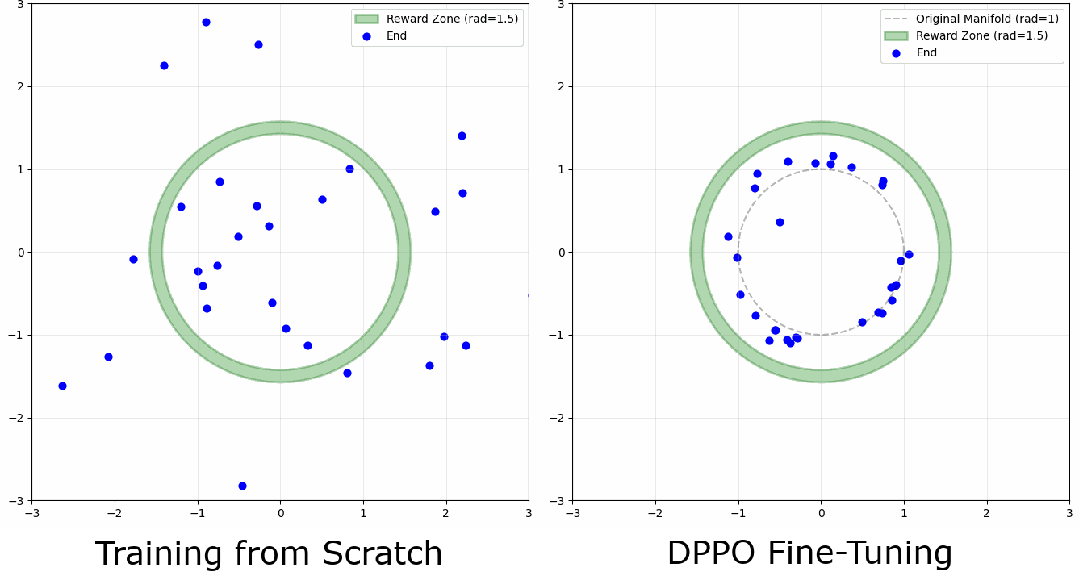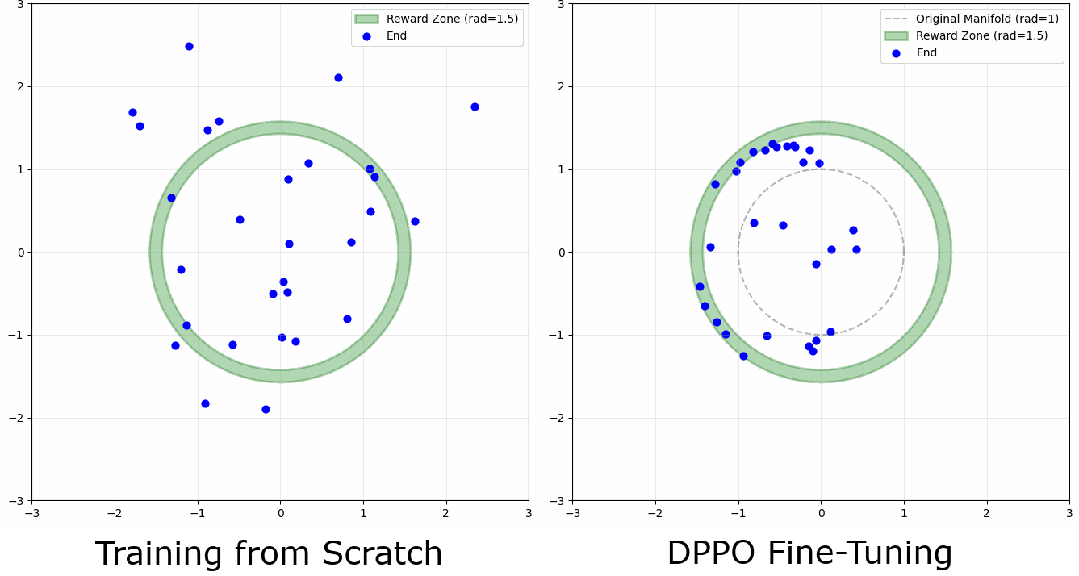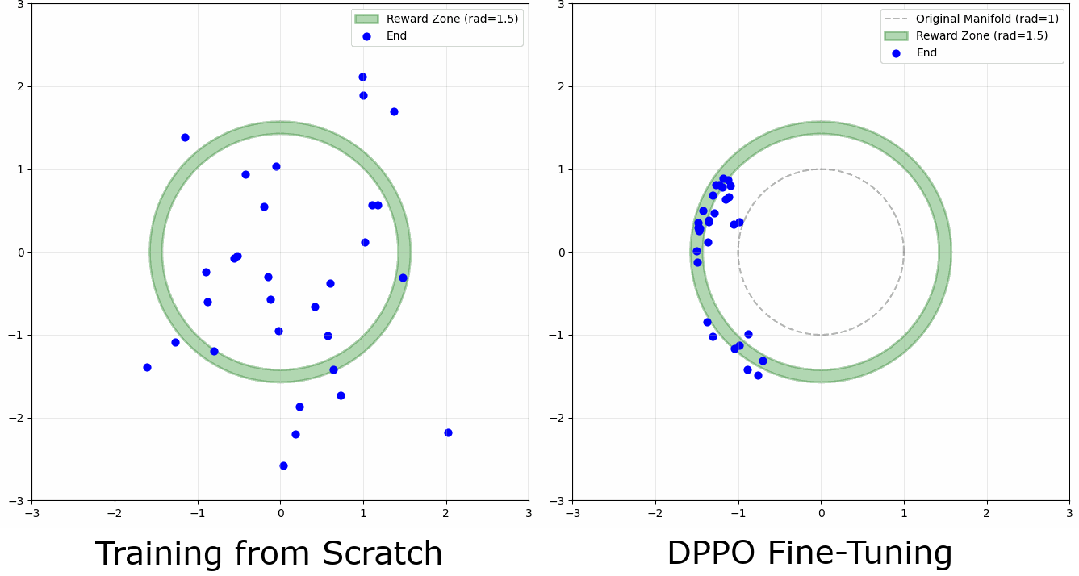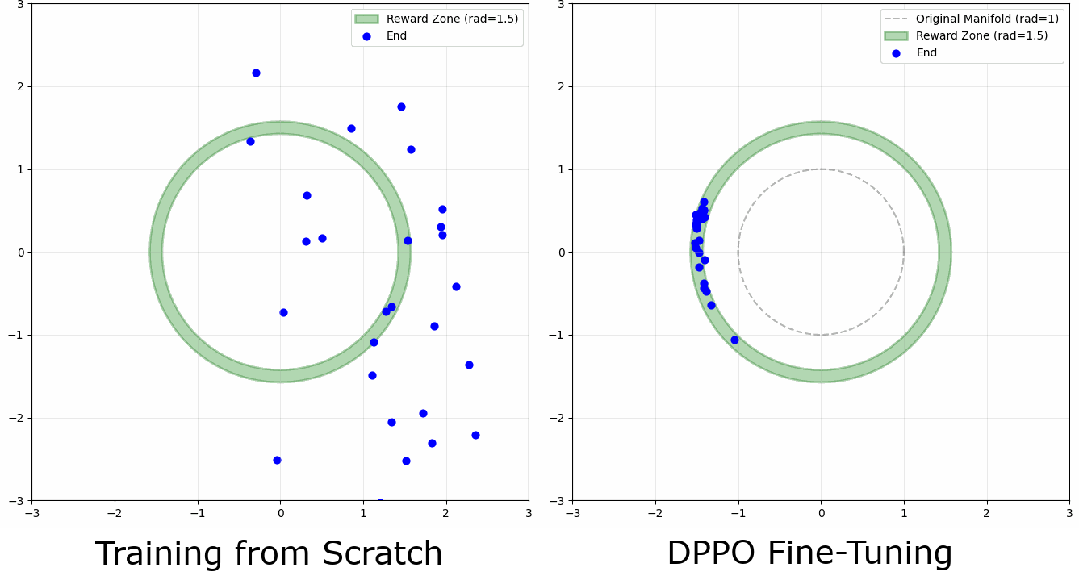
一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
这篇文章解释了如何为单步环境中的扩散模型实现 DPPO,希望能提供一个比典型机器人环境更容易理解训练动态的平台。
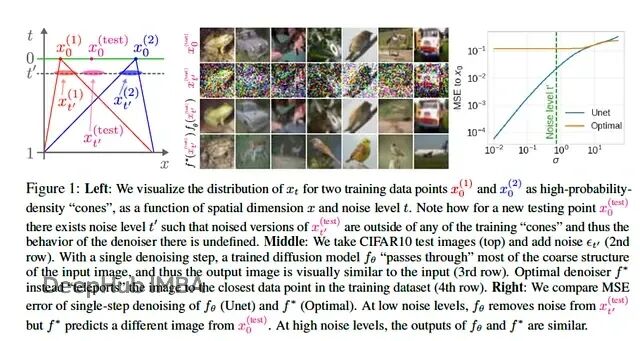
MIT新论文:数据即上限,扩散模型的关键能力来自图像统计规律,而非复杂架构
作者给出证据表明,扩散模型一个被反复强调的属性——关注局部像素关系——并不需要依赖架构的巧妙设计,它可以从训练图像的统计规律中自然涌现。

从零实现基于扩散模型的文本到视频生成系统:技术详解与Pytorch代码实现
本文详细介绍了基于扩散模型构建的文本到视频生成系统,展示了在MSRV-TT和Shutterstock视频标注数据集上训练的模型输出结果。以下是模型在不同提示词下的生成示例。
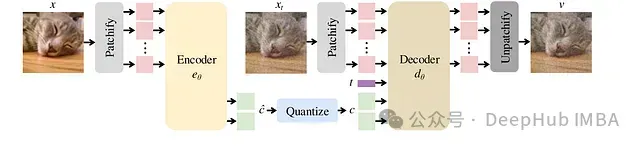
FlowMo: 模式搜索+扩散模型提升图像Token化性能
这个研究提出了FlowMo,一种基于Transformer的扩散自编码器,在多种比特率条件下实现了图像Token化的最新技术水平
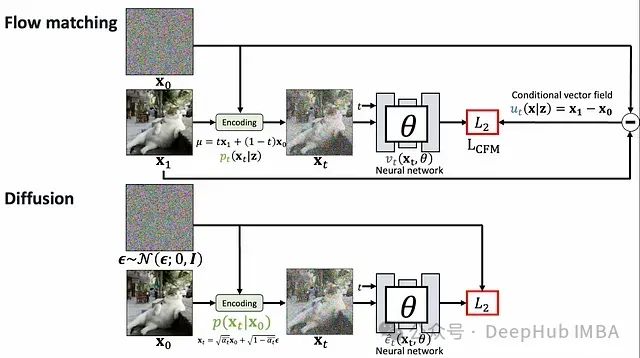
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
生成模型已成为人工智能领域的关键突破,赋予机器创建高度逼真的图像、音频和文本的能力。在众多生成技术中,扩散模型和Flow Matching尤为引人注目。

分布匹配蒸馏:扩散模型的单步生成优化方法研究
分布匹配蒸馏(Distribution Matching Distillation,DMD)通过将多步扩散过程精简为单步生成器来解决这一问题。该方法结合分布匹配损失函数和对抗生成网络损失,实现从噪声图像到真实图像的高效映射,为快速图像生成应用提供了新的技术路径。
【AI学习】DDPM 无条件去噪扩散概率模型实现(pytorch)
无条件噪声扩散模型pytorch简单实现。
AI:298-深入扩散模型-实现高质量图像生成的原理与实践
扩散模型是一类基于随机过程的生成模型,利用扩散(Diffusion)和去噪(Denoising)的机制逐步生成目标图像。该模型最初由Sohl-Dickstein等人在2015年提出,但近些年才随着深度学习的发展重新引起了广泛关注。从噪声开始:首先从标准正态分布中随机采样一个噪声图像xTx_TxT。
AI:284-扩散模型深度解析-从图像生成原理到与YOLO的创新融合
扩散模型近年来在生成任务上表现出了卓越的效果,尤其是在图像生成领域。这篇文章将介绍扩散模型的核心思想,从高斯噪声到生成图像的整个过程,并结合具体的数学原理来解释这一方法的工作机制。最后,我们将展示一个基于Python的代码实例来演示扩散模型的实现。
AI:269-无条件扩散模型详解-原理、实现与应用
无条件扩散模型是生成模型领域中的一种有趣方法。与有条件扩散模型根据特定输入生成数据不同,无条件模型的目标是在没有明确条件的情况下从分布中生成样本。本文将探讨无条件扩散模型的工作原理,通过示例代码展示其实现,并讨论结果。扩散模型是一类生成模型,其工作原理是模拟逐渐向数据中添加噪声的过程,然后学习如何逆
AI:267-深入扩散模型组件测试:从调度器到 UNet 模型的代码实战
是diffusers库中的一个调度器,用于控制扩散模型的步长与噪声混合方式。它负责在每个时间步为图像添加或去除噪声,从而实现扩散过程。该类支持从预训练模型中加载参数,帮助开发者快速测试不同的扩散步数效果。本文中的代码片段将演示如何通过简单的图像噪声混合实验来测试调度器的工作情况。通过本文的探讨,我们
最新综述:多模态引导的基于文生图大模型的图像编辑算法
近期,复旦大学 FVL 实验室和南洋理工大学的研究人员对于多模态引导的基于文生图(Text-to-Image,T2I)大模型的图像编辑算法进行了总结和回顾。综述涵盖 300 多篇相关研究,调研的最新模型截止至今年 6 月。图2.综述框架旨在根据用户的特定需求编辑给定的合成图像或真实图像。作为人工智能
扩散模型理论与公式推导——详细过程速览与理解加深
推荐在简单了解扩散模型原理后再来看本篇文章,加深对理论的理解,本篇只叙述有关扩散模型公式理论的推导~
ECCV2024中有哪些值得关注的扩散模型相关的工作?
通过广泛的人类评估和基于GPT的组合评估,RFNet在生成现实和幻想场景方面优于现有方法。实验结果表明,RFNet在处理需要高度创造力和抽象思维的提示时,能够生成更准确、更具一致性的图像,展示了其在文本到图像生成任务中的优越性能。研究者们提出了Realistic-Fantasy Network (R
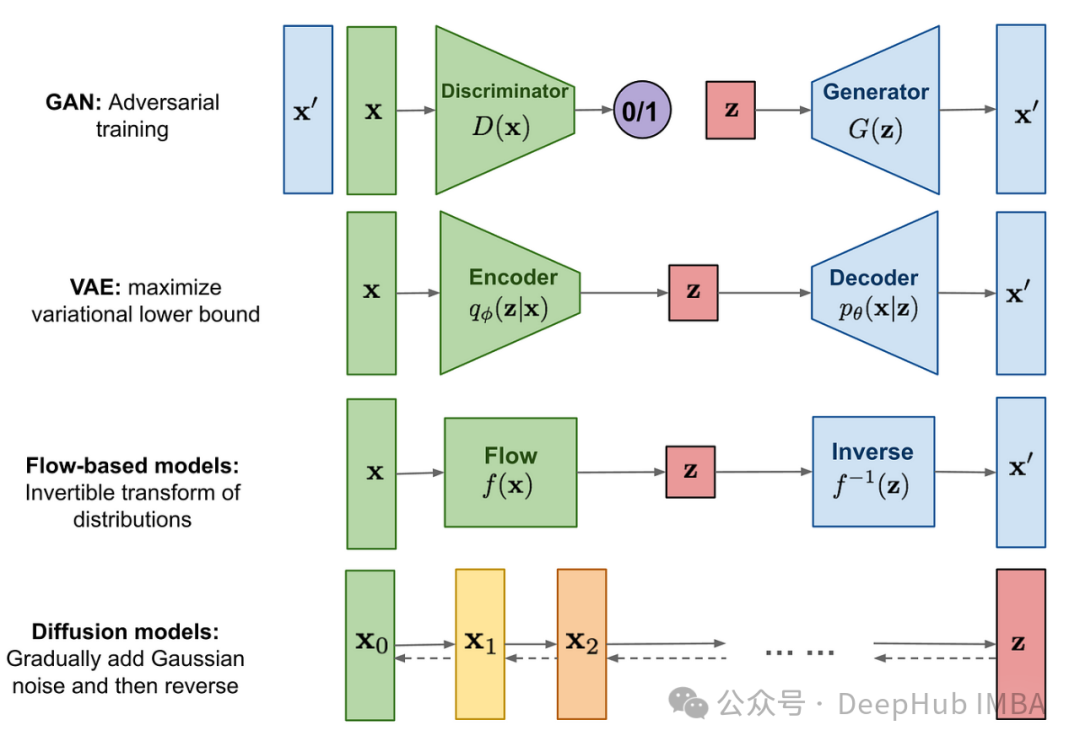
使用Pytorch中从头实现去噪扩散概率模型(DDPM)
在本文中,我们将构建基础的无条件扩散模型,即去噪扩散概率模型(DDPM)。从探究算法的直观工作原理开始,然后在PyTorch中从头构建它。本文主要关注算法背后的思想和具体实现细节。
基于 Amazon EC2 快速部署 Stable Diffusion WebUI + chilloutmax 模型
自2023年以来,AI绘图已经从兴趣娱乐逐渐步入实际应用,在众多的模型中,作为闪耀的一颗明星,Stable diffusion已经成为当前最多人使用且效果最好的开源AI绘图软件之一。Stable Diffusion Web UI 是由AUTOMATIC1111 开发的基于 Stable Diffus
手把手写深度学习(25):下载并清洗WebVid-10M数据集
WebVid-10M是一个大型文本-视频配对数据集,时至今日,依旧是做视频理解、视频生成等任务的首选数据集。这篇博客手把手详细教大家如何下载和清洗这个数据集。
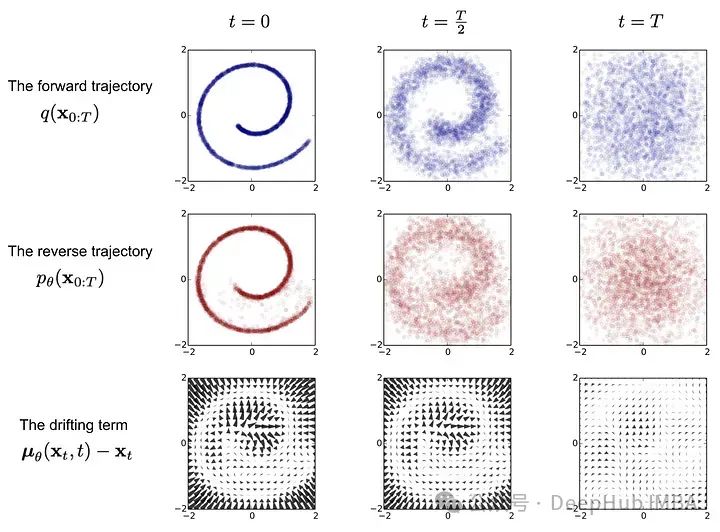
扩散模型的多元化应用:药物发现、文本生成、时间序列预测等
今天我们就来研究一下扩散模型的多元化应用。
【AI视野·今日CV 计算机视觉论文速览 第303期】Wed, 6 Mar 2024
AI视野·今日CS.CV 计算机视觉论文速览Wed, 6 Mar 2024Totally 85 papers👉上期速览✈更多精彩请移步主页Daily Computer Vision PapersFAR: Flexible, Accurate and Robust 6DoF Relative Cam
Diffusion Models视频生成-博客汇总
Diffusion Models 视频生成 博客汇总
- 1
- 2



