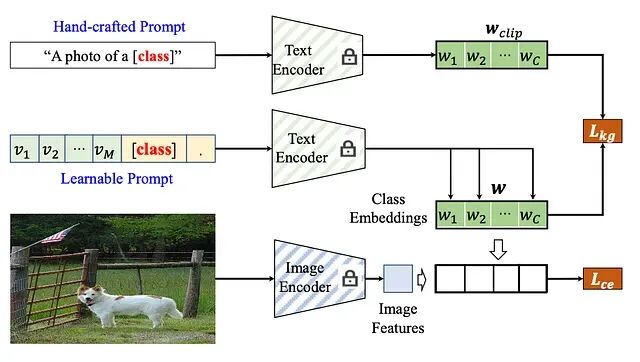
知识引导上下文优化(KgCoOp):一种解决灾难性遗忘的 Prompt Tuning 机制
如何使用知识引导损失对可学习 Prompt 进行正则化以保持泛化能力。

深入理解三种PEFT方法:LoRA的低秩更新、QLoRA的4位量化与DoRA的幅度-方向分解
三种方法各有分工,互为补充,你唯一需要考虑的是哪种 PEFT 方案最贴合自己的硬件条件和精度要求。
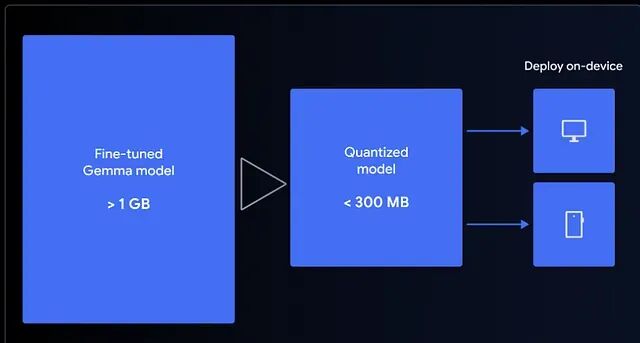
1小时微调 Gemma 3 270M 端侧模型与部署全流程
Gemma 3 270M是谷歌推出的轻量级开源模型,可快速微调并压缩至300MB内,实现在浏览器中本地运行。本文教你用QLoRA在Colab微调模型,构建emoji翻译器,并通过LiteRT量化至4-bit,结合MediaPipe在前端离线运行,实现零延迟、高隐私的AI体验。小模型也能有大作为。
Salesforce AI研究: 从奖励建模到在线RLHF工作流
该研究对RLHF的基础理论、偏好模型的构建以及迭代策略优化等内容进行了深入的讲解,展示了扎实的理论基础和实践经验。

微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
论文详细研究了一个经过微调的模型会发生什么,以及它在获得新知识后的反应会发生什么。
基于大模型的Text2SQL微调的实战教程(二)
本文主要介绍了基于大模型的Text2SQL微调的实战教程(二),希望对学习大语言模型的同学们有所帮助。文章目录1. 前言2. 配置环境 2.1 安装虚拟环境 2.2 安装依赖库 2.3 下载模型文件3. 运行代码 3.1 数据预处理 3.2 修改配置文件 3.3 微调

如何准确的估计llm推理和微调的内存消耗
在本文中,我将介绍如何计算这些模型用于推理和微调的最小内存。这种方法适用于任何的llm,并且精确的计算内存总消耗。
【微调大模型】如何利用开源大模型,微调出一个自己大模型
微调(Fine-tuning)是一种将预训练模型应用于特定任务的方法。通过微调,我们可以让预训练模型学习特定任务的参数,从而在新的任务上获得更好的性能。与从头开始训练模型相比,微调可以大大节省计算资源和时间成本。
Gemma谷歌(google)开源大模型微调实战(fintune gemma-2b)
Gemma-SFT(谷歌, Google), gemma-2b/gemma-7b微调(transformers)/LORA(peft)/推理。
使用SPIN技术对LLM进行自我博弈微调训练
SPIN从AlphaGo Zero和AlphaZero等游戏中成功的自我对弈机制中汲取灵感。它能够使LLM参与自我游戏的能力。
RoSA: 一种新的大模型参数高效微调方法
随着语言模型不断扩展到前所未有的规模,对下游任务的所有参数进行微调变得非常昂贵,PEFT方法已成为自然语言处理领域的研究热点。PEFT方法将微调限制在一小部分参数中,以很小的计算成本实现自然语言理解任务的最先进性能。
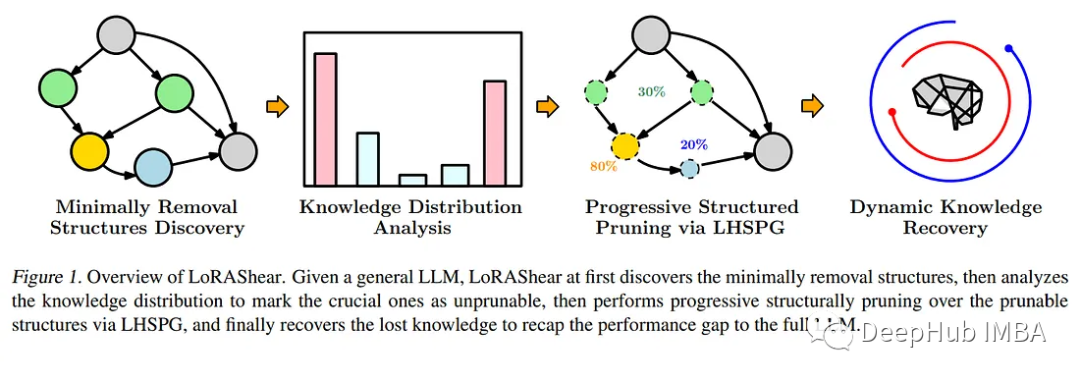
LoRAShear:微软在LLM修剪和知识恢复方面的最新研究
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。



