
目录
重要的参考链接
- 视频学习-关于DETR的讲解合集:DETR源码讲解:训练自己的数据集(这个小姐姐讲的很清楚,还有另外一个视频关于Deformable Detr的,Deformable Detr 论文思想讲解(一听就会))- 这小姐姐自己写了一个预测代码,但是还没有公布出来的,我在这个博客中看到有分享
predict.py,可以好好看一下:windows10复现DEtection TRansformers(DETR)并实现自己的数据集(这个博客是真的详细,可能视频中的小姐姐就是参照的这个博客,里面的预测代码大概率也是来自于这里) - 视频学习-跟着李沐学AI的论文精度:DETR 论文精读【论文精读】(有3篇相关的B站笔记,可以去看一下)
- 这个注意力机制要好好学一下,跟那个生物机制很像:详解可变形注意力模块(Deformable Attention Module)
重点:
- 标签格式是
COCO类型的json文件,暂时可以先参考这个VOC格式数据集转为COCO格式数据集脚本,而且必须要命名为./instances_train2017.json和./instances_val2017.json - DETR
对小目标不友好,检测大目标倒是可以 - DETR在精度上没有比过当时的SOTA,能这么被喜爱是因为
它的论文思想很精妙,真正实现了end-to-end
训练自己的代码,参考:
- 视频学习-关于DETR的讲解合集:DETR源码讲解:训练自己的数据集
- 【DETR】训练自己的数据集-实践笔记
- DETR训练自己的数据集
- windows10复现DEtection TRansformers(DETR)并实现自己的数据集
暂存:
- 目标检测算法:Cascade RCNN | 视频讲解
缺点:
- DETR需要很多的epoch才能够收敛
- 小目标性能不好
- 增大尺度或者使用多尺度,会增加计算量
- 注意力模块比较稀疏,收敛比较慢
第一步:更改权重文件
- 先下载
detr-r50-e632da11.pth权重,点击即可下载👉https://dl.fbaipublicfiles.com/detr/detr-r50-e632da11.pth - 再运行以下代码(其中,
num_class:假如json文件中类别id的最大数值为90,则num_class应当被设置为90+1。最大值90可以通过此方式查找:在json文件中Ctrl+F检索定位到最后一个supercategory,查看id值即可。下图展示的是视频1中定位的COCO数据集中的最大类别编号为90)

这是在视频下的回复:

import torch
# 下载地址: https://dl.fbaipublicfiles.com/detr/detr-r50-e632da11.pth
pretrained_weights = torch.load('./detr-r50-e632da11.pth')
num_classes =5
pretrained_weights['model']['class_embed.weight'].resize_(num_classes +1,256)
pretrained_weights['model']['class_embed.bias'].resize_(num_classes +1)
torch.save(pretrained_weights,'detr-r50_%d.pth'% num_classes)
第二步:将数据集整理为coco数据集的格式
代码参考自:windows10复现DEtection TRansformers(DETR)并实现自己的数据集
以下暂存我自己改了一点的代码,就是只管了将xml格式转为json文件,没有管将图片移动的事:
# coding:utf-8# conference link: https://blog.csdn.net/w1520039381/article/details/118905718# pip install lxmlimport os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
path2 ="C:/Users/Desktop/VOC2007"
START_BOUNDING_BOX_ID =1defget(root, name):return root.findall(name)defget_and_check(root, name, length):vars= root.findall(name)iflen(vars)==0:raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))if length >0andlen(vars)!= length:raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length,len(vars)))if length ==1:vars=vars[0]returnvarsdefconvert(xml_list, json_file):
json_dict ={"images":[],"type":"instances","annotations":[],"categories":[]}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories ={}for index, line inenumerate(xml_list):# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4]+".jpg"
image_id =20190000001+ index
size = get_and_check(root,'size',1)
width =int(get_and_check(size,'width',1).text)
height =int(get_and_check(size,'height',1).text)
image ={'file_name': filename,'height': height,'width': width,'id': image_id}
json_dict['images'].append(image)## Cruuently we do not support segmentation# segmented = get_and_check(root, 'segmented', 1).text# assert segmented == '0'for obj in get(root,'object'):
category = get_and_check(obj,'name',1).text
if category in all_categories:# 记录类别个数
all_categories[category]+=1else:
all_categories[category]=1if category notin categories:if only_care_pre_define_categories:# 只关注特定的类别,也就是遇到定义好的类别之外的类别一律不管continue
new_id =len(categories)+1print("[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category]= new_id
category_id = categories[category]
bndbox = get_and_check(obj,'bndbox',1)
xmin =int(float(get_and_check(bndbox,'xmin',1).text))
ymin =int(float(get_and_check(bndbox,'ymin',1).text))
xmax =int(float(get_and_check(bndbox,'xmax',1).text))
ymax =int(float(get_and_check(bndbox,'ymax',1).text))assert(xmax > xmin),"xmax <= xmin, {}".format(line)assert(ymax > ymin),"ymax <= ymin, {}".format(line)
o_width =abs(xmax - xmin)
o_height =abs(ymax - ymin)
ann ={'area': o_width * o_height,'iscrowd':0,'image_id':
image_id,'bbox':[xmin, ymin, o_width, o_height],'category_id': category_id,'id': bnd_id,'ignore':0,'segmentation':[]}
json_dict['annotations'].append(ann)
bnd_id = bnd_id +1for cate, cid in categories.items():
cat ={'supercategory':'none','id': cid,'name': cate}
json_dict['categories'].append(cat)
json_fp =open(json_file,'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()print("------------create {} done--------------".format(json_file))print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),len(pre_define_categories),
pre_define_categories.keys()))print("category: id --> {}".format(categories))print(categories.keys())print(categories.values())if __name__ =='__main__':
classes =['D00','D10','D20','D40']
pre_define_categories ={}for i, cls inenumerate(classes):
pre_define_categories[cls]= i +1# pre_define_categories = {'a1': 1, 'a3': 2, 'a6': 3, 'a9': 4, "a10": 5} ##
only_care_pre_define_categories =True# only_care_pre_define_categories = False ### train_ratio = 0.9
save_json_train ='instances_train2017.json'
save_json_val ='instances_val2017.json'
xml_dir =r"F:\A_Publicdatasets\RDD2022_released_through_CRDDC2022\RDD2022\A_unitedataset\annotations"
xml_list_train = glob.glob(xml_dir +"/train/*.xml")
xml_list_val = glob.glob(xml_dir +"/val/*.xml")# xml_list = np.sort(xml_list)# np.random.seed(100)# np.random.shuffle(xml_list)# train_num = int(len(xml_list) * train_ratio)# xml_list_train = xml_list[:train_num]# xml_list_val = xml_list[train_num:]
convert(xml_list_train, os.path.join(xml_dir, save_json_train))
convert(xml_list_val, os.path.join(xml_dir, save_json_val))# if os.path.exists(path2 + "/annotations"):# shutil.rmtree(path2 + "/annotations")# os.makedirs(path2 + "/annotations")# if os.path.exists(path2 + "/images/train2014"):# shutil.rmtree(path2 + "/images/train2014")# os.makedirs(path2 + "/images/train2014")# if os.path.exists(path2 + "/images/val2014"):# shutil.rmtree(path2 + "/images/val2014")# os.makedirs(path2 + "/images/val2014")## f1 = open("train.txt", "w")# for xml in xml_list_train:# img = xml[:-4] + ".jpg"# f1.write(os.path.basename(xml)[:-4] + "\n")# shutil.copyfile(img, path2 + "/images/train2014/" + os.path.basename(img))## f2 = open("test.txt", "w")# for xml in xml_list_val:# img = xml[:-4] + ".jpg"# f2.write(os.path.basename(xml)[:-4] + "\n")# shutil.copyfile(img, path2 + "/images/val2014/" + os.path.basename(img))# f1.close()# f2.close()# print("-------------------------------")# print("train number:", len(xml_list_train))# print("val number:", len(xml_list_val))
第三步:更改detr.py
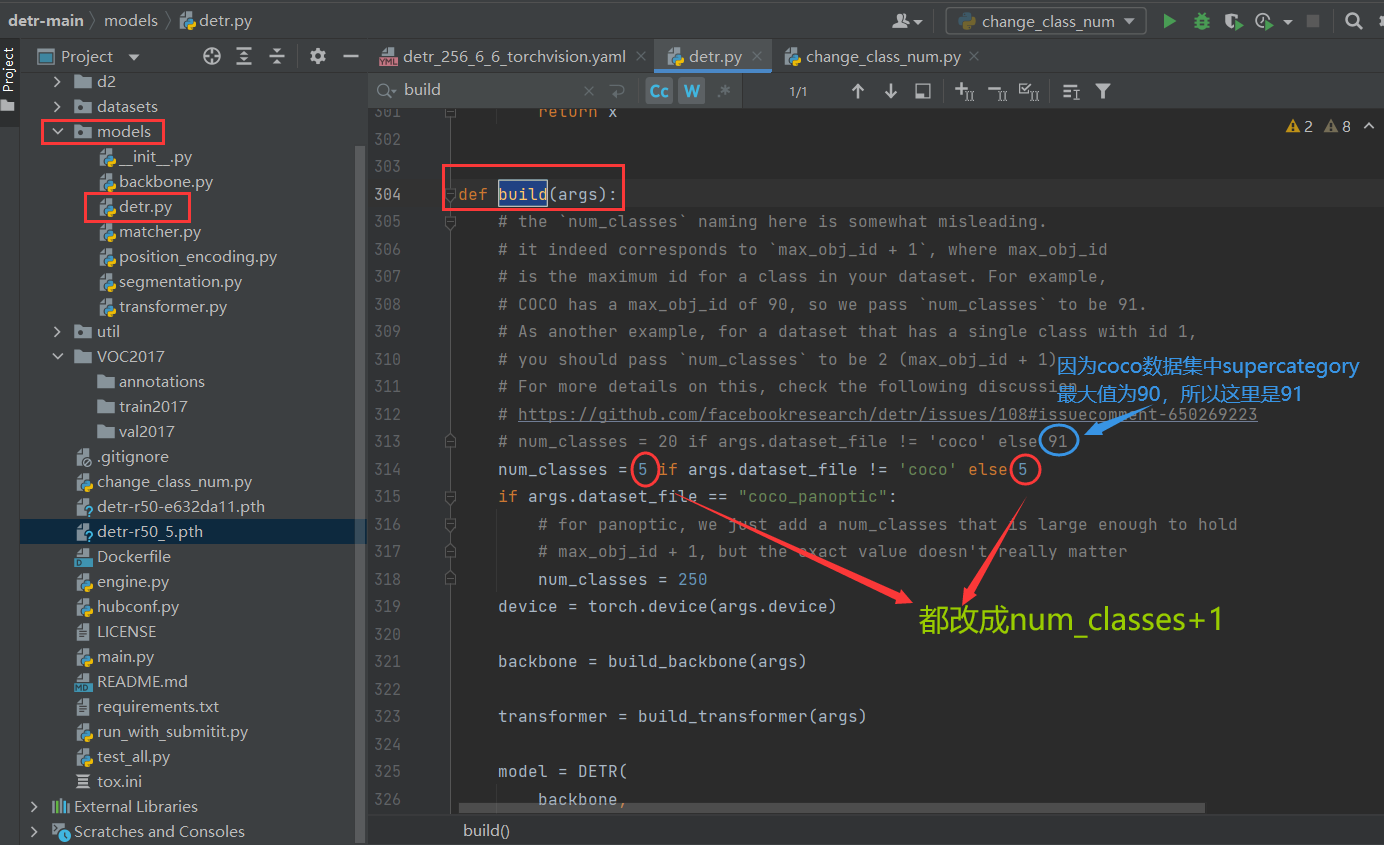
第四步:在终端设置训练参数进行训练
注意:如果是在windows下面跑的话,
num_workers
应该设置成
0
python main.py --dataset_file "coco"--coco_path data/coco --epochs 100--lr=1e-4--batch_size=2--num_workers=4--output_dir="outputs"--resume="detr-r50_3.pth"
第五步:检测效果,但是没有没有打印出来那些map指标
⭐来自博客:windows10复现DEtection TRansformers(DETR)并实现自己的数据集
其中要改的地方有:
- 102行左右的
model = detr_resnet50(False, 5)中的5改为本博客第一步:更改权重文件的 num_class,否则会报错通道数不匹配
- 103行左右
state_dict = torch.load后面改为训练好后的checkpoint.pth地址 - 108行左右
im = Image.open后面改为待检测的图片地址(注意,现在只能检测单张,且没有实现保存图片,需要自己改下代码) - 20行左右的
CLASSES后面的数组值按顺序写成自己的检测类别名 - 93行左右的
keep = probas.max(-1).values > 0.7中的0.7可以调大调小,应该是confidence的作用,也就是值越高的话,显示出来的框就会越少
import math
from PIL import Image
import requests
import matplotlib.pyplot as plt
# import ipywidgets as widgets# from IPython.display import display, clear_outputimport torch
from torch import nn
from torchvision.models import resnet50
import torchvision.transforms as T
from hubconf import*from util.misc import nested_tensor_from_tensor_list
torch.set_grad_enabled(False)# COCO classes
CLASSES =['D00','D10','D20','D40']# colors for visualization
COLORS =[[0.000,0.447,0.741],[0.850,0.325,0.098]]# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])# for output bounding box post-processingdefbox_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b =[(x_c -0.5* w),(y_c -0.5* h),(x_c +0.5* w),(y_c +0.5* h)]return torch.stack(b, dim=1)defrescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)return b
defplot_results(pil_img, prob, boxes):
plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
colors = COLORS *100for p,(xmin, ymin, xmax, ymax), c inzip(prob, boxes.tolist(), colors):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=3))
cl = p.argmax()
text =f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=15,
bbox=dict(facecolor='yellow', alpha=0.5))
plt.axis('off')
plt.show()defdetect(im, model, transform):# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0)# propagate through the model
outputs = model(img)# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0,:,:-1]
keep = probas.max(-1).values >0.00001# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)return probas[keep], bboxes_scaled
defpredict(im, model, transform):# mean-std normalize the input image (batch-size: 1)
anImg = transform(im)
data = nested_tensor_from_tensor_list([anImg])# propagate through the model
outputs = model(data)# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0,:,:-1]
keep = probas.max(-1).values >0.7# 0.7 好像是调整置信度的# print(probas[keep])# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)return probas[keep], bboxes_scaled
if __name__ =="__main__":
model = detr_resnet50(False,5)# 这里与前面的num_classes数值相同,就是最大的category id值 + 1
state_dict = torch.load(r"G:\pycharmprojects\detr-main\output\checkpoint.pth", map_location='cpu')
model.load_state_dict(state_dict["model"])
model.eval()# im = Image.open('data/coco/train2017/001554.jpg')
im = Image.open(r'F:\A_Publicdatasets\RDD2022_released_through_CRDDC2022\RDD2022\A_unitedataset\images\val\China_Drone_000038.jpg')
scores, boxes = predict(im, model, transform)
plot_results(im, scores, boxes)
本文转载自: https://blog.csdn.net/LWD19981223/article/details/129784674
版权归原作者 孟孟单单 所有, 如有侵权,请联系我们删除。
版权归原作者 孟孟单单 所有, 如有侵权,请联系我们删除。