
检测 Prompt 注入和越狱攻击的方法,大多建立在系统可以访问对话日志这个前提上。但是如果设计一个系统,每段对话只处理一次以提取特征,不保留原始文本可以吗?:
如果只保留遥测数据(关于会话行为的数值信号)实际上能保留多少检测能力?
本文就是做一个受约束的实验,用于测试这种架构边界是否可行。
系统概述
原始对话文本只处理一次,然后永久丢弃。
每次交互经过一个特征提取步骤,计算 Token 计数、重试模式和若干语义指标等信号,随后文本即被销毁。不存储任何日志,下游的组件无法触及原始内容。
系统结构如下: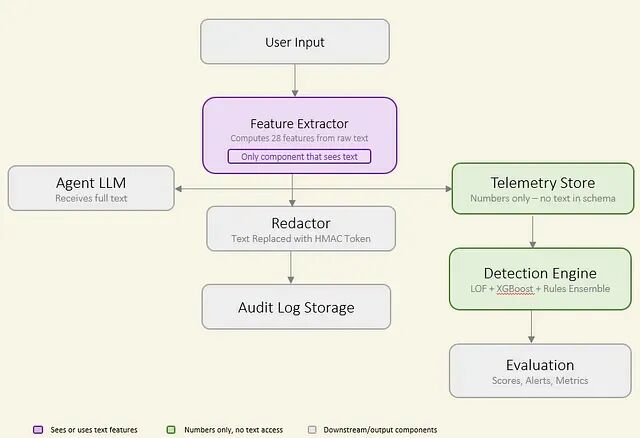
流水线分为四个部分:特征提取器是唯一能接触原始文本的组件;脱敏步骤在处理完成后立即删除文本;遥测存储仅保存数值特征;检测引擎纯粹基于遥测运行。特征提取器之后的所有环节都只与存储在会话级别的数值打交道。
整个实验的核心就在这个边界上,一旦特征计算完成,系统不会保留任何的对话内容
具体而言特征被分为几个类别: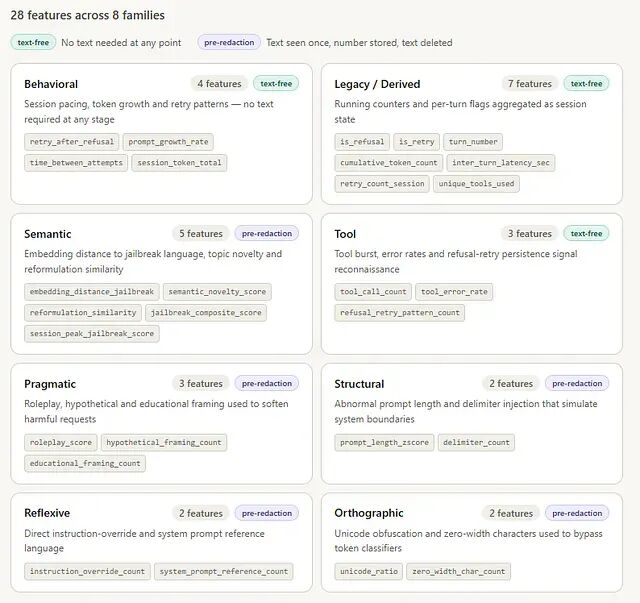
28 个特征中 11 个完全不依赖文本,从会话结构直接计算得出,任何阶段都无需访问文本内容。其余 17 个在脱敏前提取——文本仅被读取一次,存储一个数值,之后永久删除。
总特征数 = 28
不依赖文本的特征 = 11
脱敏前提取的特征 = 17
语义类别中有两个复合特征需要单独说明。
jailbreak_composite_score
结合了 embedding distance、roleplay score、instruction override count 和 system prompt reference count,用于捕获单个特征无法覆盖的共现模式。
session_peak_jailbreak_score
是实验中期分析遗漏的越狱会话后补充的——它在会话所有轮次中保留最大越狱相似度,而非取平均值。
实验设置
为测试上述思路,通过 Groq API(Llama-3.1-8b-instant)生成了跨越八个场景的多轮会话。
攻击类别共 5 种:通过角色扮演的越狱、Prompt 注入、上下文填充、重试-拒绝循环、异常工具调用链。正常类别 3 种:标准问答、正常工具使用、长但无害的会话。
两种数据集规模,实验分两个阶段进行:
关于合成数据需要说明:真实标签在此仅用于受控基准测试,并非表示标签在生产环境中可免费获取。实际部署从无监督的 LOF 和规则层起步,通过人工审核积累高置信度标记,再用确认的标签在后续周期训练 XGBoost。本实验衡量的是收集到足够标签之后系统的表现。
评估在会话级别进行,以避免轮次间的信息泄露。同一会话中的轮次存在相关性,因为轮次级别的划分会将会话上下文泄露到评估集中,导致指标虚高。
系统性能
最终运行 R8 在 27 个特征的 R1 基准上增加了
session_peak_jailbreak_score
。R1 作为一个参考,侧重于更低的误报率;R8 是包含越狱修复的最终配置。
系统始终在"不存储对话日志"的约束下运行,但特征计算方式上仍有一个关键区分。
部分特征完全不依赖文本,比如说会话结构、重试模式、Token 增长均属此类。另一部分在文本丢弃前从中提取,捕获与越狱模式的相似度等语义信息。
由此引出更深入的问题:移除全部文本派生信号、仅靠纯遥测数据,结果会怎样?
为此比较了两种配置。第一种使用完整特征集(28 个),包含不依赖文本的特征与脱敏前的语义信号;第二种仅保留 11 个不依赖文本的特征,令系统在任何阶段都对文本完全"盲"。
5 折交叉验证下,差异出乎意料地小:
F1 从 0.982 降至 0.968,对应约 1.4 个点的回落。
完全不依赖文本的系统保留了完整模型约 98.5% 的检测性能。
移除所有文本派生信号的代价是约 1.4 个 F1 点——这就是完全文本盲系统的可衡量成本。
损失是实在的。语义信号对越狱等细微攻击模式仍有可衡量的优势。但更耐人寻味的是保留了多少信号:重试循环、Token 积累和会话结构等行为模式,承载了绝大部分检测能力。
换言之,权衡发生在稍高一点的检测精度和完全脱离用户文本之间,而非"全有"与"全无"之间。
自然的后续问题是:信号究竟从哪来?所以可以拆解模型,对不同特征组做了独立评估。
以下实验评估的是完整特征集(含脱敏前语义信号),而非严格的纯文本无关变体。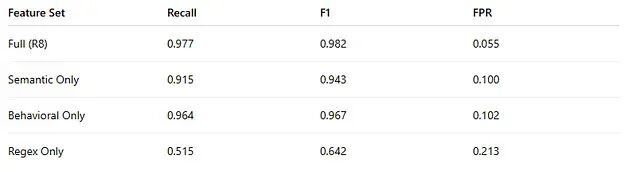
行为信号单独使用便已非常接近完整模型的表现;语义信号同样携带较强信号,但独立使用尚不充分;基于正则表达式的方法泛化能力不足,一如预期。
所以关键不在于某个类别胜出,而在于行为信号与语义信号缺一不可。
检测不仅来自用户说了什么,还来自交互如何演变。
重试模式、Token 增长和会话结构,最终被证明与已知攻击模式的语义相似度具有同等的信息量。
误报率挑战
整体准确率在多次迭代中变化不大,真正改变的是误报率。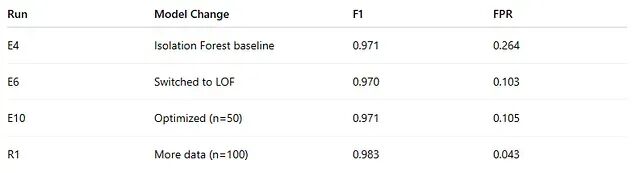
从 Isolation Forest 切换到 LOF 后误报率明显回落,扩大数据集规模又进一步将其压低。
系统的攻击检测能力并未出现质的提升——真正的进步在于对正常会话的误判越来越少。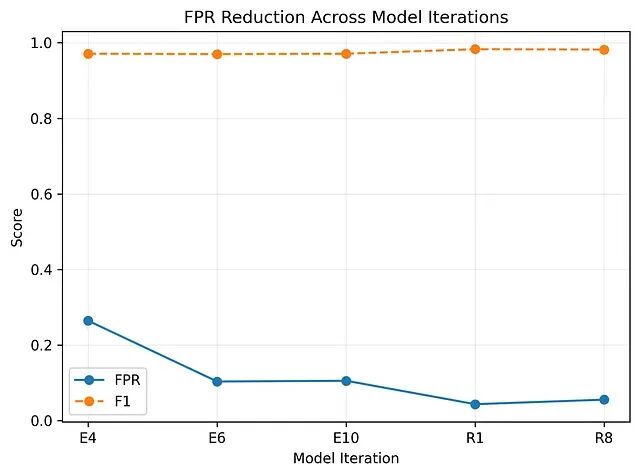
表面上指标好看与实际可用之间的差距,就在这里。
修复越狱检测
越狱检测是一个始终顽固的问题。
多次运行中召回率停滞在 0.75 附近。分析遗漏的案例后,一个规律浮现:早期轮次看起来正常,越狱信号只在会话后期才出现。
问题不在模型本身,在于信号的聚合方式。
最初的做法是对整个会话取信号均值,这把攻击实际出现的后期轮次的影响稀释掉了。修复思路很直接:
跟踪会话所有轮次中的最大越狱信号,而非取均值。
session_peak_jailbreak_score
由此而来。
仅这一个改动就拉高了召回率,同时让系统能在交互更早期阶段识别攻击。
真正驱动检测的因素
特征重要性的分布让模式更加清晰: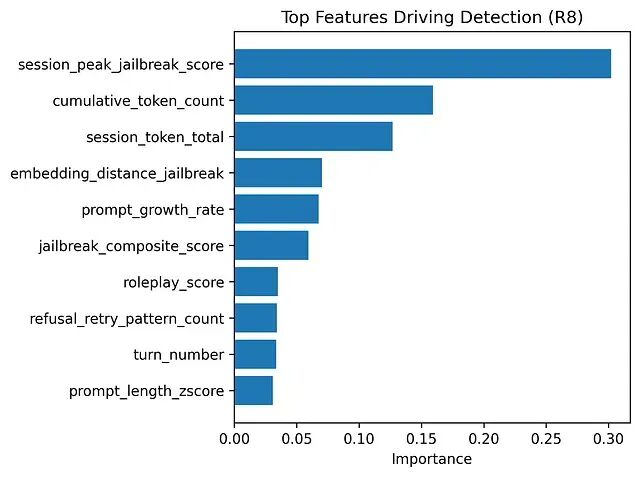
少数几个信号占据主导:峰值越狱相似度、累积 Token 使用量、Prompt 增长模式、重试相关特征。其余特征的贡献是增量式的,检测能力的大头来自这几个核心指标。
总结
本实验最直接的结论:
不需要存储对话就能检测到许多类别的攻击。
遥测数据中保留了大量信号,尤其是重试循环、升级攻击等交互驱动型模式。
但是代价同样存在,检查对话、调试个别案例、详细解释决策的能力都会丧失。整套方案还依赖一个假设:攻击者的行为与正常用户不同;而这个假设并非总是成立。
虽然做不到完美,也不是在所有场景下都行得通。但在严格约束条件下,它是一个可行的设计选择。
这个实验说明了对原始文本的依赖程度可能被高估了,而行为中蕴含的信号量被低估了。
by Siddhi Sri