
摘要:2024年2月,UC Berkeley开源了大世界模型(LWM),支持1M token(与Gemini1.5持平)、1h视频问答、及视频图片生成,相当于开源版****Gemini1.5pro。
一、前言
目前,在paperswithcode网站研究趋势榜单中排名第一。

大世界模型(LWM)是一种通用的多模态自回归模型。它使用RingAttention在各种长视频和书籍的大型数据集上进行训练,可以执行语言,图像和视频理解和生成。
大世界模型(LWM)具备的能力:
- LWM可以与图像聊天。
- LWM可以跨1M上下文检索事实,具有高准确性。
- LWM可以在1小时的YouTube视频上回答问题。
- LWM可以从文本生成视频和图像。
图像问答是大部分商业和开源VLM(Vison-Language Model)模型的通用能力,如GPT-4V、Qwen-VL。1M的上下文窗口目前与与Gemini1.5持平,超越了大部分VLM,也为视频类理解和生成能力的融入铺平道路。同时,能做到在长视频上的问答、并具备图像和视频的生成,可以说UC伯克利的这项工作直接与VLM统一架构标杆的商用产品谷歌Gemini对标,并且开源。
二、模型架构
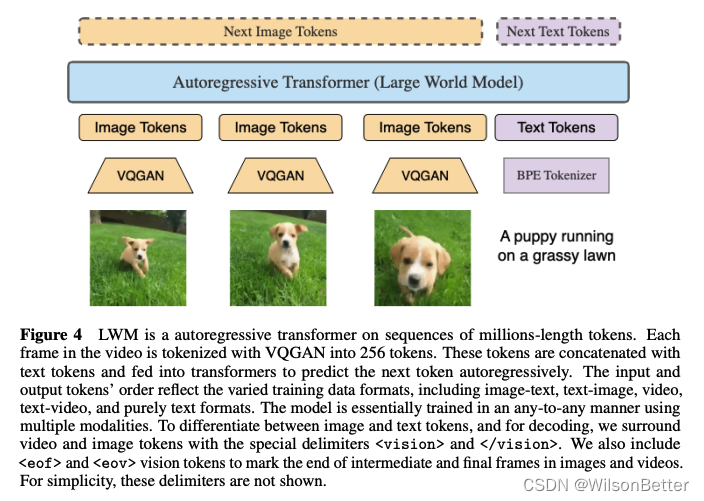
LLaMA和RingAttention。LWM采用具有高达1M tokens上下文序列的自回归transformer模型架构,基于Llama2-7B和RingAttention。
VQGAN和BPE编码器。图片和视频帧采用VQGAN编码为视觉tokens(对于图片,将256x256输入图像转换16x16=256个tokens。对于视频,通过每帧应用VQGAN并将代码连接在一起),与经过BPE编码后的文本tokens结合,统一送入LWM中,自回归方式进行token预测支持理解和生成任务。
Any-to-Any多模态任务训练。该模型基本上是使用多种模态以任意对任意(any-to-any)的方式进行训练的。输入和输出tokens的顺序反映了不同的训练数据格式,包括图像-文本、文本-图像、视频问答、文本-视频和纯文本问答等格式。为了区分图像和文本标记,并进行解码,我们用特殊的分隔符<vision>和</vision>包围视频和图像标记。我们还采用<eof>和<eov>视觉标记,以标记图像和视频中的中间帧和最后帧的结束。
CFG图像视频生成。LWM也可以从文本生成图像和视频。LWM在logits上使用CFG(classifier-free guidance)进行自回归采样,CFG在文生图扩散模型如SD、DALLE2、Imagen中广泛使用,原始噪声预测被有、无条件噪声预测的线性组合代替,可进一步提升生成质量。在LWM中对于无条件分支,我们用<bos><vision>初始化每个序列。
三、核心技术
环注意力机制:RingAttention
为了增强LWM的长文本处理能力,开发者应用了RingAttention机制。RingAttention是该团队去年提出的一种窗口扩增方式,《Ring Attention with Blockwise Transformers for Near-Infinite Context》论文入选了ICLR 2024。
RingAttention运用了“分而治之”的思想,将长文本分成多个块,用多个计算设备做序列并行处理,然后再进行叠加,理论上允许模型扩展到无限长的上下文。由于transformer自注意力架构中,内存与输入长度呈二次方关系。RingAttention思路是先把SA(Self-Attention)和FFN(前向反馈网络)计算分块****Block到不同设备上,借鉴百度提出的分布式训练技术——环形模式(RingAllReduce),在不同设备上分布式计算transformer块,解决上下文的扩展瓶颈。
在LWM中,RingAttention还与FlashAttention结合使用,并通过Pallas框架进行优化,从而提高性能。
RingAttention详细解析
为了能够拓展Transformer可支持的序列长度。作者提出以分块方式执行自注意力和前馈网络计算,跨多个主机设备分布序列维度,从而实现并发计算和通信,由于该方法将环中主机设备之间的键值块通信与块计算重叠,因此将其命名:环注意(Ring Attention)。
具体地,该方法在主机设备之间构建注意力计算块的外循环,每个主机设备具有一个查询块,并通过键值块遍历主机设备环,以逐块的方式进行注意力和前馈网络计算。当计算注意力时,每个主机将键值块发送到下一个主机,同时从前一个主机接收键值块。这里作者使用与原始 Transformer 相同的模型架构,但重新组织了计算。具体如下图所示:
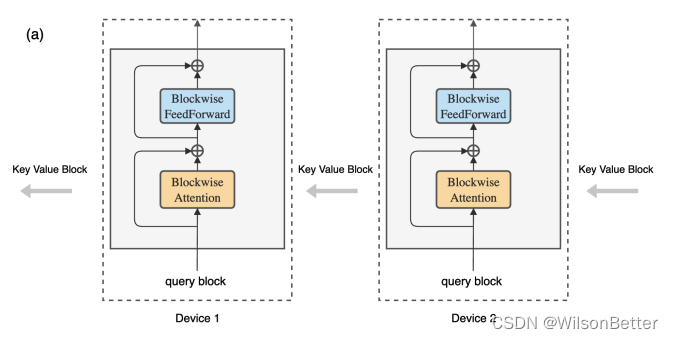
对于内循环,每个设备计算其各自的块式注意力和前馈操作。在内循环期间,每个设备将用于块式计算的键值块的副本发送到环中的下一个设备,同时从前一个设备接收键值块。由于块计算比块传输需要更长的时间,与标准Transformer相比,此过程不会增加开销。具体如下图所示:

使用RingAttention,每个设备的内存需求与块大小成线性关系,而与原始输入序列长度无关,这也消除了各个设备施加的内存限制。其中,b为批大小,h为隐藏维数,n为头数,s为序列长度,c为块大小。

四、训练过程
训练分两阶段:
- 阶段一:渐进式的纯文本训练
- 阶段二:多模态训练
第一阶段的目标是建立一个能够处理长文本序列的语言模型,以理解复杂的文档和长文本内容。为实现这一目的,研究人员采取了渐进式的训练方式,使用总计33B Token、由图书内容组成的Books3数据集,从32k开始训练,逐步将窗口扩增至1M。

第二阶段则是将视觉信息(如图像和视频)整合到模型中,以提高对多模态数据的理解能力。在此阶段,研究人员对第一阶段的LWM-Text模型进行了架构修改,以支持视觉输入。他们使用VQGAN将图像和视频帧转换为token,并与文本结合进行训练。

这一阶段同样采用循序渐进的训练方法, LWM首先在文本-*图像数据集上进行训练,然后*扩展到文本**-**视频数据集,且视频帧数逐步增多。
理解/生成任务混合训练。在训练过程中,模型还会随机交换文本和视觉数据的顺序,以学习文本-*图像生成、图像理解、*文本**-**视频生成和视频理解等多种任务。
五、效果与性能
这里主要关注多模态相关能力。
1、论文中样例测试
视频理解问答:1小时时长视频问答,在自己制作的视频和问题上准确回答,而GPT-4V、GeminiPro、Video-LLaVA等标杆产品均回答错误。
穿霸王龙服饰的人骑的什么车?LWM正确回答motorcycle。

图像视频生成:

2、论文中benchmark结果分析
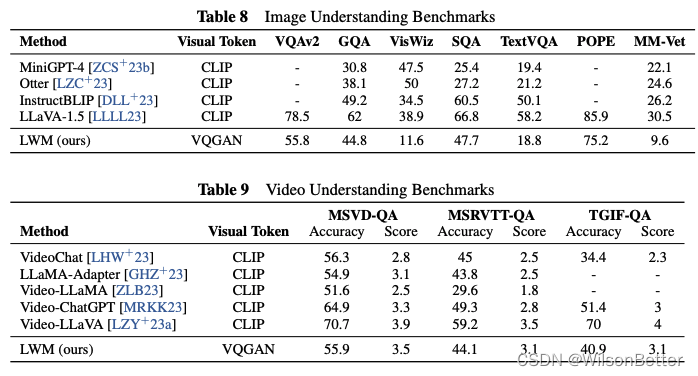
图像通用问答(VQA):在VQAv2测评集上,LWM 55.8,CogAgent 83.7,LLaVA-1.6(Vicuna-7B版本)81.8,差距很大,这个成绩根本进不了VLM第一梯队。
富文本图像问答(Text-rich VQA):论文仅给出TextVQA任务测试结果,LWM 18.8,开源标杆CogAgent 76.1,差距巨大。DocVQA、ChartQA等任务没有进行测试。一方面,训练中并没有针对此类任务数据专项提升,另一方面,与CogAgent比,LWM图像输入分辨率偏低,没有ViT及CA等规模化视觉处理机制,也造成在复杂的富文本图像理解任务上天然没有优势。

整体看,LWM当前版本在图像和视频理解问答上的表现并不出众、不在第一梯队。论文中对此进行解释。“我们的模型在基线中表现平均,表现逊于SOTA模型。我们假设这可能是由于有限的文本图像和文本视频对齐训练,而基线利用了经过更广泛、大规模数据训练的CLIP视觉骨干。相比之下,我们的模型使用VQGAN tokens,需要从头开始学习文本-图像对齐,并且由于VQGAN重建图像的文本能力较差,通常难以完成OCR任务。然而,我们相信,我们的模型将是未来基于VQ的视觉语言模型架构的一个很有前途的方向,并且可以通过更严格的训练和学习更好的tokenizers来提升表现。”
六、验证
LWM官方未提供演示系统,需自己搭建(据官方issue:32KText版约1xA100 80G,512KText版约8xA100 80G,1M多模态版至少8个A100 80G且,基于JAX),后续进行本地实际部署验证,并给出多模态能力的实测结果。

附录
- 《WORLD MODEL ON MILLION-LENGTH VIDEO AND LANGUAGE WITH RINGATTENTION》,https://arxiv.org/pdf/2402.08268v1.pdf
- 《Ring Attention with Blockwise Transformers for Near-Infinite Context》,https://browse.arxiv.org/pdf/2310.01889.pdf
- LWM代码:GitHub - LargeWorldModel/LWM
版权归原作者 WilsonBetter 所有, 如有侵权,请联系我们删除。