
做过检索增强生成(Retrieval-Augmented Generation,RAG)的人大概都遇到过这样的情况:用户问了一个完全合理的问题,但检索就是漏掉了最相关的信息。
传统 RAG Pipeline 不弱,但它严重依赖查询和文档分块之间的直接相似度匹配。措辞和文档内容只要写法不一样这套就开始失灵。
Hypothetical Document Embeddings(HyDE) 不是"搜索文档",而是让系统在检索开始之前,先想清楚理想答案应该长什么样。
传统检索的问题
大多数 RAG 系统的流程很简单:
Query → Embedding → Vector Search → Retrieved Chunks → LLM Response
向量数据库根据语义相似度去检索,但相似不等于相关。
举个例子:
Query:
"How can LangSmith help monitor LLM applications?"
如果存储的分块里从来没出现过 "monitor"、"tracking" 或 "observability",哪怕文档里其实写过答案,检索质量也会掉下来。
由此带来三类典型问题:对未见过的查询检索效果差;在领域专有术语上表现弱;不相关的上下文被送进了 LLM。检索一旦失败,生成基本也跟着崩。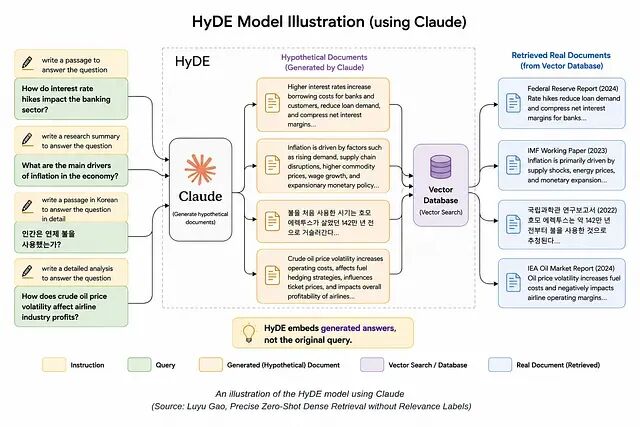
什么是 HyDE
HyDE 是 Luyu Gao 提出的检索技术,思路是:在向量检索之前,先生成一份假设的答案文档。
不是直接把用户查询拿去做 Embedding,而是这样:
User Query
↓
LLM generates hypothetical answer/document
↓
Create embedding of that hypothetical document
↓
Search vector database using this richer embedding
↓
Retrieve better context
核心想法非常简单:生成出来的假设文档,比原始的短查询承载了更丰富的语义。检索系统据此搜索的是"上下文意图",而不只是关键词层面的相似度。
HyDE 内部是怎么跑的
完整流程如下。
1、用户提交查询例如:
"What is LangSmith and why do we need it?"
2、LLM 生成一份假设文档
LLM 写出一段可能回答这个问题的合成文本。
例如:
"LangSmith helps developers monitor, debug, and evaluate LLM applications..."
这份文档并不要求事实完全正确,它要表达的是"一个有用答案大致长什么样"。
3、生成 Embedding
把假设文档转成向量。这个向量通常比直接对原始查询做 Embedding 信息密度高得多。
4、执行向量检索
用这个 Embedding 去向量数据库里做相似度搜索:
Hypothetical Embedding → Similarity Search → Relevant Documents
检索关注的是概念上的相关性,而不是浅层的关键词匹配。
5、生成最终答案
检索到的文档进入 RAG 的生成阶段,从而拿到更准确、更贴合上下文的回答。
这个设计的妙处在于不需要重新训练检索模型。改变查询的表达方式,就能改善检索质量。
LangChain 实现
HyDE 之所以流行起来,原因之一是用 LangChain 有现成的实现我们可以直接拿来用
fromlangchain.embeddingsimportOpenAIEmbeddings
fromlangchain.chat_modelsimportChatOpenAI
fromlangchain.chains.hyde.baseimportHypotheticalDocumentEmbedder
llm=ChatOpenAI(
temperature=0
)
base_embeddings=OpenAIEmbeddings()
hyde_embeddings=HypotheticalDocumentEmbedder.from_llm(
llm=llm,
base_embeddings=base_embeddings,
prompt_key="web_search"
)
query="What is LangSmith and why do we need it?"
embedding=hyde_embeddings.embed_query(query)
LLM 生成假设答案;答案被 Embedding;Embedding 用于检索。代码改动很小,但检索效果可能有不小的提升。
总结
HyDE 在 RAG 应用里尤其有用,特别是:文档很长;术语与用户表述差异大;检索质量不稳定。
传统 RAG 搜索的是"与查询相似的文档",HyDE 搜索的是"与理想答案相似的文档"。一个小小的视角切换,让检索明显聪明了不少。
by Mangesh Jadhav