
标准化(Standardization )和归一化(Nomalisation)
网上对他们的描述纷繁复杂,有些人认为他们是等价的,有些人认为他们是完全不同的,我这里更倾向于认为他们有共通的性质但不是完全相同的。
首先我们先从定义上分析
标准化(Standardization):将数据变换为均值为0,标准差为1的分布,变换后依然保留原数据分布

归一化(Normalization):将一列数据变化到某个固定区间(范围)中,通常,这个区间是[0, 1],广义的讲,可以是各种区间,比如映射到[0,1]一样可以继续映射到其他范围,图像中可能会映射到[0,255],其他情况可能映射到[-1,1]

两者的联系和差异
标准化和归一化本质上都是不改变数据顺序的情况下对数据的线性变化,而它们最大的不同是归一化(Normalization)会将原始数据规定在一个范围区间中,而标准化(Standardization)则是将数据调整为标准差为1,均值为0对分布。
另外归一化只与数据的最大值和最小值有关,缩放比例为,而标准化的缩放比例等于标准差
,平移量等于均值
,当除了极大值极小值的数据改变时他的缩放比例和平移量也会改变。
常见的归一化和标准化
均值归一化(Mean Normalization)
将数值范围缩放到[−1,1]区间里,数据的均值变为0

最大最小值归一化(Min-Max Normalization)
最大最小值归一化简称为归一化,将数值范围缩放到[0,1]区间里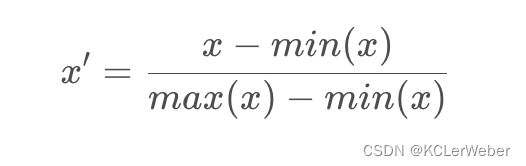
标准化/z值归一化(Standardization/Z-Score Normalization)
标准化又叫z值归一化,将数值缩放到0附近,且数据的分布变为均值为0,标准差为1的标准正态分布。

什么时候需要使用标准化和归一化
首先标准化和归一化的本质都是数据的特征缩放,而基于数据距离的算法依赖于特征缩放,例如聚类、基于距离的分类算法(KNN、逻辑回归、SVM)、线性回归等;而不基于距离的算法,大部分是分类器不需要特征缩放。
- 统计建模中,如回归模型,自变量X XX的量纲不一致导致了回归系数无法直接解读或者错误解读;需要将X XX都处理到统一量纲下,这样才可比;
- 机器学习任务和统计学任务中有很多地方要用到“距离”的计算,比如PCA,比如KNN,比如kmeans等等,假使算欧式距离,不同维度量纲不同可能会导致距离的计算依赖于量纲较大的那些特征而得到不合理的结果;
- 参数估计时使用梯度下降,在使用梯度下降的方法求解最优化问题时, 归一化/标准化后可以加快梯度下降的求解速度,即提升模型的收敛速度。
如果对数据范围有严格的要求,使用归一化。
ML领域更常使用标准化,如果数据不为稳定,存在极端的最大最小值,不要用归一化。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化表现更好;在不涉及距离度量、协方差计算的时候,可以使用归一化方法。
批归一化(Batch Normalization)
就是对每一批数据进行归一化,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理,但每一层对所有数据都进行归一化处理的计算开销太大,因此就和使用最小批量梯度下降一样,批量归一化中的“批量”其实是采样一小批数据,然后对该批数据在网络各层的输出进行归一化处理 。
BN的好处
- 加快训练速度
- 可以省去dropout,L1, L2等正则化处理方法
- 提高模型训练精度
参考
- 一文弄懂特征缩放(归一化/正则化)_愤怒的可乐的博客-CSDN博客_归一化 范围缩放
- 标准化和归一化,请勿混为一谈,透彻理解数据变换_夏洛克江户川的博客-CSDN博客_标准化和归一化
- 归一化 (Normalization)、标准化 (Standardization)和中心化/零均值化 (Zero-centered),BN,Batch,批归一化,从归一化到批归一化_贾世林jiashilin的博客-CSDN博客_归一化
- 标准化和归一化什么区别? - 知乎
版权归原作者 Weber77 所有, 如有侵权,请联系我们删除。