
写 Python 够久的话,肯定遇到过一个问题clone 一个仓库,pip install -r requirements.txt却特别慢

其实Python 打包生态已经经发了了很大的便哈, 2025 年有三款截然不同的工具。pip 是老兵,Conda 是数据科学家的主力,uv 则是彻底改写规则的挑战者。
pip:Python 的标准
pip最初的主力工具
- pip 自 2011 年起成为 Python 默认包管理器。
- 从 PyPI(Python Package Index) 安装软件包,解析依赖关系,支持
**_requirements.txt_**文件。 - PyPI 是全球最大的 Python 仓库,收录超过 50 万个软件包。某个 README 里写着
**_pip install it_**,指的就是它。
pip 向 PyPI 发起请求,下载 wheel 包或源码包,按顺序解析依赖树,再将软件包装入当前激活的 Python 环境。它使用回溯解析器(pip 20.3 引入)来寻找有效的依赖集合,但对大型项目而言,这个解析过程可能相当耗时。
# 基本用法
pip install numpy pandas torch
# 从 requirements 文件安装
pip install -r requirements.txt
# 保存当前环境
pip freeze > requirements.txt
# 升级软件包
pip install --upgrade openai
# 卸载软件包
pip uninstall package-name
pip 不管理 Python 版本,不自己创建隔离的虚拟环境(需要配合
**_venv_**
或
**_virtualenv_**
使用),也不处理非 Python 的二进制依赖。原生也不生成锁定依赖文件——为此需要
**_pip-tools_**
来生成
**_requirements.lock_**
。
Conda:数据科学家的工具
Conda 由 Anaconda 公司开发,是一个与编程语言无关的包管理和环境管理工具。与 pip 不同,它不局限于 Python 包,还能安装 C 库、CUDA 二进制文件、R 包以及系统级依赖。在数据科学、生物信息学和机器学习(Machine Learning)研究领域,技术栈往往包含针对 MKL、CUDA 驱动或编译型 Fortran 代码 构建的
**_numpy_**
,Conda 因此不可或缺。
Conda 生态已分化出多个发行版:Anaconda 是包含 1500 多个预装科学软件包的完整发行版;Miniconda 是最小安装版,只有 Conda 和 Python;Mamba 是用 C++ 重新实现的版本,专门针对 Conda 最大的弱点——依赖解析速度慢。
# Conda 核心命令
# 创建指定 Python 版本的环境
conda create -n myenv python=3.11
# 激活环境
conda activate myenv
# 从 conda-forge 安装
conda install numpy pandas pytorch
# 从指定 channel 安装
conda install -c conda-forge package
# 导出环境
conda env export > environment.yml
# 从文件重建环境
conda env create -f environment.yml
Conda 使用 channel 作为软件包仓库。默认的 Anaconda channel 属于商业性质,自 2020 年起超过 200 人的组织需要购买许可证。conda-forge 是社区驱动的替代方案,收录了 25000 多个软件包且无许可限制——大多数团队默认选择它。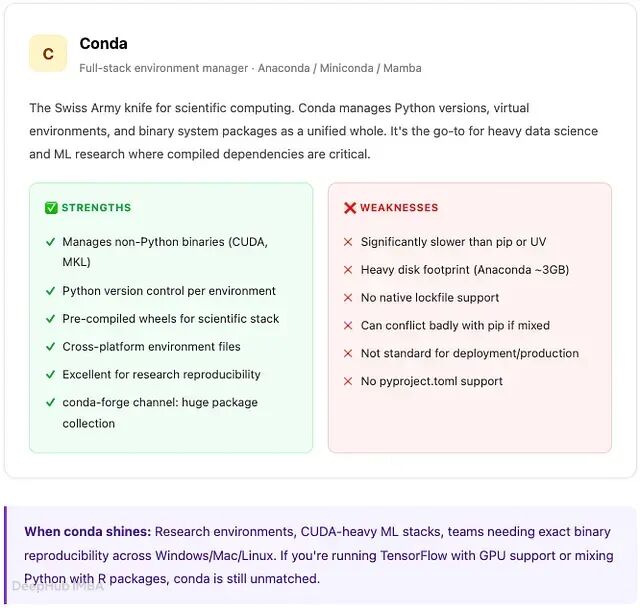
uv:Rust 驱动
uv 由 Astral(
ruff
极速 linter 背后的团队)于 2024 年初发布,到 2026 年已迅速成为新 Python 项目的默认选择。完全用 Rust 编写不只是替代 pip——它用一个统一工具同时替代了 pip、virtualenv、pyenv 和 pip-tools,速度比原来快 10 到 100 倍。
uv 是编译好的 Rust 原生代码,安装时没有 Python 解释器的开销。它使用带硬链接的全局包缓存:同一个包在一个项目中安装后,其他项目直接硬链接而非复制。依赖解析器并行运行,采用移植自 PubGrub 的算法(与 Dart 的 pub 相同)并针对 Python 生态做了深度优化。
# uv 替代整个 Python 工作流
# 安装 Python 本身
uv python install 3.12
# 创建带 pyproject.toml 的项目
uv init my-project
cd my-project
# 添加依赖(自动管理虚拟环境和锁文件)
uv add numpy pandas fastapi
# 从锁文件安装(确定性构建)
uv sync
# 在项目环境中运行
uv run python main.py
uv run pytest
# 管理 Python 版本
uv python install 3.12
uv python pin 3.11
# pip 兼容模式(直接替换)
uv pip install package
uv pip install -r requirements.txt
# 全局安装 CLI 工具
uv tool install ruff
pyproject.toml 优先
uv 全面拥抱 PEP 517/518 和
**_pyproject.toml_**
作为项目标准。运行
**_uv add_**
时,它会自动更新
**_pyproject.toml_**
中的依赖项并重新生成
**_uv.lock_**
文件——一个跨平台、人类可读的锁文件,记录精确的解析依赖图。可重现构建因此变得轻而易举。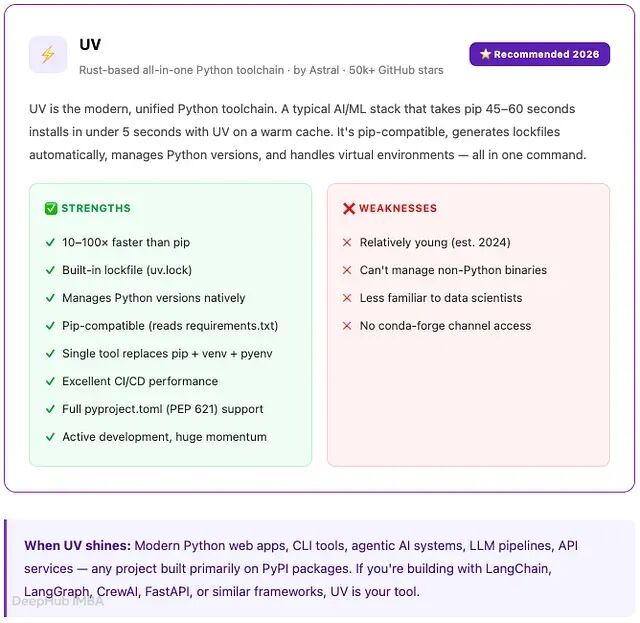
逐项对比
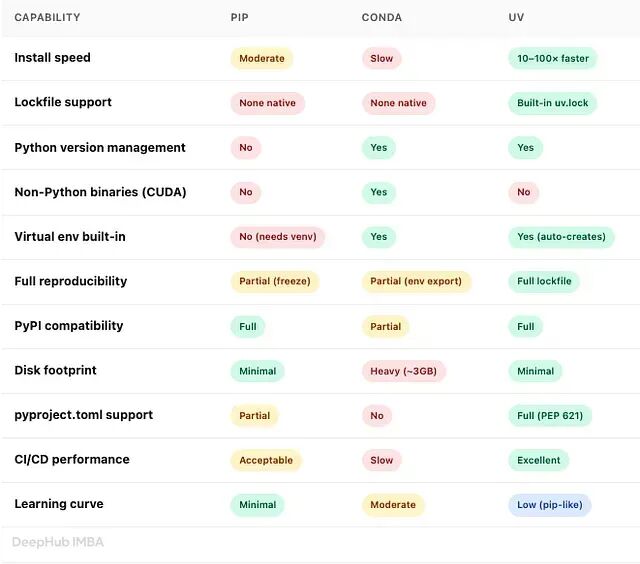
速度基准测试
在包缓存预热的情况下,安装典型的 AI/ML 栈(PyTorch、LangChain、FastAPI、Pandas 以及约 50 个传递依赖):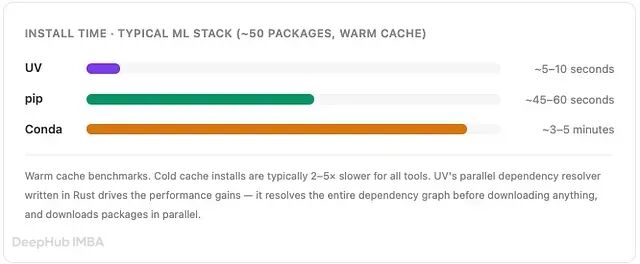
在生产 CI Pipeline 中,这种差异会成倍放大。一条 Pipeline 每天运行 20 次,每次安装耗时 3 分钟,每天就在包管理上白白烧掉 1 小时计算时间。uv 可以将总时间压缩到 5 分钟以内,节省的是真实的金钱和真实的开发者时间。
对于 Agentic AI 工作流——可能需要启动数十个隔离 Python 环境(每个 agent、每个工具、每次实验各一个)——这种速度差距绝非表面文章,而是 CI Pipeline 4 分钟和 40 分钟之间的本质差别。
如何选择

用 LLM 构建应用时——无论是 agent 框架、RAG Pipeline、工具调用系统还是多 agent 编排——面对的都是快速迭代的依赖环境。
openai
、
anthropic
、
langchain
、
llama-index
、
crewai
都在每周发版。能否在不破坏环境的前提下跟上节奏,是真实存在的工程约束。
uv 的内联脚本依赖(PEP 723)对 Agentic 工作流尤其值得关注:
# agent_runner.py — 自包含的 agentic 脚本
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "anthropic>=0.30",
# "httpx>=0.27",
# "pydantic>=2.7",
# ]
# ///
uv run agent_runner.py # 自动创建隔离环境,即刻运行
单个 Python 文件内嵌依赖声明,任何安装了 uv 的人一条命令即可运行——不需要
**_pip install_**
,不需要激活虚拟环境,也不需要读 README 说明。对内部工具、agent 原型和可分享的自动化脚本来说,这是实实在在的体验提升。
对于 AI 工程团队:从 pip 切换到 uv 通常能将 Docker 构建时间缩短 60% 到 80%,加快新成员上手速度,并消除经典的"在我机器上能跑"依赖漂移问题。迁移风险也低——uv 的
pip
子命令几乎可以完全无缝替换。
从 pip 迁移到 uv 比想象中简单
快速迁移指南:pip → uv
最快的路径是先把 uv 当作 pip 的直接替换来用,无需改动任何项目文件:
# 安装软件包
pip install flask uvicorn
uv add flask uvicorn # uv 等价命令(写入 pyproject.toml)
# 从 requirements 文件安装
pip install -r requirements.txt
uv pip install -r requirements.txt # 直接兼容
# 创建并激活环境
python -m venv venv && source venv/bin/activate
uv sync # uv 自动创建 .venv 并从锁文件安装
# 运行脚本
python script.py
uv run python script.py # 使用项目的托管环境

总结:该用哪个?

以下细分建议:
保留 Conda 的场景:确实需要它时——GPU/CUDA 库管理、包含非 Python 依赖的生物信息学或科学计算,或团队深度绑定 Anaconda 生态。如果留在 Conda 体系内Mamba 可以显著提升解析速度。
pip 随 Python 一起发布,对于快速临时脚本,或无法安装额外工具的环境,它依然完全够用。但对于任何在意可维护性和可重现性的项目,请选择 uv。
作者:Uday Sharma