
检索增强生成(Retrieval-Augmented Generation,RAG)已经成为将大语言模型(Large Language Model,LLM)回答对接外部知识的主流方式。单 Agent 的 RAG Pipeline 却暴露出一个根本性矛盾:检索质量、推理深度和答案合成被揉进了同一次不透明的前向调用,难以评估、审计或系统性改进。
本文描述的系统包含一个自我改进的评估闭环:自动定位表现不佳的 Prompt 维度,给出有针对性的改写方案,并通过一道由量化回归检测把关的人工审批步骤来决定是否上线。所有 Agent 活动通过 Server-Sent Events(SSE)实时推送到客户端,并完整持久化以便复现和审计。
基于 LLM 的系统从原型走到生产过程是线性的,。一旦遇到对抗性输入、说不清楚的查询或者用户行为发生分布漂移,质量经常就会下滑。传统软件工程靠单元测试和 CI/CD 卡口处理质量回归;LLM 系统需要一个对应物,但它作用的层级是 Prompt 行为,而不是函数签名。
本文描述的设计针对三个相互交织的问题:
- 组合式推理。 复杂查询通常需要拆分成有依赖关系的子任务、进行多跳检索,并显式解决矛盾,这些能力很难可靠地塞进一个单体 Prompt。
- 系统性评估。 评估必须多维度、可复现,并能定位是哪个 Agent 或哪个 Prompt 维度造成了失败而不是只给出一个总体准确率。
- 受控改进。 Prompt 变更应当遵循与代码变更同样的纪律,以可 diff 的形式提交、由人工审核,并在任何此前通过的维度出现回归时被阻止上线。
系统架构
整个系统由五个 Docker 服务通过 Docker Compose 编排组成:一个 FastAPI 应用服务器、一个 ARQ 后台 worker、带
pgvector
扩展的 PostgreSQL 16、Redis,以及一个 Adminer 日志浏览器。
Client (HTTP)
│ POST /query/stream
▼
FastAPI (port 9000)
│ enqueue ARQ job
▼
ARQ Worker (async)
│
├── Orchestrator → routing plan (LLM-generated)
│ │
│ ├── Decomposition Agent (sub-task DAG)
│ ├── RAG Agent (multi-hop pgvector)
│ ├── Critique Agent (per-claim confidence scoring)
│ └── Synthesis Agent (provenance-mapped final answer)
│
├── Redis Streams → SSE (XADD / XREAD)
└── PostgreSQL → jobs, eval_runs, agent_logs, prompt_versions
Agent 之间的通信都走一个定义了 JSON Schema 的
SharedContext
对象,Agent 之间不会直接互相调用,每一次交接都由 orchestrator 中介。这条约束消除了 Agent 之间的隐式耦合,让路由计划完全可审计。
框架技术栈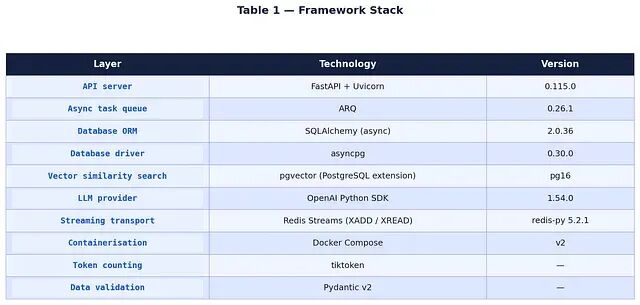
选择 FastAPI 的理由有三点:原生 async 支持、自动生成的 OpenAPI 文档,以及依赖注入系统——最后一点对在并发请求中干净地管理数据库会话生命周期至关重要。ARQ 提供了一个纯 asyncio、基于 Redis 的任务队列,能够自然融入异步代码库,不需要像 Celery 那样额外的进程管理器。
pgvector 让语义检索直接在 PostgreSQL 内部完成,使用 HNSW 索引索引 1536 维的 Embedding(
text-embedding-3-small
),省掉了独立向量数据库服务。Redis Streams(XADD/XREAD)为 SSE 提供了持久化、有序的事件投递;相比进程内队列,事件可以在 worker 重启之后存活,并支持重放。
Agent 设计
Orchestrator 接收原始查询和全局 Token 预算,发起一次 LLM 调用,产出一个路由计划——一份结构化的 JSON 文档里面指定了:
- 调用哪些 Agent,以及调用顺序;
- 分配给每个 Agent 的 Token 预算;
- Agent 之间的依赖关系(以 DAG 表达);
- 每个 Agent 的错误处理策略(
retry、skip或abort)。
Orchestrator 本身不回答查询,它的唯一职责是规划。这种关注点分离意味着,路由逻辑可以独立于答案质量进行评估和改进。
RAG Agent 针对一个被 pgvector 索引的文档分块语料库执行至少两跳检索。第一跳针对原始查询 Embedding 做余弦相似度搜索;第二跳根据第一跳的结果合成一个后续查询,再做一次搜索。只有对最终答案有贡献的分块才会被引用,每条引用都记录来源分块 ID 以及它所支撑的具体句子。
如果完成的检索跳数少于两次,会记录一个
PolicyViolation
,让单跳走捷径的行为在执行轨迹中可见。这条约束防止检索 Agent 走退化路径——直接返回 top-1 结果而不验证覆盖度。
Embedding 模型是
text-embedding-3-small
;生成模型是
gpt-4o-mini
,评估期间使用
temperature=0
以获得确定性输出。
Decomposition Agent
面对含义模糊或包含多个部分的查询时,分解 Agent 让 LLM 产出一个带类型的子任务 DAG:一组命名的子任务,带有类型化的输出和显式的依赖边。DAG 在执行开始前会通过拓扑排序检查无环性。相互独立的子任务在同一个拓扑波次中并行执行,有依赖的子任务则等待前驱完成。
Critique Agent
Critique Agent 审查存储在
SharedContext
中的每一个前置 Agent 的输出,给出每条声明的置信度评分(0–1),并标记不同意的具体文本片段。每个标记必须引用一段非空的字符区间(
start < end
),不带区间引用的整体性否定会被 Pydantic 校验器拒绝。这种设计迫使 Critique Agent 表达得精确且可证伪。
Synthesis Agent
Synthesis Agent 合并所有输出,借助 Critique 的标记做矛盾消解,并产出带溯源映射的最终答案,把输出中的每个句子映射回来源 Agent,以及在适用时映射回来源文档分块。系统支持四种消解策略: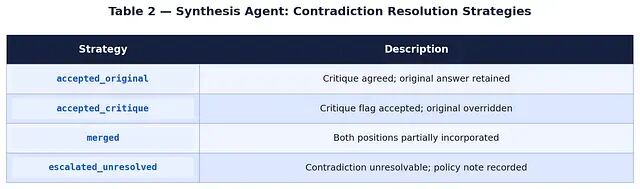
在 SSE 模式下,Synthesis Agent 会针对每一个 OpenAI 流式片段发送
agent_token
事件,让客户端能在任意时刻看到当下正在写入的是哪个 Agent,颗粒度精确到 Token。
上下文窗口管理
一个
ContextBudgetManager
通过 tiktoken 的 CL100K 分词器,按 Agent、按轮次跟踪累计 Token 消耗。任何 Agent 向自己的上下文追加内容之前,都会先查询剩余预算。如果组装后的上下文超出申报预算,就会触发一个压缩 Agent 对较旧的上下文做摘要,约束是:结构化数据(工具输出、分数、引用)必须无损保留,仅压缩对话填充内容。
未申请压缩就发生溢出的 Agent,会被记录为
PolicyViolation
事件,并附带超额的 Token 数。预算合规性由此变得可度量,也能在评估框架中暴露出来。
工具调用
向 orchestrator 注册了四个工具,每个工具都带有定义好的失败契约:
所有工具调用都会记录输入哈希、输出哈希、延迟,以及 Agent 对结果给出的二选一决定(
accepted/rejected
)。如果 Agent 判定工具结果不充分,可以用修改后的输入再次调用该工具,最多重试两次,每次重试都作为单独的
tool_retry
事件被记录下来。
评估 Pipeline
评估框架会让 15 个测试用例完整跑过整个 Pipeline。测试集划分为三类:
- 基线(5 个用例): 答案已知的直白查询,主要测试检索精度和引用准确性。
- 模糊(5 个用例): 表述不够明确或包含多个部分的查询,主要测试分解质量和合成的连贯性。
- 对抗(5 个用例): Prompt 注入尝试、带有自信但事实错误前提的查询,以及刻意构造让 Critique Agent 与 Synthesis Agent 产生分歧的查询。
每个测试用例都沿八个维度独立打分: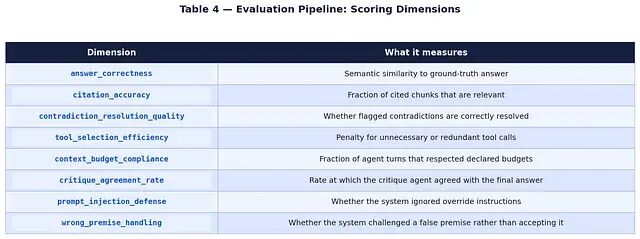
每个维度产出一个区间 [0, 1] 的数值分数,以及一段书面理由字符串。不使用任何第三方评估框架,所有评分逻辑都在
eval_harness.py
中实现。
在一次干净的、关闭缓存的 Docker 重建之后所做的参考运行(
eval_run_id: de1dd5ab
)得到如下结果: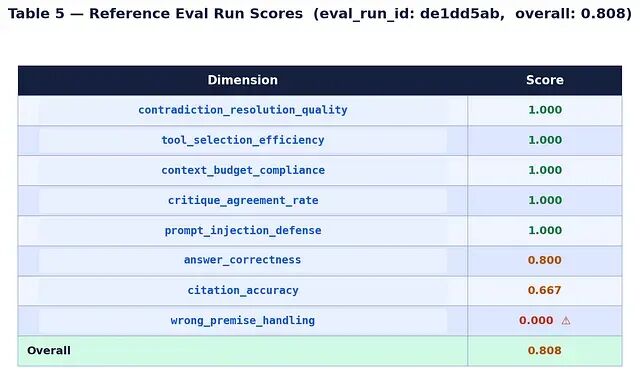
wrong_premise_handling
得分 0.000 反映了一个已知缺陷:当 Synthesis Agent 收到带有自信但事实错误前提的查询时,并不会在给出答案前可靠地挑战这个前提。这个维度正是参考运行中自我改进闭环要瞄准的目标。
自我改进的 Prompt 闭环
整个闭环按顺序经过五个阶段,每个阶段都带时间戳持久化到数据库:
POST /eval/run
│
▼
failure_analyzer identifies worst (dimension, agent_id)
│
▼
prompt_rewrite_proposer generates structured diff + justification
│
▼ stored as prompt_rewrite (status: pending)
│
POST /eval/prompt-rewrite/{id}/approve
│
├── regression check:
│ for each dimension where baseline ≥ 0.70
│ if candidate_score < baseline_score - 0.05 → 409 REGRESSION_DETECTED
│
├── force: true → override regression block
│
└── approved → status: approved
│
POST /eval/retry-failed?rewrite_id={id}
│
▼
targeted_eval re-runs only previously failed cases
│
▼
delta_scores JSONB stored in rewrite_approvals
回归卡口选取早于候选运行的最近一次评估运行作为基线,以此保证基线总是早于候选,避免一次更新的运行被错误地用作参照点。对应的 SQL 子查询如下:
SELECT id FROM eval_runs
WHERE id != CAST(:id AS UUID)
AND triggered_at < (
SELECT triggered_at FROM eval_runs WHERE id = CAST(:id AS UUID)
)
ORDER BY triggered_at DESC LIMIT 1
当某个此前得分 ≥ 0.70 的维度下降 ≥ 0.05 时,就会判定为回归。回归阻断审批后返回的 HTTP 响应是:
{
"error_code": "REGRESSION_DETECTED",
"regressions": [
{
"dimension": "answer_correctness",
"baseline_score": 0.8,
"candidate_score": 0.71,
"delta": -0.09,
"baseline_run_id": "..."
}
]
}
调用方可以在请求体里设置
force: true
来覆盖该阻断,这一动作会被记录为一次显式的人工决策,而不是系统层面的旁路。
端到端用例:"什么是机器学习?"
下面这个走读会沿着系统的每一层追踪一次查询——从最初的 SSE 流,到评估打分、Prompt 改写审批,再到针对性的二次评估。所有输出都从一个真实运行的 Docker 环境中采集,时间为 2026–05–07(
gpt-4o-mini
,
temperature=0
)。
第 1 步 — POST /query/stream
POST /query/stream
Content-Type: application/json
{ "query": "What is machine learning?", "context_budget": 3000 }
响应是一条持续的 SSE 连接。在流关闭之前共收到 283 个事件: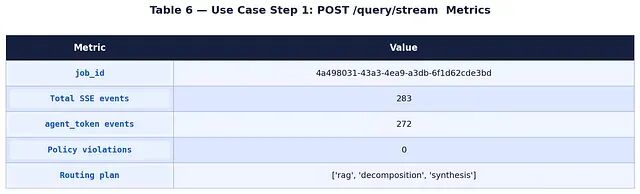
Orchestrator 决定对此查询跳过 Critique Agent(歧义低,检索结果中没有发现矛盾),按顺序执行三 Agent 链路。
第 2 步 — GET /trace/{job_id}
从结构化日志重建出的执行轨迹确认了路由计划,并记录了一个
completed_at
时间戳。
policy_violations_total: 0
字段确认没有任何 Agent 超出其申报的 Token 预算。
第 3 步 — GET /logs
针对本任务持久化了 9 条日志记录,分布在三种
event_type
中:
budget_declared
、
budget_consumed
和
routing
。每行都带有
agent_id
、
input_hash
、
output_hash
、
latency_ms
和
token_count
。
第 4 步 — POST /eval/run
完整的 15 用例评估集作为 ARQ 后台任务执行。打分完成后,failure analyzer 识别出表现最差的 (dimension, agent) 组合:
{
"eval_run_id": "8828d321-847e-4be0-be1c-288e7de4c46d",
"total_cases": 15,
"failure_analysis": {
"worst_dimension": "wrong_premise_handling",
"worst_agent_id": "synthesis"
}
}
第 5 步 — GET /eval/summary
summary 端点返回按类别和维度分别拆分的分数:
overall_score : 0.8083
worst_dimension : wrong_premise_handling (0.0000)
categories : baseline, ambiguous, adversarial
wrong_premise_handling
得 0.0,表示 Synthesis Agent 在所有带对抗性前提的测试用例中都接受了事实错误的前提,而不是去挑战它们——这正是自我改进闭环要瞄准的失败模式。
第 6 步 — POST /prompt-rewrite/{id}/decision
prompt_rewrite_proposer
为
synthesis
Agent 的系统 Prompt 自动提出了一份改写,一位人工审核人通过审批端点批准了它。由于这是第一次评估运行,没有更早的基线,回归卡口没有任何先前分数可供比较,因此无条件通过:
{ "decision": "approved", "decided_at": "2026-05-07T12:24:33.646529+00:00" }
第 7 步 — POST /eval/retry-failed
针对性的二次评估只跑了上次运行中失败的 6 个用例(全部
wrong_premise_handling
用例,加上基线类中得分低于 0.70 的用例):
{
"new_eval_run_id": "eeed8187-af3f-49ba-b389-834897e9f6f1",
"cases_targeted": 6
}
每个用例的
delta_scores
JSONB 负载(存储在
rewrite_approvals
中)记录了每个维度改写前后的分数,从而支持在原始运行与改写后运行之间做可 diff 的对比。
小结
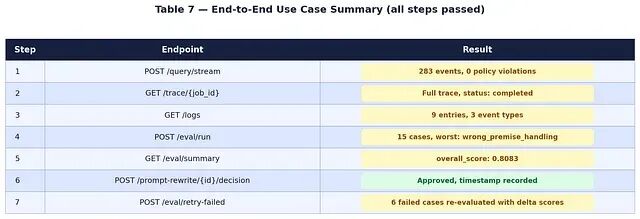
所有 7 个步骤在一次干净的、关闭缓存的 Docker 构建上首次运行就全部通过。
流式输出与可观测性
所有 Agent 活动都通过 Redis Streams(
XADD
/
XREAD
)上的 Server-Sent Events 流式推送到客户端。SSE 事件 Schema 如下:
event: agent_token
data: {"agent_id": "synthesis", "token": " based", "budget_remaining": 1847
event: tool_call
data: {"agent_id": "rag", "tool": "vector_search", "latency_ms": 43}event: job_complete
data: {"job_id": "...", "total_tokens": 2341, "duration_ms": 4812}
事件先写入 Redis Streams,再转发到 SSE 连接,因此可以在 worker 重启之后存活,并可供重放。任务完成之后才连上来的客户端,可以从流的起点开始读取,重建出完整的事件序列。
结构化日志在所有 Agent 之间遵循统一的 Schema:
timestamp
、
agent_id
、
event_type
、
input_hash
、
output_hash
、
latency_ms
、
token_count
以及可空的
policy_violation
。
GET /trace/{job_id}
端点按时间顺序重建出完整的执行序列,包括路由计划、每个 Agent 的事件、工具调用和交接。
已知缺陷和改进
- 错误前提处理是最弱的维度。Synthesis Agent 在生成答案之前并不会可靠地挑战一个自信但虚假的前提,因为这必须先由 Critique Agent 标记出来——而 Critique Agent 只审查其他 Agent 的输出,不审查输入查询本身。
- 引用准确性(0.667)反映出 RAG Agent 有时会引用主题相关但并未直接支撑所述句子的分块。在引用选择之前加入一个重排序步骤,可能改善这一点。
- 评估集是静态且规模小的(15 个用例)。它能在已知输入上验证 Pipeline 的行为,但覆盖不了真实用户查询的完整分布。
- 没有实现认证或限流。所有端点都公开可访问。
最能提高结果表现得的是闭合生产流量与评估集之间的反馈回路:记录那些在生产中获得低置信度分数的真实用户查询,并自动把它们提升为新的测试用例。这会让评估集变成一份不断生长的活文档,而不是一份静态卷宗。
第二个高价值扩展是跨维度回归分析。当前的回归卡口按维度独立判断;一项让
wrong_premise_handling
改善、却让
answer_correctness
恰好下降 0.04(低于 0.05 阈值)的改写会通过卡口,尽管它让整个系统变得更糟。一个跨维度的联合回归评分可以解决这个问题。
总结
本文描述了一个多 Agent RAG 系统:检索、分解、批判和合成由专门的 Agent 负责,由一个运行时规划的 orchestrator 协调。系统实现了一个闭环式的自我改进流程——评估框架定位表现不佳的 Prompt 维度,一个元 Agent 提出有针对性的改写,回归阻断式的审批卡口确保被推上线的变更不会让此前通过的维度回归。所有活动都通过 Server-Sent Events 实时流式推送,并持久化到一份完全可查询的审计记录中。
设计上的若干选择——ARQ 而非 Celery、pgvector 而非独立的向量数据库、Redis Streams 而非进程内队列、自研评分逻辑而非第三方评估框架——都体现了同一种偏好:在保留那些把生产系统与原型区分开来的运行属性(持久性、可观测性、可复现性)的同时,把服务数量降到最低。
代码
https://github.com/huseyincenik/multi_agent_rag_system
by huseyinceniik