
特征工程是生成精确模型的最重要步骤之一。但是没有人喜欢它,因为这个步骤非常繁琐,我坚信任何繁琐的事情都可以自动化。虽然我的解决方案并没有完全消除对手工工作的需要,但它确实大大减少了手工工作,并产生了更好的结果。它还生成了一个在结构化数据集上始终优于梯度增强方法的模型。
本文将包含以下内容:
- 到底什么被自动化了?
- 它是如何工作的?
- 你如何建立它?
- 和其他型号相比怎么样?
工程特性
正确地做工程特性可能需要数周的EDA。但幸运的是,神经网络擅长的是寻找相互作用关系!
当向模型提供一组特征时,它必须了解哪些特征相互作用,以及它们是如何相互作用的。有了庞大的数据集,可以有无数的组合进行测试,这些模型往往专注于提供快速成功的交互。通过特性工程,您可以手动创建或组合特性,以确保模型正确的关注这些特征。
根据数据和问题的不同,有许多不同类型的特征工程方法。大多数可分为以下几类:
数据清理:有些人认为这个特征工程,其实并不是这样,他应该有在训练中有着自己独立的地位。总结来说,这一步的目的是特性工程成为可能之前需要确保数据是可用的。它涉及修复数据中的错误、处理缺失值、处理异常值、独热编码、扩展特性以及无数其他事情。在我看来,数据清理是唯一一个比特征设计更糟糕的步骤,所以任何能找到自动化这一步的方法的人都将成为我的新的发现。
均值编码:这一步涉及到将分类特征(如邮政编码)转换为模型可用的信息。例如,可以创建一个列,显示邮政编码的分组后的平均销售收入。
滞后变量:在数据中添加时间序列元素通常会有帮助。通过添加以前时期的价值,模型可以计算出随着时间的推移事情的趋势(例如上个月的销售额,前月的销售额,等等)。这个过程并不太复杂,可以通过简单的循环实现自动化。
交互:这个步骤涉及到以不同的方式组合特征。例如,你可以通过将广告驱动的客户购买除以广告的总点击次数来衡量在线广告的转化率。但如果转化率因产品价格的不同而变化很大呢?现在可以根据价格阈值创建单独的列。我们也很难发现并知道如何处理三阶(或更高阶)互动(例如,广告转化率因价格和类别而异)。到目前为止,这是特性工程中最微妙和最耗时的步骤。正确地做这个步骤需要做数周的EDA。幸运的是,神经网络擅长的是寻找相互作用!诀窍是确保模型确实寻找它们,这将是以后的重点。
概念
神经网络采用一组输入特征,并在它们之间创建相互作用,以最好地预测输出。如上所述,我们可以通过设计模型来强制模型考虑某些组合。但如果我们能迫使神经网络去考虑它们吗?如果我们可以确保神经网络以对目标输出产生最佳准确性的方式来设计这些特征的话,应该该怎么办?这里的关键就是是训练模型应以首先关注特征为主。
假设我们具有特征A,特征B,特征C和特征D,其目标输出为Y。此问题的第一步是创建一个预测每个特征的模型。我们为什么要关心预测特征?因为我们希望神经网络学习特定于每个特征的交互。
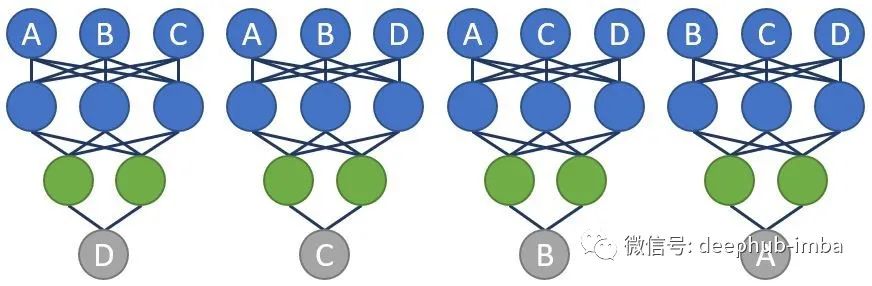
如果我们可以确保神经网络以对目标输出产生最佳精确的方式来设计这些功能,该怎么办?
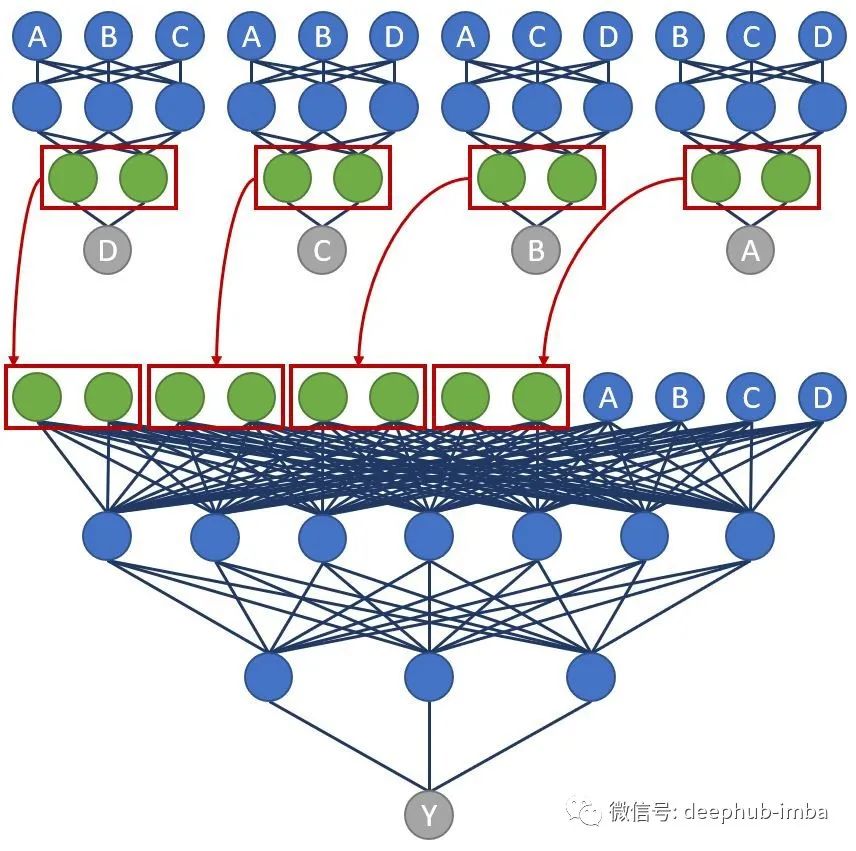
确保特征网络以最终模型而不是单独的过程进行训练。这里的技巧是训练嵌入到每个特征层的嵌入层。对您来说是个好消息:经过几个月的努力,我得以开发出一种解决方案,并且它超出了我的期望。
代码
为了演示这些方法,我们将尝试预测COVID-19病人发生严重反应的可能性。您可以在此处找到“ Cleaned-Data.csv”数据集:https://www.kaggle.com/iamhungundji/covid19-symptoms-checker?select=Cleaned-Data.csv
让我们提取数据并创建训练,验证和测试数据集:
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow import feature_column
from tensorflow.keras import layers
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.metrics import log_loss
X_train = pd.read_csv('covid_data.csv')
y_train = X_train.pop('Severity_Severe').to_frame()
X_train = X_train.iloc[:,:23]
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train,test_size=0.2,random_state=42)
X_val, X_test, y_val, y_test = train_test_split(
X_val, y_val,test_size=0.5,random_state=42)
现在,我们将要定义我们要为其创建特征模型的特征。由于我们没有很多特征,这里就全部使用它们(嵌入时将使用Country除外)。当模型包含数百个特征时,首先应该确定义最重要的特征,例如下面代码:
model_cols = ['Fever','Tiredness','Dry-Cough',
'Difficulty-in-Breathing',
'Sore-Throat','None_Sympton',
'Pains','Nasal-Congestion',
'Runny-Nose','Diarrhea',
'None_Experiencing','Age_0-9',
'Age_10-19','Age_20-24','Age_25-59',
'Age_60_','Gender_Female','Gender_Male',
'Gender_Transgender','Contact_Dont-Know',
'Contact_No','Contact_Yes']
这些特征中的每一个都会与我们试图预测的目标目标(Severity_Severe)一起成为整体模型的不同辅助输出。在创建TensorFlow数据集时,我们还必须将它们定义为输出特征。请注意,我们通过在末尾添加“ _out”来重命名每个特征,以免TensorFlow被重复的名称弄糊涂。请注意,我们还为目标输出添加了一个额外的“ _aux_out”列。这样一来,我们就可以围绕目标特征训练一个单独的特征模型,该模型也将输入到最终模型中。这是一个称为跳过连接的过程,该过程使模型可以学习围绕同一特征集的深层和浅层交互。
Y_train_df = X_train[model_cols].copy()
Y_train_df.columns = Y_train_df.columns + "_out"
Y_train_df['Severity_Severe_out'] = y_train['Severity_Severe']
Y_train_df['Severity_Severe_aux_out'] = y_train['Severity_Severe']
trainset = tf.data.Dataset.from_tensor_slices((
dict(X_train),dict(Y_train_df))).batch(256)
Y_val_df = X_val[model_cols].copy()
Y_val_df.columns = Y_val_df.columns + "_out"
Y_val_df['Severity_Severe_out'] = y_val['Severity_Severe']
Y_val_df['Severity_Severe_aux_out'] = y_val['Severity_Severe']
valset = tf.data.Dataset.from_tensor_slices((
dict(X_val),dict(Y_val_df))).batch(256)
Y_test_df = X_test[model_cols].copy()
Y_test_df.columns = Y_test_df.columns + "_out"
Y_test_df['Severity_Severe_out'] = y_test['Severity_Severe']
Y_val_df['Severity_Severe_aux_out'] = y_val['Severity_Severe']
testset = tf.data.Dataset.from_tensor_slices((
dict(X_test),dict(Y_test_df))).batch(256)
我们要创建的第一个函数是add_model。我们将向此函数提供特征名称,定义层的数量和大小,表示是否要使用批量归一化,定义模型的名称并选择输出激活。hidden_layers变量将为每个层有一个单独的列表,第一个数字是神经元的数量,第二个数字是dropout比例。该函数的输出将是输出层和最终的隐藏层(特征工程),这些层将作为最终模型的基础。使用诸如hyperopt之类的工具时,此功能允许轻松进行超参数调整。
def add_model(
feature_outputs=None,hidden_layers=[[512,0],[64,0]],
batch_norm=False,model_name=None,activation='sigmoid'):
if batch_norm == True:
layer = layers.BatchNormalization()(feature_outputs)
else:
layer = feature_outputs
for i in range(len(hidden_layers)):
layer = layers.Dense(hidden_layers[i][0], activation='relu',
name=model_name+'_L'+str(i))(layer)
last_layer = layer
if batch_norm == True:
layer = layers.BatchNormalization()(layer)
if hidden_layers[i][1] > 0:
layer = layers.Dropout(hidden_layers[i][1])(layer)
output_layer = layers.Dense(1, activation=activation,
name=model_name+'_out')(layer)
return last_layer, output_layer
下一个功能是用于创建嵌入层。因为“国家/地区”是稀疏的分类特征。此函数将提取要转换为嵌入的特征的字典,以及在此定义的该特征的唯一可能值的列表:
emb_layers = {'Country':list(X_train['Country'].unique())}
我们还稍后将对模型输入进行定义。对于Dimensions参数,我选择遵循默认特征规则。
def add_emb(emb_layers={},model_inputs={}):
emb_inputs = {}
emb_features = []
for key,value in emb_layers.items():
emb_inputs[key] = model_inputs[key]
catg_col = feature_column
.categorical_column_with_vocabulary_list(key, value)
emb_col = feature_column.embedding_column(
catg_col,dimension=int(len(value)**0.25))
emb_features.append(emb_col)
emb_layer = layers.DenseFeatures(emb_features)
emb_outputs = emb_layer(emb_inputs)
return emb_outputs
在继续使用下一个函数之前,我们需要定义哪些特征需要从不同的特征模型中排除。从根本上讲,我们将要排除要预测的特征(数据泄漏)和用于嵌入的特征。这里还应该小心删除可直接用于计算输出特征的特征。例如,一个预测男女的模型,如果有类似Gender_Female之类的特征那么它基本上可以获得100%的准确率。 为了解决这个问题,我们将从相应的特征模型中排除其他性别,年龄和联系人等特征。
feature_layers = {col:[col,'Country'] for col in model_cols}
feature_layers['Gender_Female'] += ['Gender_Male',
'Gender_Transgender']
feature_layers['Gender_Male'] += ['Gender_Female',
'Gender_Transgender']
feature_layers['Gender_Transgender'] += ['Gender_Female',
'Gender_Male']
feature_layers['Age_0-9'] += ['Age_10-19','Age_20-24',
'Age_25-59','Age_60_']
feature_layers['Age_10-19'] += ['Age_0-9','Age_20-24',
'Age_25-59','Age_60_']
feature_layers['Age_20-24'] += ['Age_0-9','Age_10-19',
'Age_25-59','Age_60_']
feature_layers['Age_25-59'] += ['Age_0-9','Age_10-19',
'Age_20-24','Age_60_']
feature_layers['Age_60_'] += ['Age_0-9','Age_10-19',
'Age_20-24','Age_25-59']
feature_layers['Contact_Dont-Know'] += ['Contact_No','Contact_Yes']
feature_layers['Contact_No'] += ['Contact_Dont-Know','Contact_Yes']
feature_layers['Contact_Yes'] += ['Contact_Dont-Know','Contact_No']
我们还想为我们模型添加一个feature_layer:
feature_layers['Severity_Severe_aux'] = ['Country']
现在,我们拥有构建特征模型所需的所有东西。此函数将使用所有输入特征列表,上面定义的排除特征和嵌入字典,在add_model函数中描述的hidden_layer结构以及是否应使用批处理规范的配置等。
首先,该函数将使用TensorFlow方式的读取输入特征。使用这种方法的原因我们只需要定义一次,就可以在每个特征模型中一再地重复使用它们。接下来我们将确定是否定义了任何嵌入列,并创建一个嵌入层(可选)。对于每个特征模型,我们将创建DenseFeatures输入层(不包括上面定义的特征),并使用add_model函数创建一个单独的模型。在返回之前,我们检查循环是否在跳连接模型上运行。如果是这样,我们将附加输入要素,以便最终模型也可以使用原始要素进行训练。最后,此函数将返回模型输入的字典,每个要特征模型输出层的列表以及每个最终隐藏层(即新设计的特征)的列表。
def feature_models(
output_feature=None,all_features=[],feature_layers={},
emb_layers={},hidden_layers=[],batch_norm=False):
model_inputs = {}
for feature in all_features:
if feature in [k for k,v in emb_layers.items()]:
model_inputs[feature] = tf.keras.Input(shape=(1,),
name=feature,
dtype='string')
else:
model_inputs[feature] = tf.keras.Input(shape=(1,),
name=feature)
if len(emb_layers) > 0:
emb_outputs = add_emb(emb_layers,model_inputs)
output_layers = []
eng_layers = []
for key,value in feature_layers.items():
feature_columns = [feature_column.numeric_column(f)
for f in all_features if f not in value]
feature_layer = layers.DenseFeatures(feature_columns)
feature_outputs = feature_layer({k:v for k,v in
model_inputs.items()
if k not in value})
if len(emb_layers) > 0:
feature_outputs = layers.concatenate([feature_outputs,
emb_outputs])
last_layer, output_layer = add_model(
feature_outputs=feature_outputs,
hidden_layers=hidden_layers,
batch_norm=batch_norm,
model_name=key)
output_layers.append(output_layer)
eng_layers.append(last_layer)
if key == output_feature + '_aux':
eng_layers.append(feature_outputs)
return model_inputs, output_layers, eng_layers
如果使用嵌入层,则它将与这些模型的每个输入连接在一起。这意味着这些嵌入不仅可以训练最大化整体模型的精度,还可以训练每一个特征模型。这导致了非常健壮的嵌入。
在进入最终功能之前,让我们定义将要输入的每个参数。以上大多数参数已在上面进行了描述,或对于所有TensorFlow模型都是典型的。例如,patience 参数,当指定时间段内验证准确性没有提高时,可使用该参数停止训练模型。
params = {'all_features': list(X_train.columns),
'output_feature':y_train.columns[0],
'emb_layers':emb_layers,
'feature_layers':feature_layers,
'hidden_layers':[[256,0],[128,0.1],[64,0.2]],
'batch_norm': True,
'learning_rate':0.001,
'patience':3,
'epochs':20
}
对于最终模型,我们将从运行上一个函数开始以生成输入,输出和特征工程的特征。然后,我们将这些层/特征中的每一个串联起来,并将其输入到最终模型中。最后,我们构建,编译,训练和测试模型。
def final_model(params,test=True):
print(params['batch_norm'],params['hidden_layers'])
model_inputs, output_layers, eng_layers = feature_models(
all_features=params['all_features'],
feature_layers=params['feature_layers'],
emb_layers=params['emb_layers'],
hidden_layers=params['hidden_layers'],
batch_norm=params['batch_norm'],
output_feature=params['output_feature'])
concat_layer = layers.concatenate(eng_layers)
last_layer, output_layer = add_model(
feature_outputs=concat_layer,
hidden_layers=params['hidden_layers'],
batch_norm=params['batch_norm'],
model_name=params['output_feature'])
output_layers.append(output_layer)
model = tf.keras.Model(
inputs=[model_inputs],
outputs=output_layers)
aux_loss_wgt = 0.5 / len(params['feature_layers'])
loss_wgts = [aux_loss_wgt for i in
range(len(params['feature_layers']))
loss_wgts.append(0.5)
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(
lr=params["learning_rate"]),
loss_weights=loss_wgts,
metrics=['accuracy'])
es = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',mode='min',verbose=1,
patience=params['patience'],restore_best_weights=True)
history = model.fit(
trainset,validation_data=valset,
epochs=params['epochs'], verbose=0, callbacks=[es])
yhat = model.predict(testset)
loss = log_loss(
np.array(y_test[params['output_feature']]),
yhat[-1])**.5
print('Binary Crossentropy:',loss)
if test==True:
sys.stdout.flush()
return {'loss': loss, 'status': STATUS_OK}
else:
return history, model
需要注意的是,函数的输入之一称为test。这个 输入可以在使用hyperopt求解最佳参数(test = True)或训练并返回最终模型(test = False)之间进行切换。编译模型时,也可能不调整loss_weights参数。因为我们有多个辅助输出,所以我们需要告诉TensorFlow在确定如何调整模型以提高准确性时给每个加权多少。我个人喜欢对辅助预测(总计)给予50%的权重,对目标预测给予50%的权重。有些人可能会觉得给辅助预测赋予任何权重是很奇怪的,因为它们在损失计算步骤中被丢弃了。问题是,如果我们不给它们赋予任何权重,模型多半会忽略它们,从而妨碍它学习有用的特征。
现在,我们只需要使用上面定义的参数来运行final_model:
history, model = final_model(params,test=False)
现在我们有了一个经过训练的模型,我们可以使用keras get_layer()函数选择性地提取要在其他模型中使用的新特性。如果这能引起足够的兴趣,我将把这一步留到以后的文章中讨论。
结果
“它最后战胜了XGBoost,这与传统观点不同,因为传统观点认为梯度增强模型更适合结构化数据集。”
你可以想象,这是一个计算上昂贵的模型训练。但是好消息是它通常会在比典型MLP少得多的试验中收敛到一个更准确的答案。如果你把不花几周时间在繁琐的工程特性上节省下来的时间也算进去,那就快得多了。此外,预测延迟足够小,可以使其成为一个生产模型(与典型的Kaggle 50+元模型相反)。如果你提取特征并用它们重新训练一个神经网络,那么它会变得更快。
问题仍然存在,它是准确的吗?在我应用这个模型的每一个案例中,它都是最准确的。它始终战胜了XGBoost,让我们看看它在这个问题上做得如何!
我测试了三种不同的模型:
- XGBoost
- 带有嵌入的标准MLP
- 上面训练的自动特征模型
对于自动特征模型,我使用hyperopt进行了20个试验,以试验不同的网络规模。对于这两个对比的模型,由于它们的训练时间较快,因此我进行了40次试验。结果如下:
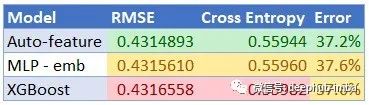
正如预期的那样,我们的自动特征模型表现最好。需要记住的一件事是,这个简单的数据集没有足够的有用信息来允许任何模型比边际收益更好。当我处理数百个特征的海量数据集时,自动功能模型将领先XGBoost击败5–10%也是有可能的。
作者:Michael Malin
原文地址:https://towardsdatascience.com/automated-feature-engineering-using-neural-networks-5310d6d4280a
deephub翻译组