AI数字人:基于VITS模型的中文语音生成训练
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语
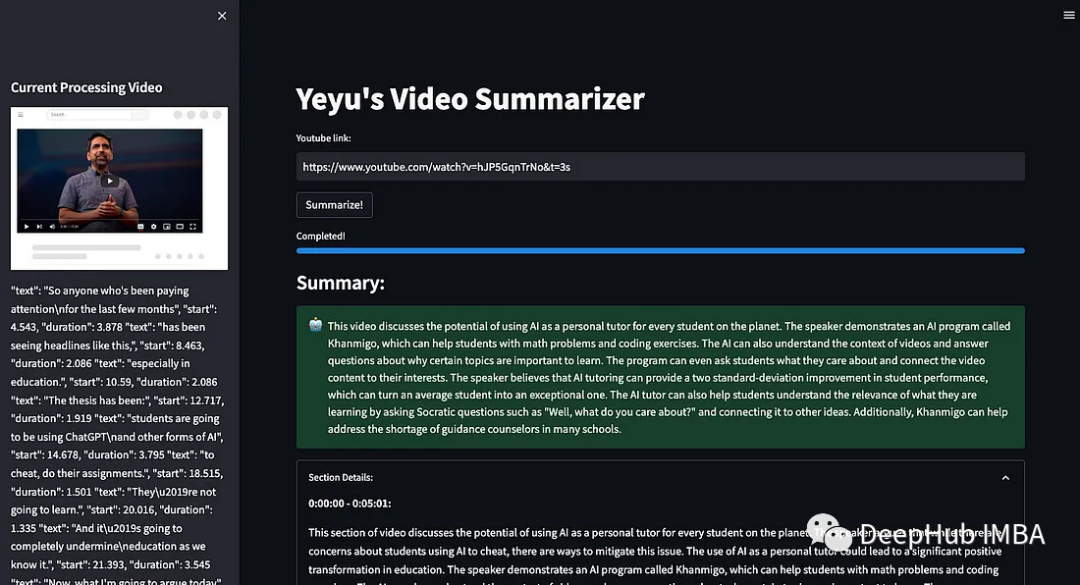
使用Streamlit和OpenAI API构建视频摘要
本文提供了使用Streamlit和OpenAI创建的视频摘要应用程序的概述。该程序为视频的每个片段创建简洁的摘要,并总结视频的完整内容。
深入浅出TensorFlow2函数——tf.data.Dataset.from_tensor_slices
from_tensor_slices( tensors, name=None)
初学者关于ConvLSTM的理解
选择最常见的基于Pytorch深度学习框架的ConvLSTM代码,在他人已有注解的情况下,逐行对代码进行详细的注解,供新手理解。
用一杯星巴克的钱,训练自己私有化的ChatGPT
点击蓝字 关注我们文章摘要:用一杯星巴克的钱,自己动手2小时的时间,就可以拥有自己训练的开源大模型,并可以根据不同的训练数据方向加强各种不同的技能,医疗、编程、炒股、恋爱,让你的大模型更“懂”你…..来吧,一起尝试下开源DolphinScheduler加持训练的开源大模型!导读让人人都拥有自己的Ch
使用MMDetection训练自己的数据集
本文主要阐述如何使用训练自己的数据,包括配置文件的修改,训练时的数据增强,加载预训练权重以及绘制损失函数图等。这里承接上一篇文章,默认已经准备好了COCO格式数据集且已安装,环境也已经配置完成。这里说明一下,因为更新至2.x版本之后有些用法不一样了,所以对本文重新更新一下,这里使用的的版本是2.27
OpenAI的人工智能语音识别模型Whisper详解及使用
拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whi
基于树莓派4B的智能无人巡逻小车设计
本实验设计的场景是智能警用无人巡逻小车,可以自动巡线,精准避障,遇到障碍物时实现S型绕弯,同时闪烁LED灯提醒,智能检测障碍物是车牌还是无关障碍,完成识别及做出相应的动作,完成信息发送,车牌存档等等操作,再实现精准避开车牌,若遇到四方都有障碍则原路返回,巡线直至检测到停车线,停车入库等内容。....
改进版ASPP(2):ASPP模块中加入CBAM(卷积注意力模块),即CBAM_ASPP
改进ASPP,加入卷积注意力机制,即为CBAM_ASPP
(四)yolov5--common.py文件解读
参考网址:https://blog.csdn.net/qq_38251616/article/details/124665998上次对yolov5s.yaml文件进行了解读,这次在对common.py文件解读之前,先放上yolov5s.yaml对应的网络结构图,如下图所示。对于网络结构图中的各个模块
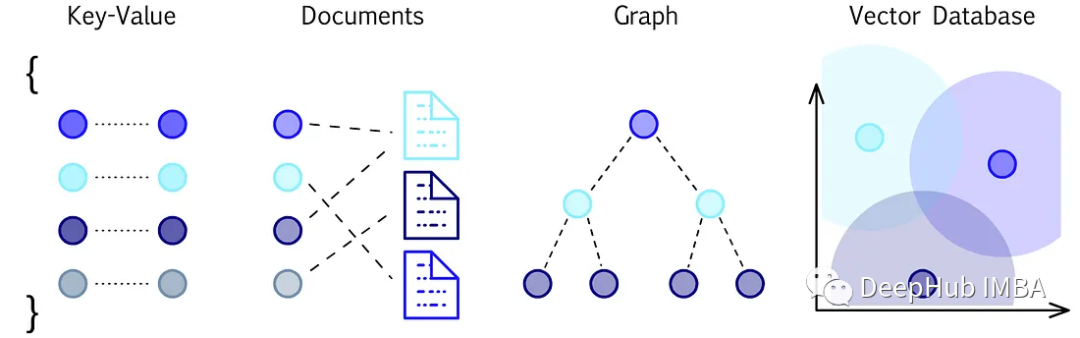
矢量数据库对比和选择指南
矢量数据库是为实现高维矢量数据的高效存储、检索和相似性搜索而设计的。使用一种称为嵌入的过程,将向量数据表示为一个连续的、有意义的高维向量。
模型加载至 cpu 和 gpu 的方式
模型加载至 cpu 和 gpu 的方式,只需改一句话
PANet(CVPR 2018)原理与代码解析
信息在神经网络中的传播方式是非常重要的。本文提出的路径聚合网络(Path Aggregation Network, PANet)旨在促进proposal-based实例分割框架中的信息流动。具体来说,通过自底向上的路径增强,利用底层中精确的定位信息来增强整个特征层次,缩短了下层与最上层之间的信息路径
AI实战营:MMPose开源算法库
【代码】AI实战营:MMPose开源算法库。
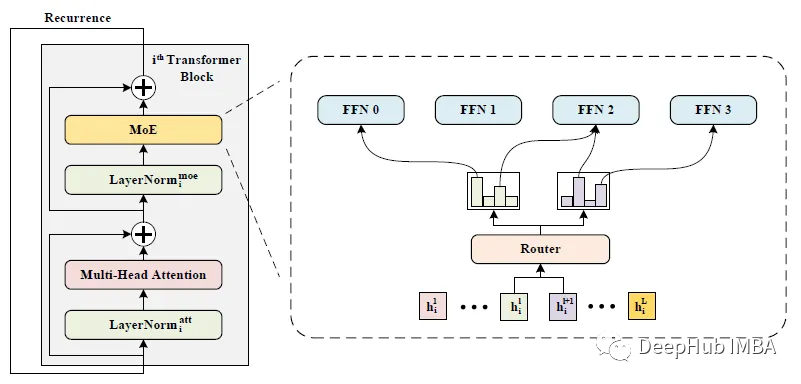
WideNet:让网络更宽而不是更深
这是新加坡国立大学在2022 aaai发布的一篇论文。WideNet是一种参数有效的框架,它的方向是更宽而不是更深。通过混合专家(MoE)代替前馈网络(FFN),使模型沿宽度缩放。使用单独LN用于转换各种语义表示,而不是共享权重。
基于 YOLOv8 的自定义数据集训练
图1.1:YOLOv8初始测试YOLOv8????于 2023年1月10日由Ultralytics发布。它在计算机视觉方面提供了进展,带来了对我们感知、分析和理解视觉世界的巨大创新。它将为各个领域带来前所未有的可能性。在速度、准确性和架构方面进行了相当大的改进。它是从头开始实现的,没有使用任何来自Y
LoRA模型是什么?
LoRA(Low-Rank Adaptation of Large Language Models,大型语言模型的低秩适应)是微软研究员提出的一种新颖技术,旨在解决微调大型语言模型的问题。研究人员发现,通过专注于大型语言模型的Transformer注意力块,LoRA的微调质量与完整模型的微调相当,同
pytorch 手动顺序搭建resnet18、附带训练代码、测试代码
文件名:mode_resnet18。
Simulink中传递函数transfer fcn中迟滞参数如何设置
simulink中传递函数transfer fcn中的参数设定,使其与原始信号更接近或按需平滑处理。
深度学习之FPN+PAN
FPN+PAN



