
原文链接:https://www.techbeat.net/article-info?id=4323
作者:seven_
最近AIGC社区中有趣的工作可谓是层出不穷,这都得益于扩散模型(Diffusion Models)的成功,扩散模型作为生成式AI模型中的一个新兴话题,已经给我们带来了很多惊喜。但是需要注意的是,目前的文本到图像扩散模型需要大规模的文本-图像对数据集进行预训练,因此想将已有的模型扩展到缺乏标记数据的新领域中,难度非常大。这其实是基于数据驱动模型老生常谈的问题,因而本文作者建议在扩散模型领域中引入大规模检索方法来帮助模型训练,具体来说,作者结合传统的k-Nearest-Neighbors(kNN)提出了一种KNN-Diffusion模型,该模型相比普通的扩散模型具有以下几个新的功能:
- KNN-Diffusion可以在没有任何文本的情况下训练一个非常小且高效的文本到图像的扩散模型。
- KNN-Diffusion可以在推理时简单地交换检索数据库中的图像来生成分布外(unseen,增强泛化能力)的图像。
- KNN-Diffusion可以在执行文本驱动的局部语义操作时同时保留原本图像的整体语义。 以上三个功能一方面提升了扩散模型的数据利用效率,也在某些层面增强了模型对未知领域的泛化能力,另一方面通过所提出的文本驱动的局部语义操作机制,可以赋予模型进行细粒度图像编辑的能力。

论文链接:
展示一些KNN-Diffusion的文本图像生成效果:
上图左侧展示了KNN-Diffusion的文本到图像效果,右侧展示了文本驱动的局部语义编辑效果,可以看到,当我们给模型输入“With a bow tie(打领带)”,模型可以非常精确地给豌豆人装上一个卡通领带。此外为了证明本文方法的鲁棒性,作者还将kNN方法应用于两个目前较为先进的扩散主干模型上,都得到了非常满意的效果。
一、引言
虽然目前大规模的文本图像扩散模型在图像生成、图像编辑甚至视频生成等任务中展现出来优秀的创造力,但是为了扩散模型的不断发展,是时候考虑如何降低扩散模型的上手难度了。目前扩散模型仍然面临几个重大挑战:
- 大规模的配对数据需求,为了获得高质量的生成结果,目前的扩散模型仍受限于已有的文本-图像对大规模数据集。
- 计算成本和效率较高,在高度复杂的自然图像分布上训练扩散模型通常需要非常大的模型容量、数据、批量大小和训练时间,这对于一般的科研人员不太友好,导致扩散模型社区的成长受限。
为了解决以上问题,本文提出了一种结合传统检索方法的KNN-Diffusion模型,KNN-Diffusion可以利用KNN方法在进行大规模检索获得数据,以便于在没有任何文本数据的情况下来训练模型。具体来说,KNN-Diffusion具有两种形式的输入:
- 图像嵌入(在训练时)或文本嵌入(在推理时),使用多模态CLIP[1]编码器获得;
- kNN嵌入,代表k个最相似的CLIP潜在空间中的图像。这样就可以在缺少文本的情况下,仅通过CLIP生成的嵌入进行文本图像对训练。
在模型推理阶段,只需要将输入的文本转换为kNN嵌入就可以完成新域的图像生成推理。此外作者借助CLIP模型提出了一种文本驱动的局部语义操作方法,而无需之前方法中手动指定的掩码,大大提高了图像编辑效率。下图展示了该方法的示例效果,给模型指定修改命令后,KNN-Diffusion可以自动定位到要修改的目标区域,合成一个高分辨率的图像,同时原有图像的身份语义可以被保留,而其他对比方法例如Text2Live[2]和Textual Inversion[3]可能会改变原本图像的身份信息。
二、本文方法
KNN-Diffusion模型主要由三个主要模块构成,如下图所示,(1)一个多模态文本-图像编码器,这里直接使用CLIP模型。(2)一个检索模型,由一种可以包含图像嵌入的数据结构构成,它可以作为kNN搜索算法的索引向量。(3)一个图像生成网络,该网络以检索向量作为条件,并以基于扩散的图像生成模型作为backbone。在模型的训练和推理阶段,图像生成网络以k个图像嵌入作为条件,并使用检索模型进行搜索和选择以确保训练和推理中的条件分布相似,下面我们将详细介绍以上这些模块的实现细节。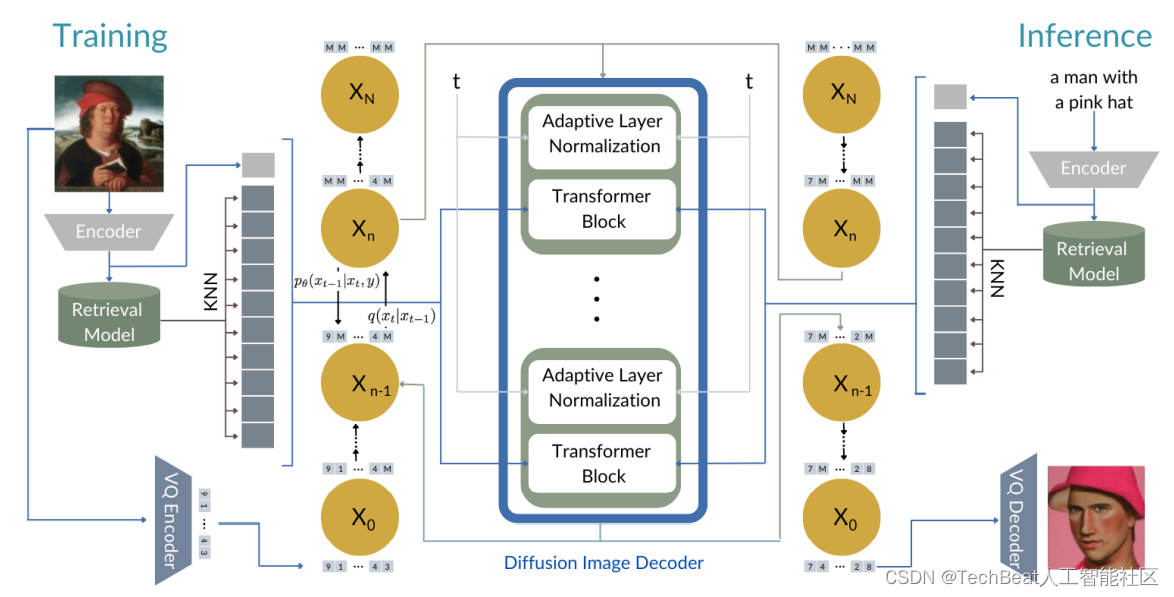
2.1 检索模型
检索模型中包含有三个不可训练的模块:一个预训练的文本编码器
f
t
x
t
f_{txt}
ftxt ,一个预训练的图像编码器
f
i
m
g
f_{img}
fimg 和一个索引
H
H
H 。编码器将文本描述和图像样本映射到一个联合的多模态
d
d
d 维特征空间
R
d
\mathbb{R}^{d}
Rd 中。索引
H
H
H 中存储了一个已有数据集中的有效图像表示
H
:
=
{
f
i
m
g
(
i
)
∈
R
d
∣
i
∈
I
}
\mathcal{H}:=\left\{f_{i m g}(i) \in \mathbb{R}^{d} \mid i \in \mathcal{I}\right\}
H:={fimg(i)∈Rd∣i∈I},其中
I
I
I 表示该数据集。在训练过程中,**作者使用这些索引有效地提取给定图像嵌入所处特征空间中的最近的
k
k
k 个邻居:**
f
i
m
g
(
I
)
∈
R
d
−
knn
i
m
g
(
I
,
k
)
:
=
arg
min
h
∈
H
k
s
(
f
i
m
g
(
I
)
,
h
)
f_{i m g}(\mathrm{I}) \in \mathbb{R}^{d}-\text{knn}_{i m g}(\mathrm{I}, k):=\arg \min _{h \in \mathcal{H}}^{k} \mathbf{s}\left(f_{i m g}(\mathrm{I}), h\right)
fimg(I)∈Rd−knnimg(I,k):=argminh∈Hks(fimg(I),h)
其中
s
s
s 是一个距离函数。集合
{
f
i
m
g
(
I
)
,
knn
i
m
g
(
I
,
k
)
}
\left\{f_{i m g}(\mathrm{I}), \text{knn}_{i m g}(\mathrm{I}, k)\right\}
{fimg(I),knnimg(I,k)}**随后被用来作为生成模型的条件**。在推理过程中,只需给定一个查询文本
t
t
t ,模型就会提取一个嵌入
f
t
x
t
(
t
)
f_{t x t}(t)
ftxt(t) 。此时生成模型的条件就是这个嵌入与它在数据集
I
I
I 中的
k
k
k 个最近的邻居。
2.2 图像生成网络
为了证明本文方法的鲁棒性,作者将KNN-Diffusion应用于两种不同的扩散backbone中。分别是离散型扩散模型[4]和连续型扩散模型[5],虽然这两种模型在实际实现中有很大不同,但其都具有相同的理论基础。假设
x
0
∼
q
(
x
0
)
x_{0} \sim q\left(x_{0}\right)
x0∼q(x0) 是我们图像分布中的一个样本。扩散模型
q
(
x
n
∣
x
n
−
1
)
q\left(x_{n} \mid x_{n-1}\right)
q(xn∣xn−1) 的正向过程是一个马尔可夫链,每一步都会增加噪声。反向过程
p
θ
(
x
n
−
1
∣
x
n
,
x
0
)
p_{\theta}\left(x_{n-1} \mid x_{n}, x_{0}\right)
pθ(xn−1∣xn,x0) 则是一个去噪过程,从初始化的噪声状态中去除噪声。在推理阶段,该模型可以产生一个输出,从噪声开始,用
p
θ
p_{\theta}
pθ 逐渐的消除噪声。作者经过实验证明,在这两种扩散模型范式上,使用kNN方法都可以得到较为鲁棒的生成效果。
2.3 文本驱动的局部语义操作
之前的方法为了实现图像的局部语义编辑,往往需要依赖于用户输入的区域掩码。要么仅限于全局编辑。此外这些方法还存在其他缺陷,例如它们只能够实现局部的纹理编辑,而无法修改复杂的图像结构。而且绝大多数方法在进行编辑时会丢失掉原本图像中的身份信息。
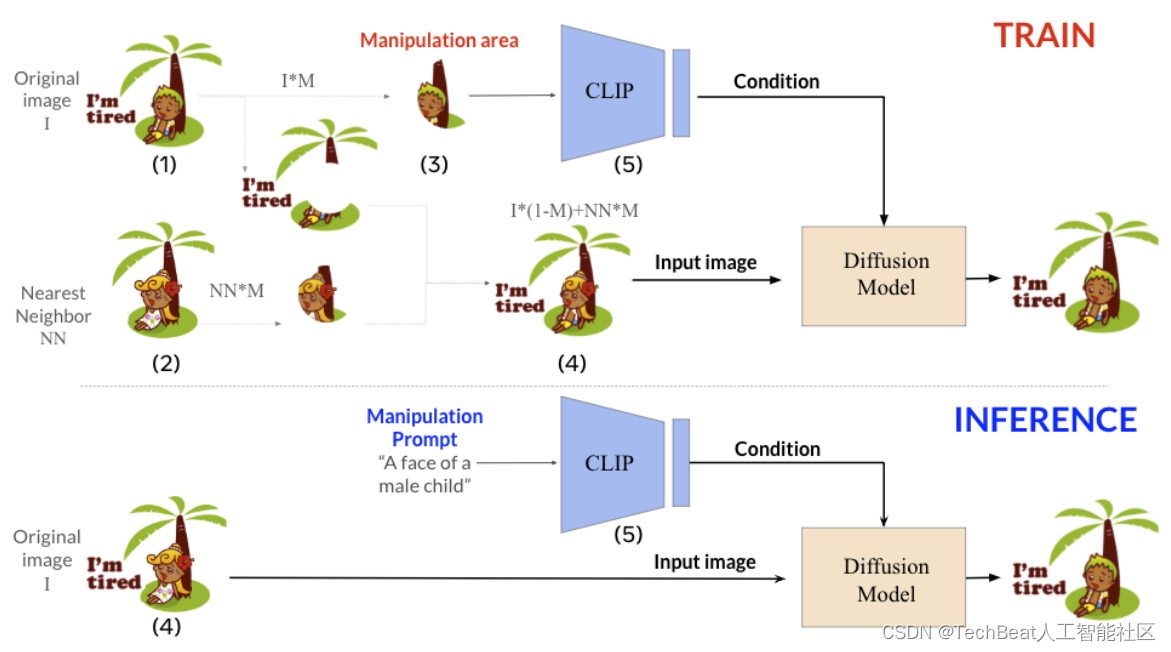
本文作者通过扩展KNN-Diffusion来解决这些问题,实现在不提供任何掩码的情况下进行局部和语义感知的图像编辑操作。上图展示了该方法的整体流程,为了实现这项任务,作者采用了一种反向思维方式,即训练模型从已编辑版本生成回原始图像。具体来说,先创建图像的编辑版本,该版本只在某些局部区域与原始图像不同。
例如给定图像
I
I
I 中一个随机的局部区域
M
M
M ,选取其最近的邻居区域
I
m
a
n
i
p
=
I
⋅
(
1
−
M
)
+
n
n
i
m
g
(
I
,
1
)
⋅
M
\mathrm{I}_{manip}=\mathrm{I} \cdot(1-M)+\mathrm{nn}_{i m g}(\mathrm{I}, 1) \cdot M
Imanip=I⋅(1−M)+nnimg(I,1)⋅M**替换该区域来构建图像的编辑版本
I
m
a
n
i
p
\mathbf{I}_{manip}
Imanip** 。
其中
n
n
i
m
g
(
I
,
1
)
n
\mathrm{nn}_{i m g}(\mathrm{I}, 1)n
nnimg(I,1)n 是使用对齐算法将其与
I
I
I 对齐后得到的最近邻居。**然后模型以图像的编辑版本,以及原始图像中局部区域的CLIP嵌入**
f
i
m
g
(
I
⋅
M
)
f_{i m g}(\mathrm{I} \cdot M)
fimg(I⋅M) 作为共同输入。**这个CLIP嵌入包含了当前图像所需的修改命令**,可以直接应用在图像的编辑版本上,来反推回原始图像。经过这样的训练,KNN-Diffusion可以通过CLIP嵌入来精确的定位要编辑的目标区域。在推理阶段,可以将用户输入的编辑命令文本转换为CLIP嵌入输入到模型中,此时图像的编辑版本和局部区域的CLIP嵌入同事作为模型的输入条件,进而完成编辑操作。
三、实验结果
本文的实验部分在MS-COCO、LN-COCO、CUB和Public Multimodal Dataset(PMD)等多个数据库上进行,前三个数据集用来作为普通定性和定量实验的比较,而PMD数据集用来进行图像逼真度(photo-realistic)实验。为了证明本文方法的优势,作者先将KNN-Diffusion应用在其他两个扩散backbone上来展示模型的对分布外图像的处理效果。下表展示了本文方法在三个不同数据集上zero-shot设置下的实验结果。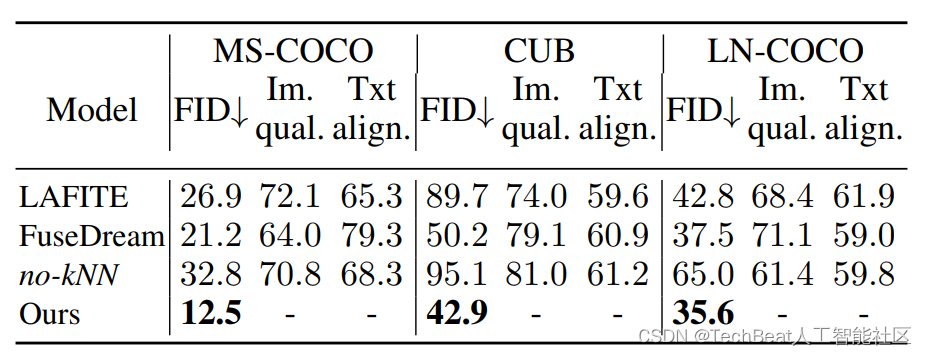
可以看到KNN-Diffusion在所有实验场景下都获得了最低的FID分数,其他两个对比方法分别是LAFITE和FuseDream,作者为了进一步证明在文本到图像生成任务中使用检索方法的优势,作者还训练了一个模型变体no-kNN,该变体仅在图像嵌入(省略kNN索引嵌入)上进行训练,而在推理过程中,图像是使用文本嵌入生成的。可以看到缺少检索引导,模型的性能会大幅下降。
下图中作者展示了本文方法与其他方法的定性生成对比,其中第一行图像是从PMD数据集中选取的与输入文本最接近的真实图像,可以观察到,KNN-Diffusion的生成结果更加逼真也更能保留真实图像的身份内容信息。
为了进一步证明本文方法的有效性,作者在下图中展示了本文模型与目前较为流行的9种文本图像生成扩散模型进行了对比,其中包括DALL·E、CogView、VQ-Diffusion、GLIDE、Latent Diffusion(LDM)、Make-A-Scene、DALL·E2、Parti和Imagen。实验结果如下图所示。其中横轴为每个模型的参数量,纵轴为该模型在当前实验数据集上的FID指标。可以看出,尽管KNN-Diffusion是在缺乏文本数据的数据集上进行训练的,但其计算成本却显着低于使用全文本图像对(例如LDM、GLIDE)训练的模型。这表明,利用外部检索数据库可以让本文的方法在性能和模型效率之间进行权衡,特别是在减少模型中的参数数量方面。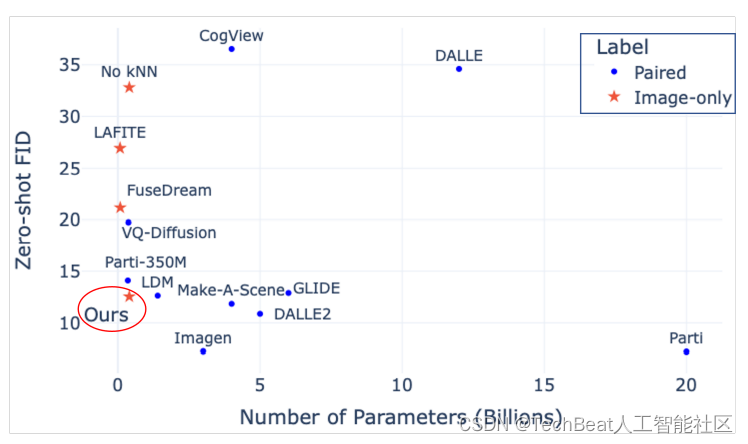
四、总结
在论文的结尾,作者致敬了苏格兰哲学家大卫·休谟,大卫·休谟在1748年提出“我们总会发现,我们迸发出的每一个想法都是从脑海中相似的印象中复制的”,这也可以看做是本文方法的核心灵感来源。在本文中,作者建议使用大规模的检索方法,以便在没有任何文本数据的情况下训练一个新的文本到图像模型。作者通过大量的实验表明,使用外部知识库可以减轻模型学习新概念的难度,从而可以得到相对较小且高效率的模型。此外,它还为模型提供了学习适应新样本的能力。最后,作者提出了一种新的技术,利用检索方法进行文本驱动的语义操作,无需用户提供的掩码,这对于文本图像编辑领域也具有一定的启发。希望KNN-Diffusion的提出可以激发社区更多的关注如何快速降低扩散模型的使用成本,实现更多的落地应用。
参考
[1] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in Proceedings of the 38th International Conference on Machine Learning, ICML 2021.
[2] Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, and Tali Dekel. Text2live: Text driven layered image and video editing. arXiv preprint arXiv:2204.02491, 2022.
[3] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
[4] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. ArXiv, abs/2111.14822, 2021
[5] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
Illustration by Iconscout Store from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com
版权归原作者 TechBeat人工智能社区 所有, 如有侵权,请联系我们删除。