
1.全方位上下文理解:与以前的模型(例如GPT)相比,BERT能够双向理解上下文,即同时考虑一个词 的左边和右边的上下文。这种全方位的上下文理解使得BERT能够更好地理解语言,特别是在理解词义、 消歧等复杂任务上有明显优势。
2.预训练+微调(Pre-training + Fine-tuning)的策略:BERT模型先在大规模无标签文本数据上进行预 训练,学习语言的一般性模式,然后在具体任务的标签数据上进行微调。这种策略让BERT能够在少量标 签数据上取得很好的效果,大大提高了在各种NLP任务上的表现。
3.跨任务泛化能力:BERT通过微调可以应用到多种NLP任务中,包括但不限于文本分类、命名实体识 别、问答系统、情感分析等。它的出现极大地简化了复杂的NLP任务,使得只需一种模型就能处理多种 任务。
4.多语言支持:BERT提供了多语言版本(Multilingual BERT),可以支持多种语言,包括但不限于英 语、中文、德语、法语等,使得NLP任务能够覆盖更广的语言和区域。
5.性能优异:自BERT模型提出以来,它在多项NLP基准测试中取得了优异的成绩,甚至超过了人类的表 现。它的出现标志着NLP领域进入了预训练模型的新时代。
6.开源和可接入性:BERT模型和预训练权重由Google公开发布,让更多的研究者和开发者可以利用 BERT模型进行相关研究和应用开发,推动了整个NLP领域的发展。
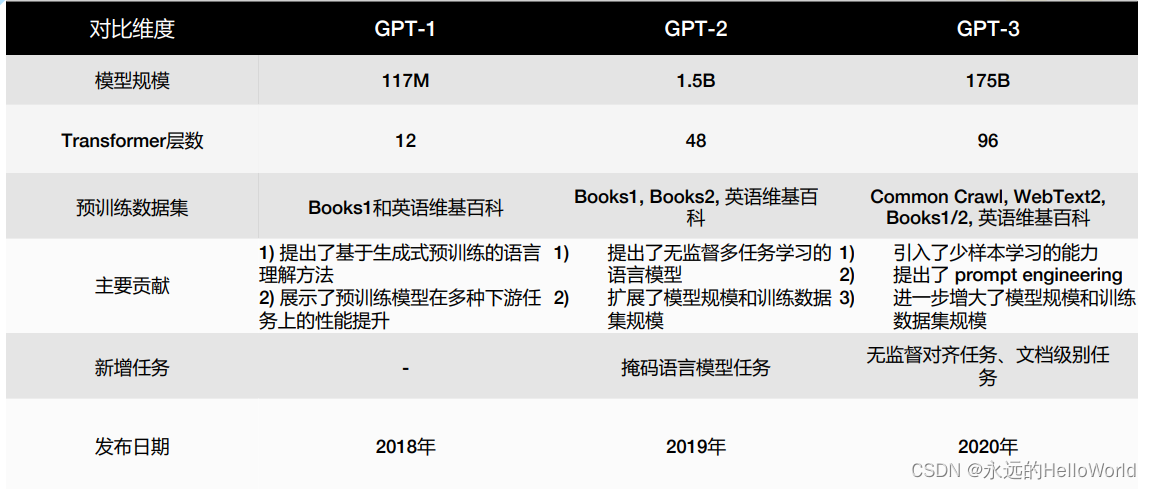
Bert与 GPT的对比

Bert与 GPT的相似处

本文转载自: https://blog.csdn.net/weixin_43882788/article/details/135730833
版权归原作者 永远的HelloWorld 所有, 如有侵权,请联系我们删除。
版权归原作者 永远的HelloWorld 所有, 如有侵权,请联系我们删除。