
谷歌2018年发布的BERT是NLP最有影响力的论文之一。
在本文中,我将进一步介绍BERT,这是最流行的NLP模型之一,它以Transformer为核心,并且在许多NLP任务(包括分类,问题回答和NER)上均达到了最先进的性能。
具体地说,与其他关于同一主题的文章不同,我将试着浏览一遍极具影响力的BERT论文——Pre-training of Deep Bidirectional Transformers for Language Understanding,同时将尽量是用通俗的描述而不使用术语,并尝试通过草图解释BERT是如何工作的。
那么,什么是BERT?
简单地说,BERT是一个可以用于很多下游任务的体系结构,如回答问题、分类、NER等。我们可以假设预先训练的BERT是一个黑盒,它为序列中的每个输入令牌(词)提供了H = 768维的向量。序列可以是单个句子或由分隔符[SEP]分隔并以标记[CLS]开头的一对句子。在本文的后续阶段,我们将更详细地解释这些令牌。
这个黑盒有什么用?
BERT模型的工作原理与大多数Imagenet深度学习模型的工作方式相同。首先,在大型语料库(Masked LM任务)上训练BERT模型,然后通过在最后添加一些额外的层来微调我们自己的任务的模型,该模型可以是分类,问题回答或NER等。
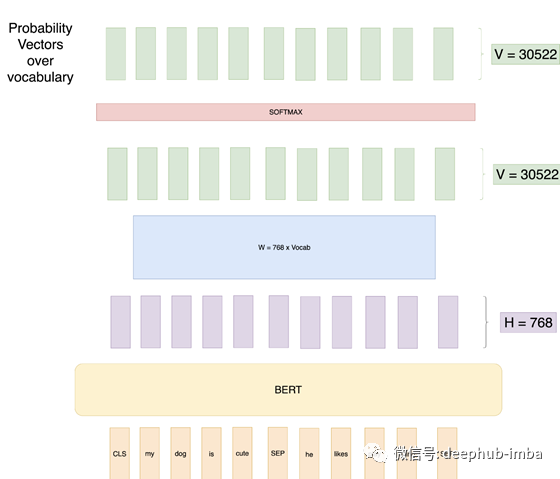
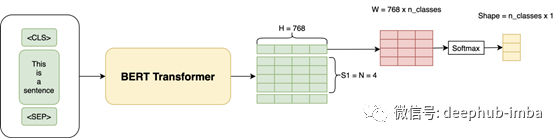
例如,我们将首先在像Wikipedia(Masked LM Task)这样的语料库上训练BERT,然后根据我们自己的数据对模型进行微调,以执行分类任务,例如通过添加一些额外的层将评论分类为负面,正面或中立。实际上,我们仅将[CLS]令牌的输出用于分类任务。因此,用于微调的整个体系结构如下所示:
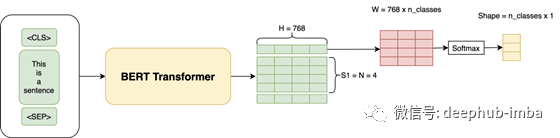
所有深度学习都只是矩阵乘法,我们只是引入一个新的W层,其形状为(H x num_classes = 768 x 3),并使用我们的训练数据来训练整个架构并使用交叉熵损失进行分类。
一个人也可能只是通过最后一层获得了句子特征,然后在顶部运行了Logistic回归分类器,或者对所有输出取平均值,然后在顶部运行了Logistic回归。有很多可能性,哪种方法最有效将取决于任务的数据。
在上面的示例中,我解释了如何使用BERT进行分类。以非常相似的方式,也可以将BERT用于问题解答和基于NER的任务。在本文结尾处,我将介绍用于各种任务的体系结构。
它和嵌入有什么不同呢?
你已经了解要点了。本质上,BERT只是为我们提供了上下文双向嵌入。
上下文:单词的嵌入不是静态的。也就是说,它们取决于单词周围的上下文。所以在“one bird was flying below another bird”这样的句子中,“bird”这个词的两次嵌入就会有所不同。
双向:虽然过去的定向模型(如LSTM)是按顺序读取文本输入(从左到右或从右到左),但Transformer实际上是一次性读取整个单词序列,因此被认为是双向的。
所以,对于像“BERT model is awesome”这样的句子。单词“model”的嵌入将包含所有单词“BERT”、“Awesome”和“is”的上下文。
现在我们了解了基本原理;我将把本节分为三个主要部分——架构、输入和训练。
体系结构
通俗的讲:BERT基本上是由编码器层堆叠而成。
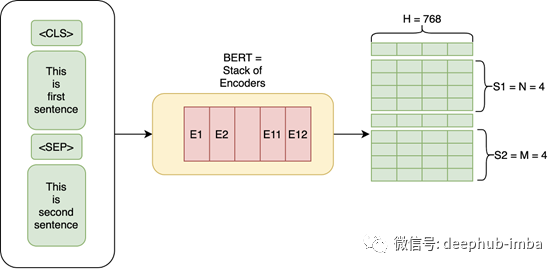
在本文中,作者实验了两种模型:
BERT Base:层数L=12,隐含层大小H=768,自我注意头A=12,总参数=110M
BERT Large:层数L=24,隐含层大小H=1024,自我注意头A=16,总参数=340M
训练输入
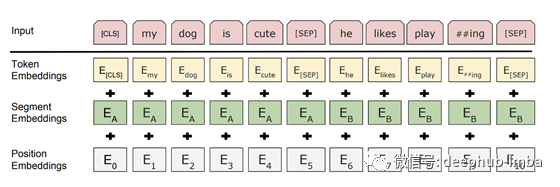
我们用上面的结构给BERT输入。输入包括一对被称为序列的句子和两个特殊标记——[CLS]和[SEP]。
所以,在这个例子中,两个句子“my dog is cute”,“he likes playing”,BERT首先使用词片标记化将序列转换为标记,并在开头添加[CLS]标记,并在其中添加[SEP]标记 第二句话的开头和结尾,因此输入为:

BERT中使用的字词标记化必然会将单词打乱成“ play”和“ ## ing”之类的词。这有两个方面的帮助-
- 它有助于限制词汇量,因为我们不必在词汇表中保留各种形式的单词,例如playing, plays, player 等。
- 它可以帮助我们避免出现含糊不清的单词。例如,如果词汇表中没有plays ,我们可能仍会嵌入play 和##s
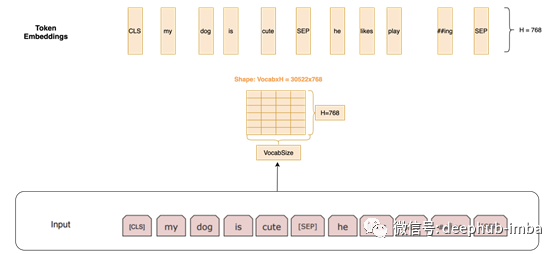
令牌嵌入:然后,我们通过索引大小为30000x768(H)的矩阵来获得令牌嵌入。此处,30000是单词片段标记化后的Vocab长度。该矩阵的权重将在训练时学习。
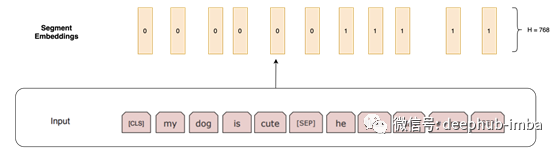
段嵌入:对于诸如回答问题之类的任务,我们应指定此句子来自哪个句段。如果嵌入来自句子1,则它们都是H长度的0个向量;如果嵌入来自句子2,则它们都是1的向量。
位置嵌入:这些嵌入用于指定序列中单词的位置,与我们在transformer体系结构中所做的相同。所以我们本质上有一个常数矩阵有一些预设的模式。这个矩阵的列数是768。这个矩阵的第一行是标记[CLS]的嵌入,第二行是单词“my”的嵌入,第三行是单词“dog”的嵌入,以此类推。
所以BERT的最终输入是令牌嵌入+段嵌入+位置嵌入。
训练Masked LM
这里是BERT最有趣的部分,因为这是大多数新颖概念的介绍。我将尝试通过各种架构尝试来解释这些概念,并找出每个尝试的问题缺陷和解决方式,最终就会得到BERT架构。
第1次尝试:如果我们按如下方式设置BERT训练:
我们尝试用交叉熵损失的训练数据预测输入序列的每个单词。你能猜到这种方法的问题吗?
问题是,学习任务是微不足道的。该网络事先知道它需要预测什么,因此它可以很容易地学习权值,以达到100%的分类精度。
第2次尝试:Masked LM,这是论文中克服前一种方法的问题的开始。我们在每个训练输入序列中屏蔽15%的随机单词,然后预测这些单词的输出。
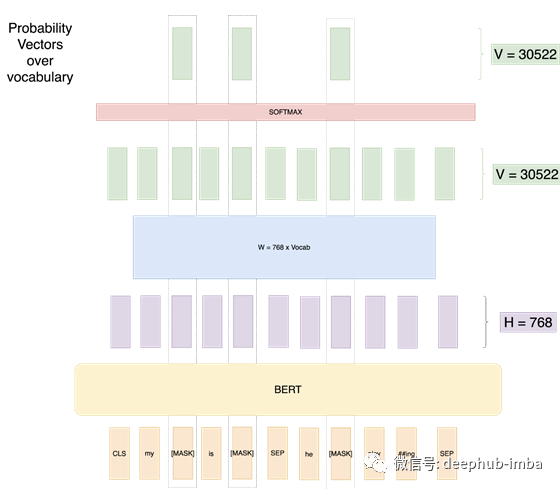
因此,仅对被遮盖的单词计算损失。因此,该模型现在可以在查看这些单词周围的所有上下文的同时,预测未见过的单词。
请注意,即使我只应该屏蔽一个字,我在这里也屏蔽了3个字,因为在这个示例中要解释的8的15%是1。
您能找到这种方法的问题吗?
该模型从本质上已经了解到,它仅应为[MASK]令牌预测良好的概率。即在预测时或在微调时该模型将不会获得[MASK]作为输入;但是该模型无法预测良好的上下文嵌入。
尝试3 :用随机单词遮盖LM:
在这次尝试中,我们仍然会隐藏15%的位置。但是我们会用随机的单词替换20%的掩码中的任何单词。我们这样做是因为我们想让模型知道,当单词不是[MASK]标记时,我们仍然需要一些输出。因此,如果我们有一个长度为500的序列,我们将屏蔽75个令牌(500的15%),在这75个令牌中,15个令牌(75的20%)将被随机单词替换。在这里,我们用随机的单词替换一些[MASK]。
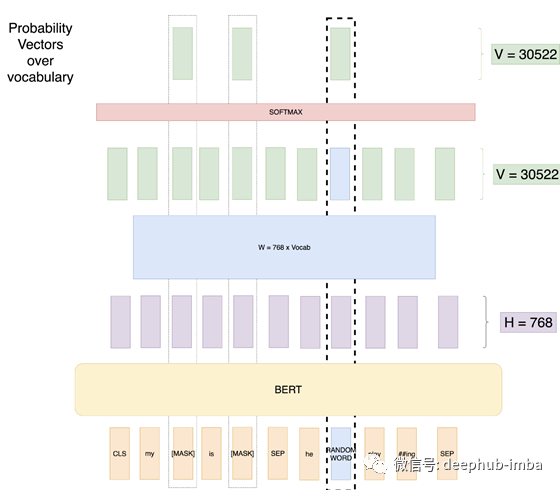
优点:现在网络仍然可以处理任何单词。
问题:网络已经知道输入永远不等于输出。也就是说,位于“随机单词”位置的输出向量永远不会是“随机单词”。
尝试4:具有随机词和未掩盖词的掩盖LM
这句话很绕嘴,为了解决这个问题,作者建议采用以下训练设置。
训练数据生成器随机选择15%的token位置进行预测。如果第i个令牌被选中,我们将第i个令牌替换为
(1)80%概率的[MASK]令牌
(2)10%概率的随机令牌
(3)10%概率不变的第i个令牌
因此,如果我们有一个长度为500的序列,我们将屏蔽75个令牌(占500的15%),在这75个令牌中,有7个令牌(占75的10%)将被随机单词替换,而7个令牌(占10%的令牌)将不替换,照原样使用。如图所示,我们用随机单词替换了一些Mask,并用实际单词替换了一些Mask。
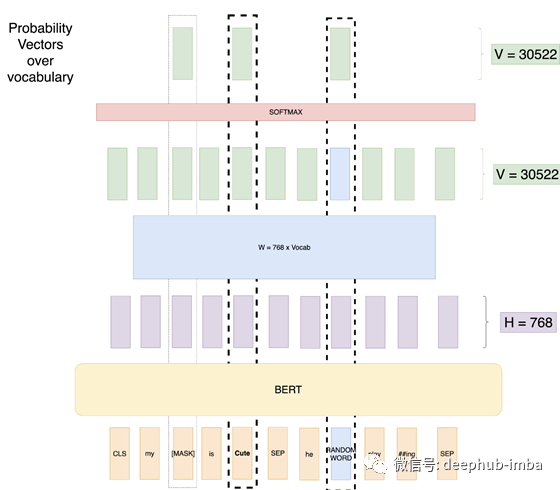
所以,现在我们有了最好的设置,我们的模型不会学习任何不好的模式。
但如果我只保留Mask+Unmask设置呢?这个模型会学习到,无论什么时候这个词出现,只要预测这个词就可以了。
训练额外的NSP任务
BERT的论文中写道:
许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于对两个句子之间关系的理解,而语言建模并没有直接捕捉到这些关系。为了训练一个理解句子关系的模型,我们预先训练了一个可以从任何单语语料库中生成的二值化下一个句子预测任务。
所以,现在我们了解了Masked LM 任务,BERT模型在训练Masked LM 任务的同时还有一个并行的训练任务。这个任务被称为下一个句子预测(NSP)。在创建训练数据时,我们为每个训练示例选择句子A和B,B是以使50%的概率紧随A的实际下一个句子(标记为IsNext),而50%是随机的 语料库中的句子(标记为NotNext)。然后,我们使用CLS令牌输出获取二进制损失,该损失也通过网络反向传播以学习权重。
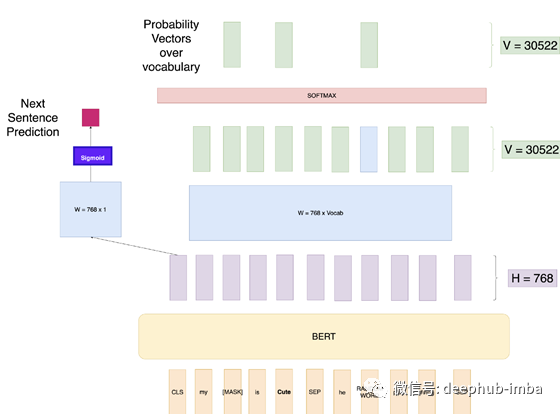
我们现在有了BERT模型,可以为我们提供上下文嵌入。那么如何将其用于各种任务?
相关任务的微调
通过在[CLS]输出的顶部添加几层并调整权重,我们已经了解了如何将BERT用于分类任务。
本文提供了如何将BERT用于其他任务的方法:
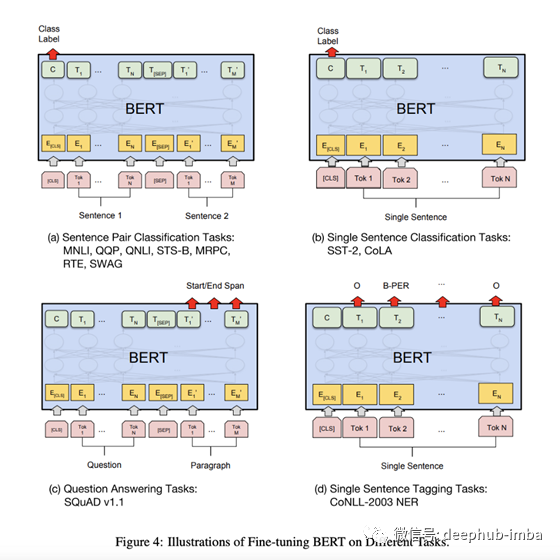
让我们一一逐一讨论
- 句对分类任务-这与分类任务非常相似。那就是在768尺寸的CLS输出之上添加一个Linear + Softmax层。
- 单句分类任务—与上述相同。
- 单句标记任务-与训练BERT时使用的设置非常相似,只是我们需要为每个标记而不是单词本身预测一些标记。例如,对于诸如预测名词,动词或形容词之类的POS标记任务,我们将仅添加大小为(768 x n_outputs)的线性层,并在顶部添加softmax层以进行预测。
- 问题解答任务-这是最有趣的任务,需要更多上下文才能了解如何使用BERT解决问题。在此任务中,给我们一个问题和一个答案所在的段落。目的是确定段落中答案的开始和结束范围。
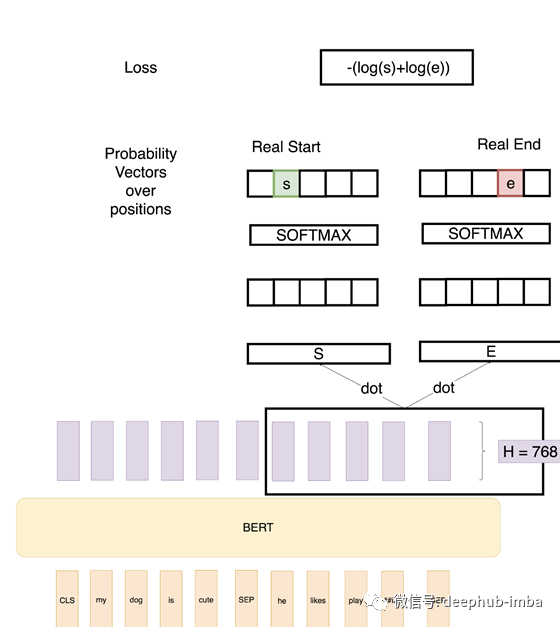
因此,在上面的例子中,我们定义了两个向量S和E(这将在微调过程中学习),它们都有形状(1x768)。然后我们取这些向量与第二个句子BERT的输出向量的点积,得到一些分数。然后我们在这些分数上应用Softmax来得到概率。训练目标是正确的起始位置和结束位置的对数概率之和。数学上,起始位置的概率向量为:
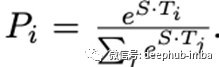
T_i是我们关注的词。对于端点位置也有一个类似的公式。
为了预测一个跨度,我们得到所有的分数- S.T和E.T,并得到最好的跨度,因为跨度有最大的分数,即max(S。T_i + e.t t_j)。
引用
- Attention Is All You Need: https://arxiv.org/abs/1706.03762
- BERT Paper: https://arxiv.org/abs/1810.04805
作者:Rahul Agarwal
原文地址:https://towardsdatascience.com/explaining-bert-simply-using-sketches-ba30f6f0c8cb
deephub翻译组