
前言
可能有讲错和没讲清楚的地方,随时私信我或者评论,感谢斧正
1 .构建 Bytetrack 环境
1.1 环境配置
- 下载资源 并 进入环境
git clone https://github.com/ifzhang/ByteTrack.git
cd ByteTrack
或者是直接到这里下载完cd进入
- 基本依赖包安装
pip install -r requirements.txt
python3 setup.py develop
报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte报错:
编辑setup.py,将
with open("README.md","r") as f:
改为
with open("README.md","r", encoding='utf_8') as f:
- 下载pycocotools.
windows下使用该语句会报错
pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'

先下载
pip install cython
- 安装cython_bbox 建议直接移步到Windows搭建ByteTrack多目标跟踪算法
参考文档:Windows搭建ByteTrack多目标跟踪算法
2. 整体代码解析
2.1 对比
模型检测模型区别Strong-SORTyolov5舍弃低分检测结果ByteTrackyolox使用低分检测结果与track进行第二次关联
检测模型是根据demo其给出模型,其他检测模型一般也适用
2.3 BYTETracker类
BYTETracker类只有两个函数
2.3.1 update 函数
主要的变化:在update 函数对低分检测框同样也进行关联(第二次关联)
defupdate(self, output_results, img_info, img_size):#output_results维度:【8400,6】,(x,y,w,h,confidence,cls)
self.frame_id +=1
activated_starcks =[]
refind_stracks =[]
lost_stracks =[]
removed_stracks =[]#-------step1 取出x1,y1,x2,y2,confidence---------------if output_results.shape[1]==5:#
scores = output_results[:,4]#confidence
bboxes = output_results[:,:4]#0,1,2,3分别代表x1,y1,x2,y2else:#一般情况下进这个
output_results = output_results.cpu().numpy()
scores = output_results[:,4]* output_results[:,5]#confidence* 类别置信度
bboxes = output_results[:,:4]# x1y1x2y2
img_h, img_w = img_info[0], img_info[1]
scale =min(img_size[0]/float(img_h), img_size[1]/float(img_w))
bboxes /= scale#缩放#------step2:分为三个部分 将相应结果取出----------------# ------step2.1 划分部分---------# 第一部分remain:scores>track_thresh
remain_inds = scores > self.args.track_thresh#判断类型:返回一个bool类型的tensor
inds_low = scores >0.1
inds_high = scores < self.args.track_thresh
# 第二部分 second:0.1 < scores < track_thresh
inds_second = np.logical_and(inds_low, inds_high)# 第三部分:0.1 > scores :不取出相当于放弃掉# ------step2.1 传入bool类型将对应结果取出---------
dets_second = bboxes[inds_second]#
dets = bboxes[remain_inds]#scores>track_thresh
scores_keep = scores[remain_inds]
scores_second = scores[inds_second]# ------step3 对于检测结果detections和跟踪目标进行关联---------iflen(dets)>0:'''Detections'''#对于高分检测结果创建STrack
detections =[STrack(STrack.tlbr_to_tlwh(tlbr), s)for(tlbr, s)inzip(dets, scores_keep)]else:
detections =[]''' Step 3.1:将新检测到的tracklet添加到tracked_stracks Add newly detected tracklets to tracked_stracks'''#---step3.1遍历之前的轨迹追踪对象track根据状态放入不同列表中---------
unconfirmed =[]
tracked_stracks =[]#新创建的,区别于self.tracked_stracks # type: list[STrack]for track in self.tracked_stracks:#self.tracked_stracks:之前的跟踪ifnot track.is_activated:#is_activated被置为false,一般只有初始化STrack被置为false
unconfirmed.append(track)else:
tracked_stracks.append(track)''' Step 3.2: 第一次关联:使用高分检测框和之前的跟踪轨迹进行关联 First association, with high score detection boxes'''# 联合tracked_stracks和self.lost_stracks还存在的
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)# 使用卡尔曼滤波器预测当前位置 Predict the current location with KF
STrack.multi_predict(strack_pool)
dists = matching.iou_distance(strack_pool, detections)#使用iou_distance计算损失矩阵ifnot self.args.mot20:
dists = matching.fuse_score(dists, detections)#使用包含置信度和iou的混合矩阵#使用匈牙利算法
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)#matches:(追踪,检测)#u_track:没有匹配上的追踪结果,用于第二次关联(低分检测框)#u_detection:没有匹配上的检测结果,用于处理未确认的跟踪轨迹for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]if track.state == TrackState.Tracked:#已经被追踪过的
track.update(detections[idet], self.frame_id)#更新状态和协方差矩阵
activated_starcks.append(track)#放入activated_starcks中,最终更新回tracked_strackselse:#追踪丢失 e.g上一帧被遮拦,这一帧刚好走出被遮拦的区域
track.re_activate(det, self.frame_id, new_id=False)#同样也会更新状态和协方差矩阵
refind_stracks.append(track)''' Step 3.3: 第二次关联:使用低分检测框和之前的跟踪轨迹进行关联Second association, with low score detection boxes'''# association the untrack to the low score detectionsiflen(dets_second)>0:'''Detections'''
detections_second =[STrack(STrack.tlbr_to_tlwh(tlbr), s)for(tlbr, s)inzip(dets_second, scores_second)]else:
detections_second =[]#u_track:匈牙利算法的返回值
r_tracked_stracks =[strack_pool[i]for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]if track.state == TrackState.Tracked:
track.update(det, self.frame_id)#更新状态和协方差矩阵
activated_starcks.append(track)#放入activated_starcks中,最终更新回tracked_strackselse:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)for it in u_track:
track = r_tracked_stracks[it]ifnot track.state == TrackState.Lost:#状态不是lost,直接标记为lost
track.mark_lost()
lost_stracks.append(track)'''Step 3.4:处理未确认的跟踪轨迹tracks,通常只有一个开始帧的跟踪轨迹tracksDeal with unconfirmed tracks, usually tracks with only one beginning frame'''
detections =[detections[i]for i in u_detection]#u_detection:最小损失对应的detection索引,匈牙利算法的返回值
dists = matching.iou_distance(unconfirmed, detections)#unconfirmed:is_activated被置为false,一般只有初始化STrack被置为false#未确认的STrack 没匹配上的检测ifnot self.args.mot20:
dists = matching.fuse_score(dists, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)#提高了上限for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)#-------------Step 4:初始化新的追踪轨迹stracks------------""" Step 4: Init new stracks"""for inew in u_detection:
track = detections[inew]if track.score < self.det_thresh:continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)#-------------Step 5 :更新状态-------""" Step 5: Update state"""for track in self.lost_stracks:if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)# print('Ramained match {} s'.format(t4-t3))
self.tracked_stracks =[t for t in self.tracked_stracks if t.state == TrackState.Tracked]
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)#lost_stracks减去已经追踪到的
self.lost_stracks.extend(lost_stracks)#追加
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)#减去被删除的
self.removed_stracks.extend(removed_stracks)
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)# get scores of lost tracks
output_stracks =[track for track in self.tracked_stracks if track.is_activated]return output_stracks
2.3.1.1 常用函数joint_stracks,sub_stracks
(1)joint_stracks:
主要出现在:
(1)第一次关联
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
(2)update函数最后 更新状态
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
用于将两个list合并起来
defjoint_stracks(tlista, tlistb):
exists ={}
res =[]for t in tlista:#遍历tlista
exists[t.track_id]=1#字典对应id置为1
res.append(t)#增加到res中for t in tlistb:
tid = t.track_id
ifnot exists.get(tid,0):#对应id不存在返回0
exists[tid]=1#置为1
res.append(t)return res
(2)sub_stracks
同样也是主要用于更新状态,更新丢失追踪
self.lost_stracks =sub_stracks(self.lost_stracks, self.tracked_stracks)#lost_stracks减去已经追踪到的
self.lost_stracks.extend(lost_stracks)#追加
self.lost_stracks =sub_stracks(self.lost_stracks, self.removed_stracks)#减去被删除的
用于删除tlista中tlistb 部分
def sub_stracks(tlista, tlistb):
stracks ={}#字典类型
for t in tlista:
stracks[t.track_id]= t
for t in tlistb:
tid = t.track_id
if stracks.get(tid,0):#在stracks不存在该id返回值为0
del stracks[tid]returnlist(stracks.values())#直接返回字典类型的值,并转化为list
2.4 STrack类
主要是以下几个函数
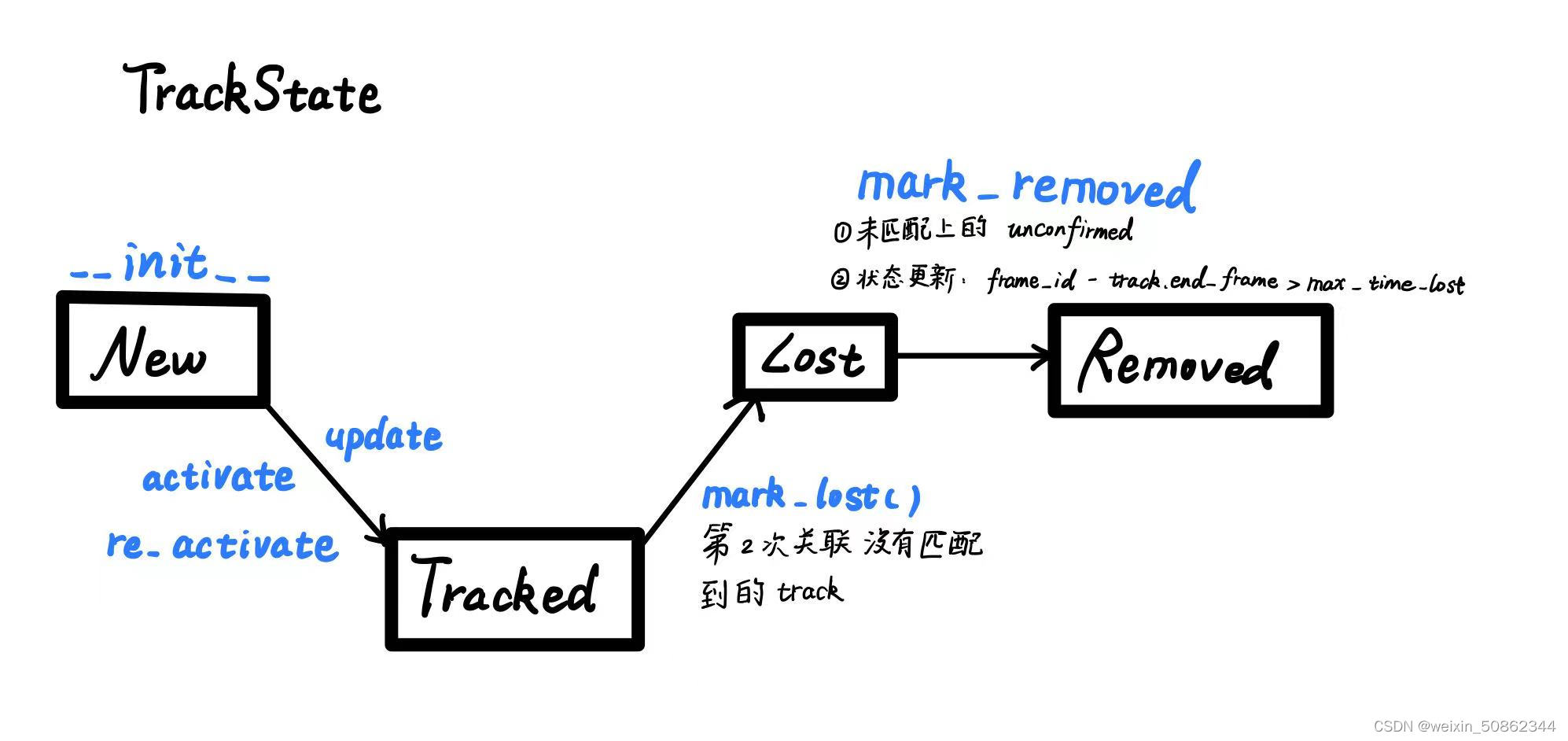
2.3.1 TrackState变化图
2.3.2 predict 和 multi_predict
defpredict(self):
mean_state = self.mean.copy()if self.state != TrackState.Tracked:
mean_state[7]=0
self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)@staticmethoddefmulti_predict(stracks):#更新所有track的状态向量和协方差矩阵iflen(stracks)>0:#将所有stack的状态向量和协方差存放起来
multi_mean = np.asarray([st.mean.copy()for st in stracks])#状态向量 数组
multi_covariance = np.asarray([st.covariance for st in stracks])#协方差矩阵for i, st inenumerate(stracks):if st.state != TrackState.Tracked:
multi_mean[i][7]=0#状态向量0-6:(x, y, a, h) 及对应的速度 multi_mean[i][7]==》Vh#使用卡尔曼滤波进行预测
multi_mean, multi_covariance = STrack.shared_kalman.multi_predict(multi_mean, multi_covariance)for i,(mean, cov)inenumerate(zip(multi_mean, multi_covariance)):
stracks[i].mean = mean
stracks[i].covariance = cov
(1)都是使用卡尔曼滤波进行预测
使用的函数分别是
kalman_filter.predic
t和
STrack.shared_kalman.multi_predict
(后面讲)
(2)multi_predict将全部track的状态向量放入一个数组
2.3.3 activate
用于初始化新的轨迹
track.activate(self.kalman_filter, self.frame_id)
2.3.4 re_activate & update
示例:
if track.state == TrackState.Tracked:#已经被追踪过的
track.update(detections[idet], self.frame_id)#更新状态和协方差矩阵
activated_starcks.append(track)#放入activated_starcks中,最终更新回tracked_strackselse:#追踪丢失 e.g上一帧被遮拦,这一帧刚好走出被遮拦的区域
track.re_activate(det, self.frame_id, new_id=False)#同样也会更新状态和协方差矩阵
refind_stracks.append(track)
- (1)update
用于tracked状态(lost)匹配到,正常更新
- (2)re_activate
用于非tracked状态(lost)匹配到了,重新激活
track.re_activate(det, self.frame_id, new_id=False)
用在第1(高分检测框)和2次(低分检测框)关联追踪轨迹,同样也是需要更新的
2.4 KalmanFilter类
其实和StrongSORT中的kalmanFilter大同小异,就不赘述了。
本文转载自: https://blog.csdn.net/weixin_50862344/article/details/127097685
版权归原作者 weixin_50862344 所有, 如有侵权,请联系我们删除。
版权归原作者 weixin_50862344 所有, 如有侵权,请联系我们删除。