
现在训练一个 1000 亿参数的 Transformer 模型已经算不上什么新鲜事。GPT-3 有 1750 亿参数,Llama 2 最大版本达 700 亿,许多团队现在随口就把"100B 作为基准"挂在嘴边。但第一次真正上手训练的团队,往往会在一个意想不到的地方撞墙:不是算力,是内存。
几乎所有人都会觉得模型放不进 GPU 内存就买更多 GPU,训练慢就换更快的卡。如果你这样想买再多 H100 也没用,因为要不清楚如何把模型参数、激活值(activations)和优化器状态(optimizer state)的内存占用分散到这些卡上,结果就是网络把算力拖死,以峰值吞吐量的零头跑着任务。100B 参数这个量级模型的核心问题是:哪些组件可以跨设备做切片(shard),哪些可以复制(replicate),哪些因为切片的通信开销比省下来的计算还贵,必须老老实实留在一张卡上。
Meta 在训练其最大规模的开源模型时,投入了大量工程资源处理这个问题。他们的技术博客,谈"扩展(scaling)"时用的语言几乎清一色是内存效率,而不是绝对吞吐量。并行策略的选择——数据并行(data parallelism)、张量并行(tensor parallelism)、流水线并行(pipeline parallelism)还是组合——本质上是在决定对模型的哪个维度做切分,而每种选择都会产生一套通信模式,这套模式如果不契合硬件,就会把整个集群卡死。
内存问题:为什么 100B 参数放不进一张 GPU
从算术说起,一个 100B 参数的 Transformer 模型,仅权重在 float32 下就占约 400 GB 显存。H100 只有 80 GB。换成 bfloat16(训练中的常用格式)也需要 200 GB,显然是不够的。而且这还只是权重,训练过程中还有三类额外的内存消耗:
- 优化器状态——使用 Adam 时,每个参数需要维护一阶矩和二阶矩两个值,内存占用直接翻倍。100B 参数模型在 bfloat16 下,权重 200 GB,优化器状态再占 400 GB,合计 600 GB。仅仅是存储可训练状态,就需要大约 8 张 H100。
- 激活值——前向传播需要把每层的激活值保存下来,供反向传播计算梯度用。对于 100B 参数的 Transformer,根据序列长度和 batch size 的不同,反向传播期间激活值可能再占 200–500 GB。
- 梯度缓冲区——在执行优化器步骤之前,每个参数对应的梯度副本需要临时驻留在内存中。
以合理的 batch size 和序列长度跑一步 100B 模型的训练,总内存需求大约在 800 GB 到 1.2 TB。H100 只有 80 GB,光是所有数据就需要 10–15 张卡。如果单纯用数据并行——每张卡都复制完整模型,处理不同 batch,计算梯度后取平均——那每个副本就得用 15 张卡。如果需要两个副本做容错?那就30 张。要是还要流水线化 batch就要继续加。
Meta 等机构最终得出的洞察是:并不是所有内容都需要在 GPU 之间复制。模型参数可以切片;激活值只在某一设备的前向和反向传播期间存在,可以流水线处理;优化器状态可以独立于参数单独切片。这一切都要以最小化跨网络的数据流量为前提——GPU 内存再多,只要网络比算力慢,就是白搭。
数据并行:最简单的基准方案
理解数据并行为何在 100B 量级失效是进入后续话题的前提。
数据并行中,每张 GPU 保存完整的模型副本,前向传播时各自独立处理不同的 batch,反向传播后各自得到梯度,再通过 all-reduce 操作取平均,最后每张卡独立执行一次优化器步骤。参数量在几十亿以内、模型能放进单卡时,这套流程运行良好。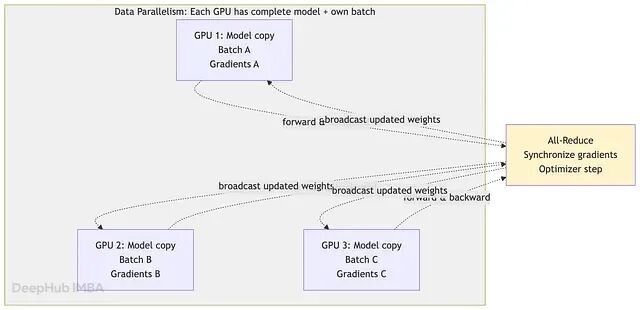
100B 参数下的问题在于,bfloat16 的权重(200 GB)需要复制到每一张卡。16 张卡就意味着 3.2 TB 的模型副本。每次优化器步骤都要同步梯度,对 100B 参数来说,这是 200 GB(bfloat16)数据在集群网络上的一次传输。即便走 NVLink(900 GB/s)这样的高速互联,每步也要约 0.22 秒。如果一次计算本身只需要 300 毫秒,光同步就吃掉了 40% 的周期时间。同步时间不随模型规模线性改善,模型越大越难看——到 500B,这个问题会彻底失控。
数据并行实现简单(PyTorch DDP 开箱即用)所以是起点,但在 100B 量级单独使用,几乎不是正确选择。
张量并行(Tensor Parallelism):跨 GPU 切分权重矩阵
张量并行,也称层内并行(intra-layer parallelism),把每一层的权重矩阵切分到多张 GPU 上,参数本身不再集中在一张卡。
以 Transformer 的多头注意力(multi-head attention)层为例,将输入投影到各注意力头的权重矩阵形状为
[hidden_dim, num_heads * head_dim]
。张量并行沿列方向把这个矩阵切开:GPU 0 持有第 0 到 N/2 列,GPU 1 持有第 N/2 到 N 列。前向传播时每张卡各自计算输出的一部分,再拼接结果;反向传播时梯度以相同方式切分。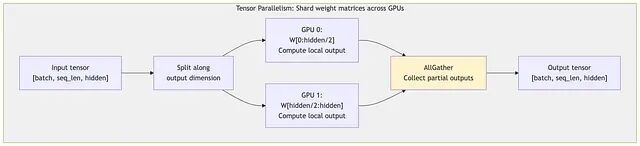
通信开销体现为 all-gather 操作,而非数据并行中的 all-reduce。8 路张量并行下,每张卡只保存 1/8 的参数,不再需要复制完整模型——这是张量并行在 100B 量级优于数据并行的直接原因。但是每经过一个线性层都需要 all-gather 来重新拼装完整输出。若能与下一层的计算重叠进行,这部分开销是非阻塞的;若模型层数不够深,或并行度太高,同步时间就会超过计算时间。
Meta Llama 2 70B 的训练采用了 2 路张量并行(通过 NVLink 桥接),将通信开销控制在合理范围内。100B 以上的前沿实践通常用 4 路或 8 路,不会再高因为超过这个度,通信开销就会占主导。
流水线并行(Pipeline Parallelism):按层切分模型
流水线并行的思路与张量并行截然不同。它不切分参数,而是把模型的层分配到不同 GPU:GPU 0 负责前 N 个 Transformer 块,GPU 1 负责接下来的 N 个,依此类推。前向传播时数据从左向右流经各卡,反向传播时从右向左流回。
100 层的 Transformer 4 路切分,每张卡只处理 25 层,内存大约降低 4 倍,好处是显而易见,但代价同样明显:流水线气泡(pipeline bubbles)。GPU 0 处理完一个 batch 并将结果传给 GPU 1 后,如果 GPU 1 还在处理上一个 batch,GPU 0 只能空等。典型前向传播过程中,任意时刻往往只有一张卡在做有效工作,其余都在等待,GPU 利用率可能低至 25% 甚至更低。
Gpipe 以及 vLLM 的变体通过在流水线中交错多个 batch 来缓解这个问题,但根本矛盾仍在:流水线并行是以延迟换内存,训练时延迟直接等于浪费掉的 GPU 周期和能耗。
实践最优点:张量并行 + 数据并行
大多数 100B 量级的团队最终收敛到同一种混合策略:节点内张量并行,节点间数据并行。
原因在于集群架构本身。节点内 GPU 通过 NVLink 互联,H100 上达 900 GB/s;节点间走集群网络,速度可能只有 400 Gbps 或 800 Gbps,低一到两个数量级。张量并行放在节点内,通信走的是快速通道;数据并行放到节点间,不需要在每层都同步,每个训练步骤只发生一次。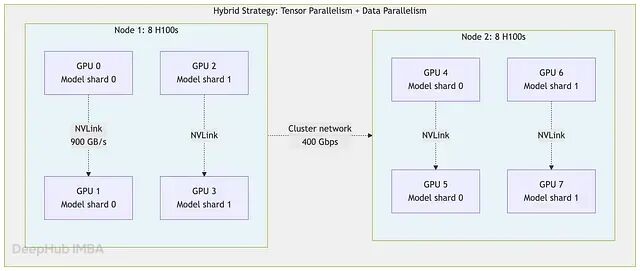
这种组合的效果是:模型参数在每张卡上放得下,张量并行的通信走高速 NVLink,数据并行的同步分散到较慢的集群网络,但每步只做一次。
梯度累积(Gradient Accumulation):不增加内存地模拟大 batch
几乎每次 100B 训练都会用到梯度累积——不在每次前向-反向传播后立即更新,而是跨多个微批次(microbatch)累积梯度再统一执行优化器步骤。
这样做有两个原因:1、有效 batch size:batch size 越大,训练动态越稳定,但单卡内存有限时只能用小 batch;梯度累积允许用四个 128-token 的微批次模拟一个 512-token 的 batch,无需一次性分配 512-token 激活值的完整内存。2、使用流水线并行时,梯度累积能让流水线保持满载,多个微批次流过各阶段后再同步,减少空闲时间。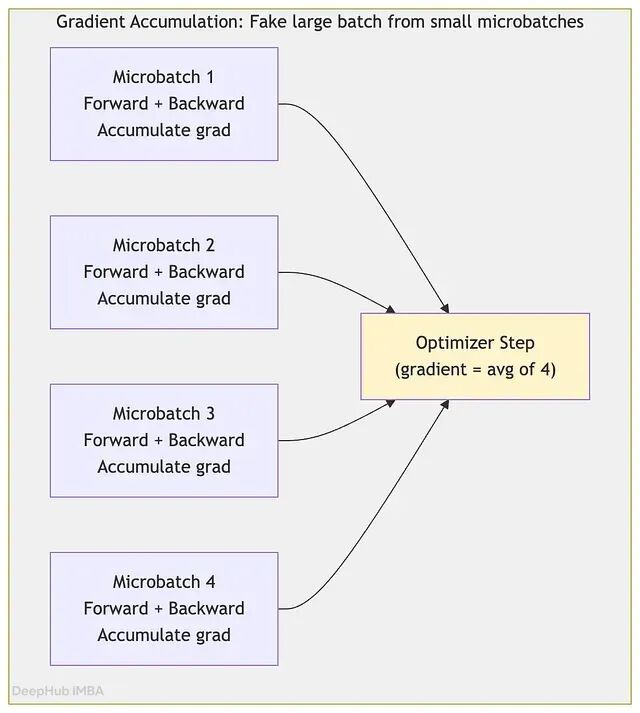
不过会更加耗时,因为每更新一次权重要做四倍的前向-反向传播,每步训练时间更长。但有效 batch size 更大,通常有助于收敛,也允许使用更大的学习率。
如何选择并行策略
训练一个 100B 参数模型之前,可以按以下决策树逐步确认:
- 模型能放进一张 GPU 吗?(100B 量级极少,除非使用 int4 量化。)→ 数据并行。结束。
- 模型能放进一个节点(8 张 GPU)吗?→ 节点内张量并行(如 8 路),节点间数据并行。
- 切分到一个节点仍然太大 → 节点内 4 路张量并行 + 节点间 2 路流水线并行 + 更大范围集群的数据并行。这是 100B 以上的主流方案。
- 模型层数很深且通信延迟低 → 可以考虑加入轻量级流水线并行,但务必仔细测量实际耗时,它往往适得其反。
- 追求最大吞吐量且集群网络带宽充足 → 可以考虑 Megatron 风格的 3D 并行(张量 + 流水线 + 数据),但仅当集群规模足够大、节点间带宽良好(每链路 ≥400 Gbps)时才值得。
张量并行度越高,模型内存越小,节点内同步开销越大;流水线并行度越高,内存进一步降低,气泡也越多;数据并行度越高,每步网络开销越大,但实现成本最低。100B 量级没有唯一最优解,只有最适合当前硬件和模型架构的那个答案。
为什么通信会成为瓶颈
超过某个临界点后,网络速度就慢于算力,再多的 GPU 也改变不了这一点。一次 100B 参数的训练步骤中:
- 计算时间(前向 + 反向):经过良好并行化的 8-GPU 配置上约 300 ms
- 梯度 all-reduce(数据并行同步):典型集群网络上约 200 ms
- 张量并行 all-gather:约 50 ms(NVLink 上,与计算重叠进行)
- 流水线气泡:0–100 ms,取决于策略
各项相加,每步约 500–600 ms,而计算只占其中 50%。把计算速度提升 20%,每步时间只改善 10%,因为网络依然卡在那里。
这正是 Llama 2 70B 训练报告中指出"跨机器通信是主要瓶颈"的原因,也是 Meta 等机构在 ZeRO(零冗余优化器,zero redundancy optimizer)和梯度检查点(gradient checkpointing)上投入大量资源的原因——目的是压缩需要通信或驻留在内存中的状态量。
PyTorch FSDP 与 Megatron
张量并行和流水线并行不需要手动实现,目前有两个主流框架。
PyTorch FSDP(Fully Sharded Data Parallel)是 PyTorch 的原生方案,将优化器状态、梯度和参数切分到各 GPU,侧重内存效率。FSDP 通过自动切分层来达到接近手动张量并行的效果,使用上更简单,但若调优不当,可能引入更多同步开销。
Megatron-LM 是 NVIDIA 专为 100B 以上规模训练构建的框架,实现了显式的张量并行、流水线并行,以及序列并行(sequence parallelism——对序列维度做切分的变体)。Megatron 更复杂,但对并行策略的控制更精细。世界上规模最大的一批模型,大多是在 Megatron 或其变体上训练出来的。
典型的 100B 训练要么用 FSDP 配合选择性激活检查点,要么用 Megatron 风格的张量并行。具体选择通常取决于模型架构能否与框架的假设良好匹配。
总结
如果你读完关于 100B 模型训练的论文,几乎都会得出同一个结论:瓶颈不在于数据移动的速度,而在于内存里能存多少、以及在移动数据的同时能让 GPU 保持多忙。100B 参数模型不只是 1000 亿个等待算力处理的数字,它是 1000 亿个在处理期间必须有地方存放的数字,而"存放的地方"是稀缺资源。
并行策略的选择,决定了这个"存放的地方"的结构。数据并行在各卡间复制这个地方;张量并行把它切片分配到各卡,附带节点内通信;流水线并行让它跨时间和节点展开,以延迟换内存;梯度累积则通过顺序处理更小的片段来模拟一个更大的空间。
每种方案都是一个取舍判断:内存、网络带宽和计算时间,哪个更贵?三者的约束在 100B 量级同时压下来,这正是混合策略成为主流的原因。工程不是要找到某种巧妙方案绕过物理限制,而是接受这些限制,围绕它们做设计。
成功扩展 PyTorch 训练的团队,花力气的方向不是让训练跑得更快,而是让训练不必等待。
by Shriom Tripathi