
做过地质统计学、储层建模或空间机器学习的人,大概都面对过这个选择:Kriging(经典地质统计学的主力工具),还是高斯过程回归(Gaussian Process Regression,GPR,其机器学习更加接近)。两者在数学上是相通的——都是基于协方差/核函数构建的"最佳线性无偏预测器"——但实际使用起来像是两个完全不同的世界。Kriging 快、可解释、有几十年积累;GPR 慢、更灵活、有 sklearn 的精良封装。
本文将在 SPE9 数据集上跑了一套正面对比,覆盖多种 Kriging 变体、GPR 以及几个 ML 基线,还包括用 5 折和 20 折交叉验证重复了一遍,看稳定性。
结果出乎意料。期间还碰到一个让不少人(包括我自己)困惑的问题:R² 名字里有"平方",怎么会出现负数?这个问题值得认真讲,因为搞清楚它之前,上面那些数字都没法正确解读。
数据集:SPE9
SPE9 是经典的 Benchmark——一个合成但具有现实意义的 3D 渗透率网格,几十年来用于测试模拟器和建模工作流。本次实验将其视为空间插值问题:
- 输入:储层网格内归一化的 (x, y, z) 坐标
- 目标:该位置的渗透率
- 任务:给定一批已知点,预测未知位置的渗透率
从网格中采样 1,500 个点,分别用于单次划分(1,200/300 训练/测试)、5 折交叉验证(每折 1,200/300)和 20 折交叉验证(每折 1,425/75)。
对比模型如下
普通 Kriging(Ordinary Kriging,OK)
Kriging 将未采样位置的值预测为附近已知值的加权平均,权重来自变差函数(variogram)——描述两点之间相似度随距离变化规律的函数。变差函数拟合一次,之后对每个预测点用
k
个最近邻解一个小型线性方程组。
测试了两种配置:自动选择变差函数模型(球形/指数/高斯/线性,通过交叉验证拟合选优)和固定球形模型。
泛 Kriging(Universal Kriging)
思路与普通 Kriging 相同,但额外在残差之上拟合一个多项式"漂移"(drift)项——线性或二次。漂移项负责捕捉大尺度趋势,变差函数则只需解释局部小尺度变异。
嵌套变差函数 Kriging(Nested Variogram Kriging)
这是最有意思的变体,也是专门为本次研究实现的。标准变差函数只有一套 nugget/sill/range,只能描述单一尺度的空间结构;而真实空间场往往同时存在多个尺度的变异:短程局部噪声,加上大范围缓变的区域趋势。
嵌套变差函数把两个(或多个)协方差结构叠加在一起:
gamma(h) = nugget + ps1 * structure_1(h, range_1) + ps2 * structure_2(h, range_2)
这与高斯过程中叠加两个核函数的做法直接类似,例如
RBF(short_length_scale) + RBF(long_length_scale)
。用 Rust 实现,采用广义 N 参数 Levenberg-Marquardt 拟合器,接入局部 Kriging 引擎,测试了球形+高斯和球形+球形两种组合。
高斯过程回归(GPR)
sklearn 的
GaussianProcessRegressor
。底层数学与 Kriging 相同,区别在于:核函数超参数通过最大化边际似然(marginal likelihood)来优化,而非拟合经验变差函数;复杂度是训练点数量的 O(N³)——没有最近邻这类快捷方式。
随机森林(及"回归 Kriging"混合版)
作为非空间基线,加入了一个普通的
RandomForestRegressor
,直接以 (x, y, z) 为输入训练渗透率预测。还尝试了回归 Kriging(Regression Kriging)混合方案:先用 ML 模型拟合大尺度趋势,再对残差做 Kriging,试图捕捉剩余的空间结构。
第一轮:单次 1,200/300 划分
先做最简单的对比——在 1,200 个点上训练,对 300 个留出点评估,只跑一次。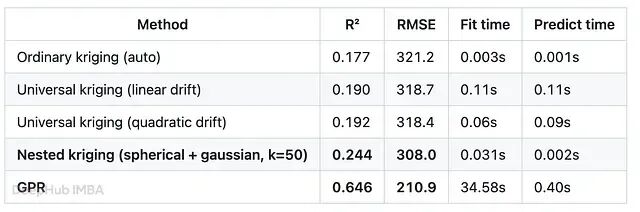
- GPR 以大幅优势胜出——R² 0.646,Kriging 各变体为 0.18–0.24。
- GPR 的拟合速度慢约 1,000 倍,预测速度慢约 200 倍。
- 嵌套变差函数将与 GPR 的差距缩小了约三分之一(0.177 → 0.244),计算代价几乎为零。
- 泛 Kriging 的多项式漂移几乎没有帮助(0.177 → 0.19),计算开销却比普通 Kriging 高 30–100 倍。
为什么 GPR 在这里赢得这么彻底?
看一下 GPR 实际拟合出的核函数:
0.96² · RBF([0.294, 2.91e-05, 0.0183])
+ 0.072² · Matern([4.47e-05, 3.08e+04, 4.53e+04], nu=1.5)
+ WhiteKernel(0.0293)
关键在 Matérn 项:它在 y 和 z 维度的长度尺度极大(约 30,000–45,000),在大多数域范围内等效于一个近线性的大尺度趋势。GPR 的优化器发现了渗透率场的结构:x 方向存在短程局部变异,叠加了一个大范围、平滑、近乎线性的区域模式——于是自动组合出 RBF(局部结构)加近线性 Matérn 项(区域趋势)的核函数。
嵌套变差函数试图表达的正是同一回事——短程结构加长程结构。效果不如 GPR,原因有两点:一是嵌套拟合中第二个结构只支持有界协方差形状(球形、指数、高斯),无法像长度尺度极大的 Matérn 项那样干净地表达无界的近线性趋势;二是 GPR 的超参数通过最大化边际似然做全局联合优化,而变差函数先独立拟合经验曲线再用于预测,两步解耦精度自然有损。
如果进行修正:按各轴变差函数范围对坐标重缩放,以校正几何各向异性(该场在 x、y、z 三个方向的相关长度差异很大)。结果反而更差(R² 降至 -0.03 到 0.07)——某一轴上估计的范围极小(约 0.005),把距离放大到如此程度,几乎所有点对在重缩放空间中都变得"无限远",彻底破坏了 Kriging 依赖的空间相关性。"更复杂"不等于"更好",所以各向异性校正需要比逐轴重缩放谨慎得多的处理。
第二轮:交叉验证下结论还成立吗?
单次 80/20 划分只反映数据的一个切面。在同一 1,500 个点的数据池上,跑了 5 折交叉验证(每折 1,200 训练 / 300 测试)和 20 折交叉验证(每折 1,425 训练 / 75 测试)。
5 折结果(5 折均值 ± 标准差)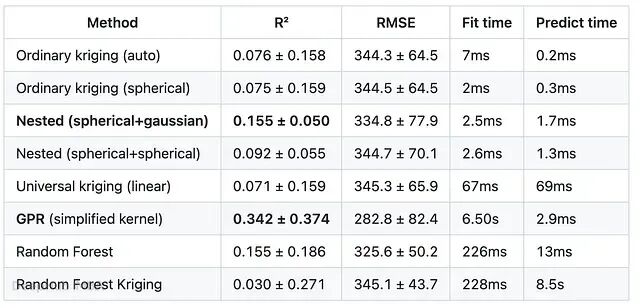
交叉验证中使用的 GPR 核函数较简单(ARD RBF + 白噪声,重启两次),而非第一轮中完全优化的核函数——平均 R²(0.342)低于单次划分的 0.646。单次划分碰巧是对 GPR 特别有利的一次。
两个问题:
- GPR 自身的精度也不稳定——标准差 0.374 极大。第 3 折的 R² 实际为负(-0.351),第 4 折又高达 0.694。同一模型、同样的超参数搜索,仅因留出的 300 个点不同,结果便天差地别。
- 嵌套变差函数是所有纯空间方法中最稳定的——标准差(0.050)在所有方法(包括 GPR)中最低,从未跌入负 R²;而普通 Kriging 和泛 Kriging 在第 3 折时都出现了约 -0.20 的负值。
20 折结果(20 折均值 ± 标准差,每折 75 个测试点)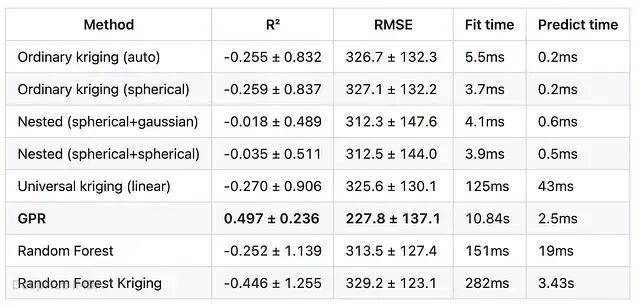
测试集缩小到每折 75 个点后,情况更加清晰:除 GPR 外,所有方法的平均 R² 均为负,即在 20 个不同留出集上平均下来,这些方法还不如直接在每处预测平均渗透率。GPR 是唯一稳定超越均值预测基线的方法,平均 R²(0.497)最高,方差(0.236)也最低。嵌套变差函数再次是纯空间方法中"最不差"的,均值最接近零(-0.018、-0.035),标准差约 0.49,而普通 Kriging 为 0.83–0.91。随机森林和随机森林 Kriging 则成了最差的选手——单次灾难性折叠(R² 分别为 -4.55 和 -4.92)将平均值拖入深度负区间。
R² 怎么会是负数?
"R 的平方"这个名字让人自然地以为它是某个量的平方,平方不可能是负数。但实际计算的公式是:
R² = 1 - (SS_res / SS_tot)
其中:
SS_res = Σ(y_true - y_pred)²——模型的总平方误差SS_tot = Σ(y_true - ȳ)²——最笨基线(对每个点都预测y_true均值)的总平方误差
两个求和项都非负,但它们的比值没有上界约束。模型预测比猜均值还差时,
SS_res > SS_tot
,比值超过 1,
1 - 比值
就成了负数。
"相关系数的平方"并不是凭空而来,需要一个前提:带截距的普通最小二乘线性回归,在训练数据上评估。这种情况下拟合直线被保证至少不比均值差——"零斜率、截距=均值"本身就是 OLS 优化器考虑过的合法候选,它只会选更好或相等的结果。这个保证把 R² 锁定在 [0, 1] 内,而它恰恰不适用于留出测试集,也不适用于 Kriging 和 GPR 这类空间/非线性模型。
测试集上出现负 R² 不是 Bug,也不是指标失灵——而是指标在正确地告诉你:模型对空间结构的过拟合或误设定已经严重到"什么都不预测"反而更好的程度。在 20 折结果里,除 GPR 之外的所有方法平均如此。这是一个真实、有据可查的发现,只是结果很差罢了。
选 Kriging 还是 GPR?
答案和数据科学里大多数问题一样,取决于样本量和时间预算——但可以说得更具体些。
选 GPR 的场景:
- 数据量只有几千个点或更少(O(N³) 的复杂度决定了它无法扩展)
- 精度优先于延迟
- 能接受超参数搜索的时间成本(本 Benchmark 中每次拟合需要几十秒;N=4,000 训练点时,GPR 拟合 11 分钟没有跑完)
- 希望通过核函数组合自动发现多尺度结构
选(嵌套)Kriging 的场景:
- 需要对 50K–1M+ 个点打分(GPR 根本做不到)
- 需要毫秒级预测
- 能接受精度上的明显折损,但想要折损范围内最稳定的那个版本
- 已有领域知识表明存在多空间尺度(局部非均质性 + 区域趋势)——嵌套变差函数能以极低代价捕捉 GPR 核组合捕捉到的部分信息
所以,在大网格主体上用 Kriging(尤其是嵌套版),在感兴趣的小区域或验证/校准场景中保留 GPR,让更高的精度在值得的地方发挥作用。
总结
Kriging 看起来是用约 0.47 个 R² 单位换取了 1,000 倍的加速。20 折交叉验证下,每种 Kriging 变体(以及随机森林和随机森林 Kriging)的平均 R² 均为负——平均下来还不如一条水平线。只有 GPR 稳定地超越了这条基线。
嵌套变差函数通过叠加两个协方差结构来模拟 GPR 的核组合,没有补上这个差距,但让失败变得不那么严重、不那么随机。这是真实、有用的改进,只是不是当初期望的那种。
如果只带走一条结论:永远做交叉验证,永远把 R² 与均值预测基线对照。单次训练/测试划分可能让一个既快又脆弱的模型看起来像是白捡来的午餐。
作者:Kyle Jones