
此为opencv学习笔记第五篇,前四篇可于opencv专栏中寻找。
一、背景建模
1.1 帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。

帧差法非常简单,就是做差看阈值,但是会引入噪音和空洞问题(比如上方人的衣服处依旧有黑色部分)
1.2 混合高斯模型
在进行前景检测前,先对背景进行训练,对图像中每个背景采用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应。然后在测试阶段,对新来的像素进行GMM匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。由于整个过程GMM模型在不断更新学习中,所以对动态背景有一定的鲁棒性。最后通过对一个有树枝摇摆的动态背景进行前景检测,取得了较好的效果。(简单来说就是背景中道路、树木、房子等都有自己的高斯分布,后面新来的比如“人、车”等即新的像素高斯分布看它与之前的背景的是否匹配,不匹配就是新的。)
在视频中对于像素点的变化情况应当是符合高斯分布
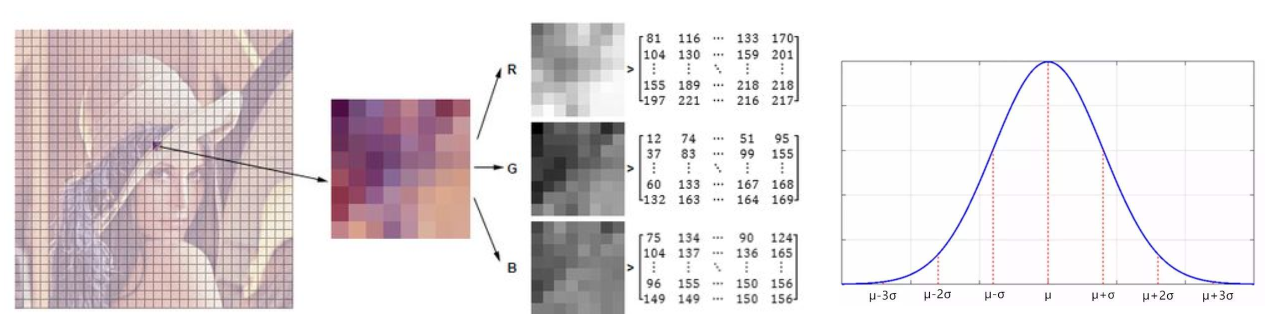
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
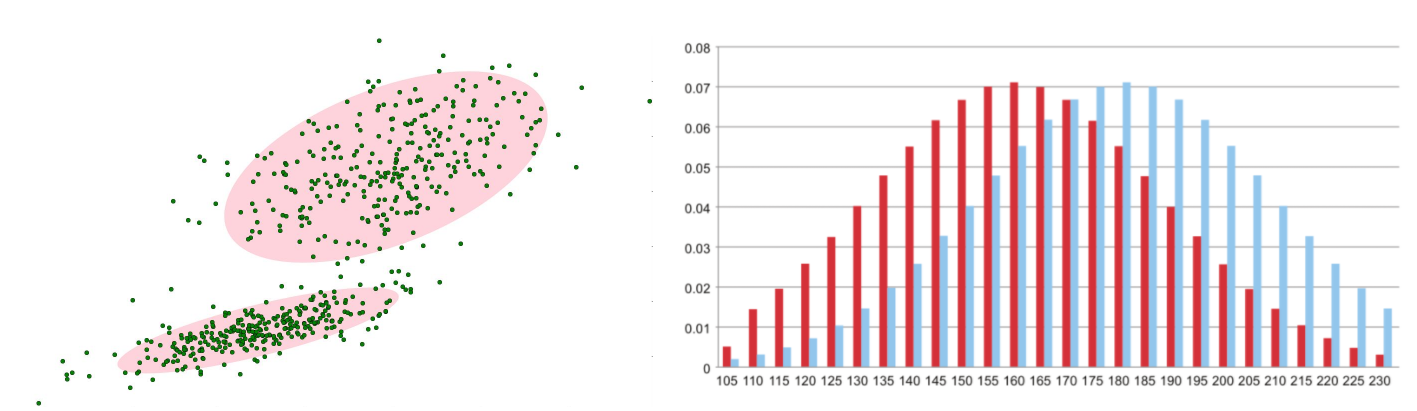
混合高斯模型学习方法
1.首先初始化每个高斯模型矩阵参数。
2.取视频中T帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布。
3.当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新。
4.如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。
混合高斯模型测试方法
在测试阶段,对新来像素点的值与混合高斯模型中的每一个均值进行比较,如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。
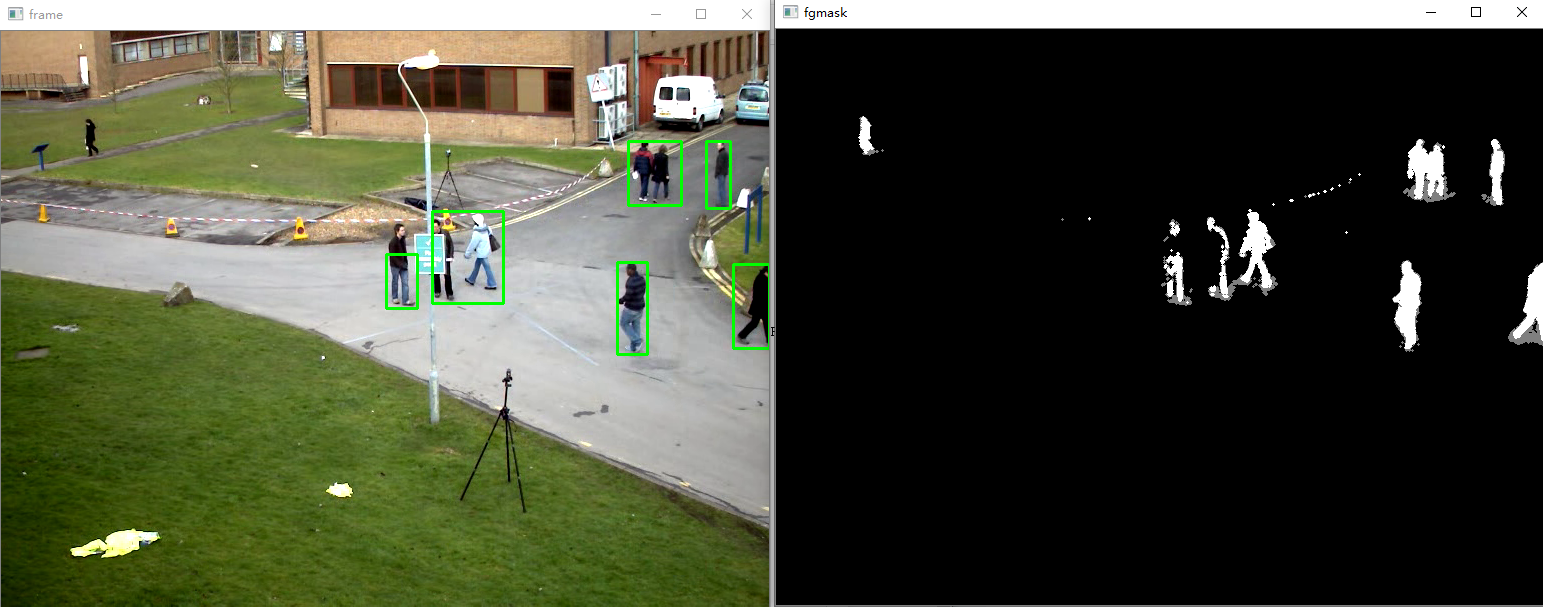
import numpy as np
import cv2
#经典的测试视频
cap = cv2.VideoCapture('test.avi')
#形态学操作需要使用
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
#创建混合高斯模型用于背景建模
fgbg = cv2.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
#形态学开运算去噪点
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
#寻找视频中的轮廓 im, contours, hierarchy
contours, hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
#找到一个直矩形(不会旋转)
x,y,w,h = cv2.boundingRect(c)
#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
二、光流估计
光流是空间运动物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。
即我们要看视频中,像素点在每一帧的时候,它的速度(瞬时)和方向。
假如我们知道了一个物体运动的速度(即大小和方向),我们不但可以找出是哪个物体,还能够预测它接下来出现在哪。
原理:
亮度恒定:同一点随着时间的变化,其亮度不会发生改变。
小运动:随着时间的变化不会引起位置的剧烈变化,只有小运动(△)情况下才能用前后帧之间单位位置变化引起的灰度变化去近似灰度对位置的偏导数。
空间一致:一个场景上邻近的点(比如车灯和车灯之间距离结构不变)投影到图像上也是邻近点,且邻近点速度一致。因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。所以需要连立n多个方程求解。
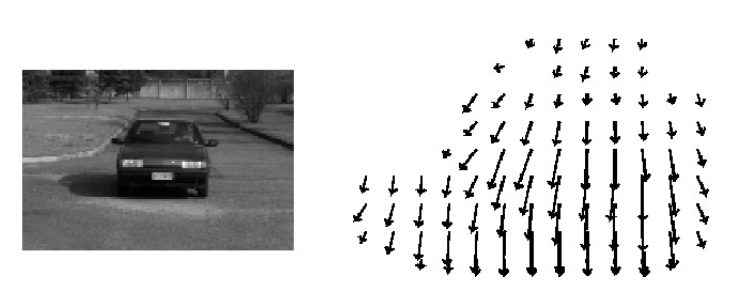

Lucas-Kanade 算法
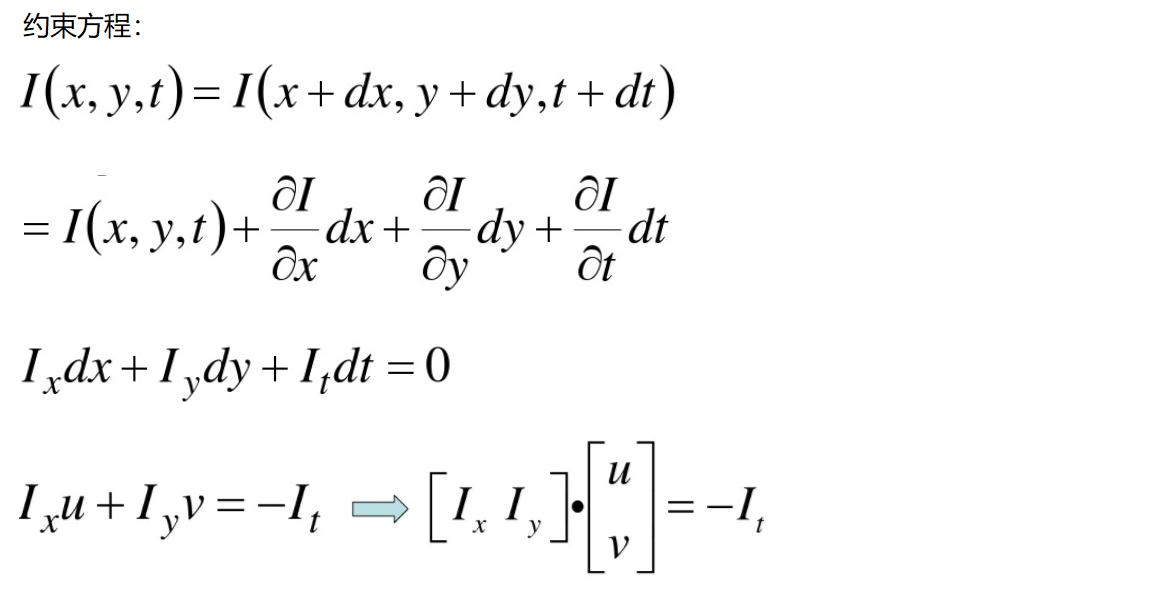
经泰勒级数展开,可见出现一个方程,两个未知数u,v。其中Ix,Iy为该像素点的梯度,It就是下一帧的。
如何求解方程组呢?看起来一个像素点根本不够,在物体移动过程中还有哪些特性呢(空间一致性)?
瞬时之间左车灯的u、v与右车灯的一样、人的左胳膊、右胳膊u、v一样。
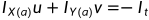
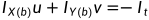
上式参数表示a、b两点在X、Y方向上的梯度IX,IY。It表示这一帧的梯度,u、v为x、y方向上的瞬时速度。
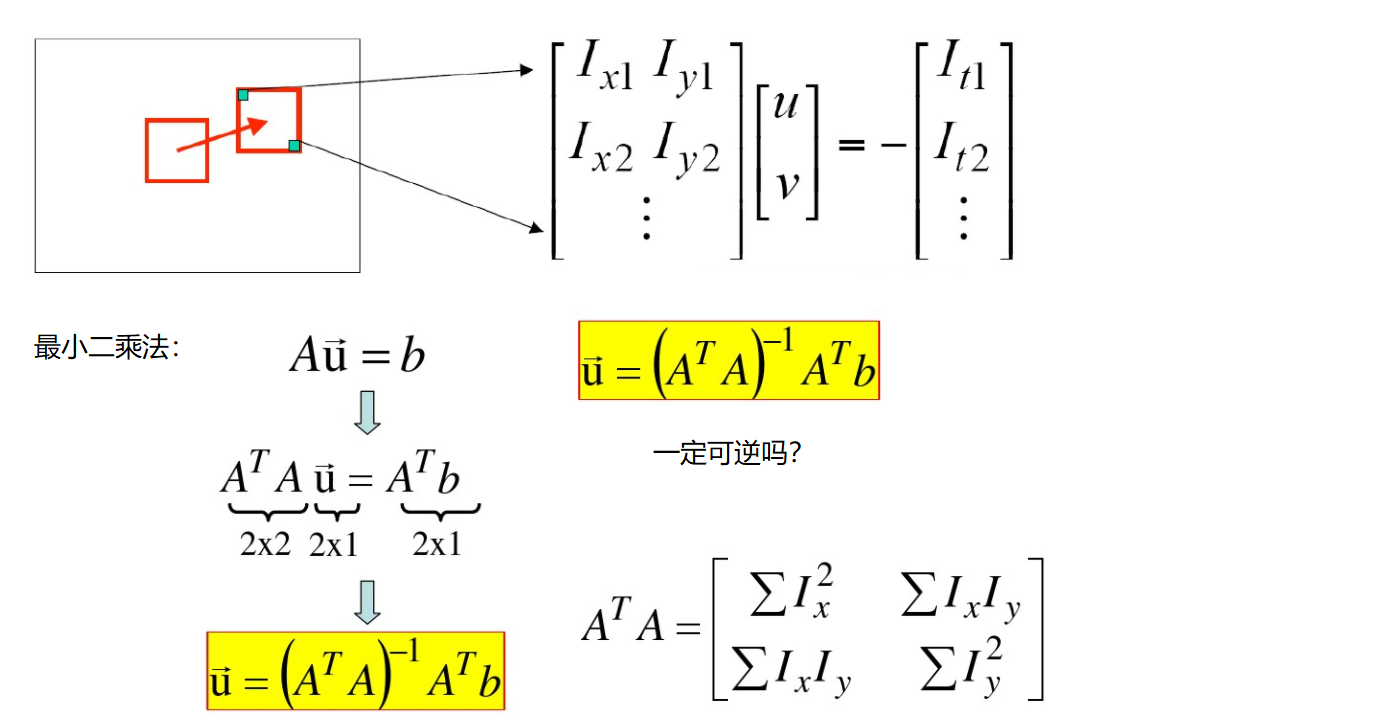
不过我们一般都是拿一部分的点,比如5x5的区域,那就有Ix1到Ix25,Iy1到Iy25。这样25个方程而我们只需要两个解,这个问题就回到了“线性回归”问题。选出最好的两个参数,使得其能更好的拟合这些点。
ps:一般角点才可逆(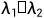 都比较大的时候)。所以我们做光流估计时,先进性角点检测,把角点作为输入传进去。
都比较大的时候)。所以我们做光流估计时,先进性角点检测,把角点作为输入传进去。
cv2.calcOpticalFlowPyrLK():
参数:
prevImage 前一帧图像
nextImage 当前帧图像
prevPts 待跟踪的特征点向量
winSize 搜索窗口的大小
maxLevel 最大的金字塔层数((openCV 第四篇 多分辨率金字塔、高斯差分金字塔DOG等概念)
返回:
nextPts 输出跟踪特征点向量
status 特征点是否找到,找到的状态为1,未找到的状态为0 (即比如一开始让它关注5个角点,下一帧还有这5个角点,状态都是1,假如这个角点消失了如人走出了画面/被障碍物挡了一帧,没找到,那就返回0,我们下面可以根据这个来选择只追踪找得到的。)
import numpy as np
import cv2
cap = cv2.VideoCapture('test.avi')
# 角点检测所需参数
feature_params = dict( maxCorners = 100, # 角点最大数量(效率)
qualityLevel = 0.3, # 品质因子(特征值越大的越好,来筛选)
minDistance = 7) # 距离 相当于这区间有强的角点,就不要周围弱的了
# lucas kanade参数
lk_params = dict( winSize = (15,15),
maxLevel = 2)
# 随机颜色条
color = np.random.randint(0,255,(100,3))
# 拿到第一帧图像
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 返回所有检测特征点
p0 = cv2.goodFeaturesToTrack(old_gray, mask = None, **feature_params)
# 创建一个mask
mask = np.zeros_like(old_frame)
while(True):
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 需要传入前一帧和当前图像以及前一帧检测到的角点
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 这里表示我们只要返回为1即找到了的角点
good_new = p1[st==1]
good_old = p0[st==1]
# 绘制轨迹
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask, (a,b),(c,d), color[i].tolist(), 2)
frame = cv2.circle(frame,(a,b),5,color[i].tolist(),-1)
img = cv2.add(frame,mask)
cv2.imshow('frame',img)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
# 更新
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
cv2.destroyAllWindows()
cap.release()

三、dnn模块
简单来说就是通过net=cv2.dnn.readNetFromCaffe("xxx.ooo")读取神经网络,其中引号内的是各种框架保存下来的模型文件。然后将要预测的图片即输入通过blob = cv2.dnn.blobFromImag()转换成blob形式,进而net.setInput(blob)、preds = net.forward()进行预测得到结果。
数据处理、显示函数
import os
image_types = (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff")
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def list_images(basePath, contains=None):
# return the set of files that are valid
return list_files(basePath, validExts=image_types, contains=contains)
def list_files(basePath, validExts=None, contains=None):
# loop over the directory structure
for (rootDir, dirNames, filenames) in os.walk(basePath):
# loop over the filenames in the current directory
for filename in filenames:
# if the contains string is not none and the filename does not contain
# the supplied string, then ignore the file
if contains is not None and filename.find(contains) == -1:
continue
# determine the file extension of the current file
ext = filename[filename.rfind("."):].lower()
# check to see if the file is an image and should be processed
if validExts is None or ext.endswith(validExts):
# construct the path to the image and yield it
imagePath = os.path.join(rootDir, filename)
yield imagePath
预测一张
# 导入工具包
import numpy as np
import cv2
# 标签文件处理
rows = open("synset_words.txt").read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
# Caffe所需配置文件
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel")
# 图像路径
imagePaths = sorted(list(list_images("images/")))
# 图像数据预处理
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
# image scalefactor size mean swapRB
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print("First Blob: {}".format(blob.shape))
# 得到预测结果
net.setInput(blob)
preds = net.forward()
# 排序,取分类可能性最大的
idx = np.argsort(preds[0])[::-1][0]
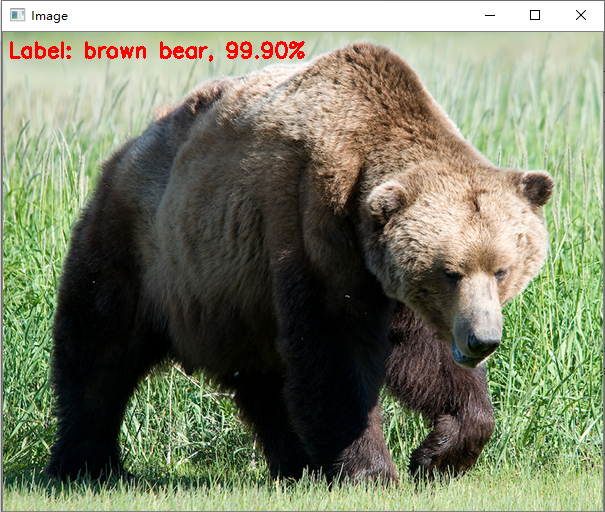
text = "Label: {}, {:.2f}%".format(classes[idx], preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# 显示
cv_show("Image", image)
First Blob: (1, 3, 224, 224)

预测一个batch
# Batch数据制作
images = []
# 方法一样,数据是一个batch
for p in imagePaths[1:]:
image = cv2.imread(p)
image = cv2.resize(image, (224, 224))
images.append(image)
# blobFromImages函数,注意有s
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))
print("Second Blob: {}".format(blob.shape))
# 获取预测结果
net.setInput(blob)
preds = net.forward()
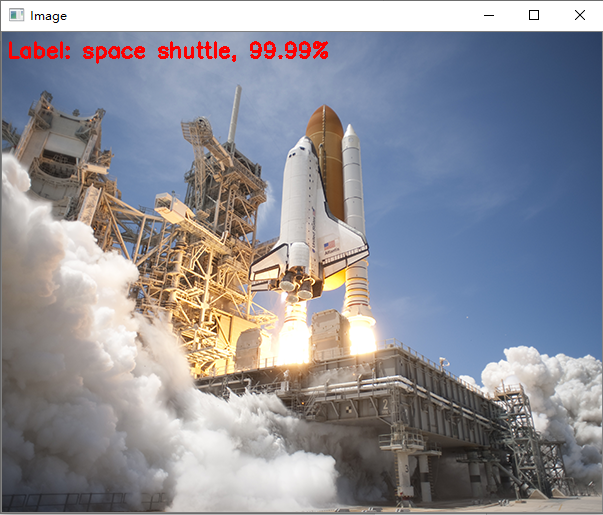
for (i, p) in enumerate(imagePaths[1:]):
image = cv2.imread(p)
idx = np.argsort(preds[i])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx],preds[i][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv_show("Image", image)
Second Blob: (4, 3, 224, 224)
...
...
版权归原作者 老师我作业忘带了 所有, 如有侵权,请联系我们删除。