
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。
LHSPG技术( Lora Half-Space Projected Gradient)支持渐进式结构化剪枝和动态知识恢复。可以通过依赖图分析和稀疏度优化应用于各种llm。
LoRAPrune将LoRA与迭代结构化修剪相结合,实现参数高效微调。在LLAMA v1上的实现即使进行了大量的修剪也能保持相当的性能。
在不断发展的人工智能领域,语言模型模型(llm)已经成为处理大量文本数据、快速检索相关信息和增强知识可访问性的关键工具。它们的深远影响跨越了各个领域,从增强搜索引擎和问答系统到启用数据分析,研究人员、专业人员和知识寻求者都从中获益。
而目前最大的问题是,信息的动态性要求LLM不断更新知识。一般情况下微调一直被用来向这些模型灌输最新的见解的方式,开发人员使用特定于领域的数据对预训练模型进行微调使其保持最新状态。因为组织和研究人员的定期更新对于保持llm与不断变化的信息景观保持同步至关重要。但微调的成本大且周期长。
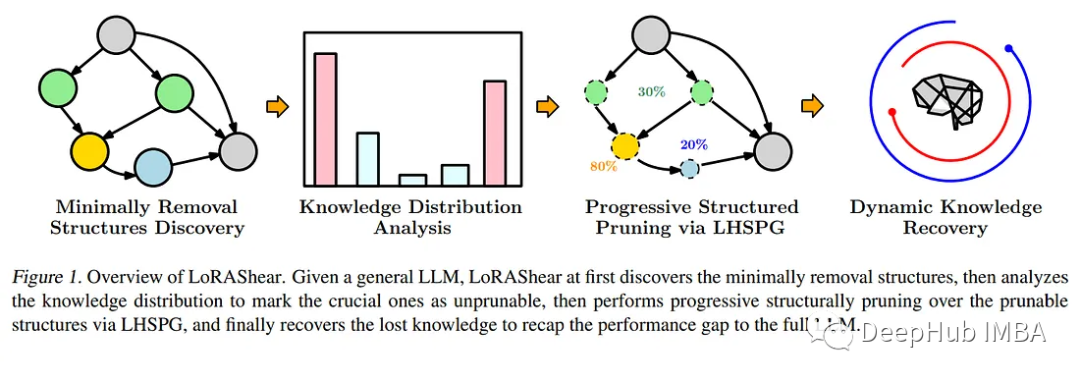
为了应对这一迫切需要,微软的研究人员推出了一种开创性的方法——LoRAShear。这种创新的方法不仅简化了llm,而且促进了结构知识的恢复。结构修剪的核心是去除或减少神经网络架构中的特定组件,优化效率、紧凑性和计算需求。
微软的LoRAShear引入了LHSPG技术,支持渐进式结构化修剪。这种方法在LoRA模块之间无缝地传递知识,并集成了动态知识恢复阶段。微调过程类似于预训练和指示微调,确保llm保持更新和相关性。
LoRAShear通过依赖图分析可以扩展到一般llm,特别是在LoRA模块的支持范围内。所采用的算法为原始LLM和LoRA模块创建依赖关系图。除此以外还引入了一种结构化稀疏性优化算法,该算法利用LoRA模块信息来增强权重更新过程中的知识保存。
论文中还有一个称为LoRAPrune的集成技术,将LoRA与迭代结构化修剪相结合,实现了参数高效的微调和直接硬件加速。这种节省内存的方法完全依赖于LoRA的权重和梯度来进行修剪标准。这个过程包括构造一个跟踪图,确定要压缩的节点组,划分可训练的变量,并最终将它们返回给LLM。
论文通过在开源LLAMAv1上的实现,证明了LoRAShear的有效性。值得注意的是,修剪了20%的LLAMAv1只有1%的性能损失,而修剪了50%的模型在评估基准上保留了82%的性能。
LoRAShear代表了人工智能领域的重大进步。它不仅简化了LLM的使用方式,使其更有效率,而且确保了关键知识的保存。它可以使人工智能驱动的应用程序能够在优化计算资源的同时,与不断发展的信息环境保持同步。随着组织越来越依赖人工智能进行数据处理和知识检索,像LoRAShear这样的解决方案将在市场上发挥关键作用,提供效率和知识弹性。
论文地址:
https://arxiv.org/abs/2310.18356
作者:Multiplatform.AI