
2026 年用于构建 agent 的开源工具包已经已经得到了巨大的发展,所以本篇文章将从以下角度来帮助你如何选择最适合你的工具:延迟预算、审计追踪、模型可移植性、还是语言栈。
我们总结了7层需求,选择每一层的工具时,可以问三个问题:
主要约束是什么? 四个约束决定了大多数层的选择。延迟预算是每轮能花多少 token 或毫秒;审计追踪是每个行为是否必须可追溯以满足合规;模型可移植性是技术栈对单个供应商的依赖程度;语言栈是团队用 Python、TypeScript 还是两者兼用。通常其中一项在每一层占主导。
选错之后的替换成本是多少? 换一个 MCP 服务器改一行配置就够了。换编排层需要重写状态 schema、节点和边。重写幅度越大,越应该先按约束来选。
它是开源还是开放核心? 开放核心项目以开源许可证发布,但生产功能(多租户认证、复制、SSO、审计日志)只在托管云产品里运行。仓库的功能列表会告诉你买的是哪一边。
第 1 层:编排与运行时控制
编排层运行 agent 的推理循环。LLM 选择行为,运行时执行,运行时观察结果,LLM 再次选择。没有这一层就要自己写循环——上线前得重新实现重试、checkpointing 和人在环门控。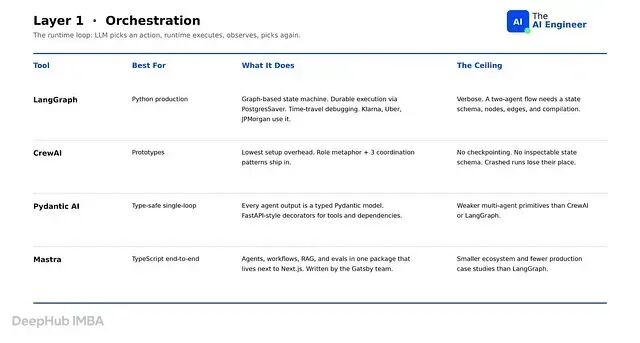
LangGraph 是 Python 生产环境的默认选择。基于图的状态机,通过 PostgresSaver 实现持久化执行,支持时间旅行调试,企业用户名单(Klarna、Uber、LinkedIn、JPMorgan、Replit)是该领域最大的经验证列表。图状态结构恰好契合受监管行业的需要:每次状态转换都是审计日志里的一条记录,崩溃的运行可以回滚到上一个节点并从那里重放。不过它太大了,哪怕只是两个 agent 的流程,也需要定义状态 schema、节点、边,再经过编译。对于"顺序调用三个工具"这类场景,用它确实过重了。
CrewAI 是四个编排框架中设置成本最低的。声明角色(researcher、writer、reviewer),选择协作模式,无需先定义状态 schema 就能跑起来。天它以牺牲生产耐久性为代价换取了原型开发速度。框架无法从崩溃点恢复运行,错误处理在 crew 级别而非每个节点级别,也没有可检查的状态 schema 记录 agent 在什么时候做了什么决定。等到生产状态管理比角色隐喻更重要的时候,团队就会从 CrewAI 迁移到 LangGraph。
Pydantic AI 把所有 agent 输出都当作带类型的 Pydantic 模型处理,校验、重试和下游序列化因此自动获得。工具和依赖关系采用 FastAPI 风格的装饰器。多 agent 原语弱于 CrewAI 或 LangGraph。最适合的场景是 agent 作为单循环运行,且必须向下游服务返回经过验证的数据。
Mastra 是 TypeScript 写的。agent、工作流、RAG 和评估集成在一个包里,由前 Gatsby 创始人开发,设计上可以直接嵌入现有的 Next.js 应用而不需要 Python 辅助服务。不过这个生态系统较小,生产案例研究比 LangGraph 少。团队已经在端到端 TypeScript 栈上且不打算用 Python 重写时,选 Mastra。
第 2 层:记忆与状态
上下文窗口不是记忆。哪怕是 200K token 的窗口,每轮对话都要为整个对话重新计算,会话结束后什么都不会留下。2026 年的生产级 agent 把记忆放在一个独立于提示的专用层里。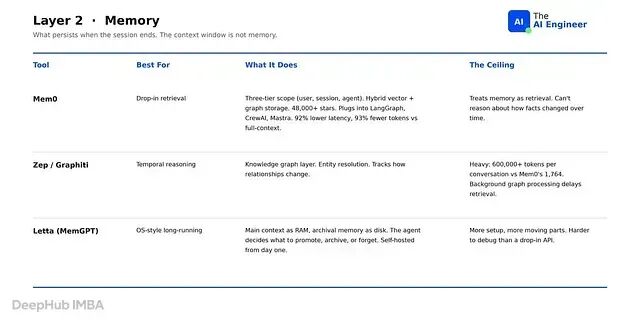
Mem0 的记忆可以按用户(跨所有会话持久化)、会话(仅当前对话)或 agent(跨该 agent 的所有用户共享)分别限定范围。混合存储结合了向量与图,有成熟的 SDK 可接入 LangGraph、CrewAI 和 Mastra。GitHub 48,000+ 星标。ECAI 2025 论文在 LoCoMo 上对 Mem0 和十种替代方案进行了 benchmark 测试,相比朴素的全上下文(每个团队第二周就会丢掉的基线),延迟降低 92%,token 减少 93%,在相同召回率下推理成本大约便宜 14 倍。不过Mem0 把记忆当作检索,返回与查询最相似的事实。时间推理——比如"用户上周说的和今天说的有矛盾"——需要一个用时间戳跟踪事实间边关系的图
Zep / Graphiti 是时间图选项。知识图谱层处理实体解析:确定"Alice"、"alice@ a"和"CEO"指向同一个人。它还跟踪关系随时间的变化,使 agent 能回答"这个客户在 Q2 的状态是什么样的"或"合同负责人是什么时候换的"。代价是图构建很昂贵——Zep 每条对话的记忆占用超过 600,000 token,而 Mem0 只有 1,764;刚输入后的检索也经常失败,因为正确答案只有后台图处理完成后才会出现。需要 agent 对历史进行推理、且能接受等待秒级而非毫秒级的场景,选 Zep。
Letta(原名 MemGPT) 把记忆当作操作系统来处理。主上下文是 RAM,归档记忆是磁盘,agent 决定把什么升级到 RAM、归档到磁盘或丢弃。完全开源、模型无关、从一开始就支持自托管。分页进出记忆的机制让 agent 的有效上下文得以远超 LLM 原生窗口的限制——和操作系统给程序提供比物理 RAM 更多的虚拟内存是同一个思路。不过这个需要自己运行存储层。比起调用托管的 Mem0 端点,Letta 更难部署,调试也更复杂,因为记忆决策是 agent 在运行时内部做出的。
第 3 层:协议与工具
两年前这一层还是函数调用:每家供应商有自己的 JSON schema,每个框架以不同方式包装它们,换模型就得重写工具。
不过现在这一层已经统一成 MCP了。Model Context Protocol 是 Claude Agent SDK 使用的开放标准,OpenAI Agents SDK 原生支持,Google ADK 集成,每个严肃的框架现在都为其提供了客户端。如果今天在写工具,就是在写 MCP 服务器。
这一层没有框架可选。第 1 层的编排选择已经决定了 MCP 如何集成。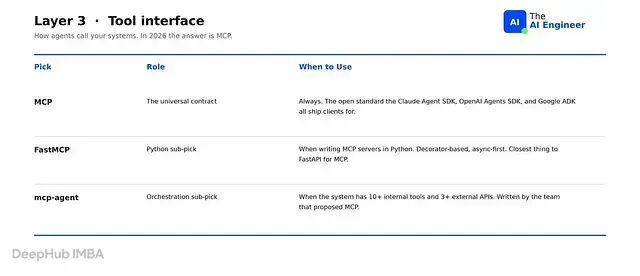
FastMCP 是用于快速编写 MCP 服务器的 Python 框架。基于装饰器、异步优先,是最接近 FastAPI 体验的 MCP 写法。mcp-agent 是一个围绕 MCP 作为主要工具接口构建的编排框架,服务器生命周期、多服务器路由和提示上下文处理都内置其中。用 LangGraph 或 CrewAI 时这些集成代码需要自己写。当 agent 连接多个 MCP 服务器、集成代码开始成为瓶颈时,可以看一下 mcp-agent。
第 4 层:浏览器与计算机使用
当 agent 需要操作的系统没有暴露 API 时,工具包必须通过屏幕来操作。2026 年的领域分为两种架构方案:DOM 驱动(解析页面、找到元素、点击)和视觉驱动(截屏、交给视觉模型、点击像素)。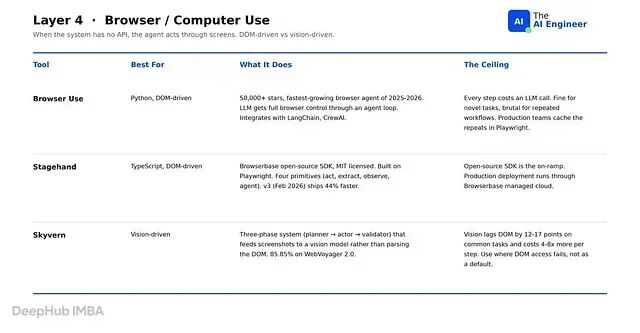
Browser Use 是 Python 的默认选择。50,000+ GitHub 星标,2025-2026 年增长最快的开源 AI 项目之一。LLM 通过 agent 循环获得浏览器的完整控制权,与 LangChain、CrewAI 和自定义框架集成。这个最大的问题是每一步都消耗一次 LLM 调用,新颖任务尚可,重复工作流则成本过高。一般情况下生产环境通常把重复的 80% 缓存到 Playwright(确定性浏览器自动化库)里,Browser Use 只处理需要推理的 20%。
Stagehand 是 TypeScript 的对应选项。来自 Browserbase 的开源 SDK,MIT 许可证,构建在 Playwright 之上。四个原语让开发者在需要推理的步骤上保留 AI 推理,其余部分用脚本化的 Playwright 代码处理。Stagehand v3(2026 年 2 月)在 Chrome DevTools Protocol 上重写了引擎,速度提升 44%。
Skyvern 是视觉优先选项。每个任务经过三阶段流水线:规划器将目标分解为步骤,执行器把截图发给视觉模型并点击其返回的坐标,验证器确认页面发生了变化。Skyvern 在 WebVoyager 2.0 上得分 85.85%,这是在 DOM 不可靠的领域(canvas 元素、嵌套在 iframe 中的 React 虚拟 DOM、反机器人机制)中表单填写任务的最强已发布分数。换算成实际使用:大约七分之一的多步骤任务还是会失败。这个最大的问题就是费钱,视觉驱动栈在常见任务上落后 DOM 驱动栈 12-17 个点,每一步的成本高 4-8 倍。
2026 年的生产模式通常两者并用:DOM 驱动作为主路径,Skyvern 或 Anthropic Computer Use 或 OpenAI CUA 作为选择器在 canvas 元素或反机器人屏幕上持续失败时的备选路径。
第 5 层:编码 Agent 与沙箱
编码 agent 现在自成一类。它们编写代码、运行代码、在出错时调试、翻文档弄清楚错在哪里。与其他六层不同,这一层额外带了三样东西:沙箱化的文件系统(用于编写和编辑代码而不逃逸到宿主机)、终端访问(用于运行构建、测试和 linter)、以及一个浏览器工具(因为一半的工作涉及阅读文档)。这个类别有自己的 benchmark——SWE-bench Verified,一组精选的真实 GitHub issue,agent 必须将其解决为可运行的 PR。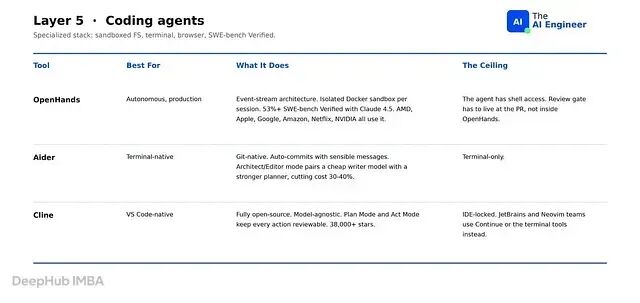
OpenHands(原名 OpenDevin) 是生产级的自主选项。72,000+ GitHub 星标,$18.8M A 轮融资,在 AMD、Apple、Google、Amazon、Netflix 和 NVIDIA 的生产环境中使用。事件流架构每轮经过四个状态:agent 推理、agent 发出行为、环境执行、环境返回观察结果。每个会话在隔离的 Docker 沙箱里运行。这个类别的核心指标是 agent 能在多大比例的真实 bug 工单上端到端解决而无需人工介入——OpenHands 在 SWE-bench Verified 上使用 Claude 4.5 得分 53%+,已发布的平台结果用 Claude 4 达到 72%。不过他的agent 有 shell 访问权限,审查不能放在 OpenHands 内部,必须落在 PR 层面。
Aider 是终端原生选项,也是最初的开源编码 agent。35,000+ GitHub 星标,93 个版本累计 13,100+ 次提交。天生集成 git:每个变更都成为一次提交,自动生成的消息说明改了什么,整个 agent 会话的轨迹就在 git 历史里。架构师/编辑器模式把工作分给两个模型:较强的那个规划编辑,较便宜的那个写代码。拆分后成本比全程用顶级模型降低 30-40%。Aider 在 SWE-bench Verified 上使用 Claude 4.5 得分 32%,远低于 OpenHands因为每个行为都有 git 记录。他的最大问题是仅限终端,没有 IDE 集成,项目级上下文也仅限于传递给 Aider 的文件。
Cline 是 VS Code 原生的选项。38,000+ GitHub 星标,完全开源,模型无关,是 VS Code 团队中唯一拥有实际市场份额的工具。计划模式和行动模式将意图与执行分离:计划模式起草变更列表并暂停等待审批,行动模式执行已批准的计划。每个行为在接触代码库之前都可以审查——这正是工程经理首先会问的设计要点。团队在 VS Code 上工作且政策要求每步都有人工审查时,选 Cline。
2026 年运行生产级编码 agent 的团队大多会并用两个:一个商业版(Claude Code、Codex)处理困难任务,一个开源版保持灵活性和故障转移能力。
第 6 层:评估与可观测性
评估与可观测性层记录 agent 在生产中做了什么,并在上线前测试它能做什么。追踪捕获每次 LLM 调用、工具调用和成本,按用户和会话索引,出现错误输出时可以重放产生它的确切上下文。评估是可重复的测试套件,agent 针对固定输入运行,每次按相同标准评分。2026 年的生产级 agent 团队从第一天起就把两者都接入。跳过这一层是 agent 工程里代价最高的一个决策失误。
Langfuse 是开源可观测性的默认选择。开放核心模式,自托管层级相当慷慨,与 LangGraph、CrewAI、OpenAI Agents SDK 和 Mastra 有原生集成。每次 LLM 调用、工具调用和成本都被追踪并索引。托管保留、SSO 和高级评估功能在 SaaS 计划上运行,自托管版本覆盖追踪和仪表板。
Arize Phoenix 是 OpenTelemetry 原生的替代方案。追踪数据流入已有的 Grafana、Datadog 或 Honeycomb 仪表板,agent 遥测与 API 和服务追踪放在一起,而不是独立的工具。在 RAG 评估和检索质量方面表现突出。Phoenix 不提供有预设的 agent 特定默认配置,流水线组装要自己来。
Inspect AI 是英国 AI 安全研究所的开源评估框架,为安全评估而编写:测试 agent 是否拒绝越狱、泄漏 PII 或生成不安全内容。前沿实验室现在也用它做能力和对齐 benchmark。Inspect 只用于离线评估,需要实时观测生产状态的话,还需要搭配 Langfuse 或 Phoenix。
第 7 层:模型与推理
agent 走的每一步至少是一次推理调用,通常更多。运行这些调用的引擎——包装 GPU 的软件、批处理请求、管理 KV 缓存——决定了其他所有事情的成本下限。托管 API 的 agent 继承供应商的引擎;自托管的 agent 自己选择引擎,这个选择决定了大规模运行时的成本。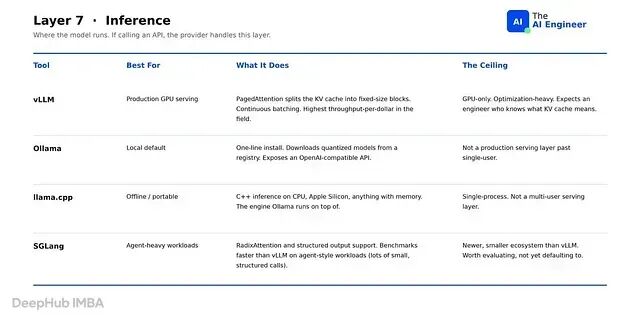
vLLM 是开源权重模型的生产服务默认选择。核心创新是 PagedAttention:一种内存管理方案,将 KV 缓存切分为固定大小的块,让多个请求共享 GPU 内存而不浪费空间。结合持续批处理,在该领域产生了最高的每美元吞吐量。vLLM仅支持 GPU,优化负担重,且假设操作者清楚 KV 缓存的含义。
Ollama 是本地默认选择。一行安装,从 registry 下载量化模型,暴露 OpenAI 兼容的 API。量化将权重从 16 位压缩到 4 或 8 位,以少量精度损失换取在笔记本电脑 RAM 中运行的能力。Ollama 不适合作为单用户之外的生产服务层。
llama.cpp 是 Ollama 运行的底层引擎。纯 C++,无 GPU 依赖,可以在 CPU、Apple Silicon、Raspberry Pi 和任何有足够 RAM 的设备上运行 LLM。这个项目还定义了 GGUF——用于分发量化开源权重模型的文件格式,相同的模型文件在所有基于 llama.cpp 的工具上可以原封不动地运行。llama.cpp 只适合本地和离线工作负载。
SGLang 是较新的挑战者,两个设计选择使其与众不同。当多个请求共享开头的提示时,SGLang 缓存该前缀的计算结果并复用,而不是每次调用都重新计算;当 agent 需要 JSON 输出时,SGLang 在推理引擎内部强制执行 schema,模型从源头就无法生成无效 JSON。在 agent 工作负载上,SGLang 的 benchmark 结果比 vLLM 快。不过它社区较小,集成较少,在生产大规模场景下不如 vLLM 经过充分验证。
七层并不自动组合
当你看到看到七层图时,第一的反应是假设各层可以垂直组合:选第 1 层,它约束第 2 层,第 2 层约束第 3 层,正确的工具集其实是每个格子都能拼在一起的那个。
2026 年大多数 agent 重写项目都是从这个假设开始的。没有任何一个生态在七层上全部同类最佳;层之间的集成也从未被设计为可组合的,它们在薄薄的接缝处对接:一个配置文件、一个 import、一个 HTTP 调用。
这七层是七个独立的决策,每一层都有一个主要约束决定胜者。四个约束决定了大多数选择:延迟预算、审计追踪、模型可移植性、语言栈。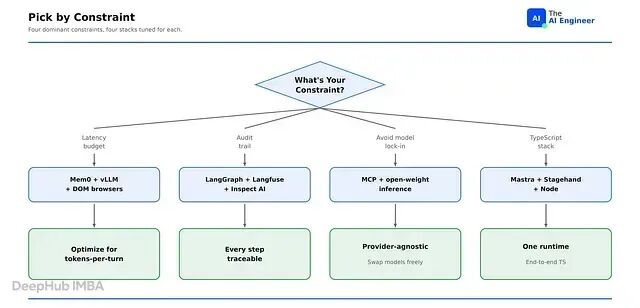
延迟优先的栈倾向于 Mem0 和 vLLM;审计优先的栈倾向于 LangGraph 和 Langfuse;模型可移植性要求远离供应商 SDK;语言栈倾向于 Mastra 或 Pydantic AI。试图用一个生态满足全部四个约束,结果是每一层都选了平均水平的工具,而不是每层最合适的那个。
总结
在替换生产 agent 中的任何一层之前,可以先查这张表。状态列告诉你需要迁移多少。锁定列告诉你切换时会放弃什么。演示到生产列告诉你替换实际需要多长时间。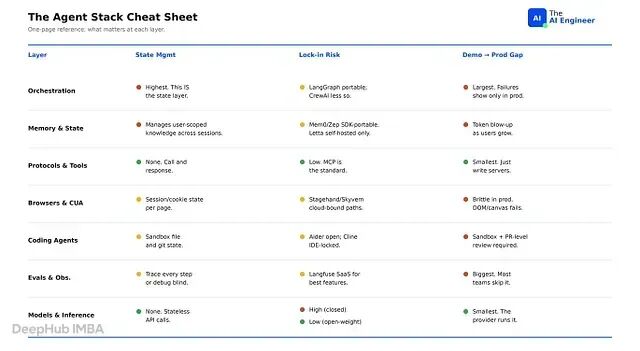
by Paolo Perrone