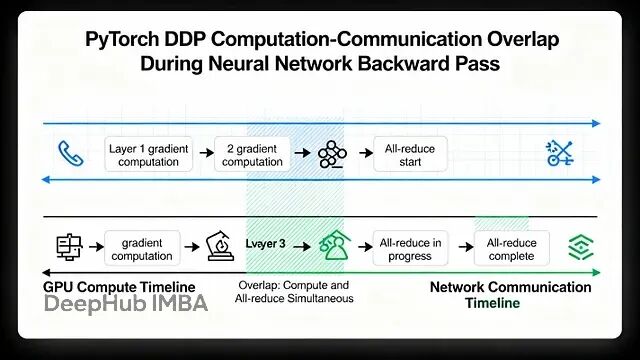
PyTorch 分布式训练底层原理与 DDP 实战指南
本文讲详细探讨Pytorch的数据并行(Data Parallelism)
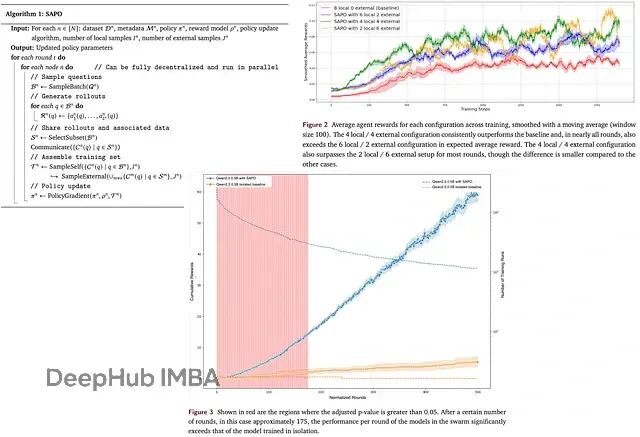
SAPO去中心化训练:多节点协作让LLM训练效率提升94%
SAPO提出了一种去中心化的异步RL方案,让各个计算节点之间可以互相分享rollouts,避开了传统并行化训练的各种瓶颈。

融合AMD与NVIDIA GPU集群的MLOps:异构计算环境中的分布式训练架构实践
本文将深入探讨如何混合AMD/NVIDIA GPU集群以支持PyTorch分布式训练。
一次讲清模型并行、数据并行、张量并行、流水线并行区别nn.DataParallel[分布式]
通过这种行切分的方式,张量并行能够有效地将大型矩阵分散到多个GPU上,既解决了单GPU内存不足的问题,又保持了计算的数学等价性。总的来说,张量并行的核心思想是利用分块矩阵的计算原理,将大矩阵切分到不同设备上,通过通信操作保证数学等价性。当然,张量并行中的行并行(Row Parallelism)是一种

PyTorch中的多GPU训练:DistributedDataParallel
本文将介绍DistributedDataParallel,DDP 基于使用多进程而不是使用多线程的 DP,可以扩充到多机多卡的环境,所以他是分布式多GPU训练的首选。
Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)
考虑到深度学习训练过程都有一套约定成俗的流程,鄙人借鉴Keras开发了一套基础训练库: Pytorch-Base-Trainer(PBT); 这是一个基于Pytorch开发的基础训练库,支持以下特征:



