
我对使用GAN进行艺术创作的想法很感兴趣,因此我开始研究人们设法创造的东西,并且遇到了Mike Tyka的工作,他是Google的研究人员,我发现他对此非常着迷,这促使我开始创建自己的GAN项目来从事艺术创作。
当我开始这个项目时,我并没有意识到训练GAN模型有多困难,并且花费了很多试验和错误才能得出令人满意的结果。因此,在本文中,我将经历构建DCGAN模型的历程,包括我所面临的挑战以及为达到最终模型所做的工作。
虽然并不完美,但结果却是不错的,因为我们仅使用本文提出的具有随机图像增强和特征匹配功能的无监督DCGAN。

我不会在更高的层次上讨论GANs,因为我认为有很多文章和视频都涉及到这一点,相反,我将只关注技术细节和我的整个过程。项目的完整代码在本文的最后提供。
数据集和预处理
我使用的维基艺术数据集可以在这里下载(https://www.kaggle.com/ipythonx/wikiart-gangogh-creating-art-gan)。这里不需要下载所有的东西,因为需要做的时肖像画,所以我只下载了portrait文件夹,,但你可以随意尝试其他东西。
接下来,我编写了一个python脚本preprocessing.py,以获取数据集以进行训练。我们可以将原始图像的尺寸调整为所需的64x64尺寸,但是如果您查看数据集,您会发现它可能会出错,因为就不希望有人像被压扁,或者他们的手被剪成正方形。理想情况下,我们希望正方形图像的中间带有人脸,所以我使用的“face-recognition”库,可以通过pip进行安装,并使用它遍历每张图像,找到人脸坐标,将其偏移指定的数量 并保存它们。
#crop faces with offset
def crop_faces(in_path, out_path, offset):
files = os.listdir(in_path)
for index, file in enumerate(files):
try:
img = Image.open(in_path+file)
img_arr = np.array(img)
top, right, bottom, left = face_recognition.face_locations(img_arr)[0]
face_image = img_arr[top-offset:bottom+offset, left-offset:right+offset]
img = Image.fromarray(face_image)
img.save(out_path+str(index)+'.jpg')
except:
pass
然后应用resize()方法,尽管人脸识别工具通常会创建方形或几乎为方形的图像,所以简单地跳过这一部分,只使用pytorch的resize方法不会有太大区别。PIL的调整大小方法与下面定义的方法的区别在于,它会调整图像的大小并对其进行裁剪,以使它们适合指定尺寸的正方形图像,从而避免挤压。但是无论如何,我已经为其他项目构建了此方法,因此不妨使用它。
def resize(in_path, out_path, dim, aspect_ratio=True):
if aspect_ratio:
files = os.listdir(path)
for index, file in enumerate(files):
img = Image.open(path+file)
if img.size[0]<img.size[1]:
ratio = dim/float(img.size[0])
new_x = dim
new_y = int(ratio * img.size[1])
img = img.resize((new_x, new_y))
val = int((new_y-dim)/2.0)
ltrb = (0,val,img.size[0],dim+val)
img = img.crop(ltrb)
elif img.size[0]>img.size[1]:
ratio = dim/float(img.size[1])
new_x = int(ratio * img.size[0])
new_y = dim
img = img.resize((new_x, new_y))
val = int((new_x-dim)/2.0)
ltrb = (val,0,dim+val,img.size[1])
#cropping
img = img.crop(ltrb)
#if image is square
else:
img = img.resize((dim, dim))
img = img.convert('RGB')
img.save(out_path+str(index)+'.jpg')
else:
files = os.listdir(path)
for index, file in enumerate(files):
try:
img = Image.open(path+file)
new_img = img.resize((dim,dim))
new_img.save(out_path+'_imgs/'+str(index)+'.jpg')
except:
pass
下载数据集后,创建另一个文件夹,在其中输出调整大小后的图像。然后只需运行上面的方法,指定原始数据集的路径,刚刚创建的输出文件夹以及所需的维度(64)
最后,我只是运行了rename_images方法以按数字顺序重命名文件,这是不必要的,但只是为了使所有内容变得有条理
#rename images numerically 0.jpg, 1.jpg, 2.jpg...
def rename_images(path):
files = os.listdir(path)
for index, file in enumerate(files):
os.rename(os.path.join(path, file), os.path.join(path, ''.join([str(index), '.jpg'])))
DCGAN模型
鉴别器
这是我们项目的核心。我创建了一个新文件“ models.py”来保存我们的鉴别器,生成器和一种初始化权重的方法。下图表示具有功能匹配的DCGAN鉴别器架构。
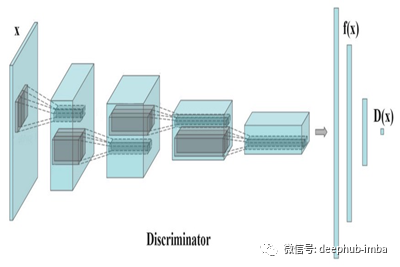
在最初的DCGAN论文中,定义了一系列具有BatchNorm和LeakyReLU的2D卷积层,以从图像中提取特征,并最终输出单个值来预测输入的图像是假的还是真实的。但是,使用此改进的版本,最终的卷积层之后是完整连接的线性层,因为生成器将使用该层来尝试匹配。
新目标不是直接使鉴别器的输出最大化,而是要求生成器生成与实际数据的统计信息匹配的数据,在这种情况下,我们仅使用鉴别器来指定我们认为值得匹配的统计信息。具体来说,我们训练生成器以使其与鉴别器中间层上的要素的期望值匹配。
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# input: N x channels_img x 64 x 64
nn.Conv2d(channels_img, features_d, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
# _block(in_channels, out_channels, kernel_size, stride, padding)
self._block(features_d, features_d * 2, 4, 2, 1),
self._block(features_d * 2, features_d * 4, 4, 2, 1),
self._block(features_d * 4, features_d * 8, 4, 2, 1),
# After all _block img output is 4x4 (Conv2d below makes into 1x1)
)
self.output = nn.Sequential(
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, bias=False,
),
nn.InstanceNorm2d(out_channels, affine=True),
nn.LeakyReLU(0.2),
)
def forward(self, x, feature_matching = False):
features = self.disc(x)
output = self.output(features)
if feature_matching:
return features.view(-1, 512*4*4), output
else:
return output
在这种情况下,特征是张量形状时(batch_size,1024),一旦开始训练,feature_matching参数的使用将变得更加清晰。但是为了快速运行此代码,我们定义了一个辅助函数_block(),它添加了DCGAN论文中建议的一层,输入通过顺序模型作为(batch_size,3,64,64)张量并卷积为 一个具有512 * 4 * 4个特征的向量,之后我仅使用了S型激活函数就为假图像返回0,为实数返回1。甚至使用模型,减去图层,观察输出的尺寸等。我始终在我的项目中保留一个park.py文件以进行打印 变量并测试我不确定的任何内容。
生成器
我们的生成器模型将完全遵循DCGAN的完全相同的体系结构。
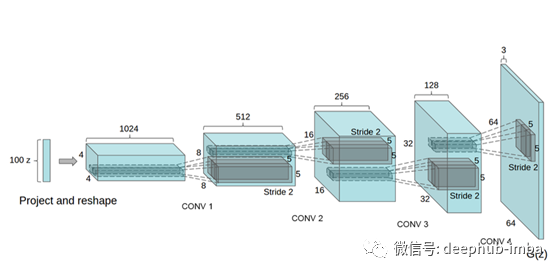
与生成器类似,但是相反,我们不是将图像卷积为一组特征,而是采用随机噪声输入“ z”并运行一系列反卷积以达到所需的图像形状(3,64,64 )。
class Generator(nn.Module):
def __init__(self, channels_noise, channels_img, features_g):
super(Generator, self).__init__()
self.net = nn.Sequential(
# Input: N x channels_noise x 1 x 1
self._block(channels_noise, features_g * 16, 4, 1, 0), # img: 4x4
self._block(features_g * 16, features_g * 8, 4, 2, 1), # img: 8x8
self._block(features_g * 8, features_g * 4, 4, 2, 1), # img: 16x16
self._block(features_g * 4, features_g * 2, 4, 2, 1), # img: 32x32
nn.ConvTranspose2d(
features_g * 2, channels_img, kernel_size=4, stride=2, padding=1
),
# Output: N x channels_img x 64 x 64
nn.Tanh(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels, out_channels, kernel_size, stride, padding, bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
最后,我们只需要在训练之前将initialize_weights()函数添加到两个模型即可:
def initialize_weights(model):
# Initializes weights according to the DCGAN paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
训练
现在我们有了数据和模型,我们可以从train.py文件开始,在这里我们将加载数据,初始化模型并运行主训练循环。
超参数和导入
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator, initialize_weights
import random
import os
import natsort
from PIL import Image, ImageOps, ImageEnhance
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
D_LEARNING_RATE = 2e-4
G_LEARNING_RATE = 1e-4
BATCH_SIZE = 64
IMAGE_SIZE = 64
CHANNELS_IMG = 3
NOISE_DIM = 128
NUM_EPOCHS = 100
FEATURES_DISC = 64
FEATURES_GEN = 64
两个优化器可以使用相同的学习率,但是我发现对鉴别器使用稍高的学习率被证明是更有效的。在更复杂的数据集上,我发现较小的批次大小(例如16或8)可以帮助避免过度拟合。
随机增强
改善GAN训练并从数据集中获得最大收益的技术之一是应用随机图像增强。在原始论文中,它们还提供了一种在生成器端还原增强图像的机制,因为我们不希望生成器生成增强图像。但是,在这种情况下,我认为应用这些简单的增幅就足够了,而这些增幅并不会真正影响画质。如果我们试图获得照片般逼真的结果,那么使用它来进行全面实施可能是一个更好的主意。
def random_augmentation(img):
#random mirroring/flipping image
rand_mirror = random.randint(0,1)
#random saturation adjustment
rand_sat = random.uniform(0.5,1.5)
#random sharpness adjustment
rand_sharp = random.uniform(0.5,1.5)
converter = ImageEnhance.Color(img)
img = converter.enhance(rand_sat)
converter = ImageEnhance.Sharpness(img)
img = converter.enhance(rand_sharp)
if rand_mirror==0:
img = ImageOps.mirror(img)
return img
我们对图像执行3个操作-镜像,饱和度调整和锐度调整。镜像图像对我们的图像质量没有影响,因为我们只是在翻转图像。对于饱和度和清晰度,我使用了一个较小的系数范围(0.5、1.5),以免对原始图像造成很大的影响。
数据加载器
为了应用我们之前构建的随机增强方法并加载数据,我编写了一个使用其下定义的转换的自定义数据集。
class CustomDataSet(Dataset):
def __init__(self, main_dir, transform):
self.main_dir = main_dir
self.transform = transform
all_imgs = os.listdir(main_dir)
self.total_imgs = natsort.natsorted(all_imgs)
def __len__(self):
return len(self.total_imgs)
def __getitem__(self, idx):
img_loc = os.path.join(self.main_dir, self.total_imgs[idx])
image = Image.open(img_loc).convert('RGB')
image = random_augmentation(image)
tensor_image = self.transform(image)
return tensor_image
transforms = transforms.Compose(
[
transforms.Resize((IMAGE_SIZE,IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
]
)
dataset = CustomDataSet("./data/128_portraits/", transform=transforms)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
训练
最后,我们可以初始化我们的网络并开始对其进行训练。对于鉴别器训练,我使用均方误差作为损失函数。我也尝试使用二进制交叉熵,但MSELoss最有效。在训练循环之前,我们还初始化张量板编写器以在tensorboard上实时查看我们的图像。
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)
### uncomment to work from saved models ###
#gen.load_state_dict(torch.load('saved_models/generator_model.pt'))
#disc.load_state_dict(torch.load('saved_models/discriminator_model.pt'))
opt_gen = optim.Adam(gen.parameters(), lr=G_LEARNING_RATE, betas=(0.5, 0.99))
opt_disc = optim.Adam(disc.parameters(), lr=D_LEARNING_RATE, betas=(0.5, 0.99))
criterion = nn.MSELoss()
fixed_noise = torch.randn(16, NOISE_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0
gen.train()
disc.train()
for epoch in range(NUM_EPOCHS):
for batch_idx, real in enumerate(dataloader):
real = real.to(device)
noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)
fake = gen(noise)
### Train Discriminator
disc_real = disc(real).reshape(-1)
loss_disc_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake.detach()).reshape(-1)
loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
loss_disc = (loss_disc_real + loss_disc_fake) / 2
disc.zero_grad()
loss_disc.backward()
opt_disc.step()
### Train Generator using feature matching
output = disc(fake).reshape(-1)
loss_gen = criterion(output, torch.ones_like(output))
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# Print losses occasionally and print to tensorboard
if batch_idx % 10 == 0:
torch.save(gen.state_dict(), 'generator_model.pt')
torch.save(disc.state_dict(), 'discriminator_model.pt')
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(dataloader)} \
Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise)
img_grid_real = torchvision.utils.make_grid(
real[:16], normalize=True
)
img_grid_fake = torchvision.utils.make_grid(
fake[:16], normalize=True
)
writer_real.add_image("Real", img_grid_real, global_step=step)
writer_fake.add_image("Fake", img_grid_fake, global_step=step)
step += 1
在训练的第一部分中,我们使用MSELoss在真实图像和伪图像上训练鉴别器。之后,我们使用特征匹配来训练我们的生成器。之前,我们在鉴别器的前向传递中添加了变量“ feature_matching”,以从图像中提取感知特征。在传统的DCGAN中,您只需训练生成器以伪造的图像来欺骗鉴别器,而在这里,我们试图训练生成器以生成与真实图像的特征紧密匹配的图像。此技术通常可以提高训练的稳定性。
经过100个批次后,我获得了以下结果。我尝试对模型进行更多的迭代训练,但是图像质量没有太大改善。

结论与最终想法
本文的目的是记录我从事该项目的过程。尽管在线上有很多资源和论文探讨了这个令人兴奋的概念的不同方面,但我发现有些东西是只能通过经验学习的……与其他任何东西一样。但我希望您能在本文中找到一些可以在自己的GAN项目中应用或试验的东西。由于我们获得的结果并不完美,因此我打算应用本文中提出的EvolGAN来优化我的生成器。
最后本文的代码在这里:https://github.com/mohdabdin/Landscapes-GANs
作者:Mohammad Abdin
原文地址:https://m-abdin.medium.com/painting-portraits-using-gans-with-pytorch-afeb69b1c5a1
deephub翻译组