
大语言模型(LLMs)在智能代理任务中发挥着重要作用,尤其是在网络导航方面。然而,现有的代理在真实世界的网页上表现不佳,主要原因网络导航代理面临着三大挑战:网页上行动的多样性、HTML文本的处理限制以及开放领域决策的复杂性。为了克服这些挑战,AUTOWEBGLM采用了基于ChatGLM3-6B模型的架构,并通过创新的HTML简化算法和混合人类-AI数据构建方法,显著提升了代理的性能。
AUTOWEBGLM的设计灵感来源于人类的浏览模式,它通过一个精心设计的HTML简化算法来表示网页,同时保留了关键信息。此外,它采用了一种混合的人类-AI方法来构建网络浏览数据,并利用强化学习和拒绝采样(Rejection Sampling Finetuning, RFT)来提升模型的网页理解和浏览器操作效率。

上图展示了AUTOWEBGLM与其他几个模型(包括GPT-3.5-Turbo、GPT-4以及人类)在不同基准测试中的表现对比。这些基准测试包括WebArena、AutoWebBench(英文)、Cross-Task (Mind2Web)、Cross-Website (Mind2Web)和Cross-Domain (Mind2Web)。
从图表中可以看出,AUTOWEBGLM在多数测试中的表现优于GPT-3.5-Turbo和GPT-4,尤其是在Cross-Domain (Mind2Web)任务中,这表明AUTOWEBGLM在跨领域的任务上具有较强的适应性和鲁棒性。

- 上图为AUTOWEBGLM 执行四个示例用户任务的示例*
方法
网络浏览任务被构建为一个序列决策过程,其中包括定义状态集合和行动集合。状态集合包含了当前页面的状态,如HTML内容、URL和窗口位置,而行动集合则包含了所有可能的浏览操作,例如点击、滚动、输入文本等。状态的转换由网页的当前状态和代理输出的行动决定,任务在代理输出完成动作或达到最大交互次数时结束。
AUTOWEBGLM系统的架构可以分为两个主要部分:浏览框架和语言模型(LM)代理,它们协同工作以实现自动化的网络浏览任务。
浏览框架
浏览框架位于架构的左侧,负责处理与网页交互相关的任务。它的主要组件包括:
- HTML元素过滤器:筛选网页中的可操作元素,如按钮、链接等。
- 格式化程序:将网页的HTML结构转换成模型易于理解的格式。
- DOM截图:提供网页的屏幕截图,帮助模型理解网页布局。
- HTML解析器:解析网页的HTML代码,提取网页的结构和内容信息。
- OCR模块:识别网页图像中的文字,使模型能够理解图像中包含的文本信息。
语言模型(LM)代理
LM代理位于架构的右侧,是系统的智能决策中心。它使用以下组件来处理信息和生成操作:
- 观察空间:收集和整合来自浏览框架的信息,包括简化后的HTML、当前网页位置、之前的操作记录等,为模型提供决策所需的上下文。
- 指令:LM代理根据用户的任务指令来确定需要完成的目标。
- 多步追踪:记录和分析用户的操作序列,以便模型能够理解完成任务所需的步骤。
- 匹配规则:用于确定用户操作与网页元素之间的对应关系。
- 手动注释:在需要时,提供手动标注的数据以辅助模型学习。
- 数据收集:收集用于训练模型的数据,包括用户指令、网页信息和操作序列。
- 强化学习(RL) 和 拒绝采样微调(RFT):通过这两种方法,模型能够从自己的操作中学习并提升性能,特别是在特定网络环境中的专业性。
交互和迭代
在这两个主要部分之间,存在一个迭代的循环过程:LM 代理预测操作,然后浏览框架执行这些操作,并观察结果。这个过程不断重复,直到任务完成。LM 代理还利用强化学习和拒绝采样微调(Rejection Sampling Finetuning, RFT)技术来提升自身的性能,使其能够从错误中学习,并在特定网络环境中变得更加专业。
- 动作预测:LM代理根据当前状态和历史信息预测下一步操作。
- 动作执行:浏览框架执行LM代理预测的操作,如点击、滚动或输入文本。
- 状态更新:执行操作后,浏览框架更新网页状态,并将新的状态信息反馈给LM代理。
- 自我提升:LM代理通过强化学习和拒绝采样微调不断优化其决策过程,提高在复杂网络环境中的性能。

上图展示了 AUTOWEBGLM 系统的架构图,该图详细描述了系统的两个关键组成部分:浏览框架(Browsing Framework)和语言模型(LM)代理。输入接口包括对 LM 代理的任务描述和简化后的 HTML 页面,而输出则是 LM 代理基于当前网页状态和历史信息所做出的操作决策。这些操作通过自动化浏览程序执行,从而实现对网页的导航和交互。
为了提高模型对网页的理解和操作水平,研究者定义了一个统一的观察空间,它提供了接近浏览器图形界面所提供的信息。观察空间包括任务描述、简化HTML、当前位置和过去操作记录四个关键指标。这些信息帮助模型理解其在网页中的位置,提供历史背景,并生成更一致的后续操作。
行动空间的构建基于语言模型能够执行的可能性,定义了一系列函数调用,以便语言模型在网络浏览世界中执行操作。这些操作包括点击元素、悬停、选择选项、输入文本、滚动页面、前进或后退、跳转到URL、切换标签页等。
数据准备

行动空间是指在网络浏览任务中,模型可以执行的所有潜在操作的集合。这些操作模拟了用户与网页交互时可能采取的行为。
- 点击(click):模拟用户点击页面上特定元素的操作。
- 悬停(hover):模拟用户将鼠标悬停在某个元素上的动作。
- 选择(select):在下拉菜单中选择一个选项。
- 输入(type_string):在输入框中键入文本。
- 滚动页面(scroll_page):向上或向下滚动页面。
- 前进/后退(go):在浏览历史中前进或后退。
- 跳转到URL(jump_to):跳转到指定的网址。
- 切换标签页(switch_tab):在浏览器的不同标签页之间切换。
- 用户输入(user_input):提示用户输入信息或与代理交互。
- 结束任务(finish):完成任务并输出结果。
这些操作被设计为函数调用,使得语言模型能够以一种结构化和一致的方式来执行网络浏览任务。通过这样的设计,AUTOWEBGLM 能够模拟真实用户的行为,自动完成复杂的网络任务。*Table 1 的定义对于训练和评估模型的性能至关重要,因为它确立了模型需要学习和执行的具体行为。*
创建训练数据集面临多种挑战,包括任务收集的多样性、隐私和安全限制、目标标注的劳动密集性以及模型限制。为了解决这些问题,研究者提出了一种混合人类-AI数据构建方法,该方法涉及以下步骤:
- Web识别和简单任务操作构建:通过收集主流网站的URL,使用HTML解析器识别可操作组件,并生成简化的HTML表示。然后,设计任务,如网站和组件功能描述,以帮助模型识别网页结构和交云组件的功能。
- 复杂任务操作构建:开发了一个包含真实世界复杂网络浏览任务的数据集,每个样本包括任务描述、完成任务的操作序列和每个步骤的意图。
- AutoWebBench构建:将复杂任务操作数据集分割为评估基准测试集AutoWebBench,包括领域内和领域外的数据,以评估模型的性能。

AUTOWEBGLM的数据构建流程主要阶段:简单任务构建和复杂任务构建。
训练
训练AUTOWEBGLM模型的三个步骤,这些步骤涉及不同的训练策略和技术,旨在提升模型在网络浏览任务中的表现。以下是如何进行训练的详细说明:
第一步:Curriculum Learning(课程学习)
- **Supervised Fine-Tuning (SFT)**:使用构建的数据集对模型进行监督式微调。这个过程增强了模型对网页的理解能力以及在环境中执行操作的能力。
- **Curriculum Learning (CL)**:采用课程学习的方法,即让模型从简单样本开始学习,然后逐渐过渡到复杂样本。这种方法模仿了人类的学习过程,并已被证明可以显著提升模型的能力。
第二步:Reinforcement Learning(强化学习)
- Self-Sampling:使用SFT训练后的模型(MSFT)对复杂任务操作样本进行自我采样,生成正面和负面的对比数据。
- **Direct Preference Optimization (DPO)**:结合DPO训练方法,使MSFT从错误中学习,进一步提升其能力。在训练过程中,为了增加稳定性,研究者们提出将DPO损失与SFT损失结合,通过调整两者的比例,来优化模型。
第三步:Rejection Sampling Finetuning(拒绝采样微调)
- Targeted Training:在特定领域的网页环境中进行有针对性的训练。通过从现有模型中大量采样,并使用奖励信号选择准确轨迹。
- Reward Signals:奖励信号可以由环境本身提供,也可以通过预先设计好的奖励模型来确定。在沙盒环境中进行实验,以避免真实网页环境中的网络策略限制。

Table 2 和 Table 3 展示了AUTOWEBGLM在不同网络浏览基准测试中的表现。Table 2* 着重于模型在AutoWebBench基准上的步骤成功率(Step Success Rates, SSR),并对比了包括GPT-3.5-Turbo、GPT-4在内的其他模型以及人类的表现。结果显示AUTOWEBGLM在跨任务和跨领域的表现上均优于基线模型。*
Table 3 则聚焦于Mind2Web基准测试,提供了模型在跨任务(Cross-Task)、跨网站(Cross-Website)和跨领域(Cross-Domain)场景下的平均步骤成功率。AUTOWEBGLM在所有场景中均展现出较高的性能,与其它模型相比,它在理解和执行复杂网络任务方面具有显著的优势。这些表格证明了AUTOWEBGLM在多样化网络环境中的鲁棒性和有效性。
实施训练的具体步骤:
- 数据准备:根据2.3节中的方法,准备包括网页识别、简单任务操作和复杂任务操作的数据集。
- 模型初始化:使用ChatGLM3-6B作为基础模型进行初始化。
- SFT训练:在第一阶段,使用构建的数据集对模型进行监督式微调。
- DPO训练:在第二阶段,通过自我采样和强化学习进一步训练模型。
- RFT训练:在第三阶段,进行拒绝采样微调,优化模型在特定领域的性能。
- 评估与调整:在每个阶段后评估模型性能,并根据需要调整训练策略和参数。
通过这三个步骤,AUTOWEBGLM模型能够学习如何理解和操作网页,以及如何在复杂的网络环境中做出决策,最终达到执行复杂网络浏览任务的目标。
简化算法的伪代码
算法是AUTOWEBGLM系统中的一个关键组件。目的是将复杂的HTML网页转换为一个简化的版本,使大型语言模型(LLMs)能够更有效地处理和理解网页内容。

算法输入:
tree:表示原始的HTML DOM树。kept:需要保留的元素列表。rcc:递归计数,用于控制递归深度。d:最大深度参数。mc:最大子节点数参数。ms:最大兄弟节点数参数。
算法输出:
pruned tree:简化后的HTML DOM树。
算法步骤:
- 初始化一个空列表
nodes,用于存储需要保留的节点。 - 对于每个递归计数
t(从0到rcc),执行以下操作: - 遍历所有需要保留的元素id。- 从tree中找到对应的元素node并将其添加到nodes列表中。- 递归地获取该node的祖先节点(getAnscendants),并将它们也添加到nodes中,但不超过d层深。- 获取node的子孙节点(getDescendants),同样不超过d层深,并且限制子孙节点的数量不超过mc。- 获取node的兄弟节点(getSiblings),限制兄弟节点的数量不超过ms。 - 更新
d、mc和ms参数,使它们在下一次迭代中变得更小,这有助于进一步简化树结构。 - 遍历
tree中的节点,逆序检查每个节点: - 如果节点不在nodes列表中,或者节点没有文本、属性、子节点数少于2或者不是根节点,则从tree中移除该节点。
实验
主要结果
实验部分首先介绍了AUTOWEBGLM在不同基准测试集上的表现。研究者们建立了一个双语(中文和英文)基准测试集AutoWebBench,用于评估真实世界的网络浏览任务。此外,AUTOWEBGLM还在其他三个已建立的网络导航基准测试集上进行了测试:Mind2Web、MiniWoB++和WebArena。
- AutoWebBench:测试集分为中文、英文、领域内和领域外四个部分,使用步骤成功率(Step Success Rate, SSR)作为评估指标。结果显示,经过多任务训练的AUTOWEBGLM在预测一般用户操作模式方面表现出色,与其他基线模型相比,能够更准确地学习基于网页内容和任务描述的用户操作。
- Mind2Web:使用Mind2Web的设置和SSR作为主要评估指标。研究者们利用MindAct框架评估模型性能,并与参考文献中的基线结果进行了比较。
- MiniWoB++ 和 WebArena:在MiniWoB++上,研究者们测试了56个任务,每个任务运行100次评估周期。对于WebArena,他们将HTML解析器模块和动作执行模块集成到WebArena环境中,以适应他们的系统。测试结果列在表格中,并与参考文献中的基线结果进行了比较。

图表中列出了不同模型在完成网络任务时的成功率,并特别标注了() 表示这些模型在其相关的任务数据集上进行了单独的微调(individual finetuning)。*
微调意味着这些模型针对特定的任务或数据集进行了额外的训练,以提高它们在类似任务上的性能。通过这种方式,模型能够更好地适应特定的任务需求,从而在基准测试中取得更好的成绩。
消融研究 (3.2 Ablation Study)
为了评估不同阶段数据和训练策略对模型性能提升的影响,研究者们进行了消融研究:
- 训练数据消融:通过只训练包含原始训练集的模型,并结合简单和复杂任务数据进行训练,来定性衡量不同数据集对模型的影响。研究发现,复杂任务数据集显著提高了模型性能,而简单任务数据集在与复杂任务数据集联合训练时也有显著提升。
- 训练策略消融:比较了监督式微调(SFT)、直接偏好优化(DPO)和拒绝采样微调(RFT)增强模型的结果。研究发现,DPO训练有助于模型从错误中学习,进一步提升性能;RFT使模型能够在不同领域进行自举增强,通过实践提高领域内的专业水平。
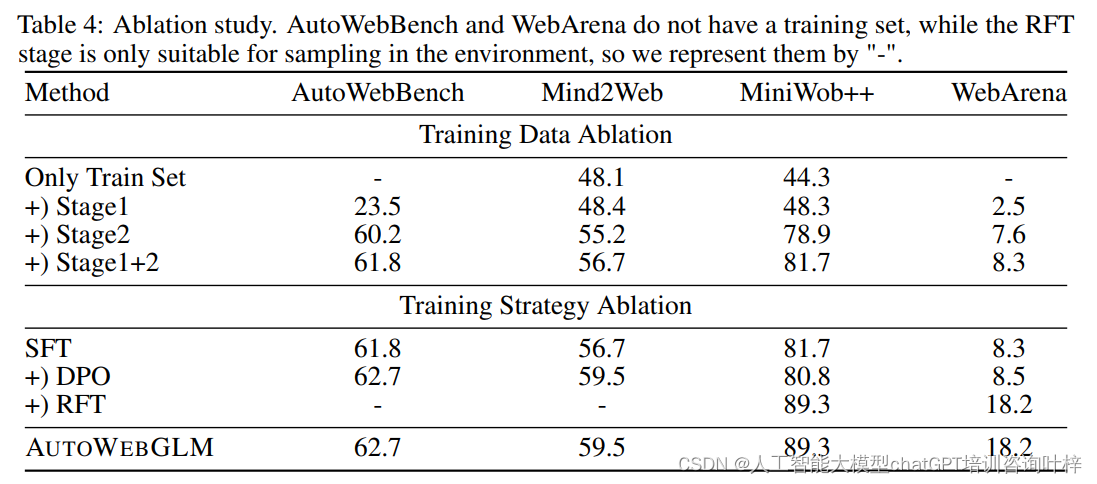
AutoWebBench和WebArena这两个基准测试集。它们在消融研究中的表示方式是"-",原因如下:
- AutoWebBench和WebArena没有训练集:这意味着在消融研究中,没有可用于训练的数据集。消融研究通常需要一个训练集来观察移除或修改某些部分对模型性能的影响,但由于这两个基准测试没有提供训练集,因此无法进行常规的消融分析。
- RFT阶段仅适用于环境采样:拒绝采样微调(Rejection Sampling Finetuning, RFT)阶段是训练过程中的一部分,它依赖于在特定环境中的采样来优化模型。由于RFT是为了在特定网页环境中提高模型的专业性而设计的,因此它不适合传统的消融研究方法,这也可能是为什么在消融研究中用"-"表示的原因。
简而言之,Table 4中的"-"表示在消融研究中无法对AutoWebBench和WebArena进行常规的分析,因为缺少训练集,同时RFT阶段的训练方法与消融研究的目的和方法不完全兼容。这表明在评估AUTOWEBGLM模型时,需要考虑这些基准测试集和训练阶段的特殊性。
AUTOWEBGLM的研究不仅推动了网络导航技术的发展,也为未来智能代理的研究奠定了基础。通过结合先进的数据处理技术和机器学习算法,AUTOWEBGLM证明了LLMs在处理复杂网络任务方面的潜力。随着技术的不断进步,我们可以预见,未来的网络导航将变得更加智能和高效。
论文链接:https://arxiv.org/abs/2404.03648
GitHub 地址:https://github.com/THUDM/AutoWebGLM
版权归原作者 人工智能培训咨询叶梓 所有, 如有侵权,请联系我们删除。