
论文标题:Eureka: Human-Level Reward Design via Coding Large Language Models
论文作者:Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
作者单位:NVIDIA; UPenn; Caltech; UT Austin
论文原文:https://arxiv.org/abs/2310.12931
论文出处:ICLR 2024
论文被引:10(01/05/2024)
项目主页:https://eureka-research.github.io/
论文代码:https://github.com/eureka-research/Eureka,2.4k star
ABSTRACT
大型语言模型(LLM)作为高层次语义规划器,在顺序决策任务中表现出色。然而,如何利用它们来学习复杂的低层次操作任务(如灵巧地转动钢笔),仍然是一个有待解决的问题。我们弥补了这一根本性差距,推出了由 LLMs 驱动的人类级奖励设计算法 EUREKA。EUREKA 利用最先进的 LLM(如 GPT-4)出色的零样本生成,代码编写和上下文改进能力,对奖励代码进行进化优化。由此产生的奖励可用于通过强化学习获得复杂的技能。在没有任何特定任务提示或预定义奖励模板的情况下,EUREKA 生成的奖励函数优于人类设计的专家奖励。在包含 10 种不同机器人形态的 29 种开源 RL 环境中,EUREKA 在 83% 的任务中表现优于人类专家,平均归一化提高了 52%。EUREKA的通用性还使一种新的无梯度上下文学习方法成为可能,即从人类反馈中进行强化学习(RLHF),在不更新模型的情况下,随时结合人类输入来提高生成奖励的质量和安全性。最后,通过在课程学习环境中使用 EUREKA 奖励,我们首次展示了能够表演钢笔旋转技巧的模拟影子手,它能熟练地操纵钢笔以极快的速度转圈。
1 INTRODUCTION
大型语言模型(LLMs)作为机器人任务的高层次语义规划器表现出色,但它们能否用于学习复杂的低层次操作任务,如灵巧地旋转钢笔,仍是一个未决问题。现有的尝试需要大量的领域专业知识来构建任务提示,或者只能学习简单的技能,在实现人类级别的灵巧性方面还存在很大差距。
另一方面,强化学习(RL)在灵巧性以及许多其他领域都取得了令人印象深刻的成果——前提是人类设计者能够精心构建奖励函数,为所需行为准确编码并提供学习信号。由于现实世界中的许多 RL 任务都存在难以学习的稀疏奖励,因此在实践中,提供增量学习信号的奖励塑造是必要的。尽管奖励功能具有根本性的重要性,但众所周知其设计难度很大;最近进行的一项调查发现,92%的受访强化学习研究人员和从业人员表示奖励设计需要手动试错,89%的人表示他们设计的奖励是次优的,会导致非预期行为。
鉴于奖励设计的极端重要性,我们不禁要问,是否有可能利用最先进的编码 LLM(如 GPT-4)来开发一种通用的奖励编程算法?它们在代码编写,零样本生成和上下文学习方面的卓越能力曾使有效的编程Agent成为可能。理想情况下,这种奖励设计算法应具有人类水平的奖励生成能力,可扩展到广泛的任务范围,在没有人类监督的情况下自动完成乏味的试错过程,同时与人类监督兼容,以确保安全性和一致性。

我们介绍了一种由编码 LLMs 驱动的新型奖励设计算法——Agent进化驱动通用奖励工具包(Evolution-driven Universal REward Kit for Agent,EUREKA),其贡献如下:
- 在 29 种不同的开源 RL 环境中,EUREKA 的奖励设计性能达到了人类水平,这些环境包括 10 种不同的机器人形态,包括四足机器人,四旋翼机器人,双足机器人,机械手以及几种灵巧的手;见图 1。在没有任何特定任务提示或奖励模板的情况下,EUREKA 自主生成的奖励在 83% 的任务中优于人类专家的奖励,并实现了 52% 的平均归一化改进。
- 解决以前无法通过人工奖励工程实现的灵巧操作任务。我们考虑了钢笔旋转的问题,在这种情况下,一只五指手需要按照预先设定的旋转配置快速旋转钢笔,并尽可能多地旋转几个周期。通过将 EUREKA 与课程学习相结合,我们首次在模拟的拟人影子手上演示了快速旋转笔的操作(见图 1 底部)。
- 我们采用了一种新的无梯度上下文学习方法,即从人类反馈中进行强化学习(RLHF),这种方法可以根据各种形式的人类输入生成性能更强,与人类更匹配的奖励函数。我们证明,EUREKA 可以从现有的人类奖励函数中获益并加以改进。同样,我们还展示了 EUREKA 利用人类文本反馈来共同引导奖励函数设计的能力,从而捕捉到人类在Agent行为中的细微偏好。
与之前使用 LLMs 辅助奖励设计的 L2R 工作不同,EUREKA 完全没有特定任务提示,奖励模板以及少量示例。在我们的实验中,EUREKA 的表现明显优于 L2R,这得益于它能够生成和完善自由形式,富有表现力的奖励程序。EUREKA 的通用性得益于三个关键的算法设计选择:环境作为背景,进化搜索和奖励反射。
- 首先,通过将环境源代码作为上下文,EUREKA 可以从主干编码 LLM(GPT-4)中零样本生成可执行的奖励函数。
- 然后,EUREKA 通过执行进化搜索,在 LLM 上下文窗口内迭代地提出一批候选奖励并完善最有希望的奖励,从而大幅提高奖励质量。这种在上下文中的改进通过奖励反思来实现,奖励反思是基于策略训练统计数据的奖励质量文本总结,可实现自动和有针对性的奖励编辑;EUREKA zero-shot 奖励的示例及其优化过程中积累的各种改进见图 3。为了确保 EUREKA 能够将奖励搜索扩展到最大潜力,EUREKA 在 IsaacGym 上使用 GPU 加速的分布式强化学习来评估中间奖励,这可以提供高达三个数量级的策略学习速度,使 EUREKA 成为一种广泛的算法,可以随着计算量的增加而自然扩展。概况见图 2。
我们致力于开源所有提示,环境和生成的奖励函数,以促进对基于 LLM 的奖励设计的进一步研究。
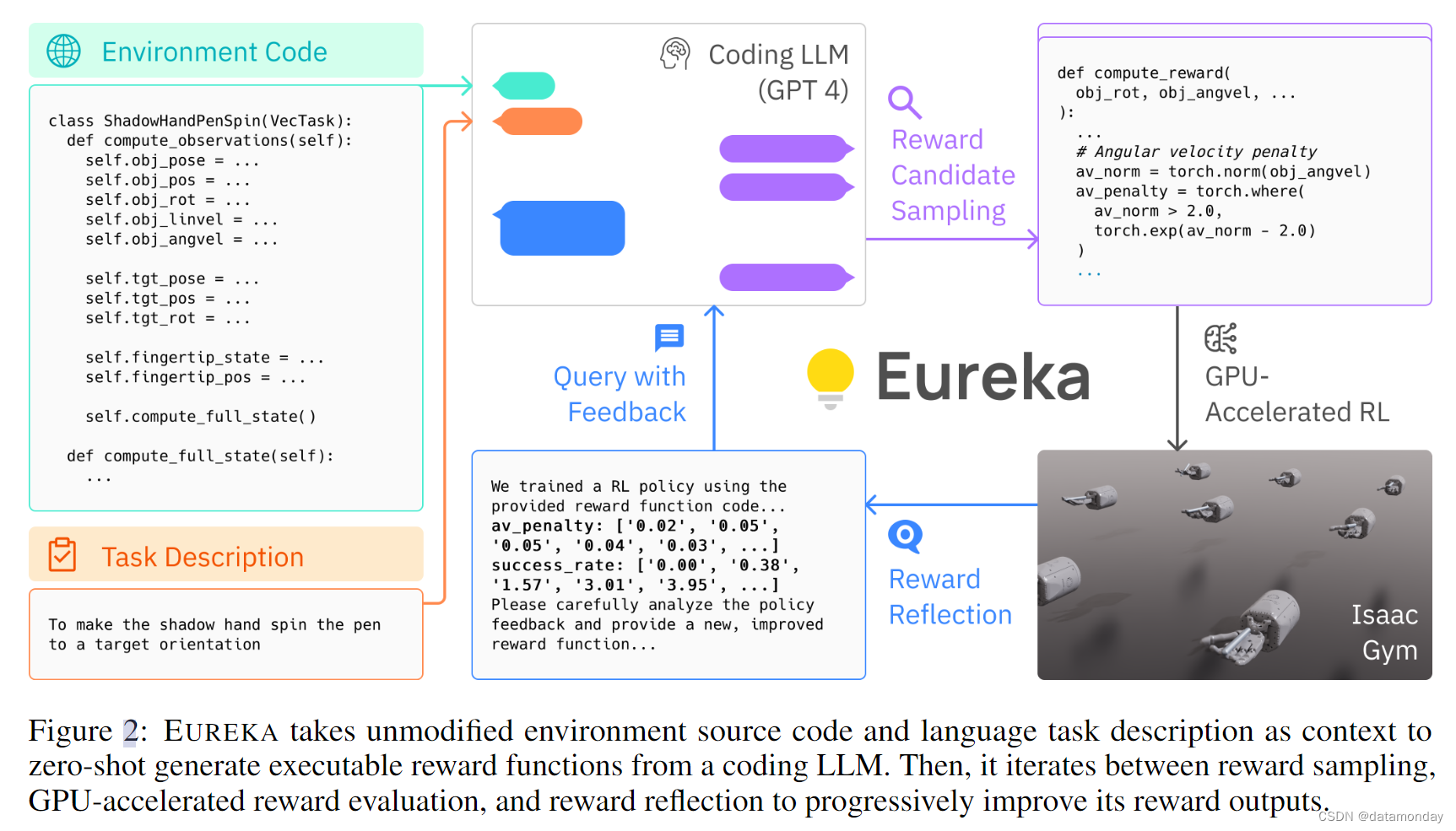
2 PROBLEM SETTING AND DEFINITIONS
奖励设计的目标是为可能难以直接优化的真实奖励函数(如稀疏奖励)返回一个成型的奖励函数;这个真实奖励函数只能通过设计者的查询来访问。我们首先介绍 Singh 等人的正式定义,然后将其应用到程序合成环境中,我们称之为奖励生成。
定义 2.1 奖励设计问题(RDP)是一个元组 P = ⟨M, R, πM , F ⟩,其中 M = (S, A, T ) 是具有状态空间 S,行动空间 A 和转换函数 T 的世界模型。R 是奖励函数空间;AM (-) : R → Π 是一种学习算法,可输出一种策略 π : S → ∆(A),在生成的马尔可夫决策过程(MDP)(M, R)中优化奖励 R∈ R;F : Π → R 是适应度函数,可对任何策略进行标量评估,只能通过策略查询(即使用适应度函数评估策略)获取。在 RDP 中,目标是输出一个奖励函数 R∈ R,从而使优化 R 的策略π := AM ® 获得最高的适应度得分 F (π)。
奖励生成问题。在我们的问题设置中,RDP 中的每个组件都是通过代码指定的。然后,给定一个指定任务的字符串 l,奖励生成问题的目标就是输出一个奖励函数代码 R,使 F (AM ®) 最大化。
3 METHOD
EUREKA 由三个算法组件组成:
- 1)以环境为背景,实现零样本生成可执行奖励
- 2)进化搜索,迭代提出并完善候选奖励
- 3)奖励反射,实现细粒度奖励改进
伪代码见 Algorithm 1。

3.1 ENVIRONMENT AS CONTEXT
奖励设计需要向 LLM 提供环境规范。我们建议直接将原始环境代码(不含奖励代码,如果存在的话)作为上下文提供给 LLM。也就是说,LLM 将从字面上把 M 作为上下文。这样做有两个直观的原因:
- 首先,编码 LLM 是根据现有编程语言编写的本地代码进行训练的,因此当我们直接允许 LLM 以它们所训练的风格和语法进行编译时,我们应该期望它们的代码生成能力会更强。
- 其次,更重要的是,环境源代码通常揭示了环境在语义上的含义,以及哪些变量可以并应该用于为指定任务编写奖励函数。
利用这些洞察力,EUREKA 会指示编码 LLM 直接返回可执行的 Python 代码,其中只包含通用奖励设计和格式提示,例如将奖励中的单个组件作为字典输出(原因将在第 3.3 节中说明)。这个过程具有最大的可扩展性,因为根据构造,环境源代码必须存在。详见附录 D。
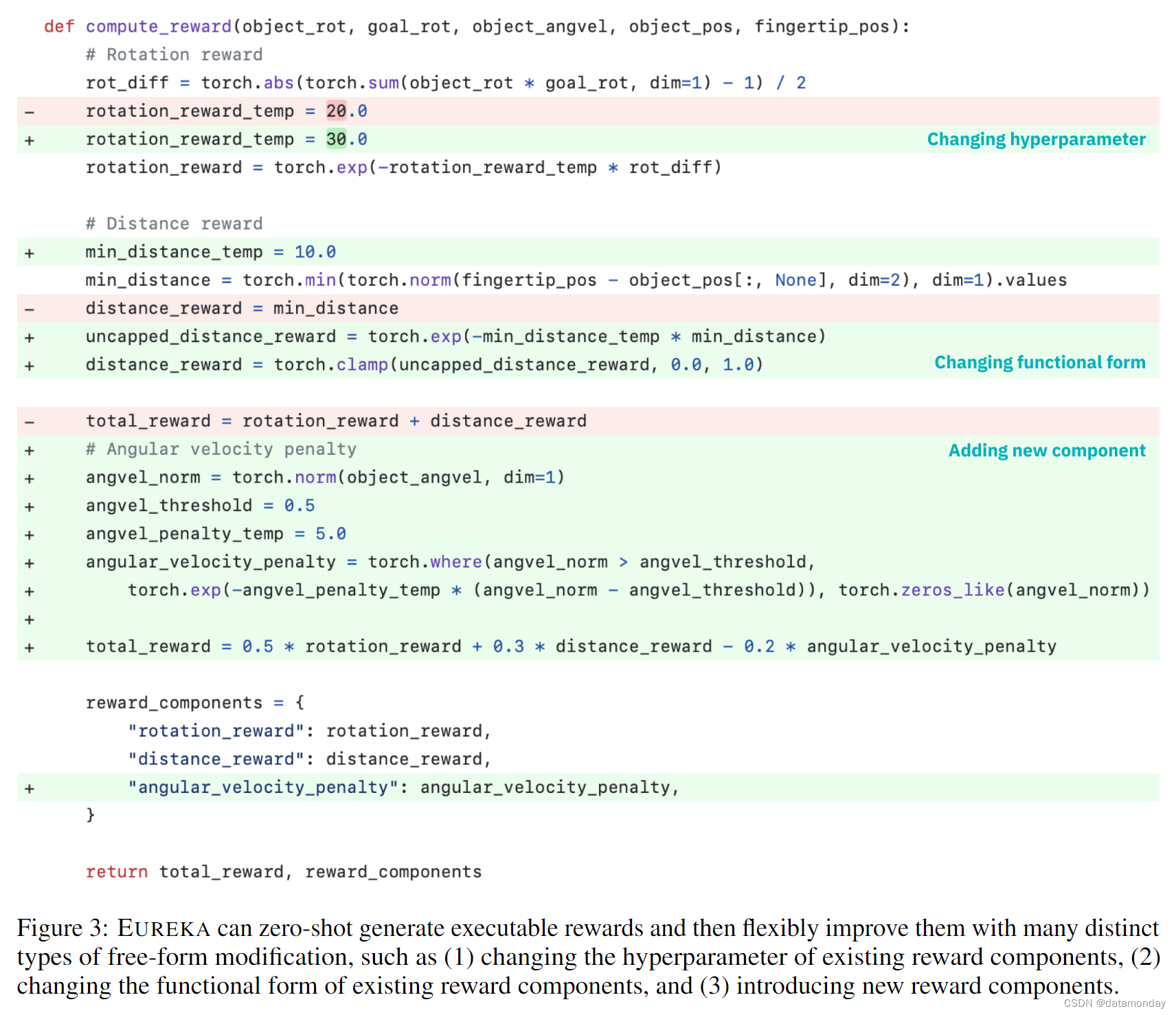
值得注意的是,仅凭这些最基本的指令,EUREKA 首次尝试就能在不同环境中零样本生成看似合理的奖励。图 3 是 EUREKA 输出的一个示例。如图所示,EUREKA 在提供的环境代码中巧妙地组合了现有的观察变量(如指尖位置),并生成了合格的奖励代码——所有这一切都不需要任何特定环境的提示工程或奖励模板。不过,在第一次尝试时,生成的奖励可能并不总是可执行的,即使是可执行的,就任务适配度量 F 而言,也可能是相当次优的。虽然我们可以通过特定任务的格式和奖励设计提示来改进提示,但这样做并不能扩展到新任务,而且会妨碍我们系统的整体通用性。如何才能有效克服单样本奖励生成的次优性?
3.2 EVOLUTIONARY SEARCH
在本节中,我们将展示进化搜索如何提供一种自然的解决方案,以解决上述执行错误和次优化难题。在每次迭代中,EUREKA 都会对 LLM 的多个独立输出进行采样(图 1 中的第 5 行)。由于各代都是 i.i.d,因此随着采样次数的增加,迭代中所有奖励函数出现错误的概率会呈指数级下降。我们发现,在我们考虑的所有环境中,即使只对少量(16 个)输出进行采样,在第一次迭代中也至少包含一个可执行的奖励代码。
通过提供早期迭代的可执行奖励函数,EUREKA 可执行上下文奖励突变,根据文本反馈从现有奖励函数中提出新的改进奖励函数。考虑到 LLM 的指令跟踪和上下文改进功能,EUREKA 只需将突变运算符指定为文本提示即可实现这一点,该文本提示会根据策略训练的文本摘要(第 3.3 节)建议几种修改现有奖励代码的一般方法。图 3 展示了几种奖励修改的示例。通过突变,新的 EUREKA 迭代会将上一次迭代中表现最好的奖励作为上下文,并从 LLM 中生成 K 个以上的 i.i.d 奖励输出。这种迭代优化一直持续到达到指定的迭代次数。最后,我们会进行多次随机重启,以找到更好的全局解决方案;这是全局优化的标准策略,用于克服糟糕的初始猜测。在我们的所有实验中,EUREKA 对每个环境进行 5 次独立运行,每次运行搜索 5 次迭代,每次迭代 K = 16 个样本。
3.3 REWARD REFLECTION
为了使上下文中的奖励突变有据可依,我们必须能够用语言表达所生成奖励的质量。由于我们可以在生成的策略上查询任务适配度函数 F,因此一个简单的策略就是只提供这个数字分数作为奖励评估。虽然任务适配度函数可以作为整体的基本真实指标,但它本身缺乏信用分配,无法提供有用的信息来说明奖励函数为何有效或无效。为了提供更复杂,更有针对性的奖励诊断,我们建议构建自动反馈,以文本形式总结策略训练动态。具体来说,鉴于 EUREKA 奖励函数被要求在奖励程序中公开其各个组件(如图 3 中的奖励组件),我们在整个训练过程中的中间策略检查点跟踪所有奖励组件的标量值。例如,考虑图 2 中的示例,其中 av 惩罚的快照值在奖励反馈中以列表形式提供。
这种奖励反射程序虽然构建简单,但由于奖励优化的算法依赖性,因此非常重要。也就是说,奖励函数是否有效受 RL 算法特定选择的影响,即使在同一优化器下,由于超参数的差异,相同奖励的表现也可能大相径庭。通过详细说明 RL 算法如何优化单个奖励成分,奖励反思使 EUREKA 能够产生更有针对性的奖励编辑,并合成能更好地与固定 RL 算法协同的奖励函数。
4 EXPERIMENTS
我们对 EUREKA 的各种机器人体现和任务进行了全面评估,测试了其生成奖励函数,解决新任务以及结合各种形式人类输入的能力。除非另有说明,我们使用 GPT-4(gpt-4-0314),作为所有基于 LLM 的奖励设计算法的主干 LLM。
Environments.
我们的环境由 10 个不同的机器人和 29 项任务组成,使用 Isaac Gym 模拟器实现。首先,我们包含了来自 Isaac Gym 的 9 个原始环境,涵盖了从四足机器人,双足机器人,四旋翼机器人,机器人手臂到灵巧双手等多种机器人形态。除了涵盖各种机器人形态外,我们还将双灵巧操作基准 Dexterity 中的全部 20 个任务都纳入了评估范围,从而确保了评估的深度。Dexterity 包含 20 项复杂的双徒手任务,要求一对影子手解决从物体交接到将杯子旋转 180 度等各种复杂的操作技能。对于输入到 EUREKA 的任务描述,我们尽可能使用环境资源库中提供的官方描述。有关所有环境的详细信息,请参见附录 B 了解所有环境的详细信息。值得注意的是,这两个基准都是同时公开发布的,或者说是在 GPT-4 知识截止日期(2021年9月)之后发布的,因此GPT-4 不太可能积累了关于这些任务的大量互联网知识,这使得它们成为评估EUREKA奖励生成能力与可测量的人类工程奖励功能相比的理想测试平台。
4.1 BASELINES
L2R 提出了一种两阶段 LLM 提示解决方案,用于生成模板奖励。对于用自然语言指定的环境和任务,第一个 LLM 会被要求填写一个描述Agent运动的自然语言模板;然后,第二个 LLM 会被要求将这个 “运动描述” 转换成代码,调用一组手动定义的奖励 API 基元,编写一个设置其参数的奖励程序。为了使 L2R 在我们的任务中具有竞争力,我们模仿原始 L2R 模板定义了运动描述模板,并尽可能使用原始人类奖励的各个组成部分来构建 API 奖励原语。需要注意的是,这将使 L2R 更具优势,因为它可以访问原始奖励函数。与 EUREKA 一致,我们在每个环境中进行 5 次独立的 L2R 运行,每次运行生成 16 个奖励样本。详情请参见附录 C 了解更多详情。
Human。这些是我们的基准任务中提供的原始形状奖励函数。由于这些奖励函数是由设计任务的主动强化学习研究人员编写的,因此这些奖励函数代表了专家级人类奖励工程的成果。
Sparse。这些与我们用来评估生成奖励质量的适应度函数 F 相同。与 “人” 一样,这些函数也是由基准提供的。在灵巧任务中,它们是衡量任务成功与否的统一二元指标函数;而在 Isaac 任务中,它们的函数形式则因任务性质而异。参见附录 B。有关所有任务的真实评分标准的描述,请参见附录 B。
4.2 TRAINING DETAILS
Policy Learning。对于每项任务,所有最终奖励函数都使用相同的 RL 算法和相同的超参数集进行优化。Isaac 和 Dexterity 共享一个经过良好微调的 PPO 实现,我们使用该实现和特定任务的 PPO 超参数,不做任何修改。需要注意的是,这些任务超参数的调整是为了使官方的人工奖赏效果更好。对于每种奖励,我们都会运行 5 次独立的 PPO 训练运行,并将策略检查点达到的最大任务指标值的平均值作为奖励的性能进行报告。
Reward Evaluation Metrics。对于 Isaac 任务,由于每项任务的任务指标 F 在语义和规模上各不相同,我们报告了 EUREKA 和 L2R,
M
e
t
h
o
d
−
S
p
a
r
s
e
∣
H
u
m
a
n
−
S
p
a
r
s
e
∣
\frac{Method-Sparse}{|Human-Sparse|}
∣Human−Sparse∣Method−Sparse 的人类标准化得分。该指标提供了一个整体衡量标准,用于衡量与人类专家奖励相比,EUREKA 奖励在真实任务指标方面的表现。对于 Dexterity,由于所有任务都使用二元成功函数进行评估,因此直接报告成功率。
4.3 RESULTS
EUREKA outperforms human rewards.
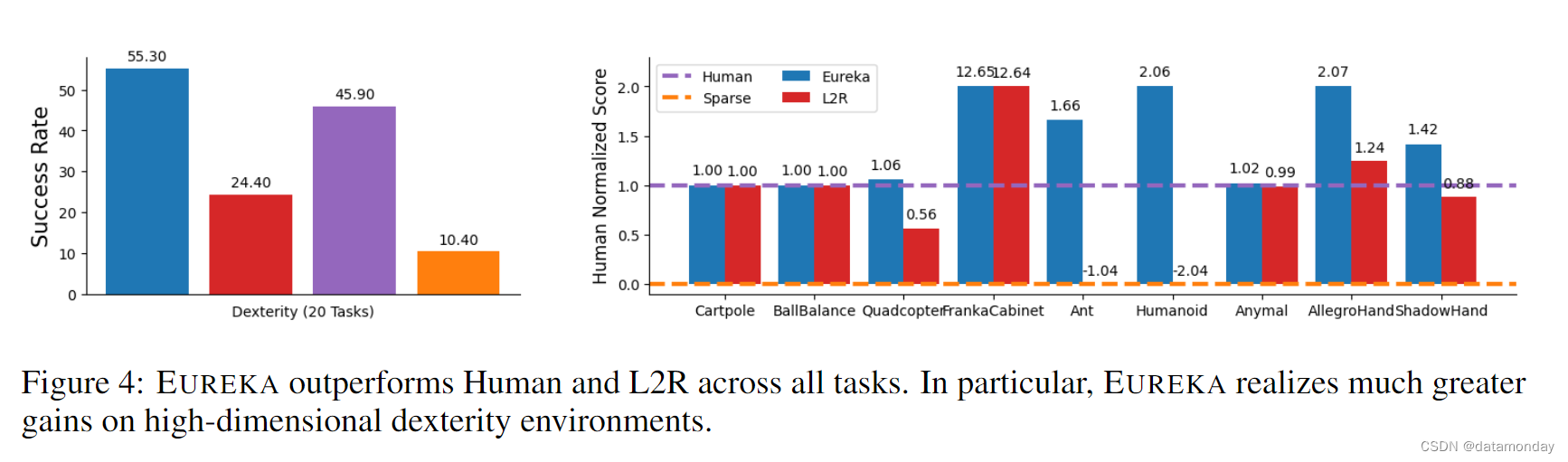
在图 4 中,我们报告了两个基准的综合结果。值得注意的是,EUREKA 在所有 Isaac 任务和 Dexterity 20 个任务中的 15 个任务上的表现都超过了人类水平或与人类水平相当(每个任务的细分见附录 E)。相比之下,L2R 虽然在低维任务(如 CartPole,BallBalance)上表现相当,但在高维任务上却明显落后。尽管 L2R 可以访问一些与 Human 相同的奖励组件,但在初始迭代后,当两种方法的奖励查询次数相同时,L2R 的表现仍然不如 EUREKA。不出所料,L2R 缺乏表达能力严重限制了其性能。相比之下,EUREKA 从零开始生成自由形式的奖赏,不需要任何特定领域的知识,表现要好得多。在附录 E 中,我们用 GPT-3.5 消融了 GPT-4,发现 EUREKA 的性能有所下降,但在大多数 Isaac 任务上仍能达到或超过人类水平,这表明它的一般原理可以很容易地应用于不同质量的LLM编码。
EUREKA consistently improves over time.
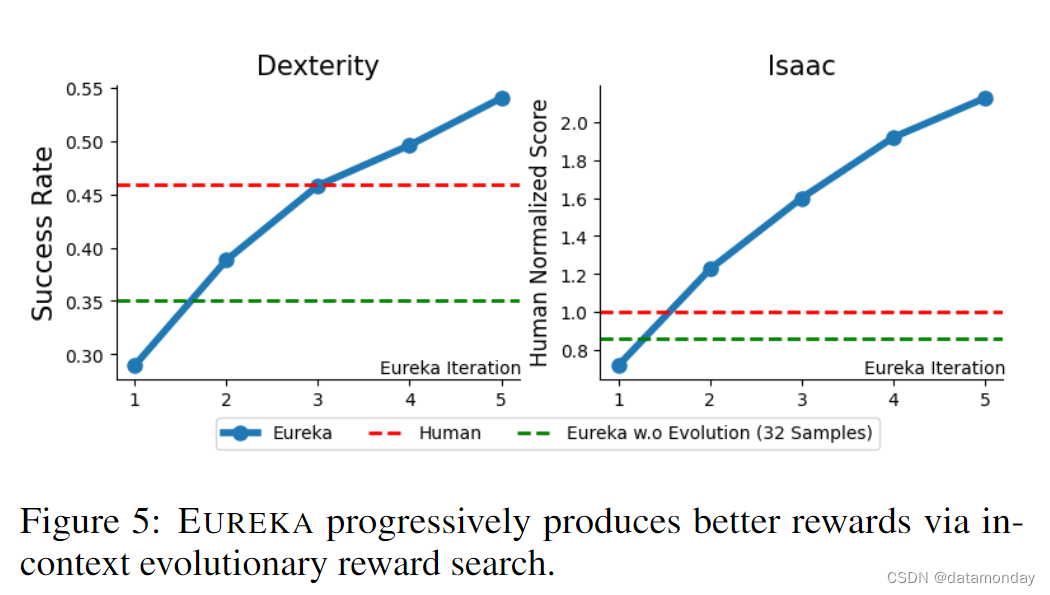
在图 5 中,我们展示了每次进化迭代后累积的最佳 EUREKA 奖励的平均性能。此外,我们还研究了EUREKA w.o. Evolution (32 Samples),它只执行初始奖励生成步骤,采样的奖励函数数量与原始EUREKA的两次迭代相同。在奖励函数预算数量固定的情况下,这种消融有助于研究是执行 EUREKA 进化更有优势,还是只采样更多的首次尝试奖励而不进行迭代改进更有优势。正如我们所看到的,在这两个基准上,EUREKA 奖励都在稳步提高,并最终在性能上超越了人类奖励,尽管最初的表现并不理想。这种持续的改进也不是在第一次迭代中进行更多采样就能取代的,因为在两个基准上,迭代 2 次之后,消融的性能都低于 EUREKA。这些结果共同表明,EUREKA 的新颖进化优化对其最终性能是不可或缺的。
EUREKA generates novel rewards.
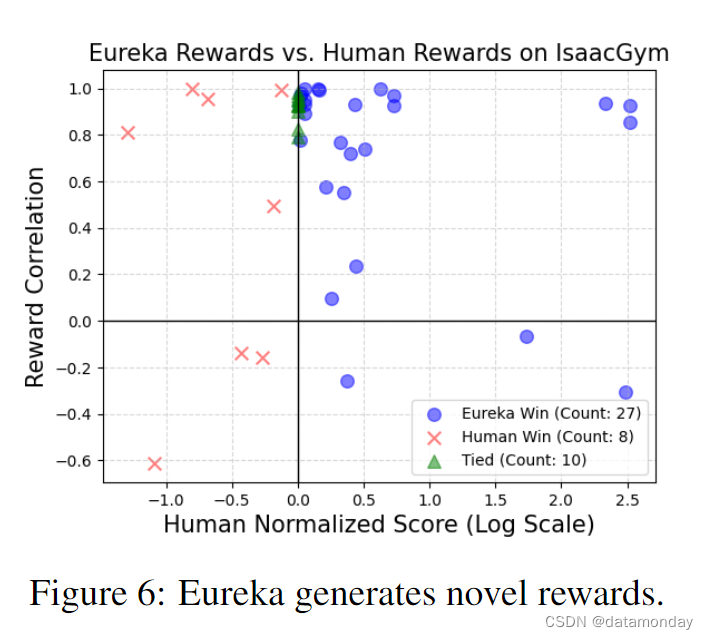
我们通过计算所有Isaac任务中EUREKA奖励与人类奖励之间的相关性来评估EUREKA奖励的新颖性。有关此过程的详情,请参阅附录 B。然后,我们在图 6 的散点图上绘制出相关性与人类归一化分数的对比图,其中每个点代表一个任务中的一个 EUREKA 奖励。如图所示,EUREKA 生成的奖励函数几乎都是弱相关的,表现优于人类的奖励函数。此外,通过研究任务的平均相关性(附录 E),我们发现任务越难,EUREKA 奖励的相关性就越低。我们的假设是,对于困难的任务,人类奖励不太可能接近最优,这就为 EUREKA 奖励留下了更多不同和更好的空间。在少数情况下,EUREKA奖励甚至与人类奖励呈负相关,但表现却明显更好,这表明EUREKA可以发现可能与人类直觉相悖的新颖奖励设计原则;我们在附录 F.2 中对这些EUREKA奖励进行了说明。
Reward reflection enables targeted improvement.
为了评估在奖励反馈中构建奖励反射的重要性,我们评估了一种消融方法,即 EUREKA(无奖励反射),它减少了奖励反馈提示,只包括任务指标 F 的快照值。从所有 Isaac 任务的平均值来看,没有奖励反射的 EUREKA 将平均归一化分数降低了 28.6%;在附录 E 中,我们提供了每个任务的详细分解,并观察到在维度更高的任务中,性能下降幅度更大。为了提供定性分析,我们在附录 F.1 中,我们列举了几个例子,其中 EUREKA 利用奖励反射执行了有针对性的奖励编辑。
EUREKA with curriculum learning enables dexterous pen spinning.
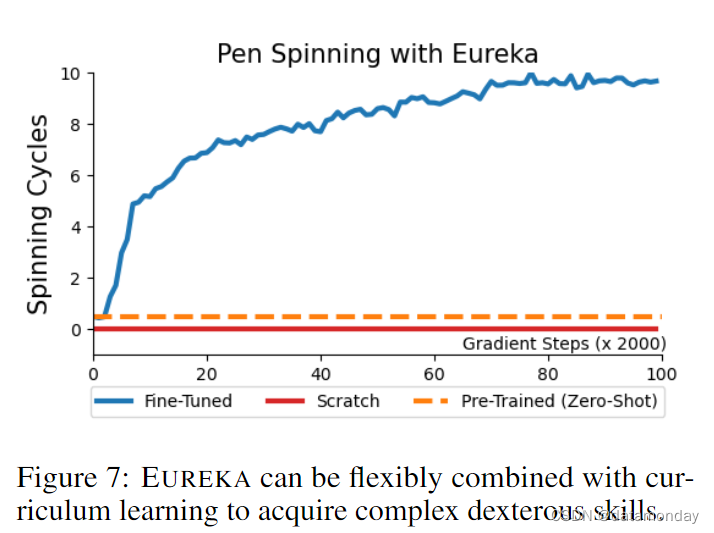
最后,我们将研究 EUREKA 能否用于解决真正新颖且具有挑战性的灵巧任务。为此,我们提出了钢笔旋转作为测试平台。这项任务是高度动态的,需要影子手不断旋转钢笔,以尽可能多的周期实现一些预定义的旋转模式。我们考虑采用课程学习的方法,将任务分解为可管理的组件,由 EUREKA 独立解决;类似的方法在其他编码 LLM 应用于决策制定时也取得了成功。具体来说,我们首先指示 EUREKA 生成一个奖励,用于将笔重新定向到随机目标配置上。然后,利用这个预先训练好的策略(Pre-Trained),我们使用 EUREKA 的奖励对其进行微调,以达到笔的旋转配置序列(Fine-Tuned)。为了证明课程学习的重要性,我们还使用 EUREKA 奖励从头开始训练一个基准策略,而不进行第一阶段的预训练(Scratch)。RL 训练曲线如图 7 所示。Eureka 微调能快速调整策略,使笔沿着指定的旋转轴连续旋转多个周期。相比之下,无论是预训练还是从零开始学习的策略,都无法完成哪怕是一个周期的笔旋转。此外,利用这种 EUREKA 微调方法,我们还针对各种不同的旋转配置训练了钢笔旋转策略;所有钢笔旋转视频可在我们的项目网站上观看,实验详情见附录 D1。这些结果表明,EUREKA 适用于高层次策略学习方法,这通常是学习非常复杂的技能所必需的。
4.4 EUREKA FROM HUMAN FEEDBACK
除了自动奖励设计外,EUREKA 还支持一种新的无梯度上下文学习方法,即从人类反馈中进行 RL(RLHF),该方法可随时纳入各种类型的人类输入,以生成性能更佳,与人类更匹配的奖励函数。
EUREKA can improve and benefit from human reward functions.
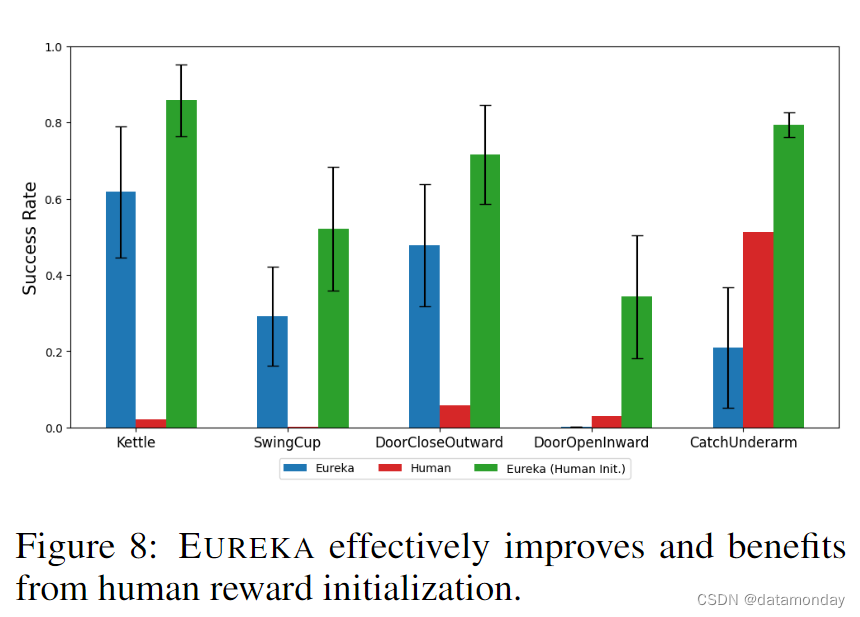
我们研究了从人类奖励函数初始化开始(这在现实世界的 RL 应用中很常见)是否对 EUREKA 有利。重要的是,加入人类初始化不需要对EUREKA进行任何修改–我们只需将原始人类奖励函数替换为EUREKA第一次迭代的输出即可。为了研究这一点,我们从 Dexterity 中选择了几个任务,这些任务在原始 EUREKA 和人类奖励的相对性能上存在差异。全部结果如图 8 所示。如图所示,无论人类奖励的质量如何,EUREKA 都能改进人类奖励并从中获益,因为在所有任务中,EUREKA(Human Init.) 这表明,EUREKA 的情境奖励改进能力在很大程度上与基础奖励的质量无关。此外,EUREKA 即使在人类奖赏高度次优的情况下也能显著提高奖赏质量,这一事实暗示了一个有趣的假设:人类设计师通常了解相关的状态变量,但在使用这些变量设计奖赏方面却不那么精通。这在直觉上是合理的,因为识别应包含在奖励函数中的相关状态变量主要涉及常识推理,而奖励设计则需要 RL 方面的专业知识和经验。这些结果共同证明了 EUREKA 的奖励助手能力,它完美地补充了人类设计者关于有用状态变量的知识,并弥补了他们在如何使用这些变量设计奖励方面的不足。附录 F.3 提供了几个EUREKA(Human Init.)步骤的例子。
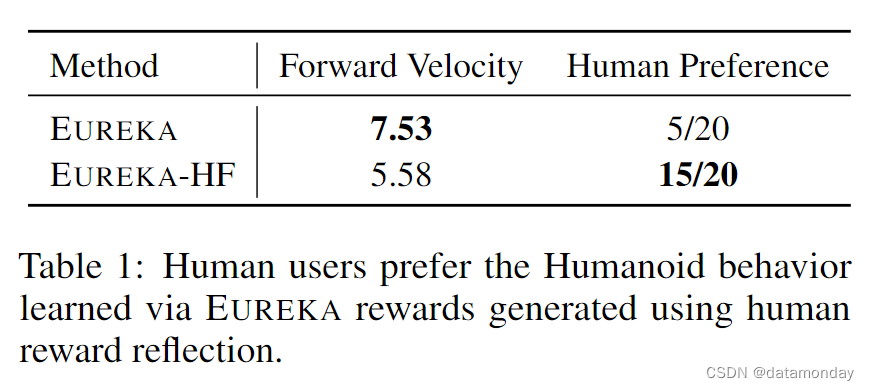
Reward reflection via human feedback induces aligned behavior

迄今为止,所有 EUREKA 奖励都是根据固定的黑盒任务适合度函数(black-box task fitness function) F 进行优化的。然而,这一任务指标可能并不完全符合人类的意图。此外,在许多开放式任务中,F 可能一开始就不可用。在这些具有挑战性的场景中,我们建议让人类介入,用语言表达出期望行为和纠正的奖励反映,从而增强 EUREKA 的功能。我们通过教一个仿人 Agent 如何纯粹根据文字奖励反映来运行来研究 EUREKA 的这一能力;在附录 F.4 中,我们展示了人类反馈和EUREKA奖励的确切顺序。然后,我们进行了一项用户研究,要求 20 名陌生用户在随机顺序播放的两个策略推出(policy rollout)视频(一个是经过人类奖励反射训练的视频(EUREKA-HF),另一个是经过原始最佳 EUREKA 奖励训练的视频)中选择自己的偏好;详情见附录 D.3。如表 1 所示,EUREKA-HF Agent受到了绝大多数用户的青睐,它成功地以速度换取了稳定性。在图 9 中,我们展示了每次人类反馈后 Eureka 学习行为的演变。我们确实看到,EUREKA-HF Agent在人类的指导下逐渐获得了更安全,更稳定的步态。在我们的项目网站上,我们提供了每种中间EUREKA-HF策略的视频以及与之相关的EUREKA奖励。
5 RELATED WORK
Reward Design.
奖励工程是强化学习中一个长期存在的难题。最常见的奖励设计方法是人工试错。逆强化学习(Inverse reinforcement learning,IRL)可从演示中推断出奖励函数,但它需要昂贵的专家数据收集,而这些数据可能无法获得,并且会输出不可解释的黑箱奖励函数。之前有几项工作研究了通过进化算法进行自动奖励搜索。这些早期尝试仅限于进化算法的特定任务实现,即只在提供的奖励模板内搜索参数。最近的研究还提出使用预训练的基础模型,为新任务生成奖励函数。大多数这些方法输出的标量奖励缺乏可解释性,自然也不具备即时改进或调整奖励的能力。相比之下,EUREKA 能够熟练地生成自由形式的白盒奖励代码,并有效地在上下文中进行改进。
Code Large Language Models for Decision Making.
最近的工作考虑使用编码 LLMs 为决策和机器人问题生成接地气的结构化程序输出。然而,这些研究大多依赖已知的运动基元来执行机器人动作,不适用于需要低层次技能学习的机器人任务,如灵巧操作。与我们的工作最接近一项工作也在探索使用 LLMs 来辅助奖励设计。不过,他们的方法需要特定领域的任务描述和奖励模板,这需要大量的领域知识,并限制了生成的奖励函数的表达能力。
Evolution with LLMs.
在神经架构搜索,提示工程以及形态设计等方面,最近的研究都在探索如何利用LLMs实施进化算法。我们首次将这一原则应用于奖励设计。与之前的方法不同,EUREKA 不需要人类提供初始候选者或小样本提示。此外,EUREKA 还引入了新颖的奖励反射机制,使奖励突变(reward mutation)更具针对性和有效性。
6 CONCLUSION
我们介绍了一种通用奖励设计算法 EUREKA,它由编码大型语言模型和上下文进化搜索驱动。在没有任何特定任务提示工程或人工干预的情况下,EUREKA 可在各种机器人和任务上实现人类水平的奖励生成。EUREKA在学习灵巧性方面具有独特优势,首次采用课程学习方法解决了灵巧的转笔问题。最后,EUREKA 采用无梯度方法从人类反馈中进行强化学习,随时将人类奖励初始化和文本反馈纳入其中,以更好地指导奖励生成。EUREKA的多功能性和显著的性能提升表明,将大型语言模型与进化算法相结合的简单原理是一种通用的,可扩展的奖励设计方法,这种见解可能普遍适用于困难的,开放式的搜索问题。
Appendix

A FULL PROMPTS
在本节中,我们提供所有 EUREKA 提示。在高层次上,EUREKA 仅指导奖励设计的通用指导以及模拟器特定的代码格式化提示。


B ENVIRONMENT DETAILS
C BASELINE DETAILS
D EUREKA DETAILS
E ADDITIONAL RESULTS
F EUREKA REWARD EXAMPLES
版权归原作者 datamonday 所有, 如有侵权,请联系我们删除。