
最近在学习文本分类,读了很多博主的文章,要么已经严重过时(还在一个劲介绍SVM、贝叶斯),要么就是机器翻译的别人的英文论文,几乎看遍全文,竟然没有一篇能看的综述,花了一个月时间,参考了很多文献,特此写下此文。
思维导图
https://www.processon.com/mindmap/61888043e401fd453a21e978
文本分类简介
文本分类(Text Classification 或 Text Categorization,TC),又称自动文本分类(Automatic Text Categorization),是指计算机将载有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程,实现这一过程的算法模型叫做分类器。文本分类问题算是自然语言处理领域中一个非常经典的问题。
根据预定义的类别不同,文本分类分两种:二分类和多分类,多分类可以通过二分类来实现。
从文本的标注类别上来讲,文本分类又可以分为单标签和多标签,因为很多文本同时可以关联到多个类别。
文本分类词云一览
这张图真的是太棒了:

文本分类历史
文本分类最初是通过专家规则(Pattern)进行分类,利用知识工程建立专家系统,这样做的好处是比较直观地解决了问题,但费时费力,覆盖的范围和准确率都有限。
后来伴随着统计学习方法的发展,特别是 90 年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典做法,也即特征工程 + 浅层分类模型。又分为传统机器学习方法和深度学习文本分类方法。
文本分类应用场景
文本分类的主流应用场景有:
- 情感分析:sentiment analysis ( SA)
- 话题标记:topic labeling(TL)
- 新闻分类:news classification (NC)
- 问答系统:question answering(QA)
- 对话行为分类:dialog act classification (DAC)
- 自然语言推理:natural language inference (NLD),
- 关系分类:relation classification (RC)
- 事件预测:event prediction (EP)
🌟 文本分类流程
这里讨论的文本分类流程指的是基于机器学习/深度学习的文本分类,专家系统已经基本上淘汰了。
文本分类系统流程如下图所示:
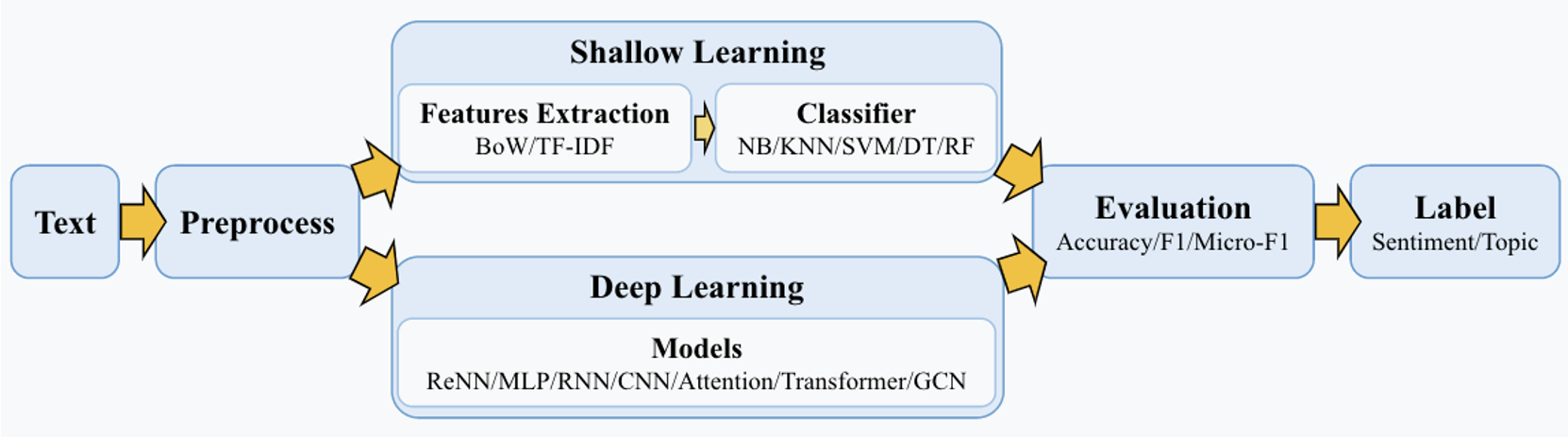
其中,先具体来看浅层学习(Shallow Learning)的具体过程,如下:
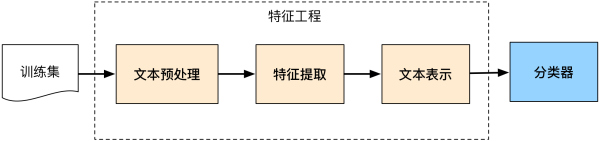
如果不考虑训练集,整个文本分类问题就拆分成了特征工程和分类器两部分。其实最后还应该有一个性能检验的步骤来评估模型。
获取训练集
数据采集是文本挖掘的基础,主要包括爬虫技术和页面处理两种方法。先通过网络爬虫获取到原始 web 网页数据,然后通过页面处理去除掉多余的页面噪声,将 Web 页面转化成为纯净统一的文本格式和元数据格式。
文本特征工程(针对浅层学习)
文本预处理
文本要转化成计算机可以处理的数据结构,就需要将文本切分成构成文本的语义单元。这些语义单元可以是句子、短语、词语或单个的字。
通常无论对于中文还是英文文本,统一将最小语义单元称为“词组”。
英文文本预处理
英文文本的处理相对简单,因为单词之间有空格或标点符号隔开。如果不考虑短语,仅以单词作为唯一的语义单元的话,只需要分割单词,去除标点符号、空格等。
英文还需要考虑的一个问题是大小写转换,一般认为大小写意义是相同的,这就要求将所有单词都转换成小写/大写。
英文文本预处理更为重要的问题是词根的还原,或称词干提取。词根还原的任务就是将属于同一个词干(Stem)的派生词进行归类转化为统一形式。
例如,把“computed”, “computer”, “computing”可以转化为其词干 “compute”。通过词干还原实现使用一个词来代替一类中其他派生词,可以进一步增加类别与文档中的词之间匹配度。词根还原可以针对所有词进行,也可以针对少部分词进行。
因为大家都是中国人,所以主要讨论的还是中文文本预处理方法。
中文文本预处理
和英文文本处理分类相比,中文文本预处理是更为重要和关键,相对于英文来说,中文的文本处理相对复杂。中文的字与字之间没有间隔,并且单个汉字具有的意义弱于词组。一般认为中文词语为最小的语义单元,词语可以由一个或多个汉字组成。所以中文文本处理的第一步就是分词。
中文文本处理中主要包括文本分词和去停用词两个阶段。
分词
研究表明中文文本特征粒度为词粒度远远好于字粒度,因为大部分分类算法不考虑词序信息,如果基于字粒度就会损失了过多的 n-gram 信息。
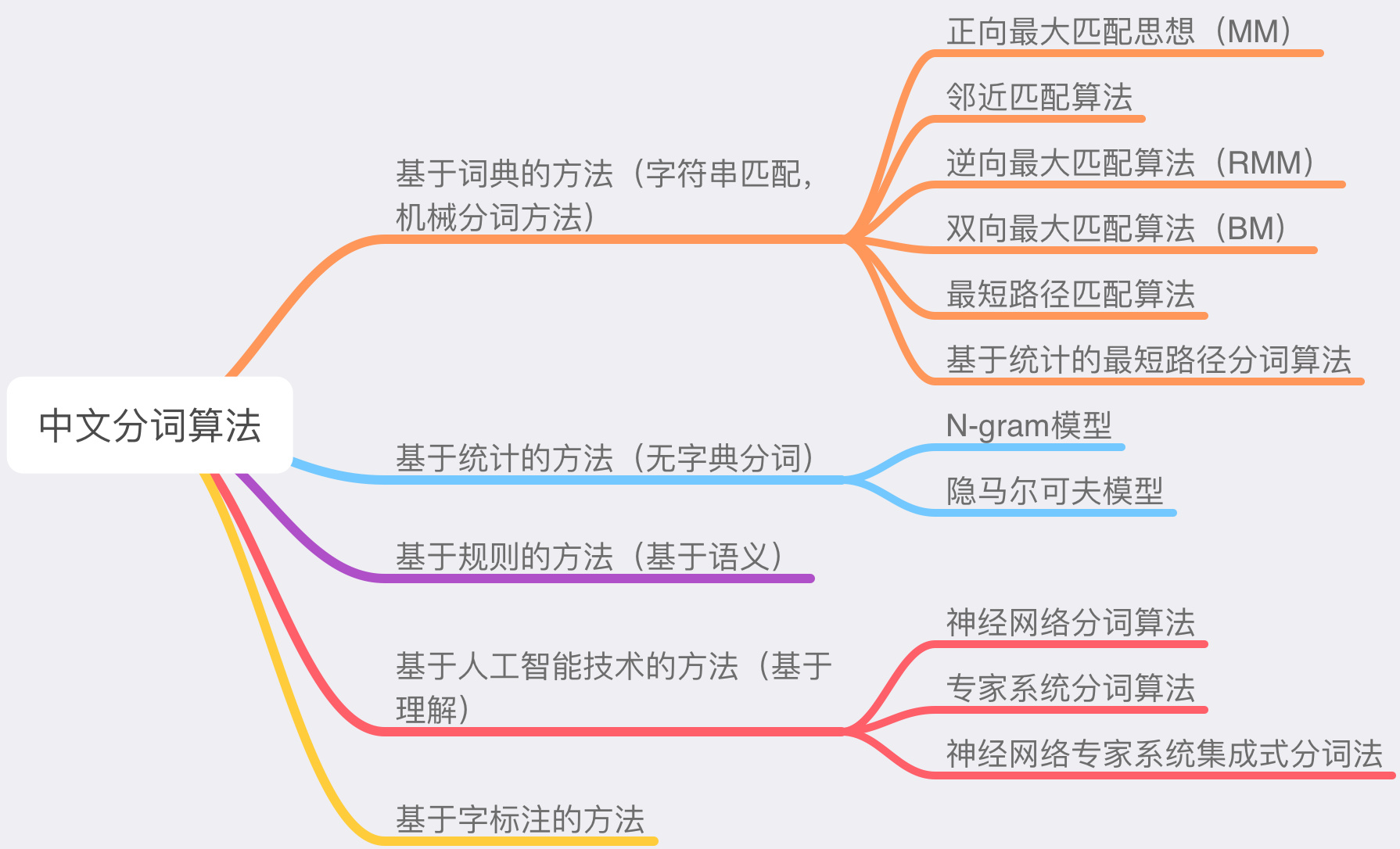
目前常用的中文分词算法可分为三大类:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。
- 基于词典的中文分词(字符串匹配) 核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。字典,切分规则和匹配顺序是核心。
- 基于统计的中文分词方法 统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
- 基于理解的分词方法 基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。 它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。 这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
去停用词
“在自然语言中,很多字词是没有实际意义的,比如:【的】【了】【得】等,因此要将其剔除。”
停用词(Stop Word)是一类既普遍存在又不具有明显的意义的词,在英文中例如:“the”、“of”、“for”、“with”、“to”等,在中文中例如:“啊”、“了”、“并且”、“因此”等。
由于这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。停用词去除组件的任务比较简单,只需从停用词表中剔除定义为停用词的常用词就可以了。
文本特征提取(特征选择)
nlp 任务非常重要的一步就是特征提取(对应机器学习中的特征工程步骤,也叫做降维),在向量空间模型中,文本的特征包括字、词组、短语等多种元素表示 。在文本数据集上一般含有数万甚至数十万个不同的词组,如此庞大的词组构成的向量规模惊人,计算机运算非常困难。
进行特征选择,对文本分类具有重要的意义。特征选择就是要想办法选出那些最能表征文本含义的词组元素 。特征选择不仅可以降低问题的规模,还有助于分类性能的改善,选取不同的特征对文本分类系统的性能有非常重要的影响。
向量空间模型文本表示方法的特征提取分为特征项选择和特征权重计算两部分。但实际中区分的并没有那么严格。
特征选择的基本思路是根据某个评价指标独立地对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有**文档频率、互信息、信息增益、
X
2
X^2
X2 统计量**等。
“特征工程详细介绍及 sklearn 实战”
#词袋模型#
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档 。可以这样理解,把整个文档集的所有出现的词都丢进袋子里面,然后 无序去重 地排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档 。例如:
句子1:我/有/一个/苹果
句子2:我/明天/去/一个/地方
句子3:你/到/一个/地方
句子4:我/有/我/最爱的/你
把所有词丢进一个袋子:
我,有,一个,苹果,明天,去,地方,你,到,最爱的
。这 4 句话中总共出现了这 10 个词。
现在我们建立一个无序列表:
我,有,一个,苹果,明天,去,地方,你,到,最爱的
。并根据每个句子中词语出现的次数来表示每个句子。

总结一下特征:
- 句子 1 特征: ( 1 , 1 , 1 , 1 , 0 , 0 , 0 , 0 , 0 , 0 )
- 句子 2 特征: ( 1 , 0 , 1 , 0 , 1 , 1 , 1 , 0 , 0 , 0 )
- 句子 3 特征: ( 0 , 0 , 1 , 0 , 0 , 0 , 1 , 1 , 1 , 0 )
- 句子 4 特征: ( 2 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 )
词袋模型生成的特征叫做词袋特征,该特征的缺点是词的维度太大,导致计算困难,且每个文档包含的词语远远数少于词典的总词语数,导致文档稀疏。仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑。
#TF-IDF 模型#
这种模型主要是用词汇的统计特征来作为特征集,TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成,利用 TF 和 IDF 两个参数来表示词语在文本中的重要程度。TF 和 IDF 都很好理解,我们直接来说一下他们的计算公式:
1. TF
TF 是词频,指的是一个词语在一个文档中出现的频率,一般情况下,每一个文档中出现的词语的次数越多词语的重要性更大(当然要先去除停用词),例如 BOW 模型直接用出现次数来表示特征值。
问题在于在 长文档中的词语次数普遍比短文档中的次数多,导致特征值偏向差异情况,所以不能仅仅使用词频作为特征。
TF 体现的是词语在文档内部的重要性。
t
f
i
j
=
n
i
j
∑
k
n
k
j
tf_{ij} = \frac{n_{ij}}{\sum_{k}n_{kj}}
tfij=∑knkjnij
其中分子
n
i
j
n_{ij}
nij 表示词
i
i
i 在文档
j
j
j 中出现的频次。分母则是文档
j
j
j 中所有词频次的总和,也就是文档
j
j
j 中所有词的个数。举个例子:
句子1:上帝/是/一个/女孩
句子2:桌子/上/有/一个/苹果
句子3:小明/是/老师
句子4:我/有/我/最喜欢/的/
每个句子中词语的 TF :

2. IDF
i
d
f
i
=
l
o
g
(
∣
D
∣
1
+
∣
D
i
∣
)
idf_{i} = log\left ( \frac{\left | D \right |}{1+\left | D_{i} \right |} \right )
idfi=log(1+∣Di∣∣D∣)
其中
∣
D
∣
\left | D \right |
∣D∣ 代表**文档的总数**,分母部分
∣
D
i
∣
\left | D_{i} \right |
∣Di∣ 则是代表**文档集中含有
i
i
i 词的文档数**。
原始公式是分母没有
+
1
+1
+1 的,这里
+
1
+1
+1 是采用了**拉普拉斯平滑**,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。
IDF 是体现词语在文档间的重要性。如果某个词语仅出现在极少数的文档中,说明该词语对于文档的区别性强,对应的特征值高,很明显
∣
D
i
∣
\left | D_{i} \right |
∣Di∣ 值越小,IDF 的值越大。
用 IDF 计算公式计算上面句子中每个词的 IDF 值:

TF-IDF 方法的主要思路是一个词在当前类别的重要度与在当前类别内的词频成正比,与所有类别出现的次数成反比。可见 TF 和 IDF 一个关注文档内部的重要性,一个关注文档外部的重要性,最后结合两者,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值。即:
t
f
∗
i
d
f
(
i
,
j
)
=
t
f
i
j
∗
i
d
f
i
=
n
i
j
∑
k
n
k
j
∗
l
o
g
(
∣
D
∣
1
+
∣
D
i
∣
)
tf*idf(i,j)=tf_{ij}*idf_{i}= \frac{n_{ij}}{\sum_{k}n_{kj}} *log\left ( \frac{\left | D \right |}{1+\left | D_{i} \right |} \right )
tf∗idf(i,j)=tfij∗idfi=∑knkjnij∗log(1+∣Di∣∣D∣)
上面每个句子中,词语的 TF-IDF 值:

把每个句子中每个词的 TF-IDF 值 添加到向量表示出来就是每个句子的 TF-IDF 特征。
例如句子 1 的特征:
(
0.25
∗
l
o
g
(
2
)
,
0.25
∗
l
o
g
(
1.33
)
,
0.25
∗
l
o
g
(
1.33
)
,
0.25
∗
l
o
g
(
2
)
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
)
( 0.25 * log(2) , 0.25 * log(1.33) , 0.25 * log(1.33) , 0.25 * log(2) , 0 ,0 ,0 ,0 , 0 , 0 , 0 , 0 , 0 )
(0.25∗log(2),0.25∗log(1.33),0.25∗log(1.33),0.25∗log(2),0,0,0,0,0,0,0,0,0)
卡方特征选择(基于卡方检验的特征选择)
对于文本分类的词向量中许多常用单词对分类决策的帮助不大,比如汉语的一些虚词和标点符号等,也可能有一些单词在所有类别的文档中均匀出现。
为了消除这些单词的影响,一方面可以用停用词表,另一方面可以用卡方非参数检验(Chi-squaredtest,X2)来过滤掉与类别相关程度不高的词语。
卡方检验(χ2 test),是一种常用的特征选择方法,尤其是在生物和金融领域。χ2 用来描述两个事件的独立性或者说描述实际观察值与期望值的偏离程度。χ2 值越大,则表明实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。
特征选择之卡方检验
基于词向量的特征提取模型
该模型通常基于大量的文本语料库,通过类似神经网络模型训练,将每个词语映射成一个定维度的向量,维度在几十维到百维之间,每个向量就代表着这个词语,词语的语义和语法相似性和通过向量之间的相似度来判断。
常用的 word2vec 主要是 CBOW 和 skip-gram 两种模型,由于这两个模型实际上就是一个三层的深度神经网络,其实 NNLM 的升级,去掉了隐藏层,由输入层、投影层、输出层三层构成,简化了模型和提升了模型的训练速度,其在时间效率上、语法语义表达上效果明显都变好。word2vec 通过训练大量的语料最终用定维度的向量来表示每个词语,词语之间语义和语法相似度都可以通过向量的相似度来表示。
[NLP] 秒懂词向量 Word2vec 的本质
一文看懂 word2vec
文本表示
文本是一种非结构化的数据信息,是不可以直接被计算的。文本表示的作用就是将这些非结构化的信息转化为计算机可以理解的结构化的信息 ,这样就可以针对文本信息做计算,来完成后面的任务。

文本表示的方法有很多种,传统做法常用上面提到词袋模型(BOW, Bag Of Words)或向量空间模型(CSM, Vector Space Model),除此之外还有基于词嵌入的的独热编码(one-hot representation)、整数编码、词嵌入(wordembeding)等方法,我们简单说几种重要的:
- 词袋模型 上面已经提到过,就是把所有文本的词汇都放在一个特别特别大的向量中,一个文本有该词就标为 1,非常原始且缺点很多,已经基本淘汰。
- 向量空间模型 是目前文本处理应用领域使用最多且效果较好的文本表示法,简单说就是在词向量中给每个词一定的权重(这个权重可以是简单的词频,也可以是 TF-IDF 等等,非常灵活)。定义:- 给定文档 D = ( t 1 , w 1 ; t 2 , w 2 ; . . . ; t n , w n ) D=(t_1,w_1;t2,w_2;...;t_n,w_n) D=(t1,w1;t2,w2;...;tn,wn) ,其中 t k ( 1 ⩽ k ⩽ n ) t_k(1\leqslant k\leqslant n) tk(1⩽k⩽n) 是组成文本的词元素, w k w_k wk 是词元素 t k t_k tk 的权重,可以理解为在文本中的某种重要程度。性质,向量空间模型满足以下两条性质::- 互异性:各词组元素间属于集合元素关系,即若 i ≠ j i≠j i=j ,则 t i ≠ t j t_i~ ≠t_j ti =tj- 无关性:各词组元素间无顺序关系和相互联系,即对于文本 D D D,若 i ≠ j i≠j i=j ,交换 t i t_i ti 与 t j t_j tj 的位置,仍表示文档 D D D。词组与词组之间不含任何关系。可以把词组 t 1 , t 2 , … , t n t_1 , t_2 ,…,t_n t1,t2,…,tn 看成 n 维坐标空间,而权重 w 1 , w 2 , … , w n w_1 , w_2 ,…,w_n w1,w2,…,wn 为相应坐标值。因此,一个文本可以表示为一个 n 维向量。
文本表示这一步往往同上一步(文本特征提取)联系非常紧密,实际应用中往往一并完成了,所以你会看到有些方法同时并属于两者。
分类器(分类算法模型)
文本分类方法模型主要分为两个大类,一类是传统的机器学习方法(具体可以再分为四类),另一类是新兴的深度学习模型。由于每个算法其实都非常复杂,在此我们仅做简单介绍,建议需要使用时一定要再深入学习理解。
文本分类算法历史
从 1961 到 2020 文本分类算法的发展历史:
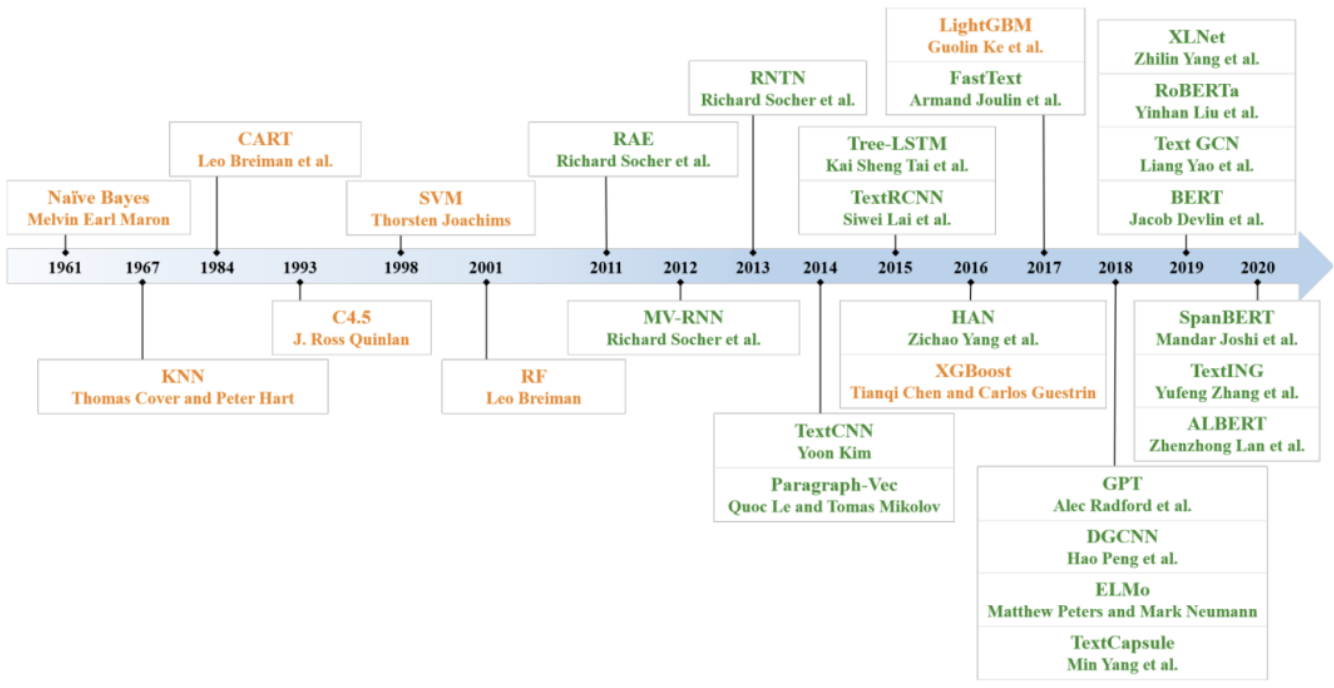
图上黄色代表浅层学习模型,绿色代表深层学习模型。可以看到,从 1960 年代到 2010 年代,基于浅层学习的文本分类模型占主导地位。自 2010 年代以来,文本分类已逐渐从浅层学习模型变为深层学习模型。
传统机器学习方法(浅层学习模型)
- 基于规则的模型 基于规则的分类模型相对简单,易于实现。它在特定领域的分类往往能够取得较好的效果。相对于其它分类模型来说,基于规则的分类模型的优点就是时间复杂度低、运算速度快。在基于规则的分类模型中,使用许多条规则来表述类别。类别规则可以通过领域专家定义,也可以通过计算机学习获得。 决策树就是一种基于训练学习方法获取分类规则的常见分类模型,它建立对象属性与对象值之间的一种映射。通过构造决策树来对未标注文本进行分类判别。常用的决策树方法包括 CART 算法、ID3、C4.5、CHAID 等。 决策树的构建过程一般是自上而下的,决策树可以是二叉树也可以是多叉树,剪枝的方法也有多种,但是具有一致目标,即对目标文本集进行最优分割。

- 基于概率的模型 假设未标注文档为 d d d ,类别集合为 C = { c 1 , c 2 , … , c m } C={c_1 ,c_2 ,…,c_m} C={c1,c2,…,cm} ,概率模型分类是对 1 ≤ i ≤ n 1≤i≤n 1≤i≤n 求条件概率模型 P ( c i ∣ d ) P(c_i |d) P(ci∣d)(即 d d d 属于 c i c_i ci 类别的概率) ,将与文档 d d d 条件概率最大的那个类别作为该文档的输出类别。其中朴素贝叶斯分类器(naive Bayes)是应用最为广泛且最简单常用的一种概率分类模型。朴素贝叶斯法基于贝叶斯定理将联合概率转化为条件概率,然后利用特征条件独立假设简化条件概率的计算。
 朴素贝叶斯分类的基本思想是利用词组与类别的联合概率来估计给定文档的类别概率。概率 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 计算相对复杂,它首先基于一个贝叶斯假设:文档 d d d 为词组元素的集合,集合中词组(元素)之间相互独立。由于前面的步骤使得文档表示简化了,所以这也就是朴素的由来之一。事实上,词组之间并不是相互独立的。虽然这是一种假设独立性,但是朴素贝叶斯还是能够在分类任务中表现出很好的分类效果和鲁棒性。这一假设简化了联合概率的计算,它允许条件概率的乘积来表示联合概率。 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 的计算式: P ( d ∣ c i ) = Π k = 1 n P ( t k ∣ c i ) P\left( d|c_{i}\right) =\Pi^{n}{k=1} P\left( t{k}|c_{i}\right) P(d∣ci)=Πk=1nP(tk∣ci)其中, t k t_k tk 表示含有 n n n 项词组的词组表 v i v_i vi 中的一个词组。因此,估计概率 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 转化为了估计词组表 v v v 中的每一个词组在每一个类别下的概率 P ( t k ∣ c i ) P(t_k|c_i) P(tk∣ci) 。 概率的估计与分类结果非常依赖于事件空间的选择,下面简单介绍两种事件空间模型,并说明相应的 P ( t k ∣ c i ) P(t_k |c_i) P(tk∣ci) 是如何估计的。1. 多重伯努利(Multiple-Bernoulli)事件空间是一种布尔独立模型的事件空间,为每一个词组 tk 建立一个二值随机变量,最简单的方式就是使用最大似然估计来估计概率。但缺点在于多重伯努利模型仅仅考虑词组是否出现,而没有考虑出现的多少,而词频也是一个重要分类信息。下面介绍加入词频信息的多项式模型。2. 多项式(Multinomial)事件空间与多重伯努利事件空间类似,但是多项式事件空间假设词组的出现次数是零次或多次,而不是出现与否。实际应用中,多项式模型已经表明优于多重伯努利模型。
朴素贝叶斯分类的基本思想是利用词组与类别的联合概率来估计给定文档的类别概率。概率 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 计算相对复杂,它首先基于一个贝叶斯假设:文档 d d d 为词组元素的集合,集合中词组(元素)之间相互独立。由于前面的步骤使得文档表示简化了,所以这也就是朴素的由来之一。事实上,词组之间并不是相互独立的。虽然这是一种假设独立性,但是朴素贝叶斯还是能够在分类任务中表现出很好的分类效果和鲁棒性。这一假设简化了联合概率的计算,它允许条件概率的乘积来表示联合概率。 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 的计算式: P ( d ∣ c i ) = Π k = 1 n P ( t k ∣ c i ) P\left( d|c_{i}\right) =\Pi^{n}{k=1} P\left( t{k}|c_{i}\right) P(d∣ci)=Πk=1nP(tk∣ci)其中, t k t_k tk 表示含有 n n n 项词组的词组表 v i v_i vi 中的一个词组。因此,估计概率 P ( d ∣ c i ) P(d|c_i) P(d∣ci) 转化为了估计词组表 v v v 中的每一个词组在每一个类别下的概率 P ( t k ∣ c i ) P(t_k|c_i) P(tk∣ci) 。 概率的估计与分类结果非常依赖于事件空间的选择,下面简单介绍两种事件空间模型,并说明相应的 P ( t k ∣ c i ) P(t_k |c_i) P(tk∣ci) 是如何估计的。1. 多重伯努利(Multiple-Bernoulli)事件空间是一种布尔独立模型的事件空间,为每一个词组 tk 建立一个二值随机变量,最简单的方式就是使用最大似然估计来估计概率。但缺点在于多重伯努利模型仅仅考虑词组是否出现,而没有考虑出现的多少,而词频也是一个重要分类信息。下面介绍加入词频信息的多项式模型。2. 多项式(Multinomial)事件空间与多重伯努利事件空间类似,但是多项式事件空间假设词组的出现次数是零次或多次,而不是出现与否。实际应用中,多项式模型已经表明优于多重伯努利模型。 - 基于几何学的模型 使用向量空间模型表示文本,文本就被表示为一个多维的向量,那么它就是多维空间的一个点。通过几何学原理构建一个超平面将不属于同一个类别的文本区分开。最典型的基于几何学原理的分类器是"支持向量机"(SVM),其分类效果较为不错,几乎可以说是传统机器学习算法中最好的了。
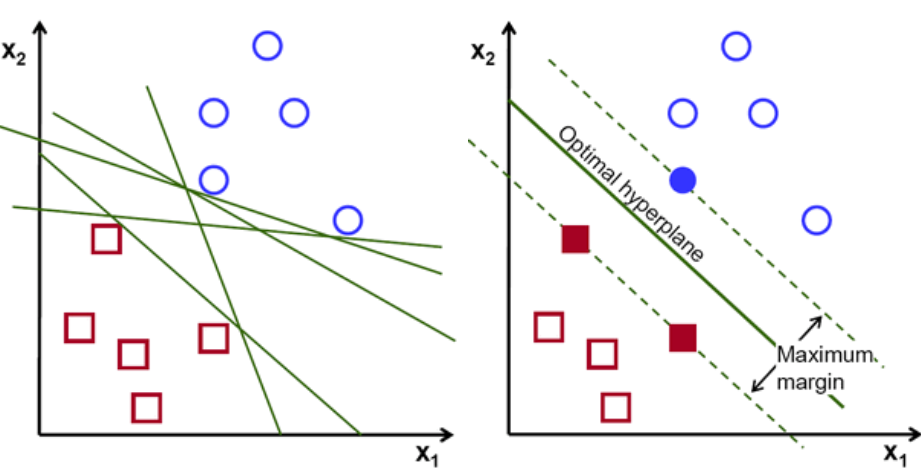 SVM 之所以能够取得比较好的分类效果,其优点在于:- SVM 是一种针对有限样本条件下的分类算法,其目标是得到当前训练集下的最优解而不是样本数趋于无穷大时的最优值,该算法最终将问题转化成二次线性规划寻求最优解问题。从理论上来讲,它得到的是全局最优解,能够避免局部极值问题。- 该方法将实际问题通过核函数技巧将线性不可分空间映射到高维线性可分空间,在高维空间中构造线性决策函数来实现原线性不可分空间的决策函数。这保证了 SVM 具有较好的推广能力,计算的复杂度不再取决于空间维数,而是取决于训练集样本数量。- SVM 方法能够很好的处理稀疏数据,更好的捕捉了数据的内在特征,准确率较高。SVM 虽然有许多优点,但是固有的缺点是不可避免的。其缺点包括:- SVM 算法时间和空间复杂度较高,随着训练样本数和类别的增加,分类时间和空间代价很高。- 核函数空间变换会增加训练集空间的维数,使得 SVM 对时间和空间需求加大,又进一步降低了分类的效率。- SVM 算法一般含有较多参数,并且参数随着训练样本的不同,呈现较大的差异,调整参数以获得最优分类效果相对困难。而且参数的不同对分类结果的显示出较大的差异性。
SVM 之所以能够取得比较好的分类效果,其优点在于:- SVM 是一种针对有限样本条件下的分类算法,其目标是得到当前训练集下的最优解而不是样本数趋于无穷大时的最优值,该算法最终将问题转化成二次线性规划寻求最优解问题。从理论上来讲,它得到的是全局最优解,能够避免局部极值问题。- 该方法将实际问题通过核函数技巧将线性不可分空间映射到高维线性可分空间,在高维空间中构造线性决策函数来实现原线性不可分空间的决策函数。这保证了 SVM 具有较好的推广能力,计算的复杂度不再取决于空间维数,而是取决于训练集样本数量。- SVM 方法能够很好的处理稀疏数据,更好的捕捉了数据的内在特征,准确率较高。SVM 虽然有许多优点,但是固有的缺点是不可避免的。其缺点包括:- SVM 算法时间和空间复杂度较高,随着训练样本数和类别的增加,分类时间和空间代价很高。- 核函数空间变换会增加训练集空间的维数,使得 SVM 对时间和空间需求加大,又进一步降低了分类的效率。- SVM 算法一般含有较多参数,并且参数随着训练样本的不同,呈现较大的差异,调整参数以获得最优分类效果相对困难。而且参数的不同对分类结果的显示出较大的差异性。 - 基于统计的模型 基于统计的机器学习方法已经成为自然语言研究领域里面的一个主流研究方法。事实上无论是朴素贝叶斯分类模型,还是支持向量机分类模型,也都采用了统计的方式。文本分类算法中一种最典型的基于统计的分类模型就是 k 近邻(k-Nearest Neighbor,kNN)模型,是比较好的文本分类算法之一。
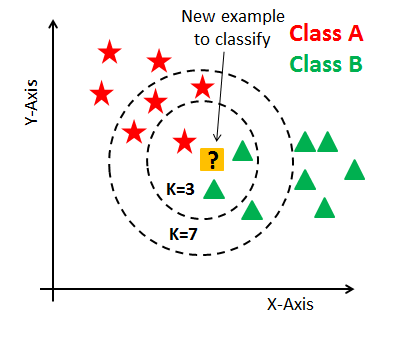 kNN 分类模型的主要思想:通过给定一个未标注文档 d d d,分类系统在训练集中查找与它距离最接近的 k k k 篇相邻(相似或相同)标注文档,然后根据这 k k k 篇邻近文档的分类标注来确定文档 d d d 的类别。分类实现过程:1. 将训练集样本转化为向量空间模型表示形式并计算每一特征的权重2. 采用类似步骤 1 的方式转化未标注文档 d d d 并计算相应词组元素的权重3. 计算文档 d d d 与训练集样本中每一样本的距离(或相似度);4. 找出与文档 d d d 距离最小(或相似度最大)的 k k k 篇训练集文本;5. 统计这个 k k k 篇训练集文本的类别属性,一般将文档 d d d 的类归为 k k k 中最多的样本类别。KNN 分类模型是一种“懒学习”算法,实质上它没有具体的训练学习过程。分类过程只是将未标注文本与每一篇训练集样本进行相似度计算, kNN 算法的时间和空间复杂度较高。因而随着训练集样本的增加,分类的存储资源消耗大,时间代价高。一般不适合处理训练样本较大的分类应用。
kNN 分类模型的主要思想:通过给定一个未标注文档 d d d,分类系统在训练集中查找与它距离最接近的 k k k 篇相邻(相似或相同)标注文档,然后根据这 k k k 篇邻近文档的分类标注来确定文档 d d d 的类别。分类实现过程:1. 将训练集样本转化为向量空间模型表示形式并计算每一特征的权重2. 采用类似步骤 1 的方式转化未标注文档 d d d 并计算相应词组元素的权重3. 计算文档 d d d 与训练集样本中每一样本的距离(或相似度);4. 找出与文档 d d d 距离最小(或相似度最大)的 k k k 篇训练集文本;5. 统计这个 k k k 篇训练集文本的类别属性,一般将文档 d d d 的类归为 k k k 中最多的样本类别。KNN 分类模型是一种“懒学习”算法,实质上它没有具体的训练学习过程。分类过程只是将未标注文本与每一篇训练集样本进行相似度计算, kNN 算法的时间和空间复杂度较高。因而随着训练集样本的增加,分类的存储资源消耗大,时间代价高。一般不适合处理训练样本较大的分类应用。
关于上面这些模型的具体原理性质参见:文本分类——常见分类模型。
⭐️ 深度学习方法
上文介绍了传统的机器学习文本分类,后起的神经网络虽然可以横扫一切,但其实一开始却不擅长对文本数据的处理(其实神经网络虽然在各种 NLP 任务中虽然准确率非常好看,但实际应用中并不明显)。主要问题是,文本本表示高维度高稀疏,但特征表达能力却很弱,神经网络还需要人工进行特征工程,成本高昂。
自 2010 年代以来,文本分类逐渐从浅层学习模式向深度学习模式转变。与基于浅层学习的方法相比,深度学习方法避免了人工设计规则和特征,并自动提供文本挖掘的语义意义表示。与浅层模型不同,深度学习通过学习一组直接将特征映射到输出的非线性转换,将特征工程集成到模型拟合过程中。目前的几乎所有研究都是基于 DNN。
下面是目前文本分类算法在最近的一些主流任务上的排行榜:

可以看到已经不见了传统算法的影子,目前的主流研究方向也都是神经网络的方向,但是对于一些小数据量、低成本的任务还是推荐使用传统算法。
而深度学习最初之所以在图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用 CNN/RNN 等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。例如新提出的 BERT 模型。
文本分类深度学习概述
前馈神经网络和递归神经网络是用于文本分类任务的前两种深度学习方法,与浅层学习模型相比,它们可以提高性能。然后,将 CNN,RNN 和注意力机制用于文本分类。许多研究人员通过改进 CNN,RNN 和注意力,或模型融合和多任务方法,提高了针对不同任务的文本分类性能。
可以生成上下文化词向量的 BERT 的出现,是文本分类和其他 NLP 技术发展的重要转折点,该模型在包括文本分类在内的多个 NLP 任务具有更好的性能。此外,一些研究人员研究了基于 GNN 的文本分类技术,以捕获文本中的结构信息,这是其他方法无法替代的。
根据结构对文本分类的 DNN 算法可分为几大类:
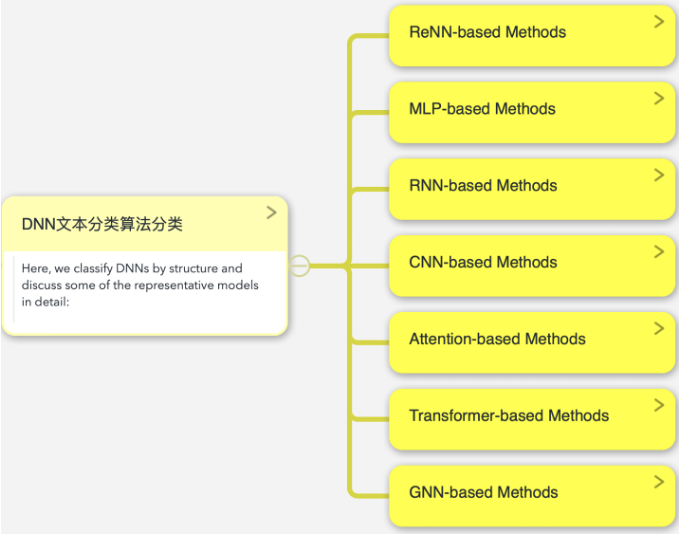
1. 基于递归神经网络的方法(ReNN-based methods)
递归神经网络(ReNN)可以自动递归学习文本的语义和语法树结构,无需特征设计。递归自动编码器(RAE)用来预测每个输入句子的情感标签分布,并学习多词短语的表示。为了学习每个输入文本的成分向量表示,矩阵向量递归神经网络(MV-RNN)引入了 ReNN 模型来学习短语和句子的表示。
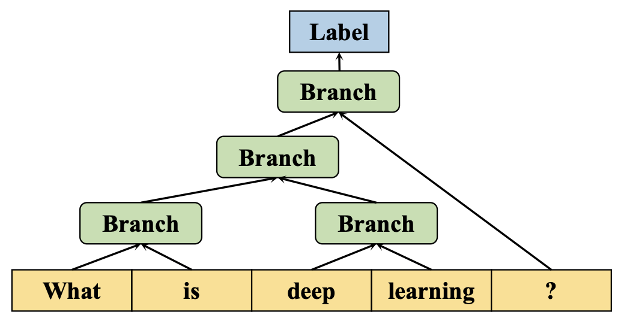
看图中的例子。首先,将输入文本中的每个单词作为模型结构的叶节点,然后通过权重矩阵将所有节点合并为父节点。权重矩阵在整个模型中共享。每个父节点与所有叶节点具有相同的维度。最后,将所有节点递归聚合为根节点,以表示预测标签的输入文本
2. 基于多层感知机的方法(MLP-based methods)
多层感知器(MLP, multilayer perceptron),俗称”vanilla”神经网络,是一种用于自动捕获特征的简单神经网络结构。
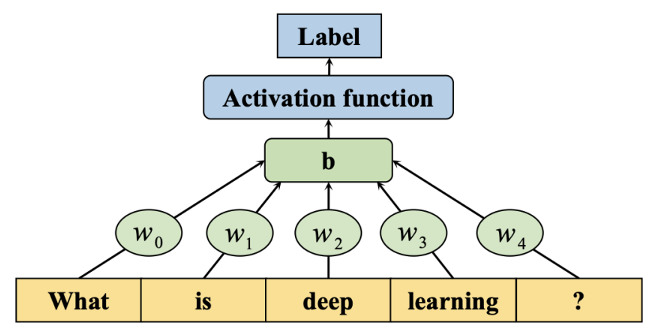
看图中例子,我们给出了一个三层 MLP 模型。它包含一个输入层、一个对应所有节点带有激活函数隐藏层,一个输出层。每个节点都连接一个具有一定权重的 wi。它将每个输入文本视为一个词袋(bagsofword)
一些研究小组提出了一些基于 MLP 的文本分类方法。段落向量(Paragraph-vec)是最流行和使用最广泛的方法,它类似于 CBOW。采用无监督算法得到不同输入长度文本的固定长度特征表示。
3. 基于循环神经网络的方法(RNN-based methods)
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN 就能够很好地解决这类问题。
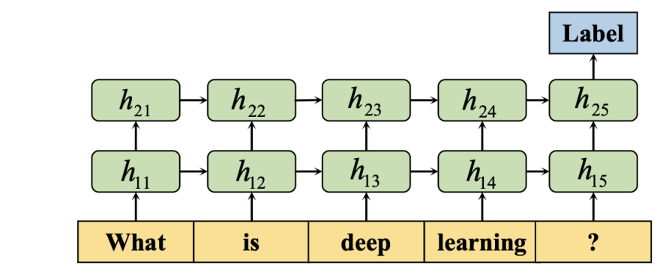
看图中例子。首先,利用词嵌入技术(word embedding),将输入的每个词用一个特定的向量表示。然后,将嵌入词向量逐个输入 RNN 单元。RNN 单元的输出与输入向量的维数相同,并馈入下一隐含层。RNN 在模型的不同部分共享参数,并且对每个输入词具有相同的权重。最后,隐藏层的最后一层输出可以预测输入文本的标签。
基于循环神经网络的方法:长短期记忆(LSTM)
在 RNN 的反向传播过程中,权值是通过导数的连续乘法来计算的梯度来调整的。如果导数非常小,连续乘法可能会导致梯度消失问题。长短期记忆(Long short-term memory, LSTM)是一种特殊的 RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的 RNN,LSTM 能够在更长的序列中有更好的表现。
它由记忆任意时间间隔值的单元和控制信息流的三个门结构组成。门结构包括输入门(input gate)、遗忘门(forget gates)和输出门(ouput gates)。LSTM 分类方法可以更好地捕获上下文特征词之间的连接,利用遗忘门结构过滤无用信息,有利于提高分类器的总体捕获能力。
LSTM 结构(图右)和普通 RNN 的主要输入输出区别如下所示。
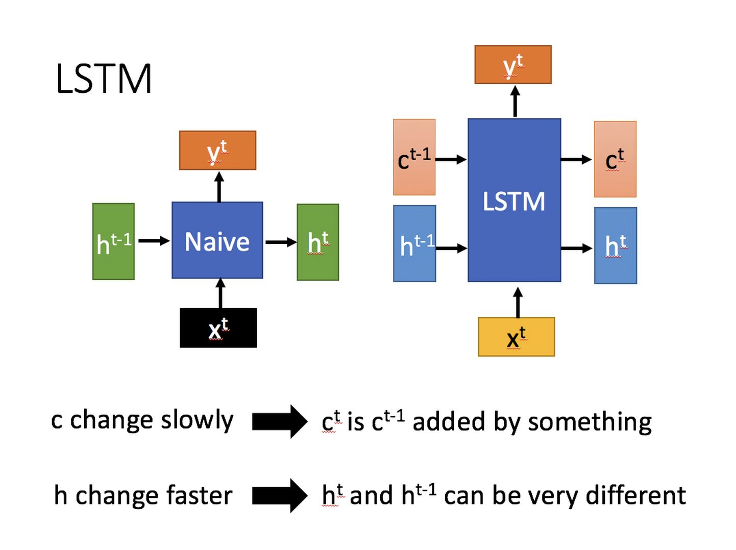
具体参见:人人都能看懂的 LSTM
4. 基于卷积神经网络的方法(CNN-based methods)
卷积神经网络(Convolutional neural networks, CNNs)起初用于图像分类,卷积滤波器(convolving filters)可以提取图像的特征。与 RNN 不同,CNN 可以同时将不同核定义的卷积应用于序列的多个块。因此,CNN 用于许多自然语言处理任务,包括文本分类。对于文本分类,需要将文本表示为类似于图像表示的向量,可以从多个角度对文本特征进行过滤。
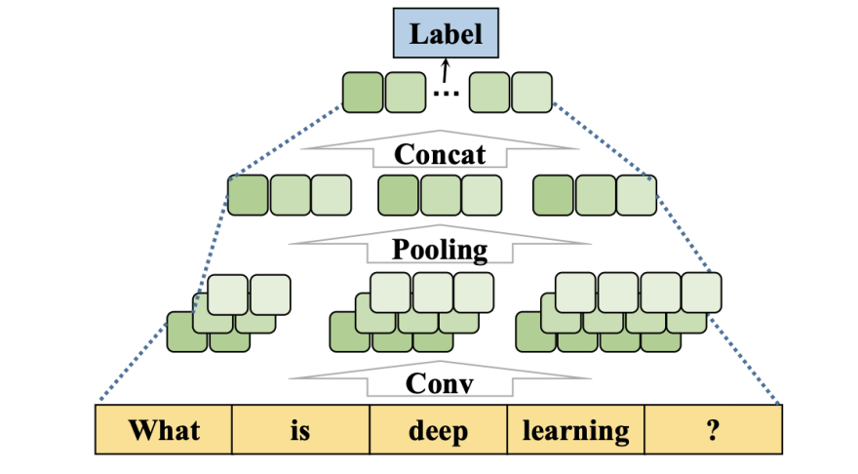
看图中例子。首先,将输入文本的词向量拼接成一个矩阵。然后将矩阵输入卷积层(Conv),卷积层包含几个不同维度的滤波器。最后,卷积层的结果经过池化层(Pooling),并将池化结果连接起来(Concat),得到文本的最终向量表示。类别由最终输出向量预测。
5. 基于注意力机制的方法(Attention-based methods)
CNN 和 RNN 在文本分类相关的任务上提供了很好的结果,但缺点在于,这些模型不够直观,可解释性较差,特别是对于一些分类错误,由于隐藏数据的不可读性,无法解释。因此提出了注意力模型。
注意力模型(Attentional mechanism, AM)最初被用于机器翻译,现在已成为神经网络领域的一个重要概念。注意力机制借鉴了人类的注意力机制。
例如,视觉注意力机制是人类视觉所特有的大脑信号处理机制。我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图中例子形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标。很明显人们会把注意力更多投入到人的脸部、文本的标题、文章首句以及更具有感情色彩的词汇等位置。

深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。同样,在涉及语言或视觉的问题中,输入的某些部分可能会比其他部分对决策更有帮助。例如,在翻译和总结任务中,输入序列中只有某些单词可能与预测下一个单词相关。
在人工智能领域,注意力已成为神经网络结构的重要组成部分,并在自然语言处理、统计学习、语音和计算机等领域有着大量的应用。
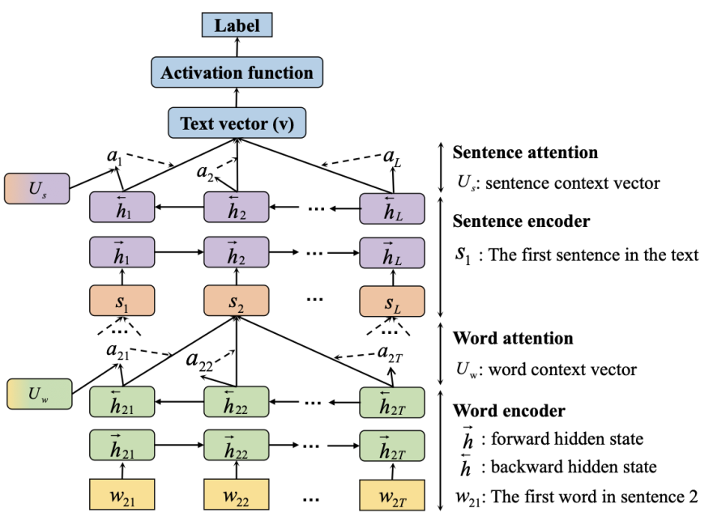
基于注意力机制的方法:HAN
HAN 包括两个编码器(encoders)和两个层次的注意层(attention layers)。注意机制让模型对特定的输入给予不同的注意。它先将关键词聚合成句子向量,再将关键句子向量聚合成文本向量。通过这两个层次的注意,可以了解每个单词和句子对分类判断贡献多少,有利于应用和分析。
6. 基于 Transformer 的方法(Transformer-based methods)
Transformer 是一种预训练的语言模型,可以有效地学习全局语义表示,并显著提高包括文本分类在内的 NLP 任务。通常使用无监督的方法自动挖掘语义知识,然后构造预训练目标,使机器能够学习理解语义。Transformer 可以在不考虑连续信息(sequential information)的情况下并行计算,适用于大规模数据集,因此在 NLP 任务中很受欢迎。
基于 Transformer 的方法最著名的有以下三个模型:
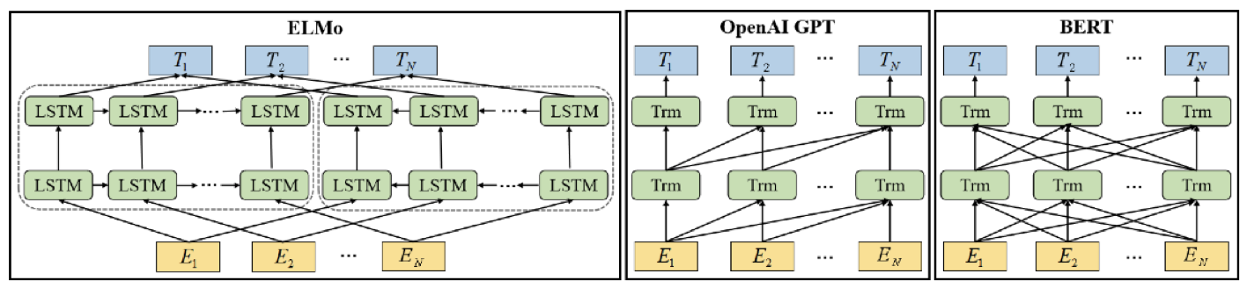
ELMo 是一个深度上下文化的词表示模型,它很容易集成到模型中。 它可以模拟词汇的复杂特征,学习不同语境下的不同表征。该算法利用双向 LSTM 算法,根据上下文单词学习每个单词的嵌入。
GPT 的核心思想是先通过无标签的文本去训练生成语言模型,再根据具体的 NLP 任务(如文本蕴涵、QA、文本分类等),来通过有标签的数据对模型进行 fine-tuning。
BERT(Bidirectional Encoder Representation from Transformers),是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的 masked language model(MLM),以致能生成深度的双向语言表征。
具体参考:什么是 BERT?
基于图神经网络的方法(GNN-based methods)
尽管传统的深度学习方法在提取结构空间(欧式空间)数据的特征方面取得了巨大的成功,但许多实际应用场景中的数据是从非结构空间生成的,传统的深度学习方法在处理非结构空间数据上的表现难以令人满意。例如,在推荐系统中,一个基于图的学习系统能够利用用户和产品之间的交互来做出非常准确的推荐。
图神经网络(GNN,Graph Neural Network),是一个可用于学习大规模相互连接的图结构信息数据的模型。基于 GNN 的模型可以学习句子的句法结构,也可以进行文本分类。
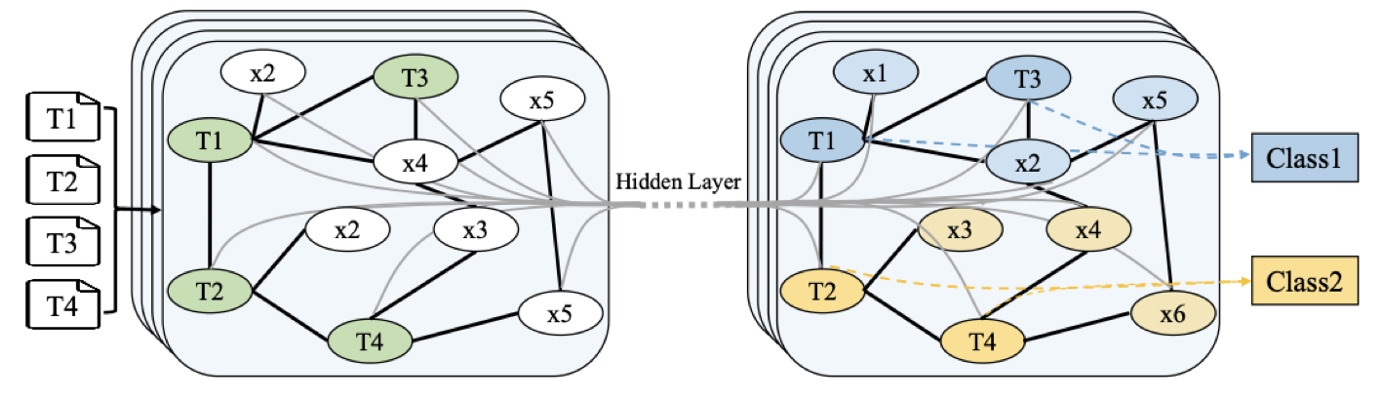
如图中例子所示。首先,将四个输入文本和文本中的单词定义为节点,构造成图结构。图节点由黑体边连接,黑体边表示文档—单词边和单词—单词边。每个词的权重通常是指它们在语料库中的共现频率。然后,通过隐藏层表示单词和文本。最后,可以用图预测所有输入文本的标签。
文本分类技术挑战
众所周知,在 DNN 中输入的有益信息越多,其性能越好。因此,增加外部知识(知识库或知识图)是提高模型性能的有效途径,由于投入规模的限制,仍然是一个挑战。
算法模型:如何权衡数据和计算资源以及预测性能。
虽然一些新的文本分类模型不断地提高了大多数分类任务的准确性指标,但并不能像人类一样从语义层面“理解”文本。此外,对于噪声样本,小样本噪声可能导致决策置信度发生较大变化,甚至导致决策逆转。以词向量为代表的预先训练的语义表示模型通常可以提高下游 NLP 任务的性能。现有的关于无语境词向量(context-free
word vectors)迁移策略的研究还处于相对初级的阶段。从数据,模型和性能的角度得出结论,文本分类主要面临以下挑战:
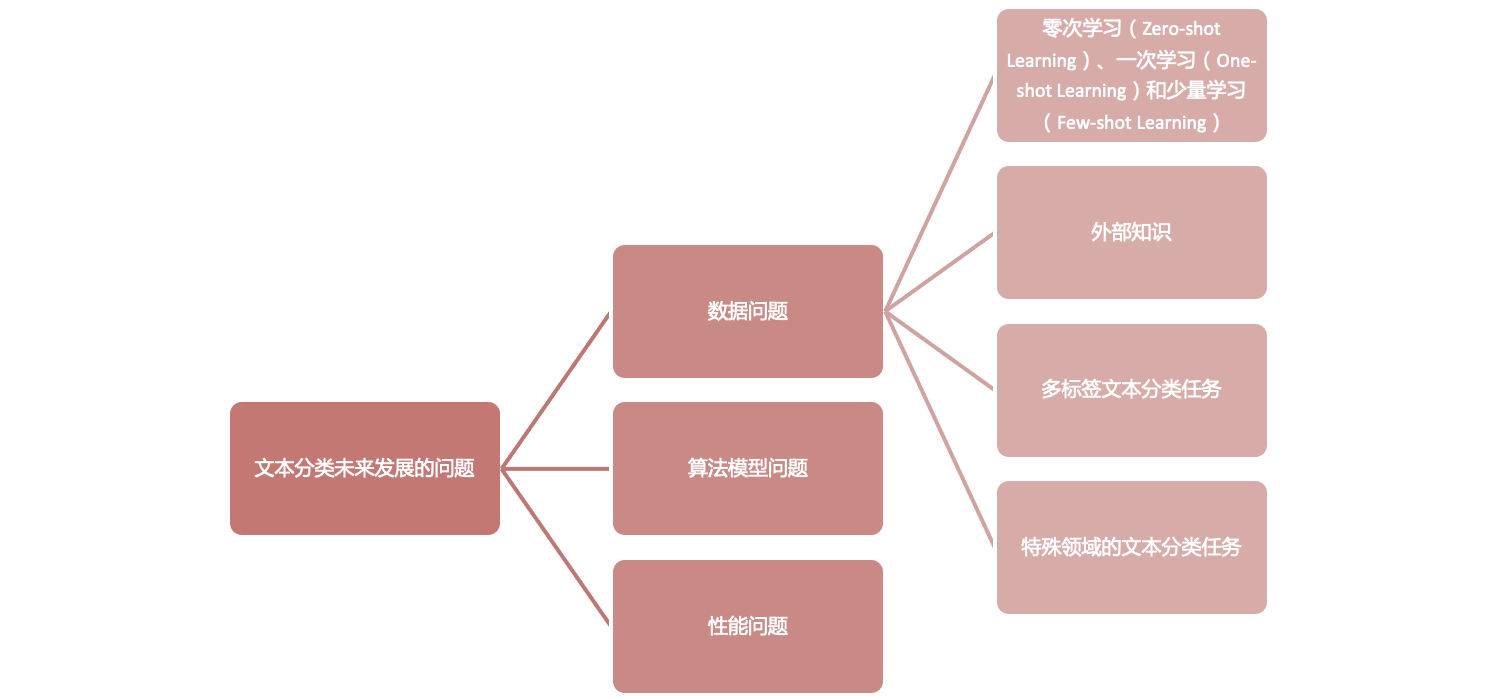
数据层面
对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。研究的文本数据主要包括多章,短文本,跨语言,多标签,少样本文本。对于这些数据的特征,现有的技术挑战如下:
- 零次学习/少量学习(zero-shot/Few-shot learning) 是指对无标注、或很少标注的文本进行分类。然而,目前的模型过于依赖大量的标记数据。
- 外部知识。 深度学习模型是大数据喂出来的,输入的信息越多,DNN 的性能就越好。所以,添加外部知识(知识库或知识图)是提高模型性能的有效途径。然而,如何添加以及添加什么仍然是一个问题。
- 多标签文本分类任务 多标签文本分类需要充分考虑标签之间的语义关系,并且模型的嵌入和编码是有损压缩的过程。因此,如何减少训练过程中层次语义的丢失以及如何保留丰富而复杂的文档语义信息仍然是一个亟待解决的问题。
- 具有许多术语词汇的特殊领域 特定领域的文本(例如金融和医学文本)包含许多特定的单词或领域专家,可理解的语,缩写等,这使现有的预训练单词向量难以使用。
模型层面
现有的算法模型,浅层和深度学习已经都尝试应用于文本分类,包括集成方法(integration methods)。横空出世的 BERT 学习了一种语言表示法,可以用来对许多 NLP 任务进行 fine-tune。但想提高模型准确率,最主要的方法是仍然是增加数据,如何在增加数据和计算资源,和预测性能之间权衡是值得研究的。
性能评估层面
浅层模型和深层模型可以在大多数文本分类任务中取得良好的性能,但是需要提高其结果的抗噪声能力。如何实现对深度模型的合理评估也是一个技术挑战。
- 模型的语义鲁棒性 近年来,研究人员设计了许多模型来增强文本分类模型的准确性。但是,如果数据集中有一些对抗性样本,则模型的性能会大大降低。因此,如何提高模型的鲁棒性是当前研究的热点和挑战。
- 模型的可解释性 DNN 在特征提取和语义挖掘方面具有独特的优势,并且已经完成了出色的文本分类任务。但是,深度学习是一个黑盒模型,训练过程难以重现,隐式语义和输出可解释性很差。它对模型进行了改进和优化,丢失了明确的准则。此外,我们无法准确解释为什么该模型可以提高性能。
总结
本文主要介绍了现有的从浅学习到深学习的文本分类任务模型。首先,介绍了一些主要的浅学习模型和深度学习模型,并给出了总结表。浅层模型主要通过改进特征提取方案和分类器设计来提高文本分类性能。
相比之下,深度学习模型通过改进表示学习方法、模型结构以及增加数据和知识来提高性能。然后,我们引入了带有摘要表和评价指标的数据集,用于单标签和多标签任务。在此基础上,给出了经典文本分类数据集在不同应用的摘要表中领先模型的定量结果。
最后,总结了文本分类未来可能面临的研究挑战。

参考文章
参考博文
中文文本挖掘预处理流程总结
自然语言处理(NLP)语义分析–文本分类、情感分析、意图识别
自然语言处理 4:文本分类
自然语言处理——文本分类概述
文本分类——常见分类模型
《文本分类大综述:从浅层到深度学习》
最新文本分类综述 2020-《A Survey on Text Classification: From Shallow to Deep Learning》
参考文献
[1] X. Zhu, P. Sobhani, and H. Guo, " Long short-term memory over recursive structures, in Proc. ICML, 2015, pp. 1604-1612, 201
[2] K. S. Tai, R. Socher, and C. D. Manning, "Improved semantic representations from tree-structured long short-term memory networks, in Proc.ACL,2015,pp.1556-1566,2015.
[3]K. Kowsari, K. J. Meimandi, M. Heidarysafa, S. Mendu, L. E. Barnes, and D. E. Brown, “Text classifification algorithms: A survey,” Information, vol. 10, no. 4, p. 150, 2019.
[4]K. Schneider, “A new feature selection score for multinomial naive bayes text classifification based on kl-divergence,” in Proc. ACL, 2004,2004.
[5]W. Dai, G. Xue, Q. Yang, and Y. Yu, “Transferring naive bayesclassifiers for text classification,” in Proc. AAAI, 2007, pp. 540–545,2007.
[6]K. Yi and J. Beheshti. A hidden markov model-based text classification of medical documents, “J. Inf. Sci., vol.35, no. 1, pp.67-81, 2009
[7]T. M. Cover and P. E. Hart, “Nearest neighbor pattern classifification,” IEEE Trans. Inf. Theory, vol. 13, no. 1, pp. 21–27, 1967.
[8]P. Soucy and G. W. Mineau, “A simple KNN algorithm for text categorization,” in Proc. ICDM, 2001, pp. 647–648, 2001.
[9]S. Tan, “Neighbor-weighted k-nearest neighbor for unbalanced text corpus,” Expert Syst. Appl., vol. 28, no. 4, pp. 667–671, 2005.
[10]C. Cortes and V. Vapnik, “Support-vector networks,” Mach. Learn., vol. 20, no. 3, pp. 273–297, 1995.
[11]T. Joachims, “Text categorization with support vector machines: Learning with many relevant features,” in Proc. ECML, 1998, pp. 137–142, 1998.
[12]T. Joachims, “A statistical learning model of text classification for support vector machines,” in Proc. SIGIR, 2001, pp. 128–136, 2001.
[13]P. Vateekul and M. Kubat, “Fast induction of multiple decision trees in text categorization from large scale, imbalanced, and multi-label data,”in Proc. ICDM Workshops, 2009, pp. 320–325, 2009.
[14]R. Socher, J. Pennington, E. H. Huang, A. Y. Ng, and C. D. Manning, “Semi-supervised recursive autoencoders for predicting sentiment distributions,” in Proc. EMNLP, 2011, pp. 151–161, 2011.
[15]R. Socher, B. Huval, C. D. Manning, and A. Y. Ng, “Semantic compositionality through recursive matrix-vector spaces,” in Proc.EMNLP, 2012, pp. 1201–1211, 2012.
[16]M. k. Alsmadi, K. B. Omar, S. A. Noah, and I. Almarashdah, “Performance comparison of multi-layer perceptron (back propagation, delta rule and perceptron) algorithms in neural networks,” in 2009 IEEE International Advance Computing Conference, pp. 296–299, 2009.
[17]Q. V. Le and T. Mikolov, “Distributed representations of sentences and documents,” in Proc. ICML, 2014, pp. 1188–1196, 2014.
[18]B. Felbo, A. Mislove, A. Søgaard, I. Rahwan, and S. Lehmann, “Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm,” in Proc. EMNLP, 2017, pp. 1615–1625, 2017.
[19]T. Miyato, S. Maeda, M. Koyama, and S. Ishii, “Virtual adversarial training: a regularization method for supervised and semi-supervised learning,” CoRR, vol. abs/1704.03976, 2017.
[20]T. Miyato, A. M. Dai, and I. J. Goodfellow, “Adversarial training methods for semi-supervised text classification,” in Proc. ICLR, 2017, 2017. [21]Li Q, Peng H, Li J, et al. A survey on text classification: From shallow to deep learning[J]. arXiv preprint arXiv:2008.00364, 2020.
版权归原作者 Suprit 所有, 如有侵权,请联系我们删除。