
本文提供了使用Streamlit和OpenAI创建的视频摘要应用程序的概述。该程序为视频的每个片段创建简洁的摘要,并总结视频的完整内容。
要运行应用程序,需要安装以下依赖项:
- Python(3.7或更高版本)
- Streamlit
- OpenAI API密钥
- llama_index
- youtube_transcript_api
- html2image
- langchain
搭建环境
首先,需要设置我们的开发环境,可以使用以下代码片段将API密钥设置为环境变量:
import os
os.environ["OPENAI_API_KEY"] = '{your_Api_Key}'
然后导入所有的包
from llama_index import StorageContext, load_index_from_storage
from llama_index import VectorStoreIndex
import streamlit as st
from llama_index import download_loader
from llama_index import GPTVectorStoreIndex
from llama_index import LLMPredictor, GPTVectorStoreIndex, PromptHelper, ServiceContext
from langchain import OpenAI
from langchain.chat_models import ChatOpenAI
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api.formatters import JSONFormatter
import json
import datetime
from html2image import Html2Image
处理用户输入和YouTube视频检索
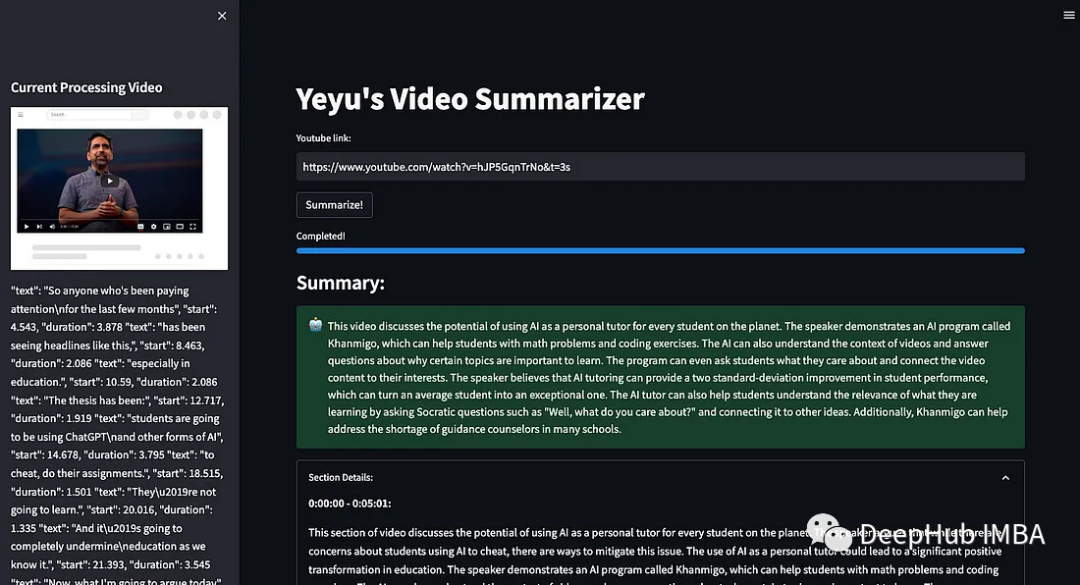
以下代码是Streamlit的按钮和事件:我们提示用户输入一个YouTube视频链接。使用st.text_input捕获输入,并将其存储在youtube_link变量中。按钮的名字为“Summarize!”,当单击该按钮时将触发我们的处理过程。下面是相关的代码片段:
youtube_link = st.text_input("Youtube link:")
st.button("Summarize!", on_click=send_click)
获取视频文本和预处理
使用YouTubeTranscriptApi可以获得视频文本。然后将转录本格式化为JSON并保存到文件中。然后再使用Html2Image库捕获YouTube视频的屏幕截图:
srt = YouTubeTranscriptApi.get_transcript(st.session_state.video_id, languages=['en'])
formatter = JSONFormatter()
json_formatted = formatter.format_transcript(srt)
with open(transcript_file, 'w') as f:
f.write(json_formatted)
hti = Html2Image()
hti.screenshot(url=f"https://www.youtube.com/watch?v={st.session_state.video_id}", save_as=youtube_img)
建立索引和查询语言模型
下面就是对上面获取文本的处理,使用llama_index库中的VectorStoreIndex类创建索引。索引是根据视频文本构建的,另外还定义了LLMPredictor和ServiceContext来处理语言模型交互。下面是相关的代码片段:
documents = loader.load_data()
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# Create and load the index
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
index.storage_context.persist()
# Load the index from storage
storage_context = StorageContext.from_defaults(persist_dir=index_file)
index = load_index_from_storage(storage_context, service_context=service_context)
# Create a query engine for the index
query_engine = index.as_query_engine()
生成视频摘要
这一步遍历视频文本并为视频的每个部分生成摘要。通过使用query_engine从视频部分构造的提示来查询语言模型。生成的摘要存储在section_response变量中:
section_response = ''
for d in transcript:
# ...
if d["start"] <= (section_start_s + 300) and transcript.index(d) != len(transcript) - 1:
section_texts += ' ' + d["text"]
else:
end_text = d["text"]
prompt = f"summarize this article from \"{start_text}\" to \"{end_text}\", limited to 100 words, start with \"This section of video\""
response = query_engine.query(prompt)
start_time = str(datetime.timedelta(seconds=section_start_s))
end_time = str(datetime.timedelta(seconds=int(d['start'])))
section_start_s += 300
start_text = d["text"]
section_texts = ''
section_response += f"**{start_time} - {end_time}:**\n\r{response}\n\r"
生成最终总结
在处理完所有视频片段后,,生成整个视频的最终摘要。生成的摘要存储在响应变量中:
prompt = "Summarize this article of a video, start with \"This Video\", the article is: " + section_response
response = query_engine.query(prompt)
显示结果
最后,我们使用streamlit显示生成的摘要和部分详细信息:
st.subheader("Summary:")
st.success(response, icon="🤖")
with st.expander("Section Details: "):
st.write(section_response)
st.session_state.video_id = ''
st.stop()
总结
本文演示了如何创建一个基于python的视频摘要程序。使用youtube_transcript_apto直接获取视频的文本,并通过OpenAI的语言模型来提供摘要。
作者没有个完整代码地址,所以有兴趣请与原文作者联系:
作者:Abhijeetas