
这是7月份的一篇论文,Qwen团队提出的群组序列策略优化算法及其在大规模语言模型强化学习训练中的技术突破
大规模强化学习的稳定性挑战
强化学习(Reinforcement Learning, RL)已成为构建先进大语言模型(Large Language Models, LLMs)的核心技术环节。通过人类反馈强化学习(RLHF)和AI反馈强化学习(RLAIF)等方法,模型获得了执行复杂指令、进行多步推理以及与人类偏好对齐的能力。
然而大规模强化学习面临的核心挑战在于训练稳定性。在实际训练过程中,模型经常出现突发性性能退化,表现为能力丢失和输出质量严重下降,这种现象被称为"模型崩溃"。此类不稳定性不仅造成大量计算资源浪费,更严重阻碍了技术发展进程。
Qwen团队在其最新研究中提出了群组序列策略优化(Group Sequence Policy Optimization, GSPO)算法,该算法针对性地解决了上述稳定性问题。为深入理解GSPO的技术价值,本文将首先分析其前身算法群组相对策略优化(Group Relative Policy Optimization, GRPO)的设计理念与内在缺陷,进而阐述GSPO如何通过算法改进实现更稳健的训练过程。
GRPO算法:超越PPO的技术创新
在GSPO出现之前,大语言模型的强化学习训练主要依赖近端策略优化(Proximal Policy Optimization, PPO)算法,该算法在InstructGPT的训练中得到了广泛应用。PPO的训练框架涉及四个关键组件:策略模型作为主要的训练目标,参考模型作为原始模型的冻结副本以约束策略偏移,奖励模型基于人类或AI偏好对模型输出进行评分,以及价值模型用于预测未来奖励但计算成本高昂。
群组相对策略优化(GRPO)的核心创新在于消除了对计算密集型价值模型的依赖。该算法采用了一种创新的群组生成和相对评估机制:对于给定的输入提示,系统生成G个不同的响应构成一个群组,随后奖励模型对群组内所有响应进行评分。通过计算群组内分数的均值和标准差,算法为每个响应计算相对优势值(Â_i)。优于群组平均水平的响应获得正向优势,反之则获得负向优势。
这种设计显著降低了强化学习训练的内存占用和计算复杂度,使大规模模型的训练变得更加高效和可行,代表了该领域的重要技术进步。
GRPO在大规模应用中的局限性
尽管GRPO在概念层面表现出色,但其底层实现存在一个关键的设计缺陷,该缺陷在大规模模型训练中会导致严重的稳定性问题。
问题的根源在于奖励分配与优化更新之间的粒度不匹配:奖励值(Â_i)是基于完整序列计算得出的,而GRPO的优化更新却在令牌(token)级别执行。为了将序列级奖励应用于每个令牌,GRPO引入了令牌级重要性权重w_i,t(θ),该参数在目标函数中起到关键作用。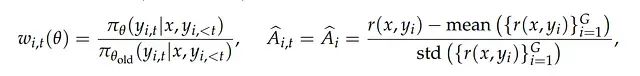
权重w_i,t(θ)表示新策略相对于旧策略生成特定令牌y_i,t的概率比值,每个令牌的梯度更新通过w_i,t(θ) * Â_i进行调整。
此处的不稳定性源于同一序列内不同令牌之间权重值的剧烈波动。在获得单一序列级评分Â_i的情况下,序列内各令牌的重要性权重w_i,t可能出现显著差异,导致学习信号的噪声化和不一致性。随着训练序列长度的增加,这种噪声效应累积并可能触发整个训练过程的失稳,最终导致模型崩溃。该问题在稀疏专家混合(Mixture-of-Experts, MoE)模型中尤为严重,因为这类模型的令牌概率在更新过程中变化更为剧烈。
GSPO算法:实现优化粒度与奖励粒度的统一
群组序列策略优化(GSPO)基于一个核心设计原则解决了上述问题:优化单位应当与奖励单位保持一致。
鉴于奖励是在序列层面给出的,GSPO将重要性采样校正也调整到序列层面执行。算法使用稳定的序列级重要性比率s_i(θ)替代了噪声较大的令牌级权重。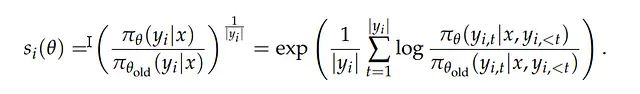
序列级重要性比率s_i(θ)衡量新策略相对于旧策略生成完整序列y_i的概率比值。算法设计的关键在于引入了长度标准化机制(指数项中的1/|y_i|),确保重要性比率在数值上保持稳定,无论序列长度为10个令牌还是1000个令牌。
这种设计产生了一个清晰且稳健的更新规则:给定序列内的所有令牌接收完全一致的更新权重,该权重由s_i(θ) * Â_i确定。令牌级别的不一致反馈被消除,取而代之的是基于完整序列奖励的统一更新机制。
算法优越性的量化证据
GSPO论文通过多维度实验验证了算法的技术优势。
训练稳定性和性能对比实验(图1)表明,在相同计算资源配置下,GSPO相比GRPO展现出更优的训练稳定性和基准测试性能。训练曲线清晰地反映了GSPO的优势。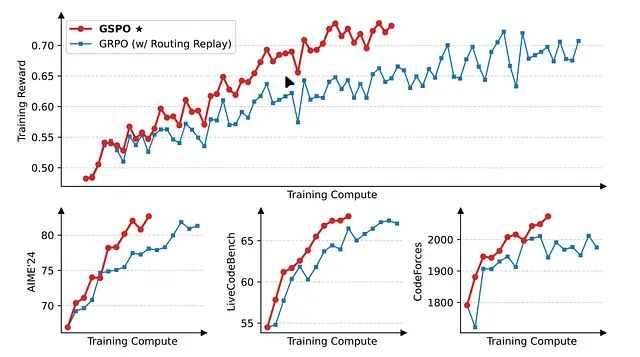
令牌裁剪行为分析(图2)揭示了一个重要发现:GSPO裁剪了显著更高比例的令牌(15%),而GRPO仅裁剪0.13%的令牌。裁剪机制用于移除与旧策略差异过大的样本。GSPO在丢弃更多"离策略"数据的同时仍保持更优性能,这强烈表明其序列级信号在识别低质量训练样本方面具有更高的可靠性,而GRPO的令牌级信号存在效率问题。
专家混合模型稳定性测试显示,由于GSPO对MoE模型中个别令牌概率波动的不敏感性,该算法能够稳定地训练此类模型,无需采用"路由重放"等GRPO所必需的复杂解决方案。
总结
GSPO的贡献远超增量性改进。通过识别并修复GRPO中的根本性设计缺陷,该算法为稳定且可扩展的强化学习建立了更加坚实的理论基础。算法实现了数学目标与序列奖励实际特性的有效对齐,产生了更清晰的学习信号、更优的性能表现和更强的训练稳定性,这些优势对于未来大规模复杂模型的发展具有重要意义。
从令牌级优化向序列级优化的转变体现了算法设计的重要洞察,这一范式转变必将对未来语言模型强化学习算法的发展产生深远影响。
论文: