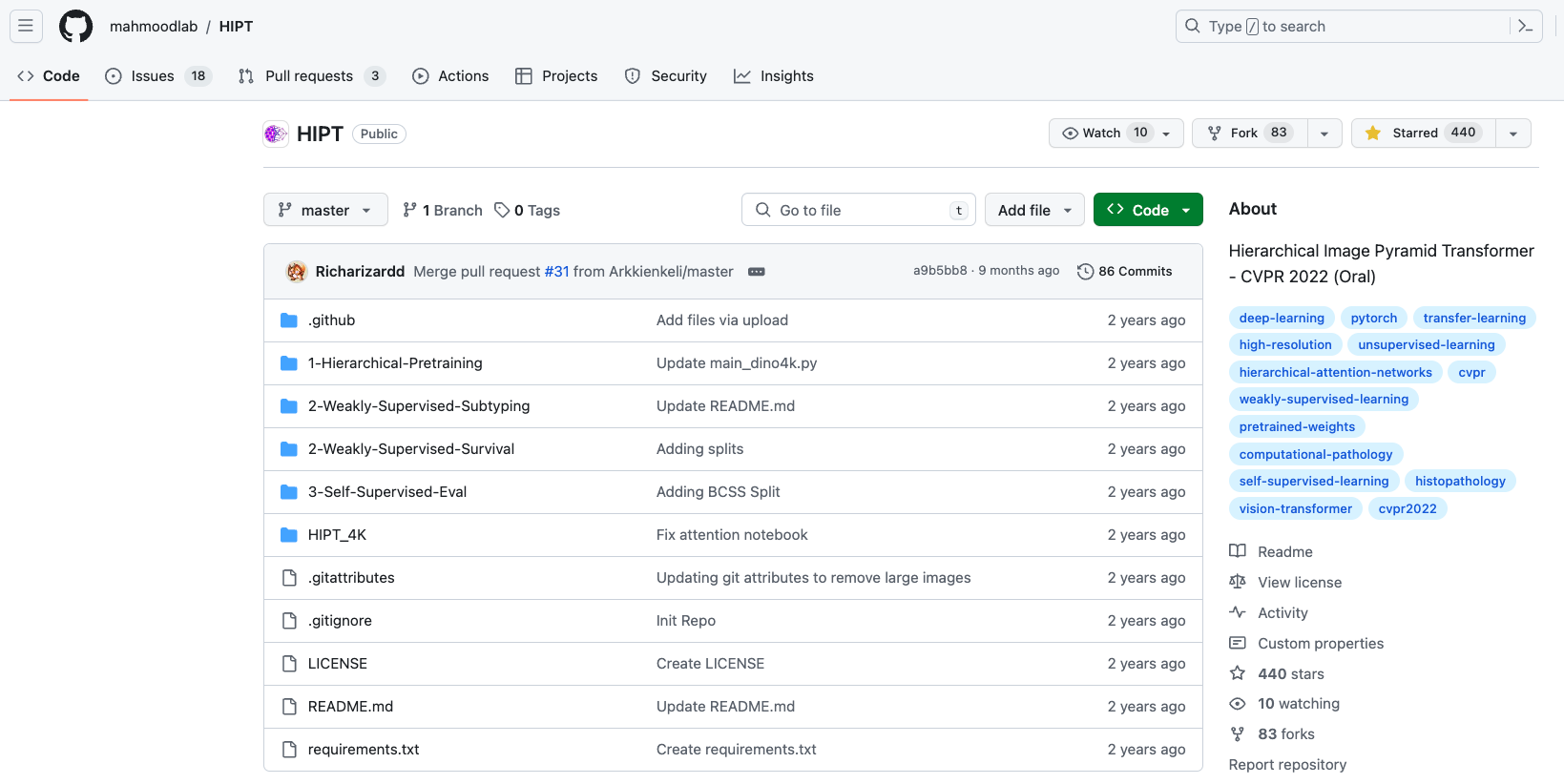
挑选好项目以后,可以建立一个简单的思维导图辅助我们梳理架构,首先要关注的,就是我红框选出来的两个文档。
一、Readme文档分析
先翻译一下标题。
作者放了一个动图。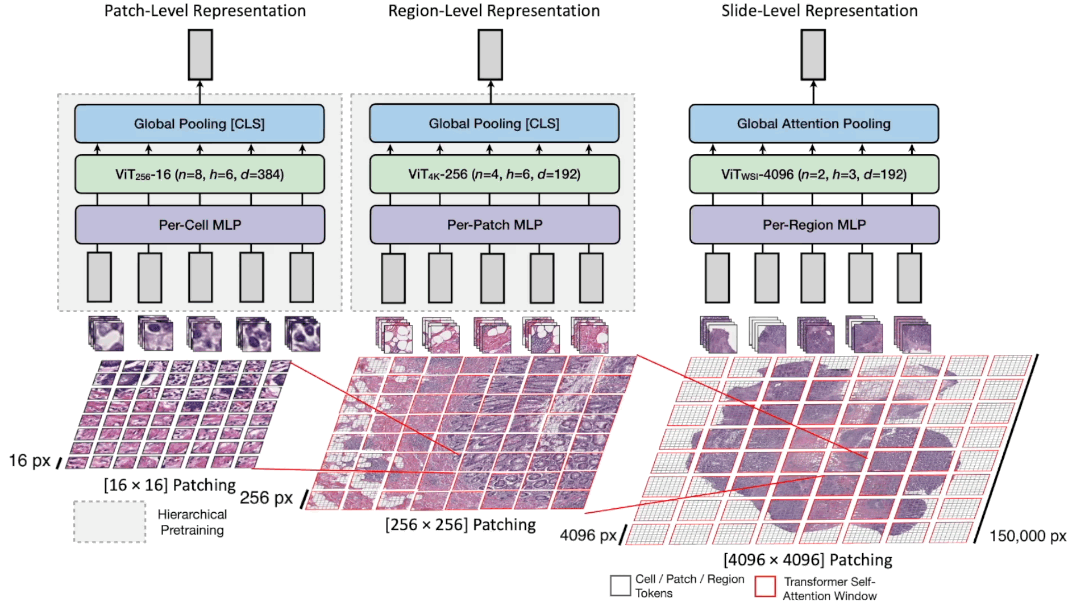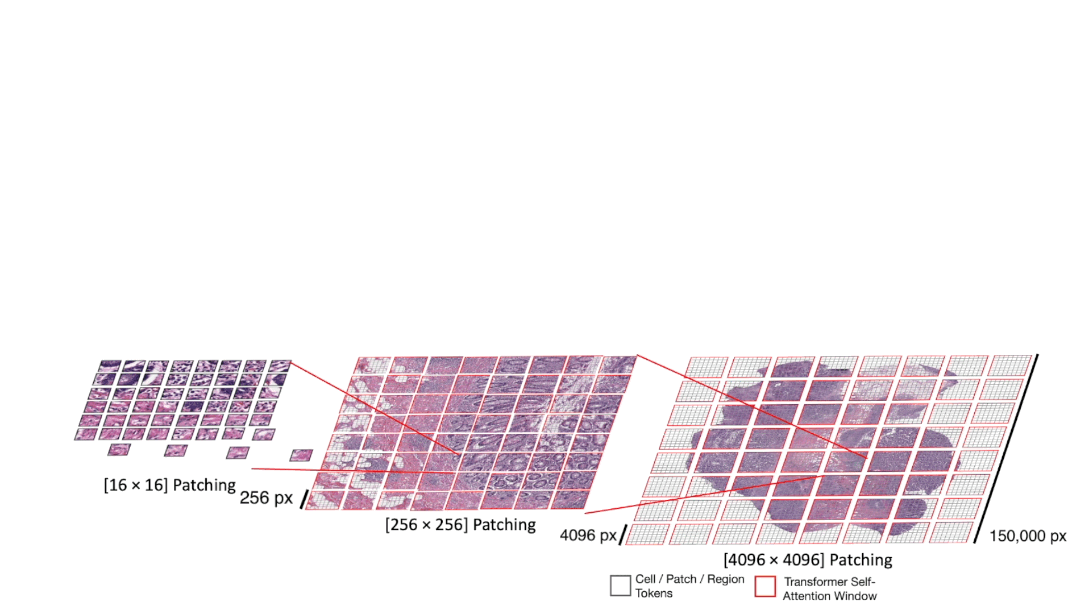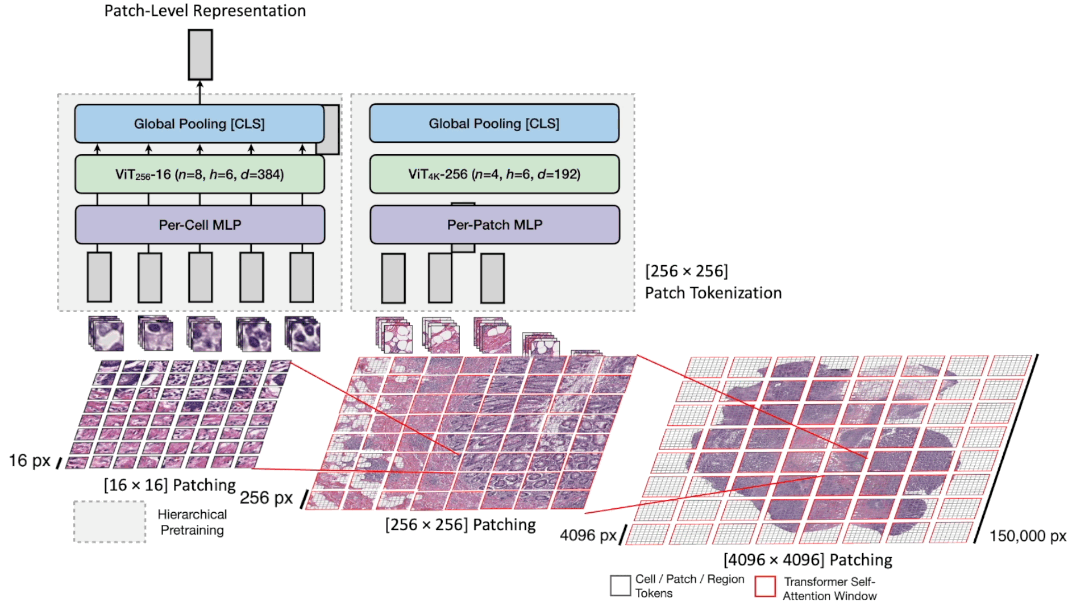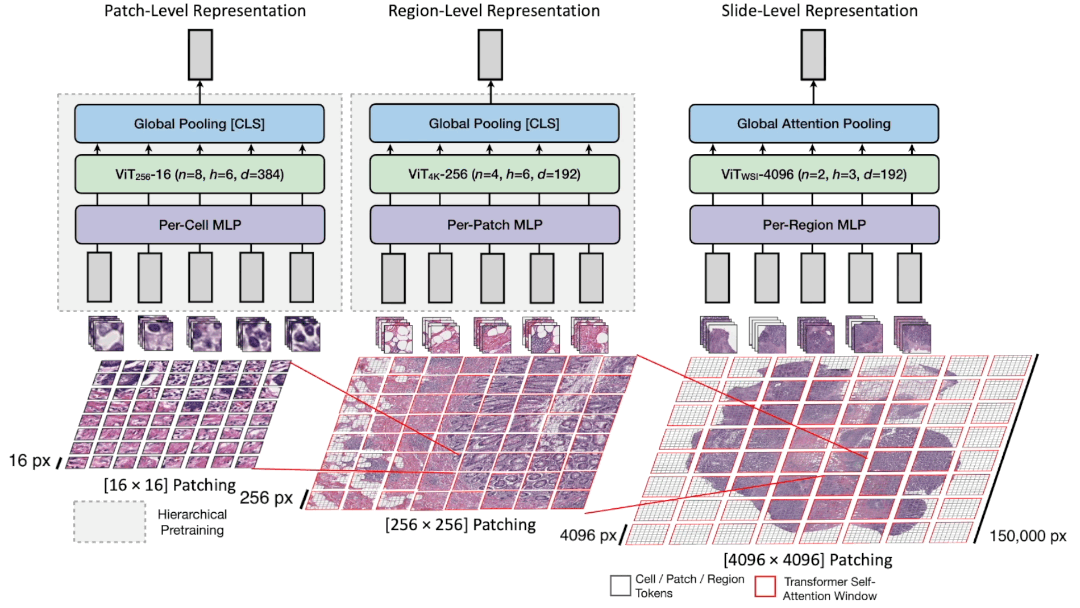
然后就介绍了一下配套论文提出的观点和主要的发现。
分层图像金字塔变换器(HIPT)架构:
HIPT是一个三阶段的分层ViT,将千亿像素的全切片图像(WSIs)构建为一组嵌套序列。HIPT将WSI展开为不重叠的
[4096 × 4096]
图像区域,然后将每个区域展开为不重叠的
[256 × 256]
图像块,最后将每个块作为不重叠的
[16 × 16]
单元标记。我们的方法类似于长文档建模中的分层注意力网络,其中句子内的单词嵌入被聚合以形成句子级嵌入,随后再聚合成文档级嵌入。在HIPT中,通过Transformer注意力对各自
[256 × 256]
和
[4096 × 4096]
窗口中的
[16 × 16]
视觉标记进行自下而上的聚合,以计算切片级表示。
学习WSI中的上下文感知标记依赖关系:
注意,Transformer注意力仅在局部窗口中计算(而不是整个WSI),这使得学习远程依赖关系变得可行。尽管对于
[4096 × 4096]
图像区域的表示学习可能看起来昂贵,但也请注意,这个级别的块大小为
[256 × 256]
,因此在ViTs应用于带有
[16 × 16]
标记的
[256 × 256]
图像块时具有类似的复杂性。
分层预训练:
由于编码
[4096 x 4096]
图像与编码
[256 x 256]
图像是相同的子问题,我们假设ViT预训练技术可以以很少的修改推广到更高分辨率。DINO不仅用于在HIPT中预训练ViT-16,还用于通过在2D特征网格上使用ViT-16作为ViT-256的块标记器进行[6 x 6]局部和[14 x 14]全局裁剪。
注意:ViT-16是指Vision Transformer中的一个模型,其中的**“16”表示该模型使用的输入图像被分割成
16 × 16
的图像块(tokens)**。ViT(Vision Transformer)是一种基于Transformer架构的视觉处理模型,将图像分割成固定数量的图像块(tokens),并通过Transformer的自注意力机制来学习图像中不同区域之间的关系,从而实现对图像的理解和处理。ViT的“16”表示每个图像块包含
16 × 16
个像素。
在ViT-16中,图像被分解成
16 × 16
的图像块,每个图像块被表示为一个向量,然后这些向量经过Transformer模型的处理,最终得到整个图像的表示。ViT-16通常用于处理较小尺寸的图像,并且通常作为更大规模的模型(如ViT-256)的一部分,用于构建更复杂的视觉处理系统。ViT-16通过在图像块级别上学习特征表示,可以用于各种视觉任务,如图像分类、目标检测和图像分割。
自监督幻灯片级表示学习:
通过对ViT-16 / ViT-256阶段进行预训练+冻结,并使用切片级标签对ViT-4K阶段进行微调评估HIPT。在TCGA中进行癌症亚型和生存预测任务。我们还通过计算从ViT-256提取的平均[CLS]-4K标记作为幻灯片级嵌入的代理,执行自监督的HIPT嵌入的KNN评估。在肾细胞癌亚型中,我们报告称,没有任何标签的平均预训练HIPT-4K嵌入效果与CLAM-SB一样好。
1-1:预备工作
该存储库不仅包括HIPT的代码库,还包括保存的HIPT检查点和预先提取的HIPT幻灯片嵌入,占用约4.08 GiB的存储空间,我们通过Git LFS进行版本控制。
要克隆此存储库而不包含初始的大文件:
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/mahmoodlab/HIPT.git # Pulls just the codebase
这段代码是用于从指定的GitHub存储库(https://github.com/mahmoodlab/HIPT.git)克隆代码时,跳过Git LFS的自动文件下载(smudge)操作的命令。通过设置环境变量
GIT_LFS_SKIP_SMUDGE
为1,Git LFS将在克隆操作时跳过自动下载大文件的步骤。
注意,我当时已经在这篇文章里讲解了如何导入仓库,所以先去看看这篇文章再回来继续看下面的。
通常情况下,当使用Git LFS管理存储库中的大文件时,Git LFS会自动下载这些大文件。但是,有时候由于网络速度或其他原因,用户可能希望在克隆存储库时跳过这些大文件的下载,这时可以使用
GIT_LFS_SKIP_SMUDGE=1
这个设置来实现。这样做可以节省时间和带宽,但是请注意,如果存储库中的大文件是必需的,则可能会影响代码的完整性和可用性。
git lfs pull --include "*.pth"# Pulls the pretrained checkpoints
git lfs pull --include "*.pt"# Pulls pre-extracted slide embeddings
git lfs pull --include "*.pkl"# Pulls pre-extracted patch embeddings
git lfs pull --include "*.png"# Pulls demo images (required for 4K x 4K visualization)
这段代码是使用Git LFS命令来下载特定类型的文件。在这里,
git lfs pull
命令用于从远程存储库中拉取(下载)文件,而
--include
选项用于指定要拉取的文件类型模式。
git lfs pull --include "*.pth":这行代码会拉取(下载)预训练检查点(pretrained checkpoints)文件,文件名以".pth"结尾的文件。git lfs pull --include "*.pt":这行代码会拉取(下载)预先提取的幻灯片嵌入(pre-extracted slide embeddings)文件,文件名以".pt"结尾的文件。git lfs pull --include "*.pkl":这行代码会拉取(下载)预先提取的补丁嵌入(pre-extracted patch embeddings)文件,文件名以".pkl"结尾的文件。git lfs pull --include "*.png":这行代码会拉取(下载)演示图像(demo images),这些图像通常用于4K x 4K可视化,文件名以".png"结尾的文件。
通过这些命令,可以有选择地下载存储库中所需的特定类型的文件,而不必下载整个存储库中的所有文件,这有助于节省带宽和时间。
我的建议是按照我上面👆的那篇文章,直接把整个仓库都克隆下来。
git clone https://github.com/mahmoodlab/HIPT.git
1-2:依赖环境安装
现在来安装Python依赖环境。(注意,下面的操作都是在这篇文章的基础上进行的,没看的一定要看,不然你不知道我在干嘛)
打开你的终端,输入我们已经创建好的一个仓库。
cd learn-git
cd HIPT

开始安装依赖环境。
pip install -r requirements.txt
不出意外,是出意外了,熟悉小罗的同学都知道我是踩雷小霸王。

我经过反思以后,突然想起我好像没进入虚拟环境,人傻了。(不知道怎么建立虚拟环境的,去看这篇文章)
conda activate pyt
然后再次安装依赖环境。
pip install -r requirements.txt
对不起,并不是虚拟环境的问题,该报错还是报错。
这次报错和上次一样,问题还是出在numpy这个包上,所以我先来看看这个环境下有没有numpy。
conda list

我决定暂时搁置,看后续会不会有影响,有影响再按照报错信息去调整。
二、HIPT流程
2-1:HIPT的工作原理
以下是一个独立的两阶段
HIPT
模型架构的片段,可以加载完全自监督的权重,用于嵌套的
[16 x 16]
和
[256 x 256]
令牌聚合,在./HIPT_4K/hipt_4k.py中定义。
通过几个
einsum
操作,您可以组合多个ViT编码器,并使其扩展到大分辨率。
HIPT_4K
用于在TCGA上跨非重叠的
[4096 x 4096]
图像区域进行特征提取。
注意
einsum
操作是NumPy中的一种功能,用于执行张量的乘法、求和以及转置等操作。
einsum
代表“Einstein Summation”,它提供了一种紧凑而强大的方式来描述和执行一系列张量运算。

在
einsum
中,您可以指定一个操作字符串,该字符串描述了输入张量的索引标签如何组合以生成输出张量。这种方法非常灵活,允许您按照自定义的方式组合张量的元素。
例如,在一个简单的情况下,您可以使用
einsum
来执行矩阵乘法:
import numpy as np
# 创建两个矩阵
A = np.array([[1,2],[3,4]])
B = np.array([[5,6],[7,8]])# 使用einsum执行矩阵乘法
C = np.einsum('ij,jk->ik', A, B)print(C)
打开jupyter,运行上述代码。
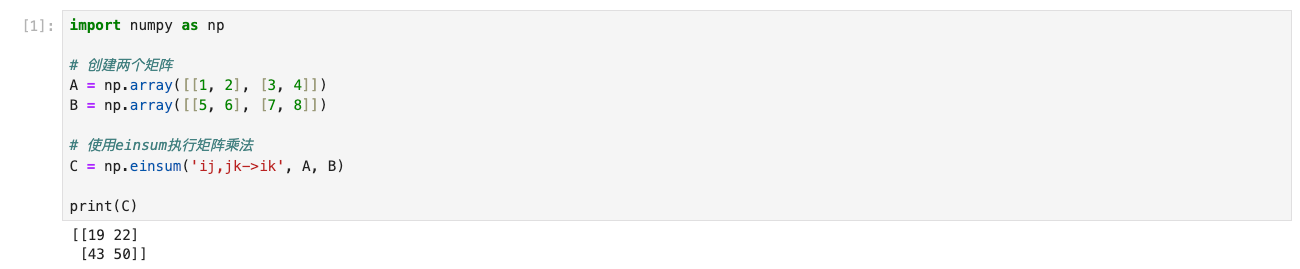
在上面的例子中,
'ij,jk->ik'
描述了输入矩阵A和B的维度关系,以及它们如何相乘以生成输出矩阵C。
这两个矩阵A和B如下所示:
A = [[1, 2],
[3, 4]]
B = [[5, 6],
[7, 8]]
接下来,我们使用
einsum
函数执行矩阵乘法操作:
C = np.einsum('ij,jk->ik', A, B)
在这个einsum函数中,字符串
'ij,jk->ik'
描述了输入矩阵A和B的维度关系以及它们如何相乘以生成输出矩阵C。
- 字符串中的每个字母代表一个矩阵的维度标签。在这里,
'i'和’j’表示矩阵A的行和列,'j'和’k’表示矩阵B的行和列。 - 箭头
'->'之前的部分'ij,jk'表示了乘法操作中两个矩阵的维度关系。 - 箭头
'->'之后的部分'ik'表示了输出矩阵C的维度关系,即输出矩阵的行来自矩阵A,列来自矩阵B。
根据这个操作字符串,
einsum
函数将矩阵A和B相乘,并将结果存储在矩阵C中。最终,输出矩阵C将是一个
2x2
的矩阵,其计算结果如下:
C = [[1*5 + 2*7, 1*6 + 2*8],
[3*5 + 4*7, 3*6 + 4*8]]
计算结果为:
C = [[19, 22],
[43, 50]]
einsum操作可以用于更复杂的张量运算,例如张量的点积、求和、转置等。通过灵活地指定操作字符串,您可以实现许多不同类型的张量操作,这使得einsum成为处理多维数据的强大工具。
2-2:代码分析
这段代码涉及了PyTorch库、einops库以及自定义的函数调用。
import torch
from einops import rearrange, repeat
from HIPT_4K.hipt_model_utils import get_vit256, get_vit4k
import torch: 这行代码导入了PyTorch库,PyTorch是一个用于深度学习的开源机器学习库,提供了张量运算和神经网络构建等功能。from einops import rearrange, repeat: 这行代码从einops库中导入了rearrange和repeat函数。einops是一个用于重塑和操作张量的库,它提供了简单而强大的工具来处理张量的形状。from HIPT_4K.hipt_model_utils import get_vit256, get_vit4k: 这行代码从自定义的"HIPT_4K"模块中导入了get_vit256和get_vit4k函数。
总体来说,这段代码的作用是导入PyTorch库、einops库中的函数,并从自定义模块中导入特定的函数以便后续使用。
这段代码定义了一个名为
HIPT_4K的PyTorch模型类,该类继承自
torch.nn.Module。
classHIPT_4K(torch.nn.Module):"""
HIPT Model (ViT_4K-256) for encoding non-square images (with [256 x 256] patch tokens), with
[256 x 256] patch tokens encoded via ViT_256-16 using [16 x 16] patch tokens.
"""def__init__(self,
model256_path:str='path/to/Checkpoints/vit256_small_dino.pth',
model4k_path:str='path/to/Checkpoints/vit4k_xs_dino.pth',
device256=torch.device('cuda:0'),
device4k=torch.device('cuda:1')):super().__init__()
self.model256 = get_vit256(pretrained_weights=model256_path).to(device256)
self.model4k = get_vit4k(pretrained_weights=model4k_path).to(device4k)
self.device256 = device256
self.device4k = device4k
self.patch_filter_params = patch_filter_params
class HIPT_4K(torch.nn.Module): 这行代码定义了一个名为HIPT_4K的PyTorch模型类,该类继承自torch.nn.Module,表明这个类是一个PyTorch模型。def __init__(self, model256_path: str = 'path/to/Checkpoints/vit256_small_dino.pth', model4k_path: str = 'path/to/Checkpoints/vit4k_xs_dino.pth', device256=torch.device('cuda:0'), device4k=torch.device('cuda:1')):: 这是类的构造函数__init__,它接受四个参数:model256_path(指向Vit_256模型的预训练权重路径)、model4k_path(指向Vit_4K模型的预训练权重路径)、device256(Vit_256模型所在的设备,默认为第一个CUDA设备)、device4k(Vit_4K模型所在的设备,默认为第二个CUDA设备)。super().__init__(): 调用父类torch.nn.Module的构造函数,初始化HIPT_4K类。self.model256 = get_vit256(pretrained_weights=model256_path).to(device256): 使用get_vit256函数加载Vit_256模型的预训练权重,并将其移动到device256设备。self.model4k = get_vit4k(pretrained_weights=model4k_path).to(device4k): 使用get_vit4k函数加载Vit_4K模型的预训练权重,并将其移动到device4k设备。self.device256 = device256: 将device256设备保存在类属性中,以便后续使用。self.device4k = device4k: 将device4k设备保存在类属性中,以便后续使用。self.patch_filter_params = patch_filter_params: 用于处理图像中的补丁信息。
总体来说,这个类的作用是组合了
Vit_256
和Vit_4K模型,分别加载它们的预训练权重,并将它们移动到指定的设备上。这个类用于处理非方形图像的编码任务,其中
[256 x 256]
的补丁通过Vit_256-16模型使用
[16 x 16]
的补丁进行编码。
这段代码定义了
HIPT_4K类中的
forward方法,用于执行模型的前向传播过程。
defforward(self, x):"""
Forward pass of HIPT (given an image tensor x), outputting the [CLS] token from ViT_4K.
1. x is center-cropped such that the W / H is divisible by the patch token size in ViT_4K (e.g. - 256 x 256).
2. x then gets unfolded into a "batch" of [256 x 256] images.
3. A pretrained ViT_256-16 model extracts the CLS token from each [256 x 256] image in the batch.
4. These batch-of-features are then reshaped into a 2D feature grid (of width "w_256" and height "h_256".)
5. This feature grid is then used as the input to ViT_4K-256, outputting [CLS]_4K.
Args:
- x (torch.Tensor): [1 x C x W' x H'] image tensor.
Return:
- features_cls4k (torch.Tensor): [1 x 192] cls token (d_4k = 192 by default).
"""
batch_256, w_256, h_256 = self.prepare_img_tensor(x)# 1. [1 x 3 x W x H].
batch_256 = batch_256.unfold(2,256,256).unfold(3,256,256)# 2. [1 x 3 x w_256 x h_256 x 256 x 256]
batch_256 = rearrange(batch_256,'b c p1 p2 w h -> (b p1 p2) c w h')# 2. [B x 3 x 256 x 256], where B = (1*w_256*h_256)
features_cls256 =[]for mini_bs inrange(0, batch_256.shape[0],256):# 3. B may be too large for ViT_256. We further take minibatches of 256.
minibatch_256 = batch_256[mini_bs:mini_bs+256].to(self.device256, non_blocking=True)
features_cls256.append(self.model256(minibatch_256).detach().cpu())# 3. Extracting ViT_256 features from [256 x 3 x 256 x 256] image batches.
features_cls256 = torch.vstack(features_cls256)# 3. [B x 384], where 384 == dim of ViT-256 [ClS] token.
features_cls256 = features_cls256.reshape(w_256, h_256,384).transpose(0,1).transpose(0,2).unsqueeze(dim=0)
features_cls256 = features_cls256.to(self.device4k, non_blocking=True)# 4. [1 x 384 x w_256 x h_256]
features_cls4k = self.model4k.forward(features_cls256)# 5. [1 x 192], where 192 == dim of ViT_4K [ClS] token.return features_cls4k
batch_256, w_256, h_256 = self.prepare_img_tensor(x): 这行代码调用prepare_img_tensor方法,对输入的图像张量x进行预处理,返回裁剪后的图像张量以及宽度w_256和高度h_256信息。batch_256 = batch_256.unfold(2, 256, 256).unfold(3, 256, 256): 对裁剪后的图像张量进行展开操作,将其转换为[1 x 3 x w_256 x h_256 x 256 x 256]的形状。batch_256 = rearrange(batch_256, 'b c p1 p2 w h -> (b p1 p2) c w h'): 使用rearrange函数重新排列张量的维度,将其转换为[B x 3 x 256 x 256]的形状,其中B = (1 * w_256 * h_256)。- 在一个循环中,对
batch_256进行分批处理,以便ViT_256模型能够处理。每个小批次的大小为256。 features_cls256 = torch.vstack(features_cls256): 将ViT_256提取的特征列表垂直堆叠在一起,得到形状为[B x 384]的张量,其中384是ViT-256的[CLS]标记的维度。- 对
features_cls256进行形状调整和转置操作,最终得到形状为[1 x 384 x w_256 x h_256]的张量,并将其移动到device4k设备。 features_cls4k = self.model4k.forward(features_cls256): 将经过ViT_256处理后的特征作为输入,通过ViT_4K模型进行前向传播,得到ViT_4K的[CLS]标记,返回形状为[1 x 192]的张量,其中192是ViT_4K的[CLS]标记的默认维度。
总体来说,这个
forward
方法实现了对输入图像进行预处理、特征提取和模型间传递的操作,最终输出ViT_4K模型的[CLS]标记。
2-3:使用 HIPT_4K 应用程序接口
您可以使用开箱即用的 HIPT_4K 模型,并将其即插即用到任何下游任务中(示例如下)。
这段代码展示了如何使用之前定义的
HIPT_4K模型类来对一张图像进行推理。
from HIPT_4K.hipt_4k import HIPT_4K
from HIPT_4K.hipt_model_utils import eval_transforms
model = HIPT_4K()
model.eval()
region = Image.open('HIPT_4K/image_demo/image_4k.png')
x = eval_transforms()(region).unsqueeze(dim=0)
out = model.forward(x)
from HIPT_4K.hipt_4k import HIPT_4K: 导入之前定义的HIPT_4K模型类,该类包含了模型的结构和前向传播方法。from HIPT_4K.hipt_model_utils import eval_transforms: 导入用于评估的图像转换函数eval_transforms,可能包含了对输入图像进行预处理的操作。model = HIPT_4K(): 创建了一个HIPT_4K模型的实例model。model.eval(): 将模型设置为评估模式,这会影响模型中的一些操作,如Dropout层的行为。region = Image.open('HIPT_4K/image_demo/image_4k.png'): 打开名为image_4k.png的图像文件,这个图像将被用作输入进行推理。x = eval_transforms()(region).unsqueeze(dim=0): 对打开的图像region应用评估转换函数,这可能包括对图像进行归一化、缩放或其他预处理操作。然后,通过unsqueeze(dim=0)将图像张量的维度扩展为[1 x C x W x H],以符合模型的输入要求。out = model.forward(x): 将处理后的图像张量x传递给model的forward方法进行推理,得到输出结果out。在这个过程中,模型将执行图像的预处理、特征提取和模型间传递操作,最终输出ViT_4K模型的[CLS]标记。
通过这段代码,你可以使用已经训练好的
HIPT_4K
模型对输入图像进行推理,从而获取模型对图像的表示。
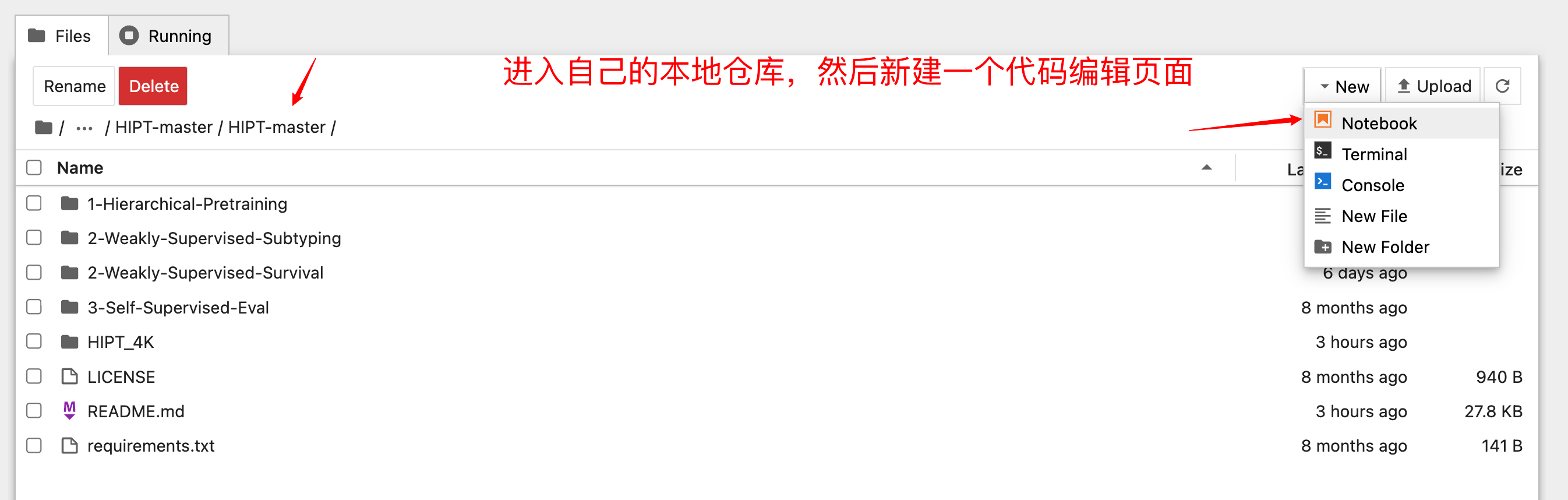
2-4:动手实操
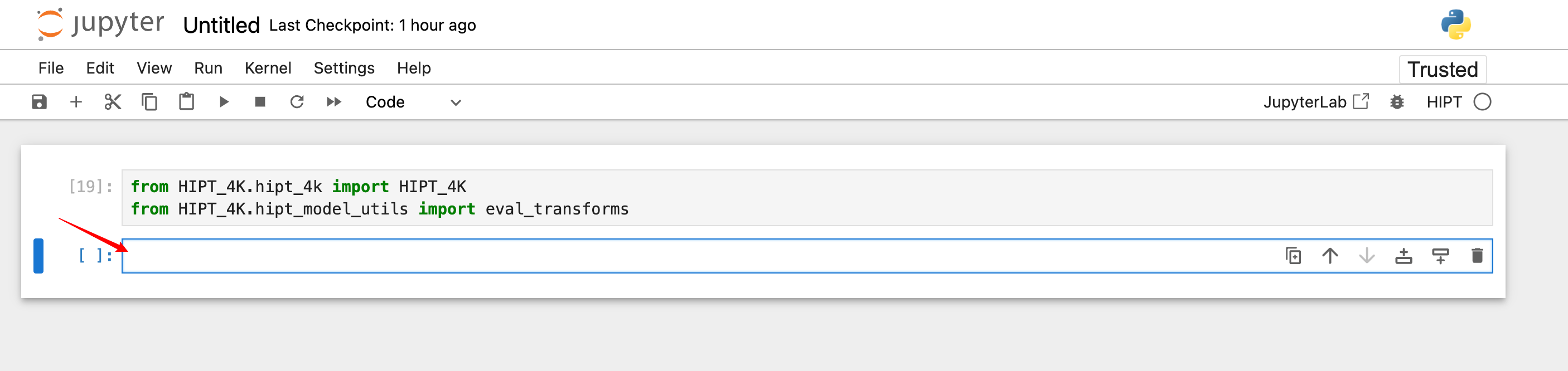
首先按下图操作新建页面。
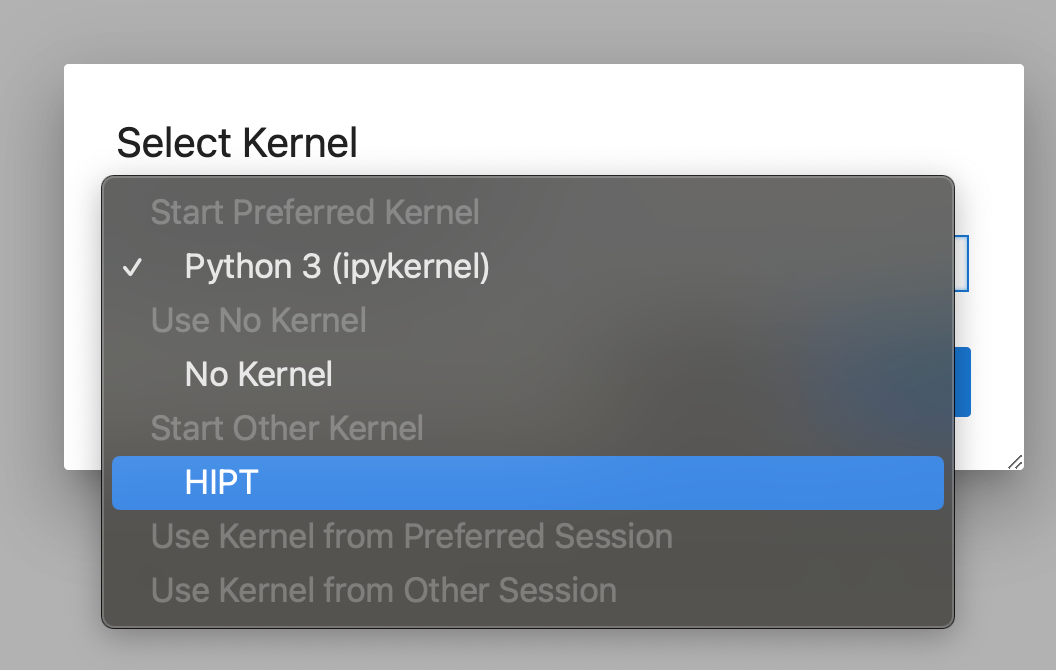
切换内核。
运行代码
from HIPT_4K.hipt_4k import HIPT_4K
from HIPT_4K.hipt_model_utils import eval_transforms
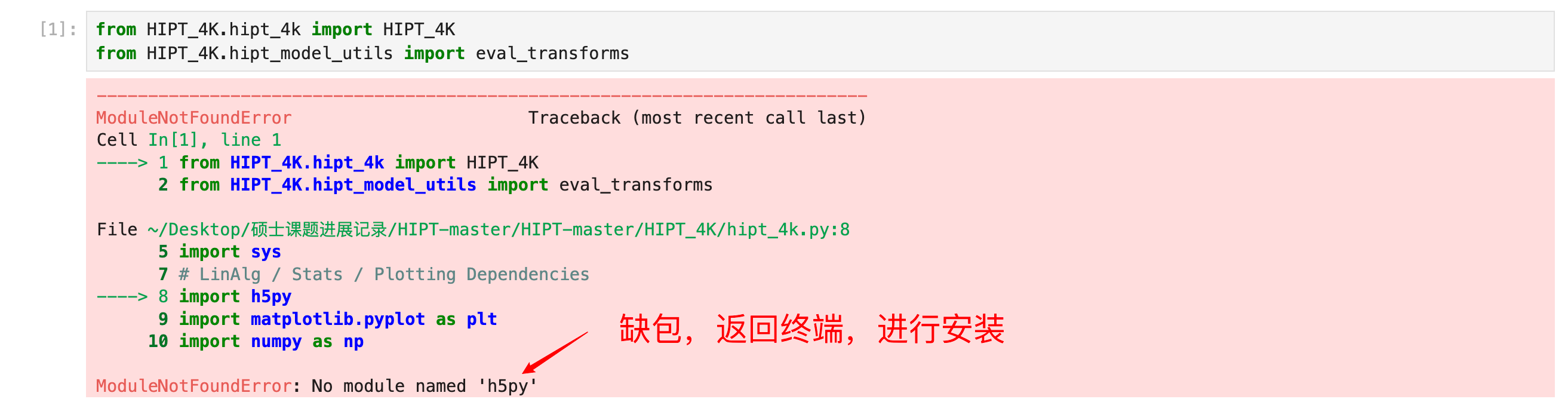
装包
pip install h5py

再次运行代码
from HIPT_4K.hipt_4k import HIPT_4K
from HIPT_4K.hipt_model_utils import eval_transforms
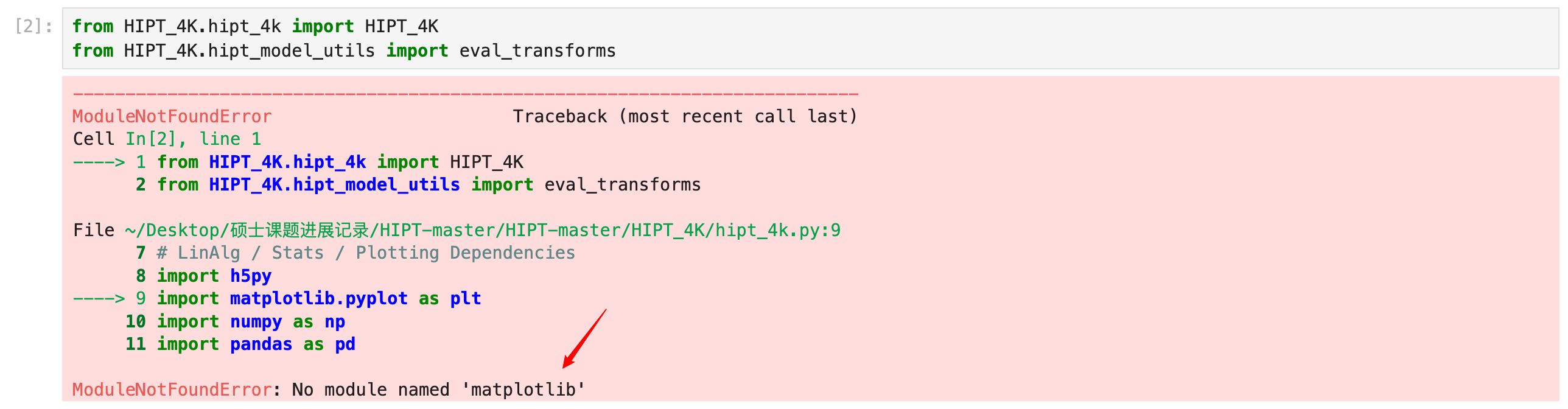
我算是明白了,这是压根就没装依赖环境,不想一个一个装了,直接找到requirements文件。
pip install -r requirements.txt
奇怪,刚刚明明看到有装numpy了,为什么还是报错?
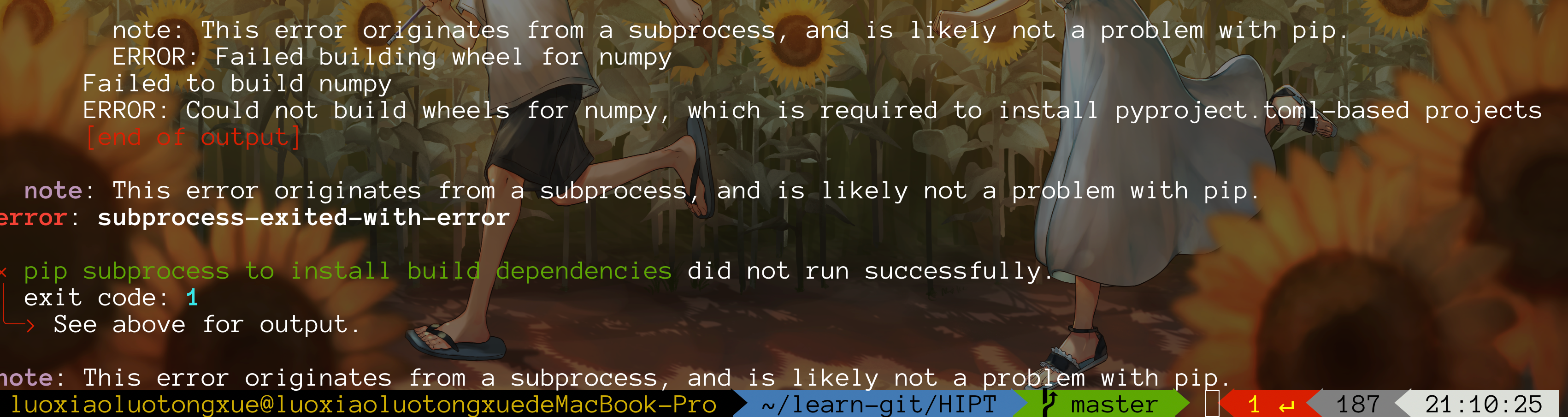
不管了,再次运行代码
pip install matplotlib

这回让我看看你还缺啥
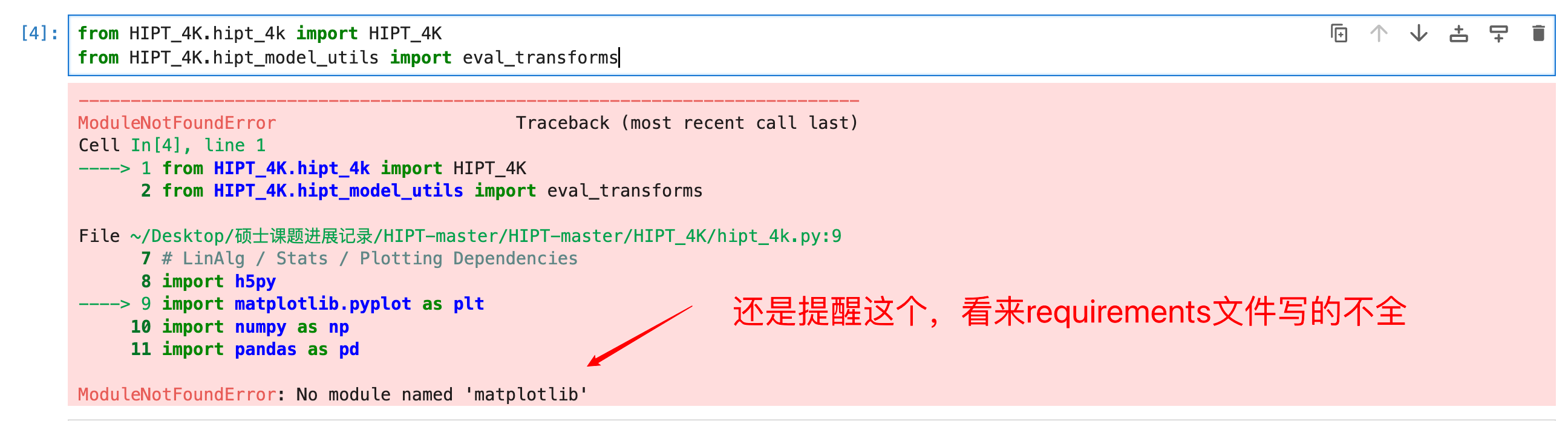
好吧,缺的东西很多,我就不一一放图了。
pip install pandas
pip install tqdm
pip install einops
这里遇到一个问题,vision_transformer是一个自定义的包,你用pip是无法安装的。
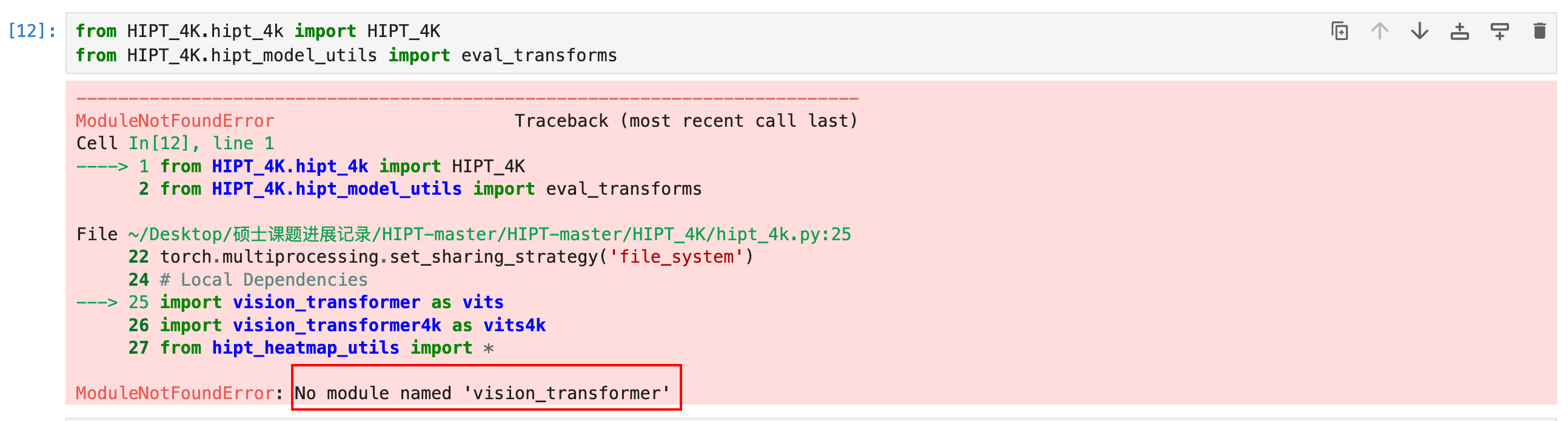
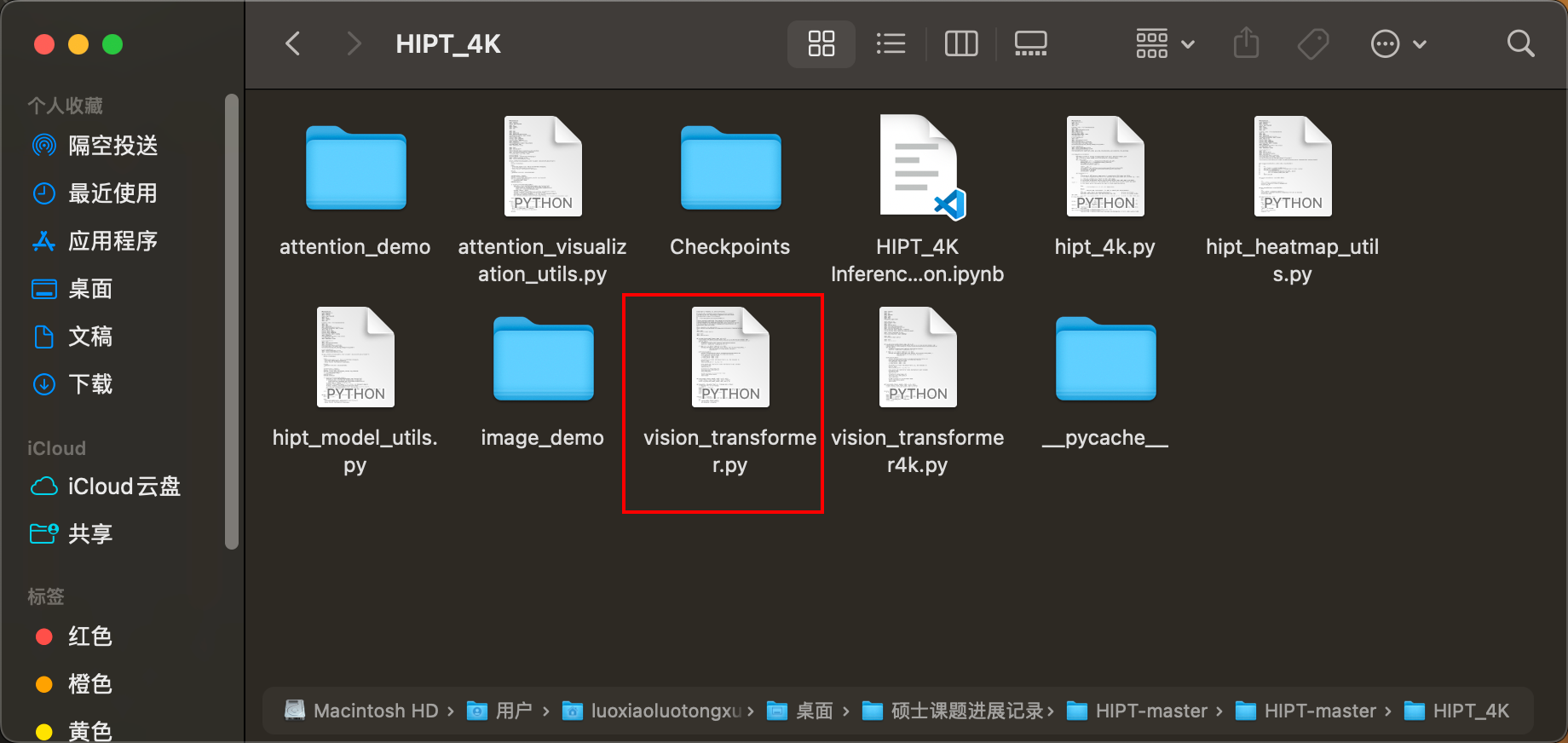
所以,需要将这个文件导入到你的虚拟环境下。
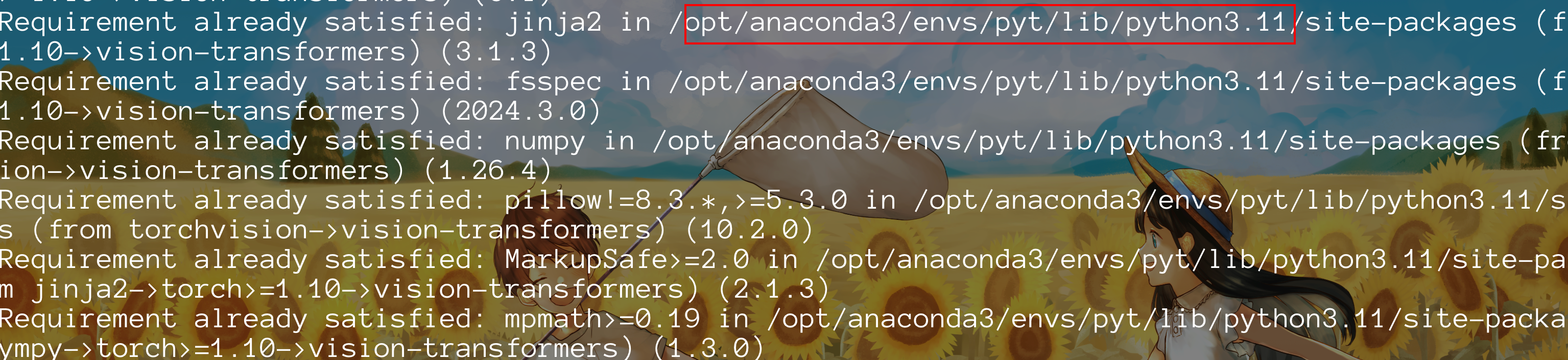
直接在终端输入指令
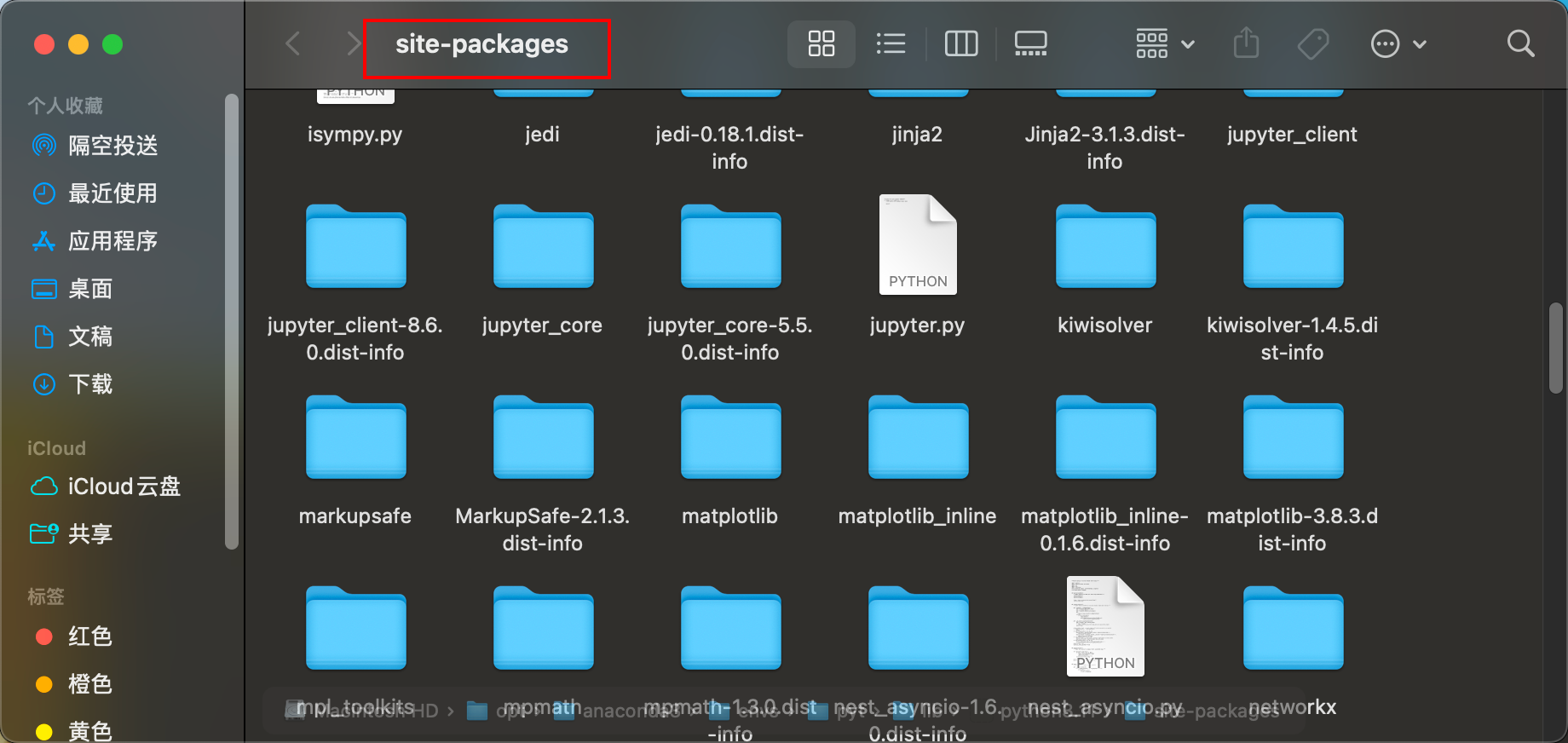
open/opt/anaconda3/envs/pyt/lib/python3.11/site-packages
然后将相应的文件拖进来就好了。
接下来这个如法炮制
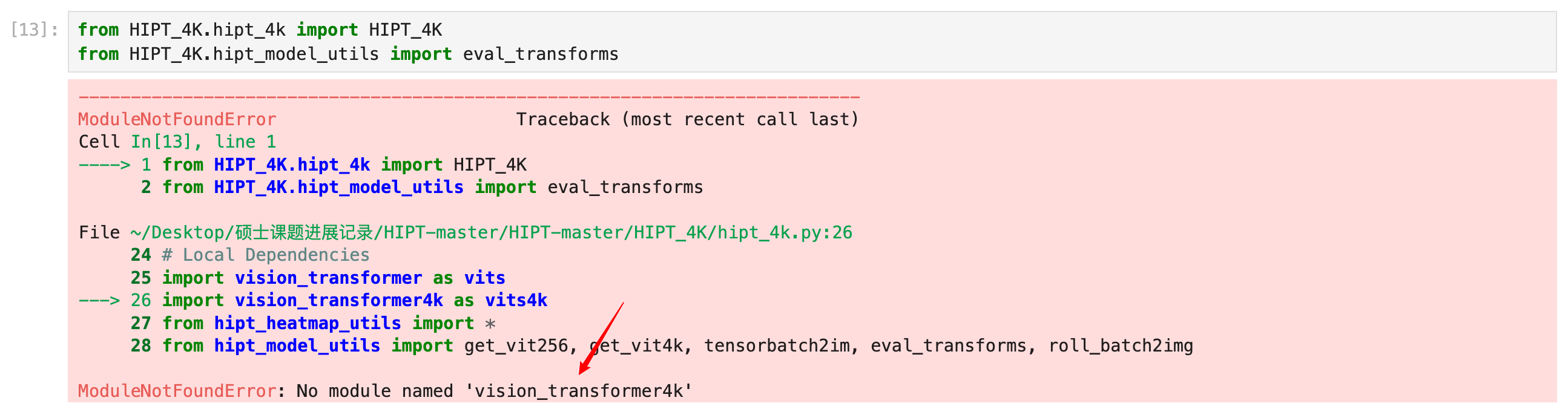
后续的不再一一展示,需要复制的,都给你们标记出来了。
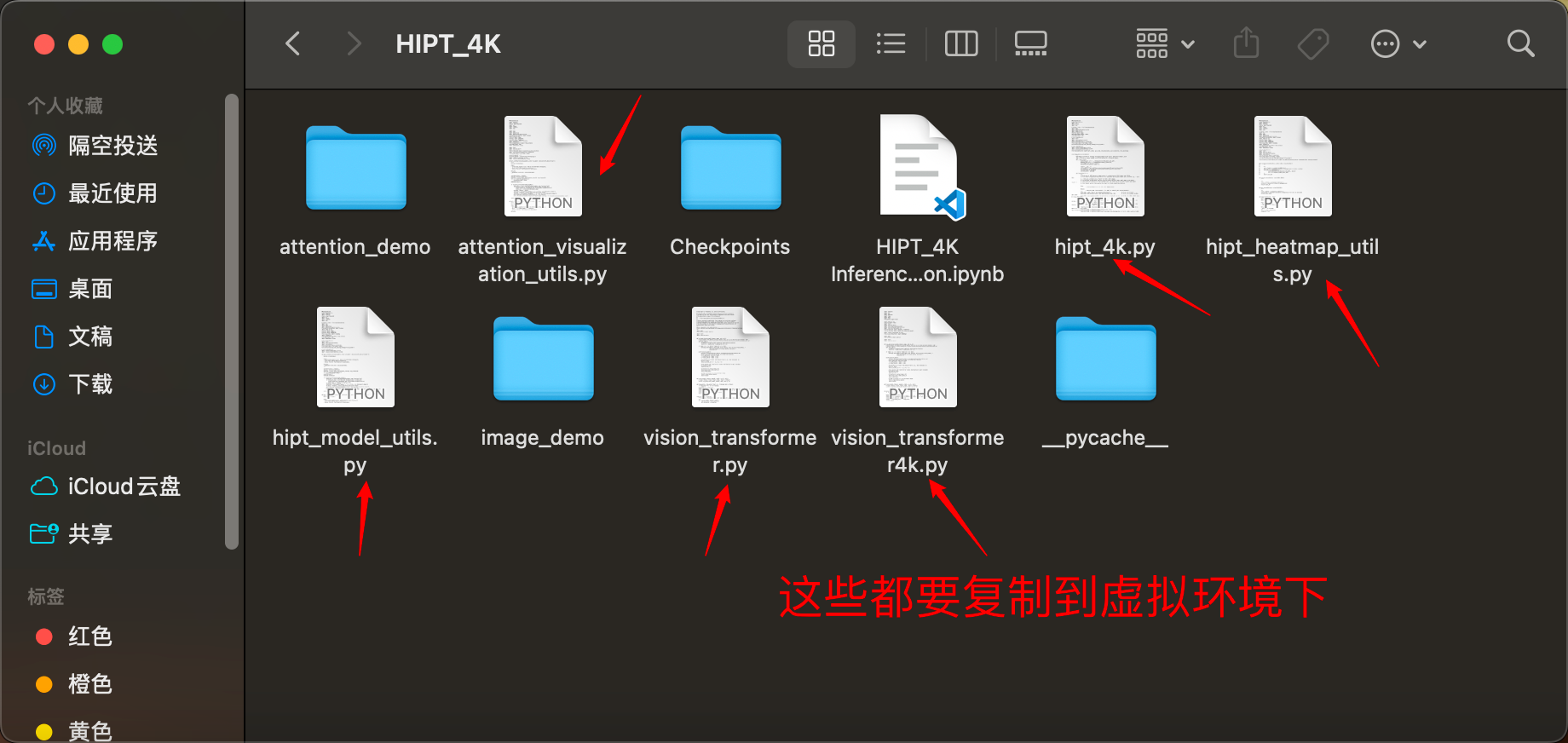
这个又要去pip安装了,但是略有区别
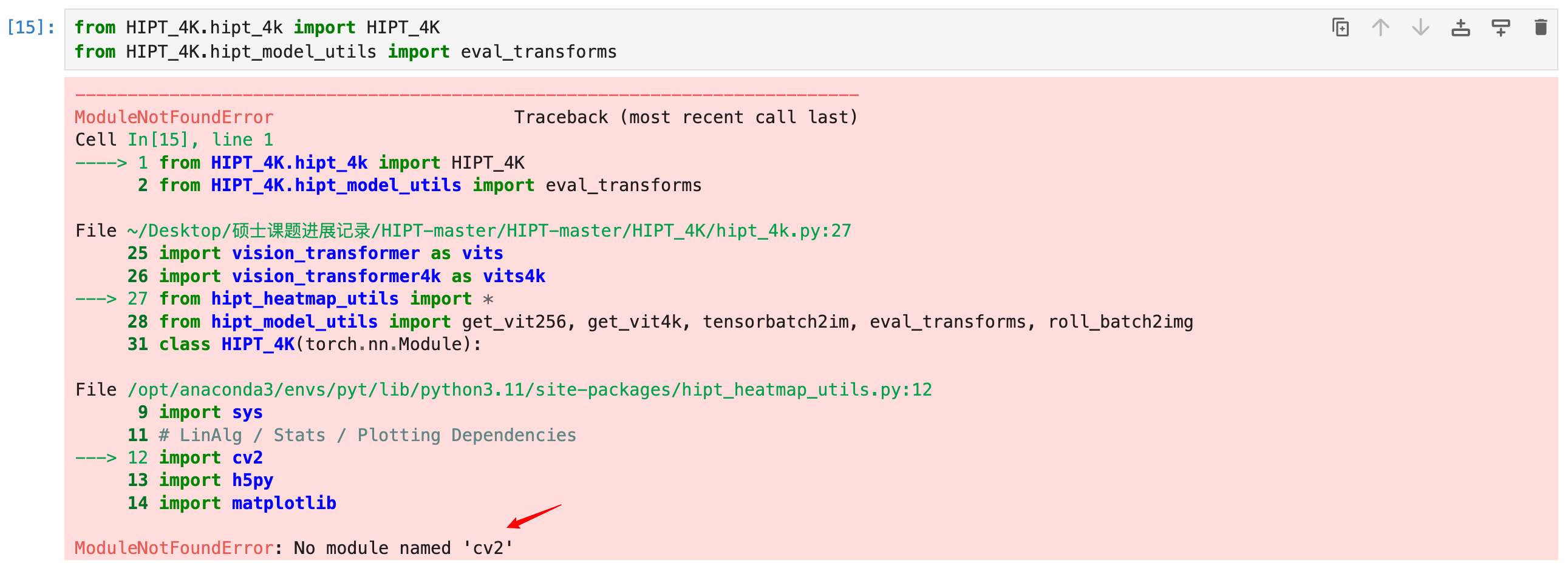
pip install opencv-python
pip install scipy
pip install scikit-image
pip install webdataset
终于可以进行下一阶段了。
model = HIPT_4K()
model.eval()
上来就给我报错,报一个大错,爽翻。

进cuda官网转转

三、服务器操作
本地是没办法跑了,所以我宣布,转移到服务器再战!!
未完待续
版权归原作者 罗小罗同学 所有, 如有侵权,请联系我们删除。