深度学习大模型框架的简单介绍(ChatGPT背后原理的基本介绍)
介绍ChatGPT背后,简单介绍整个大规模预训练语言模型的发展历程。
深入理解机器学习——过拟合(Overfitting)与欠拟合(Underfitting)
机器学习的主要挑战是我们的算法必须能够在先前未观测的新输入上表现良好,而不只是在训练集上表现良好。在先前未观测到的输入上表现良好的能力被称为泛化(Generalization)。通常情况下,当我们训练机器学习模型时,我们可以使用某个训练集,在训练集上计算一些被称为 训练误差(Training Rrr
【MacOS】MacBook使用本机m1芯片GPU训练的方法(mps替代cuda)
使用Mac M1芯片加速 pytorch 不需要安装 cuda后端,因为cuda是适配nvidia的GPU的,Mac M1芯片中的GPU适配的加速后端是mps,在Mac对应操作系统中已经具备,无需单独安装。只需要安装适配的pytorch即可。mps用法和cuda很像,只是将“cuda”改为“mps”
kaggle(白嫖免费GPU,新手必看!!!)
超详细新手白嫖kaggle GPU教程,不可错过哦
2023年十大目标检测模型!
“目标检测是计算机视觉中最令人兴奋和具有挑战性的问题之一,深度学习已经成为解决该问题的强大工具。”—Dr. Liang-Chieh Chen目标检测是计算机视觉中的基础任务,它涉及在图像中识别和定位目标。深度学习已经革新了目标检测,使得在图像和视频中更准确和高效地检测目标成为可能。在2023年,有几
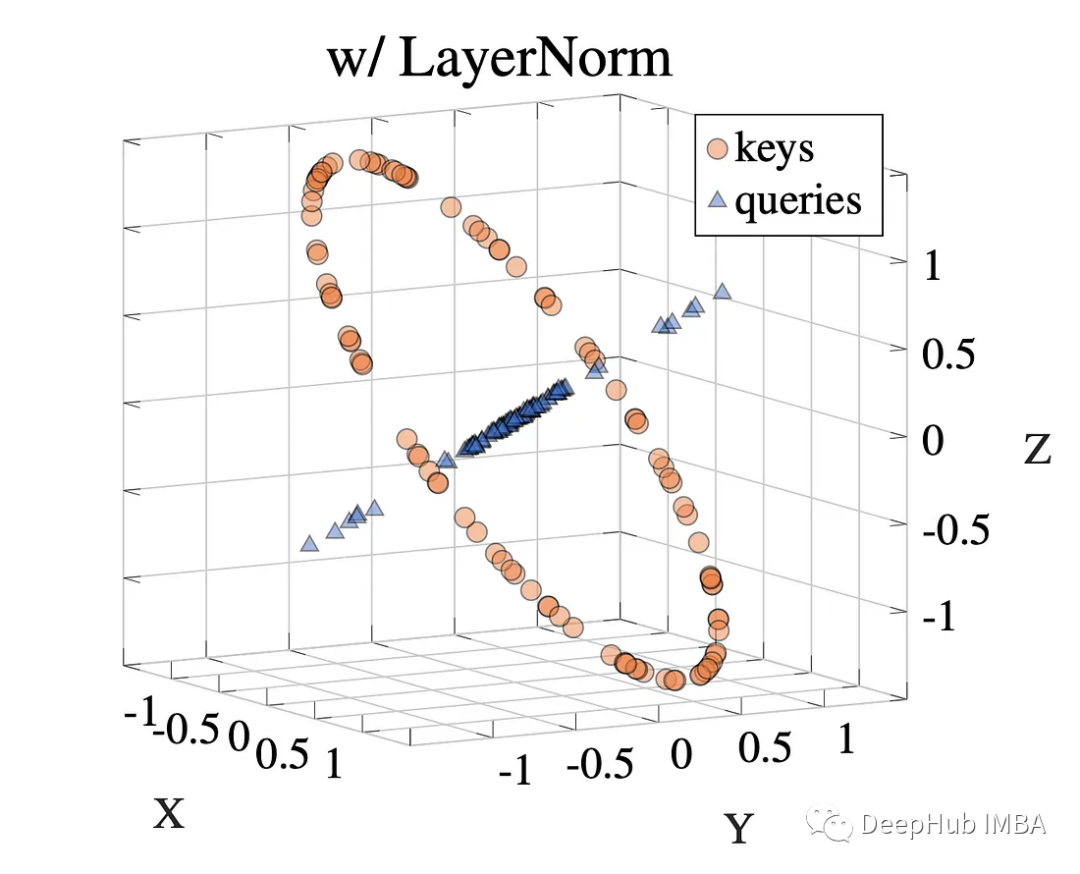
LayerNorm 在 Transformers 中对注意力的作用研究
LayerNorm 一直是 Transformer 架构的重要组成部分。如果问大多人为什么要 LayerNorm,一般的回答是:使用 LayerNorm 来归一化前向传播的激活和反向传播的梯度。
Windows Server 2019服务器远程桌面服务部署+深度学习环境配置教程
文章目录1.安装Windows Server 20192.开启WLAN服务3.固定IP地址4.开启远程桌面服务4.1 添加远程桌面服务4.2 激活服务器4.3 安装许可证5.配置远程桌面服务5.1 配置许可证服务器和授权模式5.2 配置连接模式5.3 启用计算机的远程功能5.4 设置用户能使用简单密
yolov7.yaml文件详解
yolov7.yaml文件详解
SadTalker项目上手教程
最近发现一个很有趣的GitHub项目,它能够将一张图片跟一段音频合成一段视频,看起来毫无违和感,如果不仔细看,甚至很难辨别真假,预计未来某一天,一大波网红即将失业。虽然这个项目目前的主要研究方向还是基于cuda的脸部训练,生成动态的视频,但如果能够接入语音服务,利用ChatGPT实时生成对话prom
ChatGPT中文在线官网-如何与chat GPT对话
ChatGPT是一种基于Transformer架构的自然语言处理技术,其中包含了多个预训练的中文语言模型。这些中文ChatGPT模型大多数发布在Github上,可以通过Github的源码库来下载并使用,包括以下几种方式:下载预训练的中文ChatGPT模型文件:不同的中文ChatGPT平台提供的预训练
Yolov5
以Yolov5模型结构
长短时记忆网络(Long Short Term Memory,LSTM)详解
长短时记忆网络(LSTM)基本原理与基于Pytorch的实现方法。
显卡的一些总结
显卡的一些总结
权重衰减/权重衰退——weight_decay
权重衰减/权重衰退——weight_decay
谈yolov5车辆识别
当今社会,随着人工智能技术的发展和应用,车辆识别成为了一项重要的研究课题。YOLOv5是一种流行的车辆识别算法,它能够快速、准确地检测和识别出图像中的车辆。本篇博客将对YOLOv5算法进行详细的介绍,并探讨其在车辆识别领域的应用。
什么是预训练模型?
什么是预训练模型?
Yolo训练时,输出的参数的含义
这些指标的意义是,P和R可以帮助评估模型的分类和检测能力,mAP则综合了模型在不同IoU阈值下的表现,是评估模型性能的主要指标之一。这些参数的意义可以帮助训练者监控模型的训练过程,以便在必要时进行调整和优化。
单个消费级GPU笔记本win电脑测试LLaMA模型
b N,--batch_size N用于提示处理的批量大小(默认值:8)-n n,--n_predict n个要预测的令牌数(默认值:128)将在"7B”文件夹产生一个名为”models/7B/ggml-model-q4_0.bin"的文件。将在"7B”文件夹产生一个名为”models/7B/ggm
Halcon深度学习总结
Halcon深度学习
深入浅出Pytorch函数——torch.as_tensor
torch.as_tensor(data, dtype=None, device=None)



