opencv实战---物体尺寸测量
物体尺寸测量的思路是找一个确定尺寸的物体作为参照物,根据已知的计算未知物体尺寸。
一文通俗讲解元学习(Meta-Learning)
©PaperWeekly 原创 ·作者 | 孙裕道学校 | 北京邮电大学博士生研究方向 | GAN图像生成、情绪对抗样本生成元学习(meta-learning)是过去几年最火爆的学习方法...
多尺度特征融合
最后,使用研究者提出的多尺度特征融合模块融合相邻层中的特征图,这进一步减少了不同特征通道层之间的语义差距。然而,由于不同尺度的特征图之间的语义差距,他们取得的改进非常有限。首先,采用预训练的dilated ResNet-101作为主干来提取视觉特征,还在最后两个ResNet-101块中用空洞卷积替换
CVPR2022论文列表(中英对照)
CVPR论文列表,中英对照
【Android App】实战项目之使用OpenCV人脸识别实现找人功能(附源码和演示 超详细)
【Android App】实战项目之使用OpenCV人脸识别实现找人功能(附源码和演示 超详细)
目标检测算法——垃圾分类数据集汇总(附下载链接)
🎄🎄近期,小海带在空闲之余收集整理了一批垃圾分类数据集供大家参考。整理不易,小伙伴们记得一键三连喔!!!🎈🎈
残差网络(Residual Network,ResNet)原理与结构概述
残差网络(Residual Network)简介、概述与基本结构。
【ESP32Cam项目1】:ESP32Cam人脸检测(ArduinoESP32底层、Python版opencv)
【ESP32Cam项目1】:ESP32Cam人脸检测(ArduinoESP32底层、Python版opencv)
使用python控制摄像头
本文主要介绍了使用Python的OpenCV库进行摄像头操作的基本方法,包括打开摄像头、读取视频帧、显示视频帧、保存视频等。对于初学者来说,本文提供了一个简单易懂的入门教程。如果你想更深入地了解OpenCV库的使用方法,可以参考OpenCV官方文档或其他高质量的教程。遇到问题欢迎留言私信,我只要看到
【Yolov5】Yolov5添加ASFF, 网络改进优化
Yolov5添加ASFF模块,有完整的使用说明,实验可行,可以提高模型性能
计算机视觉-OpenCV入门讲解
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智
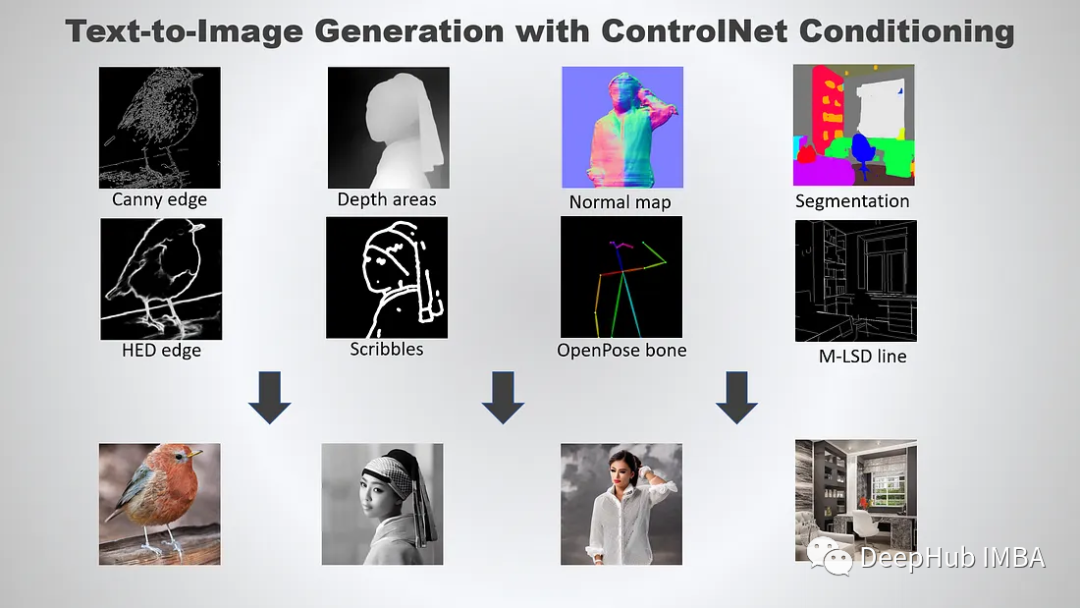
使用ControlNet 控制 Stable Diffusion
本文将要介绍整合HuggingFace的diffusers 包和ControlNet调节生成文本到图像,可以更好地控制文本到图像的生成
SwinIR实战:详细记录SwinIR的训练过程
SwinIR实战:详细记录SwinIR的训练过程。论文地址:https://arxiv.org/pdf/2108.10257.pdf预训练模型下载:https://github.com/JingyunLiang/SwinIR/releases训练代码下载:https://github.com/csz

Python图像处理:频域滤波降噪和图像增强
快速傅里叶变换(FFT)是一种将图像从空间域变换到频率域的数学技术,是图像处理中进行频率变换的关键工具,本文将讨论图像从FFT到逆FFT的频率变换所涉及的各个阶段,并结合FFT位移和逆FFT位移的使用。
ROS点云类型sensor_msgs::PointCloud2与PCL的PointCloud<T>点云类型转换
ROS中sensor_msgs::PointCloud2类型定义;与PCL的PointCloud点云数据类型转换;moveFromROSMsg()函数解析;点云格式转换中的注意事项。
【Call for papers】ICCV-2023(CCF-A/人工智能/2023年3月8日截稿)
ICCV是主要的国际计算机视觉活动,包括主要会议和几个联合举办的研讨会和教程。
yolov5s模型剪枝详细过程(v6.0)
基于yolov5s(v6.0)的模型剪枝实战分享,参考github教程带链接带源码。
基于深度学习的图像去噪方法归纳总结
基于深度学习的图像去噪方法
Python - Opencv应用实例之CT图像检测边缘和内部缺陷
Python - Opencv应用实例之CT图像检测边缘和内部缺陷
火爆全网的ChatGPT,可以自己上手搭建了。
没有人不知道ChatGPT了吧?ChatGPT,发布于2022年11月30日,来自人工智能研究实验室OpenAI,是一款全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。



