
一、引言
主流的深度学习基础框架有很多:tensorflow、pytorch、paddlepaddle、keras、caffee等等。
随着以Bert、GPT系列为代表的NLP预训练语言模型的诞生,对于NLP的语言模型研究走向了大规模预训练之路。
在CV领域,随着GAN、Diffusion Model、Transformers与传统CV技术的结合,也逐步走向了大模型之路,DALL·E2的爆炸效果也是基于“大力出奇迹”。
在多模态领域,CLIP等模型参数也很大。
这似乎预示着,只有“大力出奇迹”才是强人工智能的未来之路。像当下异常火爆的ChatGPT的背后原理则是超大规模模型GPT-3采用STF+RLHF(Supervised Fine-Tuning Reinforcement Learning Human Feedback)进行训练得来。
因此,基于基础深度学习框架,学习了解大模型深度学习框架是必不可少的。而这方面的研究,更多的是系统方向和深度学习的结合。
二、深度学习系统方向发展简单介绍
深度学习在2014年之后,开始大火,缘由在于2012年,AlexNet模型引起的计算机视觉图像分类任务的变革方法。在此之后,DL领域很卷,模型相继很大,系统方向的研究也层出不穷。
2.1 参数服务器(Parameter Server)
论文地址:参数服务器:李沐
这个工作是李沐在2014年完成的工作,其核心在于提出一种数据并行(Data Parallel)的参数服务器,目的是使得大规模的机器学习模型能在工业界完成训练。
其意义在于:为之后大规模深度学习框架ZeRO提供了思路借鉴。
(后续会针对这篇论文进行精读,发一个博客,有兴趣的童鞋可以关注)
2.2 GPipe
论文地址:Gpipe:2019
这篇论文提出一个新的大规模深度学习框架。它采用一种流水线并行的方式,实现了更少显存的情况下训练了更大的模型。这些大模型包括语言模型和CV的一些模型。
其意义在于:提出一种流水线并行的方式,对大模型不同的层之间进行切片训练。
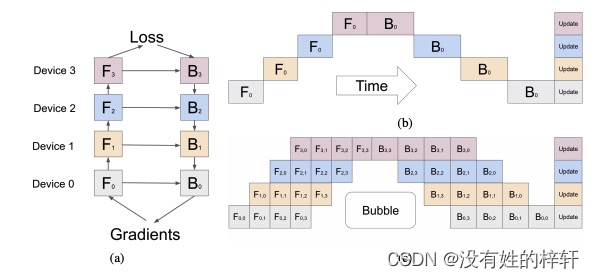
它有两个关键技术:
(1)micro-batch
把L层的神经网络按层切开(层外),一共为K快。然后把每一块放到一个GPU上进行计算。如上图(b)所示。但这种方式,在时间层面上,和单卡训练的时间没啥区别。为了解决这个问题,可以对每个小批量的数据样本再进行切分成微批量(micro-batch),然后每个时刻只让一个微批量送入GPU中进行训练,如上图©所示。这样即可实现简单流水线并行。其中的Bubble形状只与GPU数量相关。若增加微批量的数目,则会进一步增加GPU的存储利用率。
(2)re-materialization(active checkpoint)
每层中间计算的梯度数据会占用大量的GPU显存。
实际上,梯队下降算法更新梯度时,是对参数W求偏导梯度。这里之所以要求y对x的偏导是因为,反向传播时,需要用到这个数值(通常称为:activation)。而这个数值在前向传播时若已求得,并保存到显存中,会加快反向传播的速率。但增大了内存使用量。
re-materialization技术是指在对L层大规模神经网络分为若干块后,对每个快连接的地方的网络层的相关前向传播梯度数据进行保存,而其他层则在反向传播时重新计算。(时间换空间)
这样会节省大量GPU显存。
使得在少量GPU或使用较少的显存能训练起来更大的模型。
重新计算占用总计算时间的三分之一。(暂未有论文论述原因)
其他的工作:PipeDream(微软的工作)
2.3 Megatron-LM (张量并行 TP)
论文地址:Megatron-LM:2019
该模型提出一种特殊的模型并行(Model Parallel)方法,即层内模型并行也叫张量并行(Tensor Parallel)。
该框架最大的贡献在于:开源+简单。
这导致后续的深度学习大模型开源框架都或多或少是在该框架基础上进行的改进和修整。
Megatron-LM框架只针对语言模型。主要是GPT、Bert、T5等模型。
对于Bert,该框架对其层归一化做了上图的修改,才能使得大规模Bert模型能得到收敛。
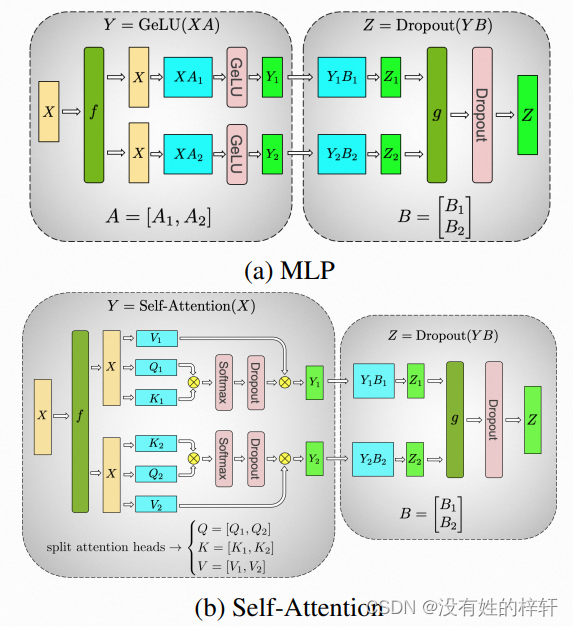
对于张量并行,其切分方法只有两种,一种是对MLP的切分,一种是对Self-Attention的切分。
2.4 Zero (Offload Infinity)
论文地址:ZeRO
该框架是在Megatron基础上构建,其开源框架为DeepSpeed
这是一个较为容易上手的大规模预训练语言模型框架。它不仅实现了ZeRO,还包括ZeRO Offload 及 ZeRO Infinity。
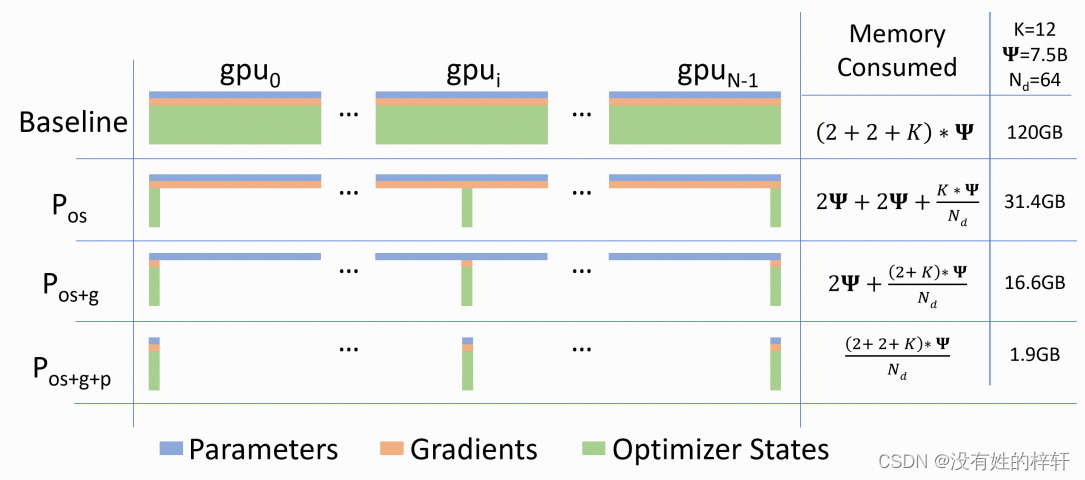
实际上,ZeRO采用的思想和参数服务器的思想基本一致,都是对超大规模深度神经网络模型在训练过程中,产生的参数、优化器状态、梯度等使用数据并行的方式,进而减少冗余,以使得更少的显存占用训练更大的模型。
ZeRO需要对三块数据进行数据并行优化:
优化器状态(Optimizer states) os
梯度数据(gradients) g
超参数数据(parameters) p
其中:Pos=ZeRO1、Pos+g=ZeRO2、Pos+g+p=ZeRO3
讲这三个数据之前要讲一个重点内容:混合精度训练(mixed-precision)
2.4.1 mixed-precision
nvidia的卡在半精度训练会更快点儿,即fp16位浮点数。
原因:在硬件上来说,每个bit都要对应硬件的计算逻辑单元,即物理的门来帮助运算当把正常的浮点运算从32位降到一半时,能剩下大量的物理门电路逻辑运算单元。意味着在相同尺寸的芯片上,则能放到更多的,能并行计算机的物理单元。所以,从计算密度角度来说,fp16要比fp32要高。
使用半精度训练的意思是指:对模型每个层的w(parameters)和中间结果数据的输入输出(activations)都是使用fp16进行训练的
w*x=y 这个运算过程都是fp16,但由于fp16的精度不够,导致会出现爆炸。即很小的数会变成0.这种情况在累计权重的时候会出现。权重是指不断的把梯度的东西加进来。如果,权重也是fp16的话,加半天也加不动,因此,在权重更新时,采用fp32进行的。
权重还有一个额外的fp32的复制,在做梯度更新时,需要使用fp32的精度进行计算,算完后再转为fp16,再参与前向传播和反向传播算法。
2.4.2 训练过程中维护的数据量计算
假设一个模型的参数占用的存储量是Y
则在前向传播和后向传播计算过程中的fp16的参数量(parameter)需要维护2Y(bytes),fp16的梯度(gradients)需要维护2Y(bytes)。
优化器(ADAM)需要维护三个fp32的数据(做梯度更新采用fp32的精度进行计算)。复制的参数量(parameter):4Y (bytes)、momentum (bytes)、variance (bytes)
这些一共是16Y的数据保存量。若一个GPT2(1.5B)模型训练起来,需要保存的数据量会扩大到1.5*16B的情况。
(后续会补充 Offload 和 Infinity的相关内容)
2.5 Pathways 2022
论文地址:Pathways:2022
基于谷歌的Tensorflow系列的大模型
引出Jeff Dean对下一代深度学习框架的预测:
多模态、稀疏、动态路由
2.6 InstructGPT
论文地址:InstructGPT
这个模型是ChatGPT背后的模型之一。当前ChatGPT模型的论文还没有出来,预计还需要几个月的时间。但参考这篇文章的核心思想已经可以确定ChatGPT是向哪个方向去发展了。
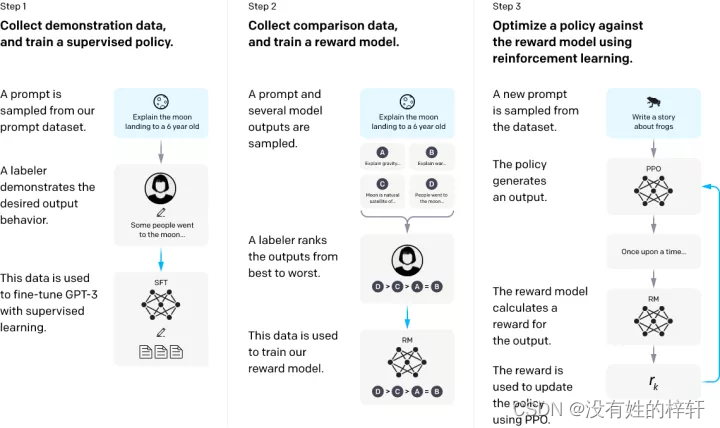
2.6.1 数据集采集
(1)雇佣一些工作人员去编写一些问题和对应答案的数据集。
(2)用第一批数据集训练第一个InstructGPT模型,然后再对相关问题再进行预测,基于此扩充更大的数据集。
2.6.1 Supervised Fine-Tuning (SFT) prompt
这个思想很简单,就是使用GPT-3去在人类标注的问答对上进行训练。当然也采用了prompt learning的思想。
2.6.1 RLHF (Reinforcement Learning Human Feedback)
简单来说,就是采用强化学习的方式,对某个问题的不同个答案进行排序。训练目标就是让模型预测出的排序和人类进行排序的答案一致。也被称为一种Reward Model。而这种反馈来自于人类。
三、总结
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow/JAX (Pathways)和 GPU + PyTorch + Megatron-LM + DeepSpeed。前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Googler来说, 只可远观而不可把玩,后者背后则有NVIDIA、Meta、MS大厂加持,社区氛围活跃,也更受到群众欢迎。
版权归原作者 没有姓的梓轩 所有, 如有侵权,请联系我们删除。