NWD(2022)
检测微小物体是一个非常具有挑战性的问题,因为微小物体仅包含几个像素大小。我们证明,由于缺乏外观信息,最先进的检测器无法在微小物体上产生令人满意的结果**。我们的主要观察结果是,基于联合交集 (IoU) 的指标(例如 IoU 本身及其扩展)对微小物体的位置偏差非常敏感,并且在用于基于锚点的检测器中时会
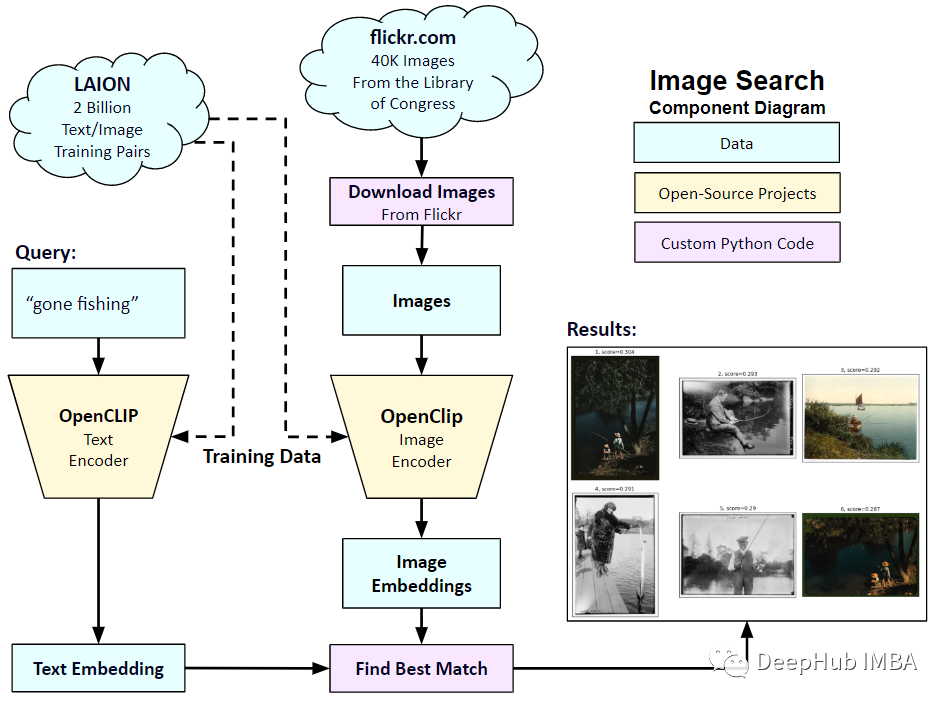
在自定义数据集上实现OpenAI CLIP
在本文中,我们将使用PyTorch中从头开始实现CLIP模型,以便我们对CLIP有一个更好的理解
ISP-长短曝光融合生成HDR图像
根据Debevec等人提出的相机响应曲线(Camera Response Curve,CRV),采集图像数据计算长曝光与像素值的关系,短曝光与像素值的关系,再利用权重函数,将长曝光、短曝光对应的低动态范围图像数据合成,得到高动态范围图像。第二,像素点亮度值与曝光时间成线性关系。2、**长短曝光融合:
Autolabelimg自动标注工具
在做机器视觉有监督方面,通常会面对很多数据集,然后去进行标注,而有些时候我们面对庞大数量数据集的情况下也会感到十分头疼,这个时候Autolabelimg这个自动标注神器就应运而生了。让我们可以实现批量处理图片和标注文件。
【计算机视觉】Visual grounding系列
【计算机视觉】Visual grounding系列
Point-NeRF总结记录
Point-NeRF阅读总结记录 PPT形式
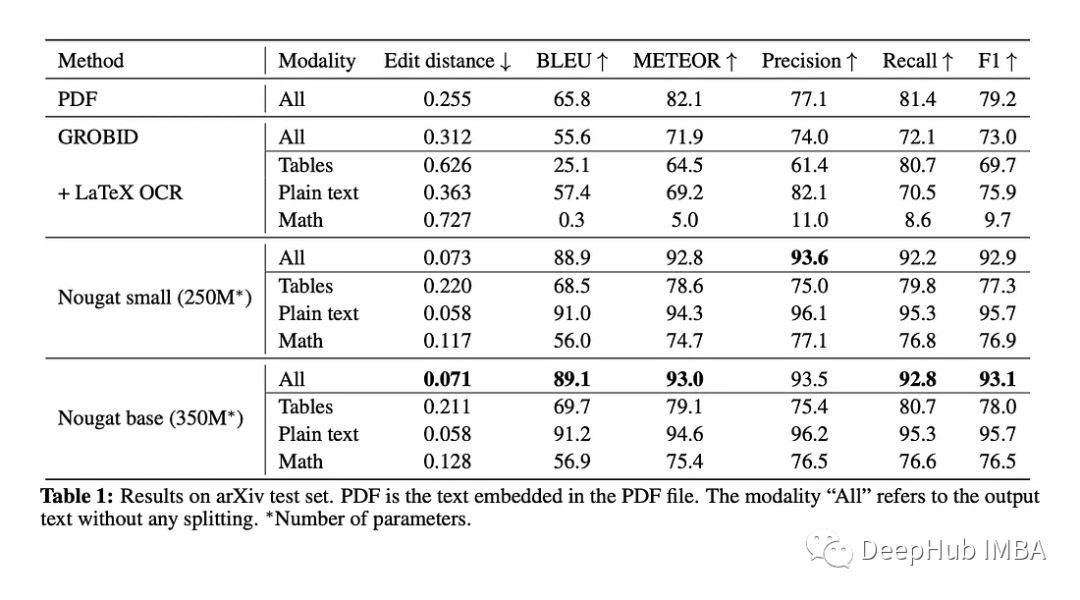
Nougat:一种用于科学文档OCR的Transformer 模型
Nougat是一种VIT模型。它的目标是将这些文件转换为标记语言,以便更容易访问和机器可读。
PointPillars 工程复现
PointPillars 工程复现, 学习并复现PointPillars,解决部署时遇到的各类问题。
Inpaint Anything (AI替换)
Inpaint Anything 是一个结合了 SAM、图像修补模型(例如 LaMa)和 AIGC 模型(例如 Stable Diffusion)等视觉基础模型的AI图像替换,修补系统。基于此系统,用户可以方便的使用IA进行图像替换,处理具有任意长宽比和 2K 高清分辨率的图像,且不受图像原始内容限
OpenMMLab-AI实战营第二期-课程笔记-Class 3:RTMPose关键点检测
数据集:Labelme标注数据集、整理标注格式至MS COCO目标检测:分别训练和目标检测模型、训练日志可视化、测试集评估、对图像、摄像头画面预测关键点检测:训练RTMPose-S关键点检测模型、训练日志可视化、测试集上评估、分别对“图像、视频、摄像头画面”预测模型终端部署:转ONNX格式,终端推理
DenseNet(密集连接的卷积网络)
DenseNet是指Densely connected convolutional networks(密集卷积网络)。它的优点主要包括有效缓解梯度消失、特征传递更加有效、计算量更小、参数量更小、性能比ResNet更好。它的缺点主要是较大的内存占用。
[点云学习] 一、点云相关知识了解
点云是一种表示三维空间中对象的数据结构,它由许多离散的点组成。每个点都有自己的位置坐标和可能的其他属性,如颜色、法向量和强度等。点云通常由激光扫描仪、相机或其他传感器捕获,用于创建三维模型、地图或进行遥感分析。在计算机视觉和机器学习领域,点云也被广泛应用于目标检测、物体识别、3D重建和虚拟现实等方面
Opencv实现抠图
原图如下:想将左上角的图扣下做素材这样就完成了抠图做素材的所有步骤了此处是将图像由彩色图转成了灰度图。
3DMM(3D Morphable Model)原理和实现
3DMM的基本原理是将人脸表示为参数化的模型,包括形状参数和纹理参数。形状参数描述了人脸的几何结构,如位置、大小和形状,而纹理参数描述了人脸的外观特征,如皮肤颜色和纹理。通过调整这些参数的值,可以生成不同形状和纹理的人脸模型。首先,3DMM使用大量的训练数据来建立一个平均的人脸形状模型。该模型包含了
sparse conv稀疏卷积
"""Args:"""self.features = features # 储存密集的featureself.indices = indices # 储存每个feature对应的voxel坐标系下的坐标self.spatial_shape = spatial_shape #存储voxel的最大边界s
CV 经典主干网络 (Backbone) 系列: CSP-Darknet53
CSP-Darknet53无论是其作为CV Backbone,还是说它在别的数据集上取得极好的效果。与此同时,它与别的网络的适配能力极强。
R3live官方数据集测试及R3live+ Velodyne
1. 下载livox-SDK,编译安装。4.下载r3live源码,编译安装。2.下载livox驱动,编译安装。r3live一般使用的是livox固态激光雷达,在这里我尝试将其与velodyne 激光雷达进行适配
四元数快速入门【Quaternion】
四元数(Quaternion)是用于旋转和拉伸向量的数学运算符。本文提供了一个概述,以帮助理解在空间导航等应用程序中对四元数的需求。推荐:用快速搭建3D场景。可以通过多种方式在空间中准确定位、移动和旋转物体。更熟悉和更容易可视化的滚动(Roll)、俯仰(Pitch)和偏航(Yaw)表示是有局限性的,
DETR训练自己的数据集
DETR训练自己的数据集
报错:RuntimeError: expected scalar type Double but found Float
解决办法:这个是格式问题,希望的格式是double,但得到的是float。字面意思是这个,但是并不是非要把格式改成double,这个时候应该在出错的前面几处代码设个断点debug一下,我得到的结果是image、img_rgb都是tensor.unit8格式的,但程序所需要的是torch.float3



