

如果你住在一栋楼的10层,你会选择走楼梯还是乘电梯。
这两种选择的目的都是一样的:在漫长的一天工作之后,你想回到你的公寓。
当然,如果你是一个忙碌的人,没有时间去健身房,把楼梯当作是有氧运动的简易版,那么走楼梯会更好。但是除此之外,你更可能选择乘电梯。
我们再举一个例子:
假如你要去上班,当没有交通堵塞的时候,开车需要十分钟,走路需要五十分钟。
你可以选择开车或者步行。虽然最终到达同一个目的地,但是你想要节省时间。你每天都去上班而不是一辈子只去一次。因此,你可能需要定期做出决定。
你想要更快地去上班,这样你就有很多的时间和家人朋友待在一起,开始你的副业,读一下你在当地书店买的那本书,观看一下你一直想看的课程。
你不想花那么多时间去同一个目的地,你想驾车或乘公交车帮你到达那里。这样,你就有更多的时间去做其他事。
使用对数的好处的例子
使用对数也是一样的:你需要找到使损失函数最小的参数,这是你在机器学习中试图解决的主要问题之一。
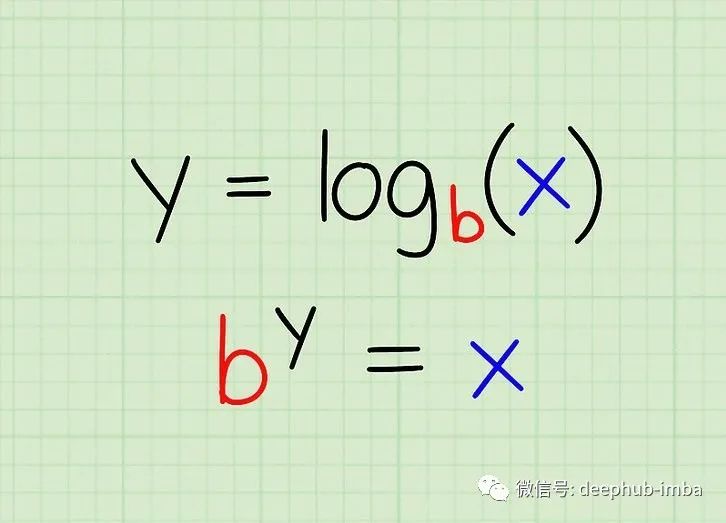
假设你的函数如下:
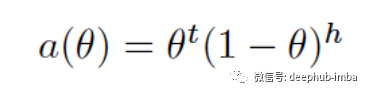
如果我们求出了他的一阶导数,我们最终会得到如下表达式:
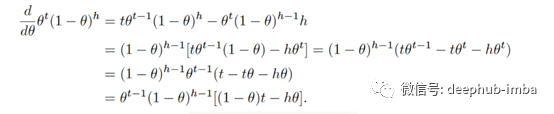
有时,我们甚至需要求出它的二阶导数来判断这个函数是否是凸函数。当一个函数是凸函数时,我们知道它只有一个最小值,所以每一个局部最小值实际上就是全局最小值。
在我们的表达式中,我们会有以下的内容:
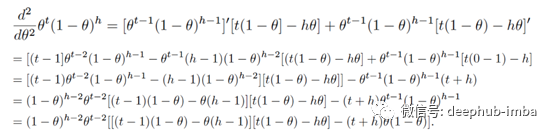
正如你看到的,它很混乱,对吧?
此外,也很乏味
同一函数的对数函数的一阶导数要简单得多:
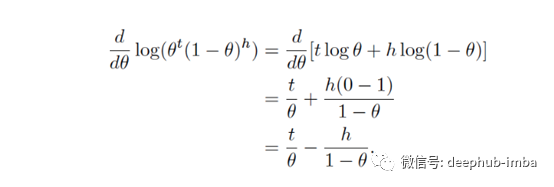
二阶导数也很简单:

当你实际使用对数时,你会得到一个不同的函数。
你走路和开车时不需要走相同的路线。你有与行人使用的车道分开的汽车车道。但你其实并不在乎这么多。
这并不是说你太关心那些在路边开着的商店。你已经在家里吃了一顿简单的快餐,想直接去上班,这意味着这些都不重要。
你想要最小化某些参数的损失函数。你需要最小化损失函数的参数。这正是一个函数和该函数的对数函数共同之处:相同的参数可以最小化损失函数。
对这个函数和它对数函数同时求导就得到损失函数的最小值。
一个数学证明
我们来证明一个使函数最小化的参数等于这个函数的对数函数的最小化的参数。
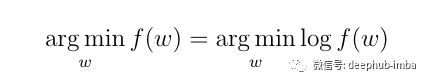
假设w是g(w) = log f(w)的局部最小值点,这意味着w附近的点都满足g(w*)≤ g(w),现在由于 e(通常也表示为exp)具有单调性,则有:

换句话说,w*是函数f的最小值点,这也是我们要证明的。
这意味着我们将对数应用于任何函数时,我们会保留最小值或最大值点(使函数最大化或最小化的参数,而不是函数的实际值)
正如我们在上面的例子所看到的,这样可以简化计算并提高稳定性。
如果你理解起来有困难,让我们用一些图来说明。
我们取以下函数:
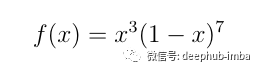
它的部分图像如下:
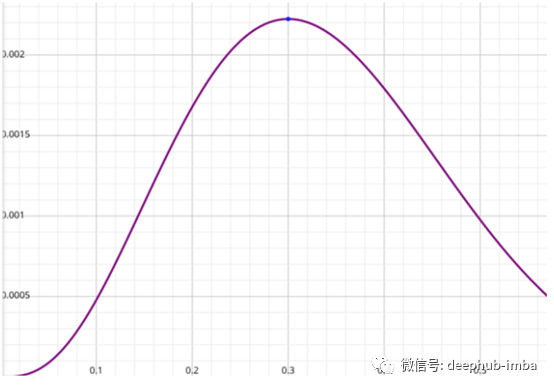
它的对数函数是:
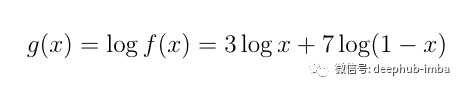
部分图像如下:
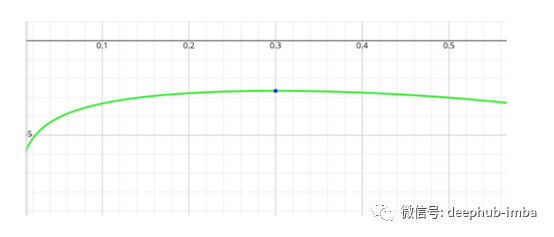
可以看到,在这两种情况下,函数的最大值都是当x=0.3时取得。
是的,我们没有得到相同的函数,但是我们仍然有相同的临界点来帮助我们最小化损失函数。
一句话总结:一个函数和该函数的对数函数有一个共同之处,就是最小化的参数是相同的,对数求导要简单很多,会加快我们的计算速度。
deephub翻译组:gkkkkkk
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********